Sqoop的安装配置及使用
一、Sqoop基础:连接关系型数据库与Hadoop的桥梁
1.1 Sqoop的基本概念
Hadoop正成为企业用于大数据分析的最热门选择,但想将你的数据移植过去并不容易。Apache Sqoop正在加紧帮助客户将重要数据从数据库移到Hadoop。随着Hadoop和关系型数据库之间的数据移动渐渐变成一个标准的流程,云管理员们能够利用Sqoop的并行批量数据加载能力来简化这一流程,降低编写自定义数据加载脚本的需求。

Apache Sqoop(SQL-to-Hadoop) 项目旨在协助 RDBMS 与 Hadoop 之间进行高效的大数据交流。用户可以在 Sqoop 的帮助下,轻松地把关系型数据库的数据导入到 Hadoop 与其相关的系统 (如HBase和Hive)中;同时也可以把数据从 Hadoop 系统里抽取并导出到关系型数据库里。因此,可以说Sqoop就是一个桥梁,连接了关系型数据库与Hadoop。
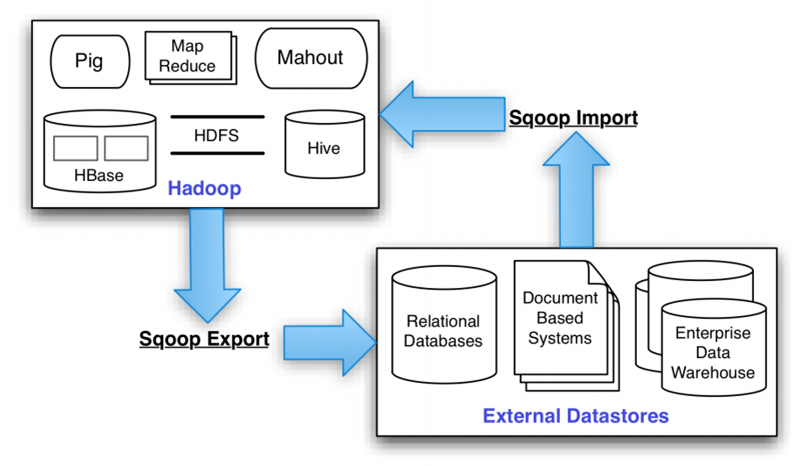
1.2 Sqoop的基本机制
Sqoop中一大亮点就是可以通过hadoop的mapreduce把数据从关系型数据库中导入数据到HDFS。Sqoop架构非常简单,其整合了Hive、Hbase和Oozie,通过map-reduce任务来传输数据,从而提供并发特性和容错。Sqoop的基本工作流程如下图所示:
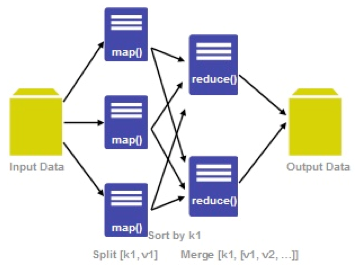
Sqoop在import时,需要制定split-by参数。Sqoop根据不同的split-by参数值来进行切分,然后将切分出来的区域分配到不同map中。每个map中再处理数据库中获取的一行一行的值,写入到HDFS中(由此也可知,导入导出的事务是以Mapper任务为单位)。同时split-by根据不同的参数类型有不同的切分方法,如比较简单的int型,Sqoop会取最大和最小split-by字段值,然后根据传入的num-mappers来确定划分几个区域。 比如select max(split_by),min(split-by) from得到的max(split-by)和min(split-by)分别为1000和1,而num-mappers为2的话,则会分成两个区域(1,500)和(501-100),同时也会分成2个sql给2个map去进行导入操作,分别为select XXX from table where split-by>=1 and split-by<500和select XXX from table where split-by>=501 and split-by<=1000。最后每个map各自获取各自SQL中的数据进行导入工作。
二、Sqoop导入
2.1 Sqoop的安装配置
(1)下载sqoop安装包:这里使用的是sqoop-1.4.5-cdh5.3.6.tar.gz版本。(下载:http://archive.cloudera.com/cdh5/cdh/5/)
(2)解压sqoop安装包:tar -zvxf sqoop-1.4.5-cdh5.3.6.tar.gz -C /opt/modules
(3)设置环境变量:sudu vim /etc/profile ,增加以下内容
#SQOOP_HOME
export SQOOP_HOME=/opt/modules/sqoop-1.4.5-cdh5.3.6
export PATH=$PATH:$SQOOP_HOME/bin
最后是环境变量生效:source /etc/profile
(4)将mysql的jdbc驱动mysql-connector-java-5.1.27-bin.jar复制到sqoop项目的lib目录下:
cp mysql-connector-java-5.1.27-bin.jar /opt/modules/sqoop-1.4.5-cdh5.3.6/lib
(5)重命名配置文件:在${SQOOP_HOME}/conf中执行命令
mv sqoop-env-template.sh sqoop-env.sh
(6)【可选】修改配置文件:vim sqoop-env.sh
# Set Hadoop-specific environment variables here.
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/opt/modules/hadoop-2.5.0-cdh5.3.6#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/opt/modules/hadoop-2.5.0-cdh5.3.6#set the path to where bin/hbase is available
#export HBASE_HOME=#Set the path to where bin/hive is available
export HIVE_HOME=/opt/modules/hive-0.13.1-cdh5.3.6#Set the path for where zookeper config dir is
#export ZOOCFGDIR=
(7) 启动Sqoop (/opt/modules/sqoop-1.4.5-cdh5.3.6目录下执行bin/sqoop help)
红色标注部分为Sqoop的所有命令,具体查看可以通过bin/sqoop help 加字段的方式来查看。例如:bin/sqoop help import
Warning: /opt/modules/sqoop-1.4.5-cdh5.3.6/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /opt/modules/sqoop-1.4.5-cdh5.3.6/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /opt/modules/sqoop-1.4.5-cdh5.3.6/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /opt/modules/sqoop-1.4.5-cdh5.3.6/../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
18/03/01 10:57:23 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5-cdh5.3.6
usage: sqoop COMMAND [ARGS]Available commands:
codegen Generate code to interact with database records
create-hive-table Import a table definition into Hive
eval Evaluate a SQL statement and display the results
export Export an HDFS directory to a database table
help List available commands
import Import a table from a database to HDFS
import-all-tables Import tables from a database to HDFS
import-mainframe Import datasets from a mainframe server to HDFS
job Work with saved jobs
list-databases List available databases on a server
list-tables List available tables in a database
merge Merge results of incremental imports
metastore Run a standalone Sqoop metastore
version Display version informationSee 'sqoop help COMMAND' for information on a specific command.
2.2 数据导入:MySQL->HDFS
这里假设我们已经在hadoop-master服务器中安装了MySQL数据库服务,并使用默认端口3306。需要注意的是,sqoop的数据库驱动driver默认只支持mysql和oracle,如果使用sqlserver的话,需要把sqlserver的驱动jar包放在sqoop的lib目录下,然后才能使用drive参数。
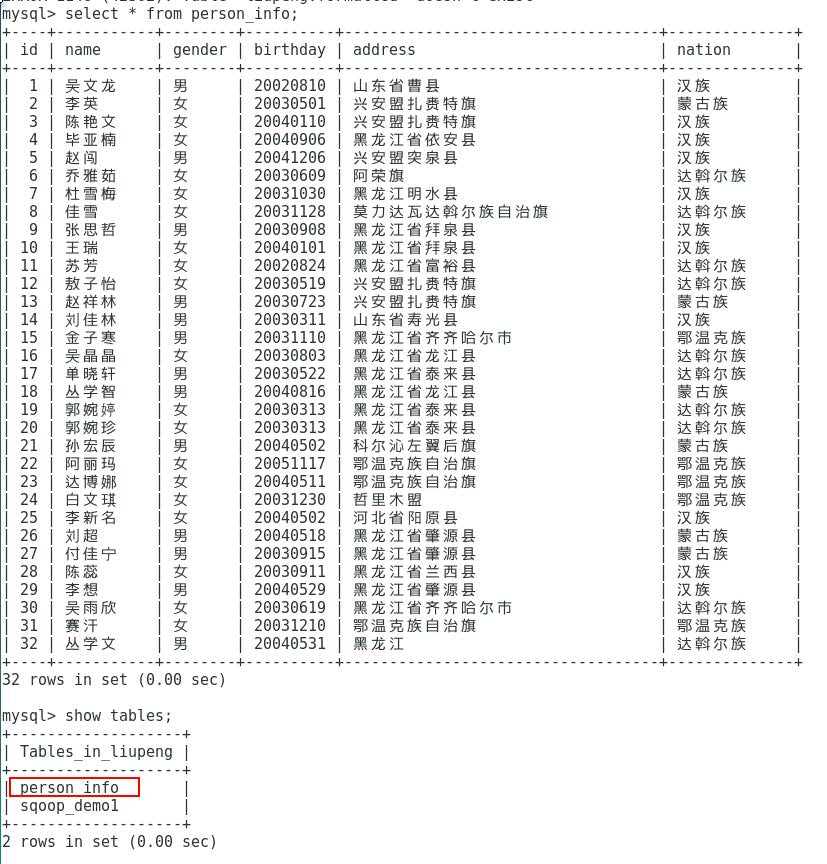
(1)MySQL数据源:mysql中的hive数据库的Person_info表,这里使用学习笔记17《Hive框架学习》里边Hive的数据库表。
(2)使用import命令将mysql中的数据导入HDFS:
首先看看import命令的基本格式:
sqoop ##sqoop命令
import ##表示导入
--connect jdbc:mysql://ip:3306/sqoop ##告诉jdbc,连接mysql的url
--username root ##连接mysql的用户名
--password admin ##连接mysql的密码
--table mysql1 ##从mysql导出的表名称
--fields-terminated-by '\t' ##指定输出文件中的行的字段分隔符
-m 1 ##复制过程使用1个map作业
--hive-import ##把mysql表数据复制到hive空间中。如果不使用该选项,意味着复制到hdfs中
然后看看如何进行实战:这里将mysql中的Person_info表导入到hdfs中(/user/liupeng/sqoop/Person_Info/mysql_to_HDFS)
为了更高效的显示成果,我们把sqoop的语句写到一个文件中格式如下(文件地址:/opt/datas/sqoop_Demo/per_info_mysql_to_HDFS.sql)
import
--connect
jdbc:mysql://127.0.0.1:3306/liupeng
--username
root
--password
123456
--table
person_info
--target-dir
/user/liupeng/sqoop/Person_Info/mysql_to_HDFS
--num-mappers
1
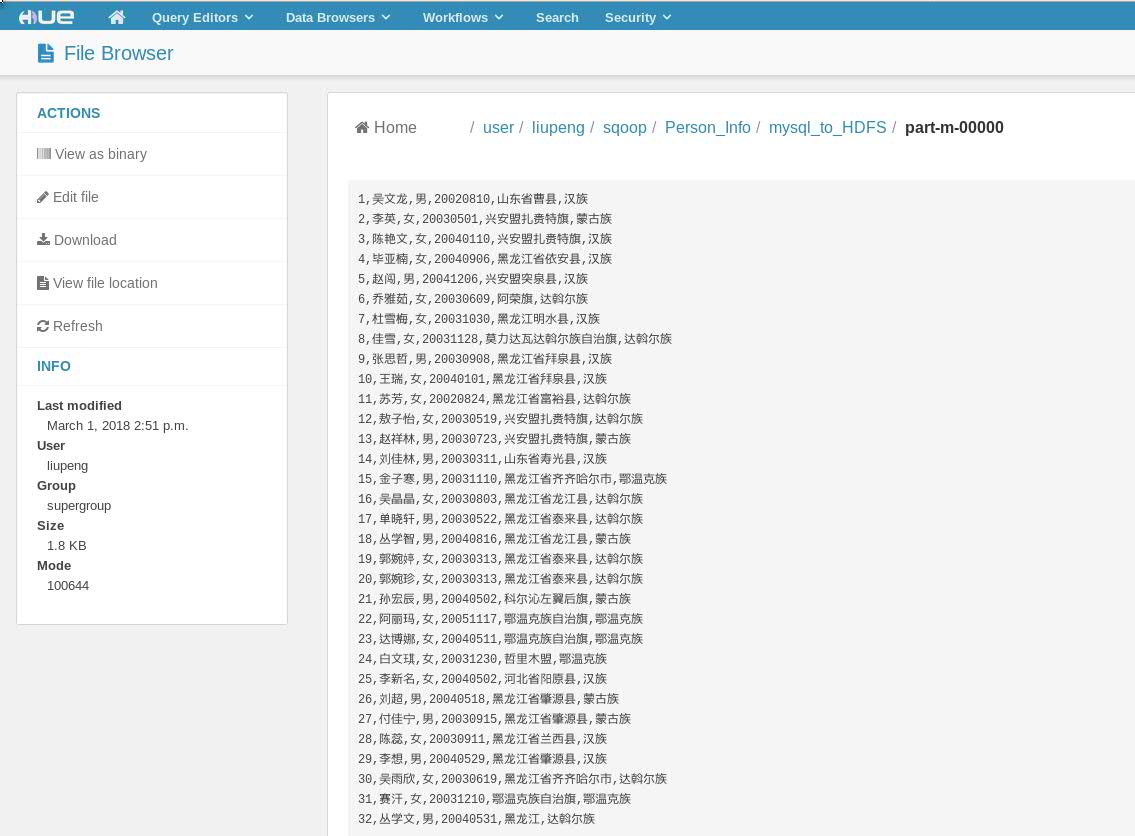
最后看看是否成功导入了HDFS中:可以看到Person_info表存入了1个map任务所生成的文件中,那是因为上述语句中--num-mappers指定了生成map的个数是1个。如果不指定会生成多个。如果数据量过大的情况下不建议设置为1
以下为Hue集成HDFS文件系统的地址及文件内容。实际上Hadoop HDFS相同路径下也同样存在相同文件。
2.3 数据导出:HDFS->MySQL
(1)既然要导出到MySQL,那么首先得要有一张接收从HDFS导出数据的表。这里为了示范,还拿上面这个数据作例子。把已经存在HDFS上的Person_info数据重新export到mysql 数据库中的test表里。
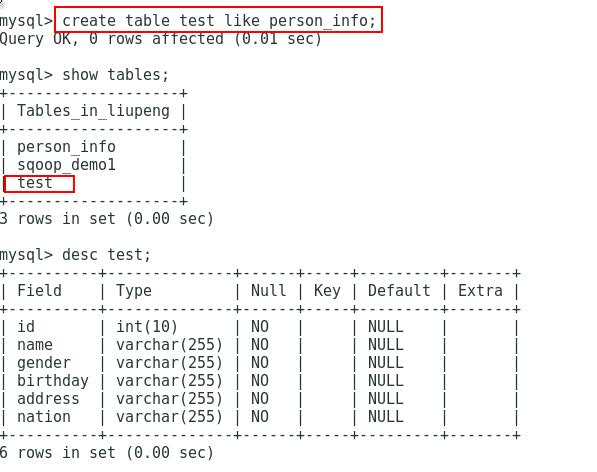
(2)使用export命令进行将数据从HDFS导出到MySQL中,可以看看export命令的基本格式。同inport案例相同。我们把数据放到一个文件中然后通过bin/sqoop --options-file 文件路径 的方式去传输数据。
export
--connect
jdbc:mysql://127.0.0.1:3306/liupeng
--username
root
--password
123456
--table
test
--export-dir
/user/liupeng/sqoop/Person_Info/mysql_to_HDFS注意:导出的数据表必须是事先存在的。而且格式必须跟HDFS文件系统要导出数据的文件格式相同才可以。
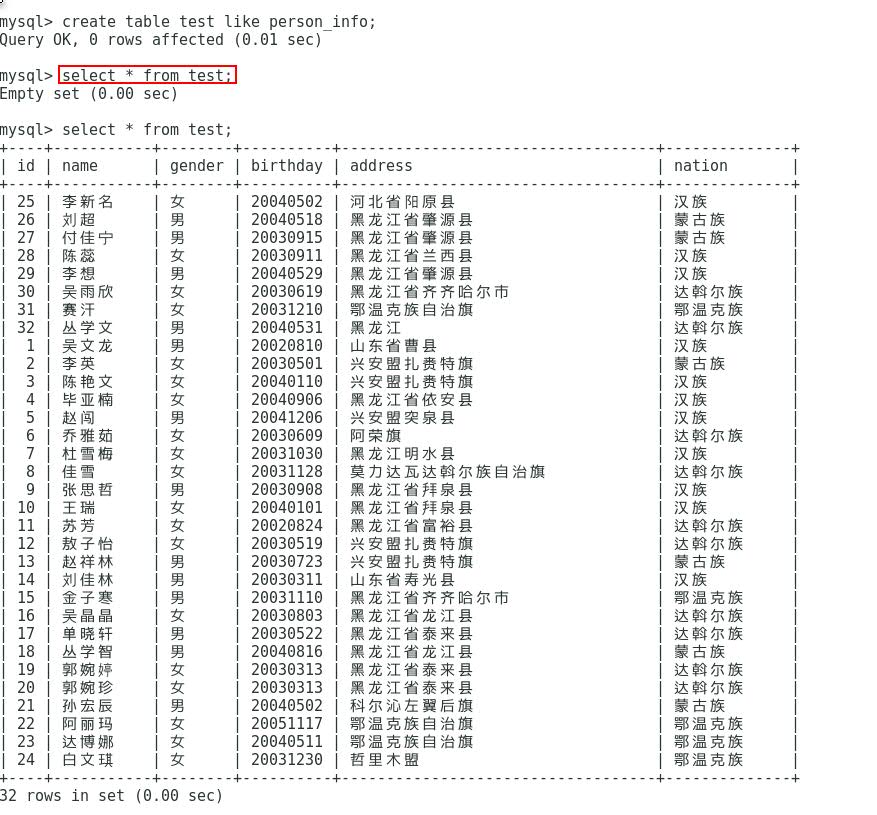
(3)export实战:将HDFS中的Person_info导出到mysql中的test数据表中。最后查看是否导入到了mysql中的TEST_IDS数据表中:
下列如图所视,数据已经导入到mysql 数据库的test表中了。至于为什么id的顺序是错开的,此处不作具体说明。可以通过sqoop的语句指定更详细的数据传输语句来解决这个问题。
2.4 数据导入:Hive->MySQL,MySQL-> Hive
(1)Sqoop的强大之处不仅仅局限与关系型数据库跟HDFS文件系统之间的正反导入导出。也支持大数据仓库Hive到Mysql及Mysql到Hive等的数据传输。接下来看2个案例分别演示mysql --> Hive, Hive -->Mysql的数据传输。至于其他数据库入HBase等的案例在日后学习过程中更新。
案例1: Hive->MySQL
export
--connect
jdbc:mysql://127.0.0.1:3306/liupeng
--username
root
--password
123456
--table
test
--export-dir
/user/hive/warehouse/liupeng.db/test
--fields-terminated-by
'\t'
--num-mappers
1
在此必须提前声明的是--table test 为mysql 中的test 表。而/user/hive/warehouse/liupeng.db/test是HDFS上的路径而不是本地Local的路径。在/user/hive/warehouse/liupeng.db/test目录下必须有文件(hive中的表)。如果没有必须事先通过hadoop的put命令先上传到HDFS文件系统只上。
(2)在 sqoop目录下通过 /bin/sqoop --options-file /opt/datas/sqoop_Demo/test_hive_to_mysql.sql 的方式去运行数据传输。
(3)最终查看数据是否已经成功导入到hive的test 表中。

案例2: MySQL --> Hive
(1) 首先在MySQL中把要准备的数据表准备好
(2) 同样在hive中创建与MySQL数据表字段格式相同的表。(格式必须相同)
因为我们这里还是拿上面Person_info种的数据作例子。因此在hive中要创建相同字段的表格。然后最后用‘\t’的方式指定表格式。
hive> create table person_info(
> id int,
> name string,
> gender string,
> birthday string,
> address string,
> nation string)row format delimited fields terminated by'\t';
(3) 数据准备好之后,把下列语句存放到/opt/datas/sqoop_Demo/mysql_to_hive.sql文件中。方便sqoop目录下bin/sqoop --options-file 命令的调用。
import
--connect
jdbc:mysql://127.0.0.1:3306/liupeng
--username
root
--password
123456
--table
person_test
--fields-terminated-by
'\t'
--delete-target-dir
--num-mappers
1
--hive-import
--hive-database
liupeng
--hive-table
person_info
(4) 查看数据是否已经正常显示在Hive的person_info表中。(此处同样通过Hue的web界面展示)
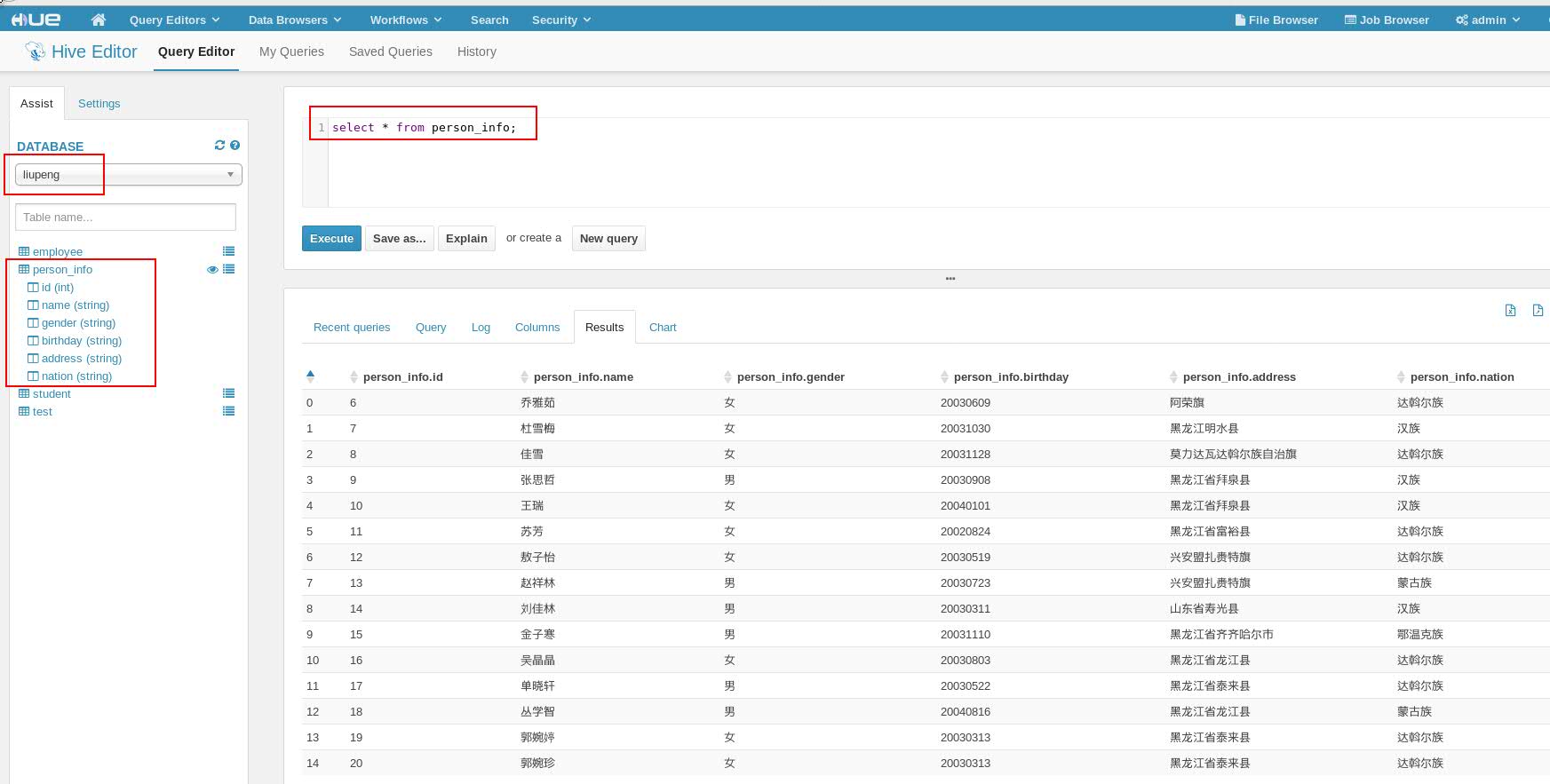
2.5 数据导入:部分字段的导入
(1) 以上的案例已经充分的证明了sqoop功能的强大,当然不光可以实现关系形数据库和Hadoop HDFS,Hive之间的正反数据表的导入导出,同时同MySQL语句一样,也支持部分字段的导入导出。这里只作一个案例展示。
案例:
<1> 同样在/opt/datas/sqoop_Demo目录下准备一个文件,编辑要传输的sqoop语句。此处命名为perinfo_columns_to_HDFS.sql
import
--connect
jdbc:mysql://127.0.0.1:3306/liupeng
--username
root
--password
123456
--table
person_info
--target-dir
/user/liupeng/sqoop/sqlcolumns_to_HDFS/Person_info_test
--num-mappers
1
--columns
id,name,gender,address
<2> 在sqoop目录下执行 bin/sqoop --options-file /opt/datas/sqoop_Demo/perinfo_columns_to_HDFS.sql
<3> 在HDFS文件系统 /user/liupeng/sqoop/sqlcolumns_to_HDFS/Person_info_test目录下查看是否文件被导入进来。此处通过Hue界面展示
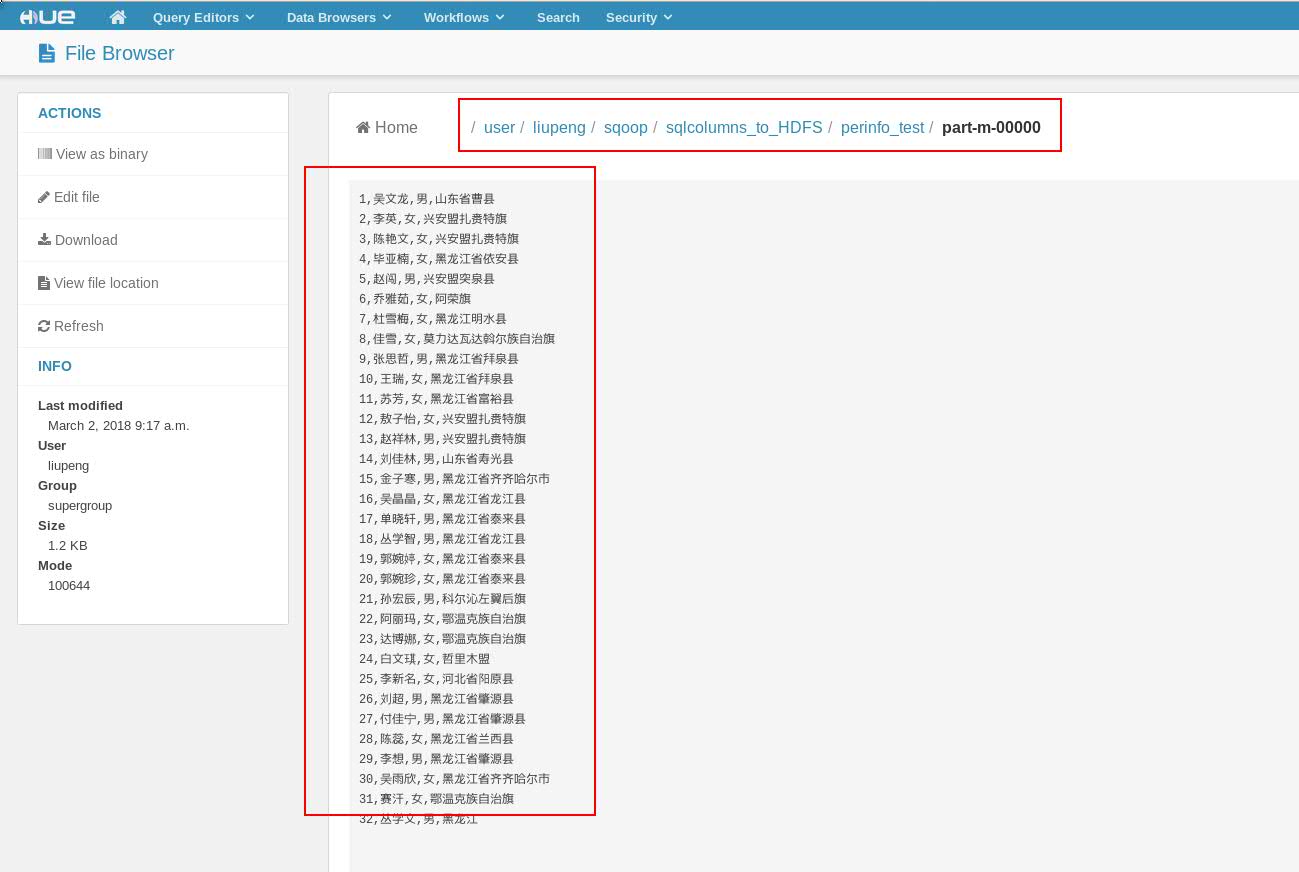
2.6 数据导入:Query
对于上述MySQL数据表部分数据导入到HDFS文件系统上的方法。还可以通过Sqoop 中Query语句方法来实现。而这个方法更像我们MySQL数据中的语句直接来使用。一起看一下下列的案例。
案例
<1> Query 文件的编写。同上目录下创建query_to_HDFS.sql文件并编写语句
import
--connect
jdbc:mysql://127.0.0.1:3306/liupeng
--username
root
--password
123456
--query
select id,name from person_info where $CONDITIONS
--target-dir
/user/liupeng/sqoop/query/Person_info
--num-mappers
1
<2> 同样在Sqoop目录下执行 --options-file 指定该文件
<3> 查看结果(Hue界面下查看)
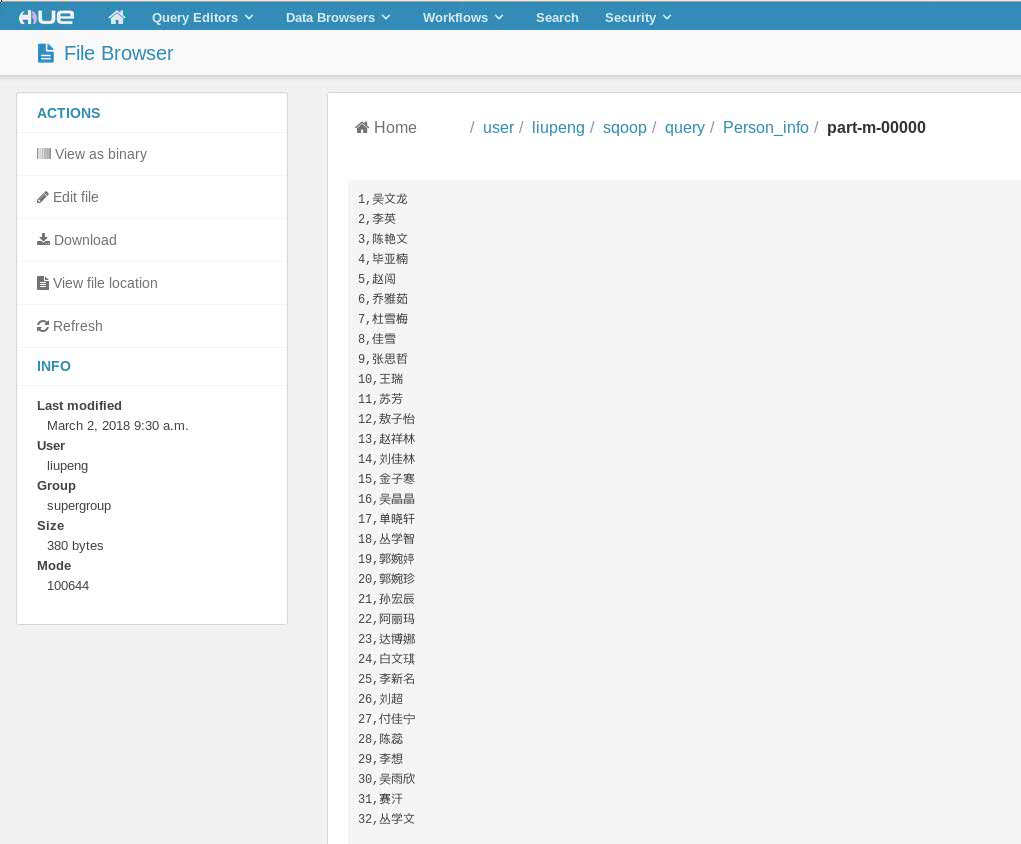
另外补充一句,如果select 语句选择字段同时想要加入where条件的话请在句末添加如下。
import
--connect
jdbc:mysql://127.0.0.1:3306/liupeng
--username
root
--password
123456
--query
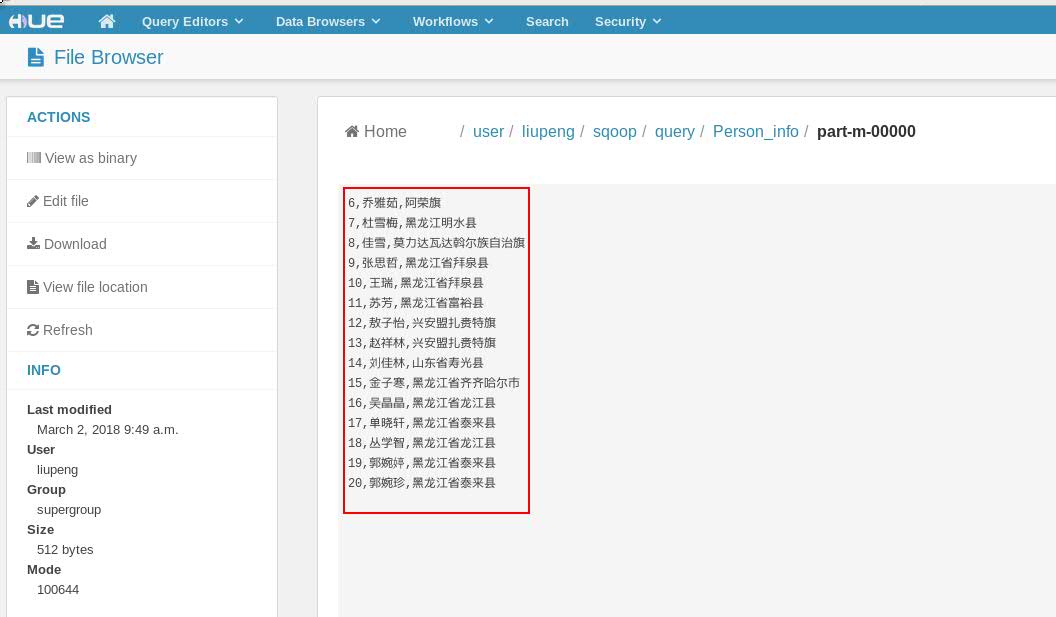
select id,name,address from person_info where $CONDITIONS and id >5 and id<21
--target-dir
/user/liupeng/sqoop/query/Person_info
--num-mappers
1
查看结果
以上为Sqoop的基本命令使用。当然Sqoop的强大功能远不仅如此。实际工作中按照不同的需求来选择不同的方式来进行数据的导入导出。具体细节方法可以参照Sqoop的官网及API。
Sqoop的安装配置及使用的更多相关文章
- 【sqoop】安装配置测试sqoop1
3.1.1 下载sqoop1:sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz 3.1.2 解压并查看目录: [hadoop@hadoop01 ~]$ tar -zxvf sq ...
- hbase-hive整合及sqoop的安装配置使用
从hbase中拿数据,然后整合到hbase中 上hive官网 -- 点击wiki--> hive hbase integation(整合) --> 注意整合的时候两个软件的版本要能进行整 ...
- 大数据之路week07--day06 (Sqoop 的安装及配置)
Sqoop 的安装配置比较简单. 提供安装需要的安装包和连接mysql的驱动的百度云链接: 链接:https://pan.baidu.com/s/1pdFj0u2lZVFasgoSyhz-yQ 提取码 ...
- Sqoop安装配置及数据导入导出
前置条件 已经成功安装配置Hadoop和Mysql数据库服务器,如果将数据导入或从Hbase导出,还应该已经成功安装配置Hbase. 下载sqoop和Mysql的JDBC驱动 sqoop-1.2.0- ...
- sqoop的安装与使用
1.什么是Sqoop Sqoop即 SQL to Hadoop ,是一款方便的在传统型数据库与Hadoop之间进行数据迁移的工具.充分利用MapReduce并行特点以批处理的方式加快传输数据.发展至今 ...
- Hadoop 2.6.0-cdh5.4.0集群环境搭建和Apache-Hive、Sqoop的安装
搭建此环境主要用来hadoop的学习,因此我们的操作直接在root用户下,不涉及HA. Software: Hadoop 2.6.0-cdh5.4.0 Apache-hive-2.1.0-bin Sq ...
- 指导手册 07 安装配置HIVE
指导手册 07 安装配置HIVE 安装环境及所需安装包: 1.操作系统:centos6.8 2.四台虚拟机:master :10.0.2.4, slave1:10.0.2.5,slave2:10. ...
- sqoop的安装
Sqoop是一个用来完成Hadoop和关系型数据库中的数据相互转移的工具, 他可以将关系型数据库(MySql,Oracle,Postgres等)中的数据导入Hadoop的HDFS中, 也可以将HDFS ...
- Hive/Hbase/Sqoop的安装教程
Hive/Hbase/Sqoop的安装教程 HIVE INSTALL 1.下载安装包:https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-2.3 ...
随机推荐
- Android下最小化程序到后台代码
procedure TForm1.Button4Click(Sender: TObject); var Intent: JIntent; begin Intent := TJIntent. ...
- 使用Gardener在Google Cloud Platform上创建Kubernetes集群
Gardener是一个开源项目,github地址: https://github.com/gardener/gardener/ 使用Gardener,我们可以在几分钟之内在GCP, AWS, Azur ...
- Codeforces 396A 数论,组合数学
题意:给一个a数组,求b 数组的方案数,但是要求两者乘积相同. 分析: 不可能将它们乘起来,对于每个数质因数分解,得到每个质因子个数,遍历这些质因子,将某个质因子放到 对应的盒子里面,可以不放,方案数 ...
- 【洛谷P1039】侦探推理
侦探推理 题目链接 这是一道恶心至极的模拟题 我们可以枚举罪犯是谁,今天是星期几,从而判断每个人说的话是真是假 若每个人说的话的真假一致,且说谎话的人数<=k且说真话的人数<=m-k,就是 ...
- js 3秒后跳转页面的实现代码
隔多少秒后自动跳转到其它页(js脚本) 方法一: $(function(){ Load(URL); }) var secs = 3; //倒计时的秒数 var URL = "<?= u ...
- PowerDesign16.6支持Mysql的生成sql脚本中包含Collate信息
当前powerDesign版本:16.6 列上指定:Collation = utf8_general_ci 但是SQL脚本中,列字段没有显示Collect ---------------------- ...
- LeetCode17.电话号码的字母组合 JavaScript
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合. 给出数字到字母的映射如下(与电话按键相同).注意 1 不对应任何字母. 示例: 输入:"23" 输出:[&quo ...
- Vue nodejs商城-订单模块
一.订单列表渲染 新建OrderConfirm.vue订单确认页面,添加路由 src/router/index.js添加路由 import OrderConfirm from '@/views/Ord ...
- Spring知识点总结(三)之注解方式实现IOC和DI
1. 注解概念 所谓注解就是给程序看的提示信息,很多时候都用来作为轻量级配置的方式. 关于注解的知识点,参看java基础课程中java基础加强部分的内容. 2 ...
- c#解析分析SQL语句
最近总结了c#一般的功能,然后自己在博文中写了很多东西.主要是在用途上面.能够解决一些问题.现在分各个组件和方向写完了.主要的内容写了demo,也写了自己的项目组件和模型. 最后一个SQL分析.其实在 ...