【python爬虫】利用selenium和Chrome浏览器进行自动化网页搜索与浏览
from selenium import webdriver
from time import sleep # 后面是你的浏览器驱动位置,记得前面加r'','r'是防止字符转义的
driver = webdriver.Chrome(r'C:\Python34\chromedriver_x64.exe')
# 用get打开百度页面
driver.get("http://www.baidu.com")
# 查找页面的“设置”选项,并进行点击
driver.find_elements_by_link_text('设置')[0].click()
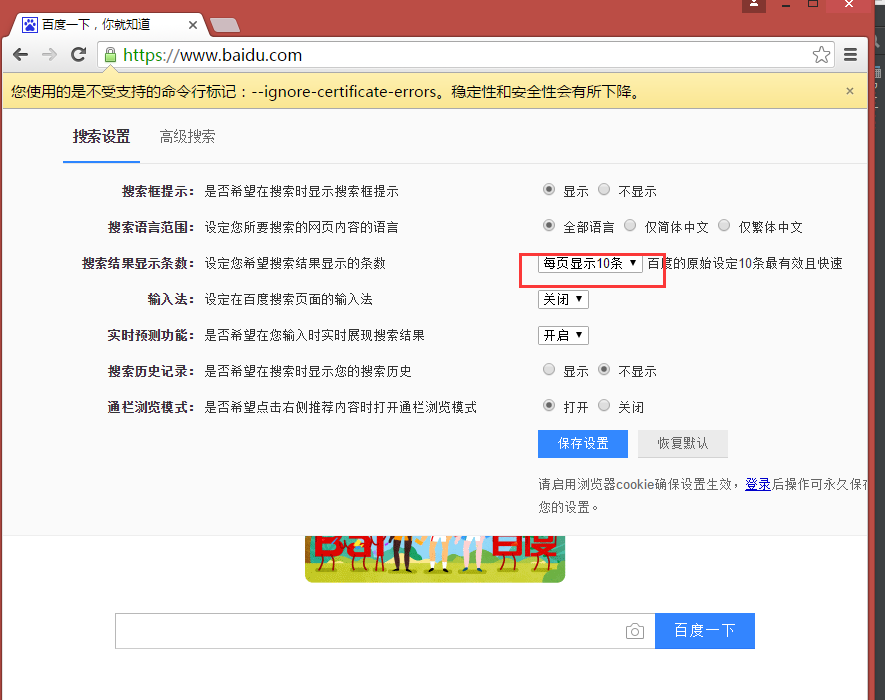
# 打开设置后找到“搜索设置”选项,设置为每页显示50条
driver.find_elements_by_link_text('搜索设置')[0].click()
sleep(2)
m = driver.find_element_by_id('nr')
sleep(2)
m.find_element_by_xpath('//*[@id="nr"]/option[3]').click()
sleep(2)
# 处理弹出的警告页面
driver.find_element_by_class_name("prefpanelgo").click()
sleep(2)
driver.switch_to_alert().accept()
sleep(2)
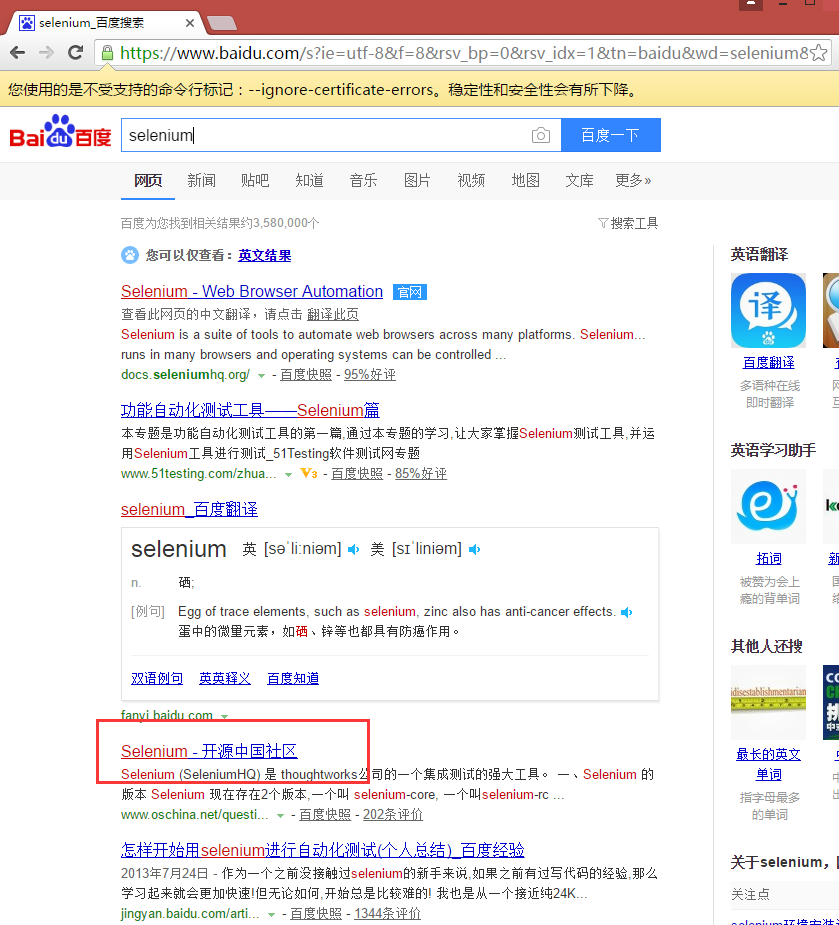
# 找到百度的输入框,并输入“selenium”
driver.find_element_by_id('kw').send_keys('selenium')
sleep(2)
# 点击搜索按钮
driver.find_element_by_id('su').click()
sleep(2)
# 在打开的页面中找到“Selenium - 开源中国社区”,并打开这个页面
driver.find_elements_by_link_text('Selenium - 开源中国社区')[0].click()
4.以下页面操作都是自动完成
【python爬虫】利用selenium和Chrome浏览器进行自动化网页搜索与浏览的更多相关文章
- [Python爬虫]使用Selenium操作浏览器订购火车票
这个专题主要说的是Python在爬虫方面的应用,包括爬取和处理部分 [Python爬虫]使用Python爬取动态网页-腾讯动漫(Selenium) [Python爬虫]使用Python爬取静态网页-斗 ...
- Python 爬虫利器 Selenium
前面几节,我们学习了用 requests 构造页面请求来爬取静态网页中的信息以及通过 requests 构造 Ajax 请求直接获取返回的 JSON 信息. 还记得前几节,我们在构造请求时会给请求加上 ...
- Python 爬虫利器 Selenium 介绍
Python 爬虫利器 Selenium 介绍 转 https://mp.weixin.qq.com/s/YJGjZkUejEos_yJ1ukp5kw 前面几节,我们学习了用 requests 构造页 ...
- Python爬虫之selenium的使用(八)
Python爬虫之selenium的使用 一.简介 二.安装 三.使用 一.简介 Selenium 是自动化测试工具.它支持各种浏览器,包括 Chrome,Safari,Firefox 等主流界面式浏 ...
- Python爬虫教程-28-Selenium 操纵 Chrome
我觉得本篇是很有意思的,闲着没事来看看! Python爬虫教程-28-Selenium 操纵 Chrome PhantomJS 幽灵浏览器,无界面浏览器,不渲染页面.Selenium + Phanto ...
- Python爬虫之selenium高级功能
Python爬虫之selenium高级功能 原文地址 表单操作 元素拖拽 页面切换 弹窗处理 表单操作 表单里面会有文本框.密码框.下拉框.登陆框等. 这些涉及与页面的交互,比如输入.删除.点击等. ...
- Python爬虫之selenium库使用详解
Python爬虫之selenium库使用详解 本章内容如下: 什么是Selenium selenium基本使用 声明浏览器对象 访问页面 查找元素 多个元素查找 元素交互操作 交互动作 执行JavaS ...
- selenium与chrome浏览器及驱动的版本匹配
用selenium+python+webdriver完成UI功能自动化,经常会碰到浏览器版本与驱动的版本不匹配而引起报错,下面就selenium与chrome浏览器及驱动的版本匹配 做个总结. 使用W ...
- Python爬虫教程-10-UserAgent和常见浏览器UA值
Python爬虫教程-10-UserAgent和常见浏览器UA值 有时候使用爬虫会被网站封了IP,所以需要去模拟浏览器,隐藏用户身份, UserAgent 包含浏览器信息,用户身份,设备系统信息 Us ...
随机推荐
- CentOS7 yum安装lamp环境
1.安装apache yum install httpd #根据提示,输入Y安装即可成功安装 systemctl start httpd.service #启动apache systemctl sto ...
- 在云主机后台进行python程序运行
nohup python main.py & nohup liunx自带的命令 注意:后面(&)!
- Android 应用检查更新并下载
1.在Android应用当中都有应用检查更新的要求,往往都是在打开应用的时候去更新下载. 实现的方法是:服务器端提供接口,接口中可以包含在最新APK下载的URL,最新APK的VersionCode,等 ...
- 数据库表转换成JavaBean
本人花了几个小时用C#开发了一款,数据表生成javabean的软件.目前只支持Mysql,内置类型映射器.开源,没有测试. 支持数据库注释,忘了获取表注释,见谅.使用之前配置一下config.xml文 ...
- CentOS 6.9下PXE+Kickstart无人值守安装操作系统
一.简介 1.1 什么是PXE PXE(Pre-boot Execution Environment,预启动执行环境)是由Intel公司开发的最新技术,工作于Client/Server的网络模式,支持 ...
- MVC进阶篇(四)——[HttpGet]和[HttpPost]
前言 Get和post,一个获取请求,一个提交请求,在MVC里面用法也很特别,总结一下,我理解的不是特别深刻,希望多多交流. 内容 [HttpGet] 需求: 用户想要通过点击修改按钮来达到修改这部分 ...
- 最新cenos执行service httpd restart 报错Failed to restart httpd.service: Unit not found.
原来是需要将Apache注册到Linux服务里面啊!注册Apache到Linux服务在Linux下用源代码方式编译安装完Apache后,启动关闭Apache可以通过如下命令实现: /usr/local ...
- [CQOI2006]凸多边形(半平面交)
很明显是一道半平面交的题. 先说一下半平面交的步骤: 1.用点向法(点+向量)表示直线 2.极角排序,若极角相同,按相对位置排序. 3.去重,极角相同的保留更优的 4.枚举边维护双端队列 5.求答案 ...
- idea中文输入问题
desc: idea2017.3.4输入中文,光标不跟随. 解决方案:
- 查找表 219.Contains Duplicate(2),217 Contain Duplicate, 220(3)
思路:滑动窗口(长度为k+1)看这个窗口里的是否有两个元素的值相同.加查找表. //时间:O(n) //空间:O(k) class Solution { public: bool containsNe ...