sed 很棒的介绍
选项与参数:
-n :使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN 的数据一般都会被列出到终端上。但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来。
-e :直接在命令列模式上进行 sed 的动作编辑;
-f :直接将 sed 的动作写在一个文件内, -f filename 则可以运行 filename 内的 sed 动作;
-r :sed 的动作支持的是延伸型正规表示法的语法。(默认是基础正规表示法语法)
-i :直接修改读取的文件内容,而不是输出到终端。
动作说明: [n1[,n2]]function
n1, n2 :不见得会存在,一般代表『选择进行动作的行数』,举例来说,如果我的动作是需要在 10 到 20 行之间进行的,则『 10,20[动作行为] 』
function:
a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
p :列印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦!
用s命令替换
我使用下面的这段文本做演示:
|
1
2
3
4
5
6
7
8
9
|
$ cat pets.txtThis is my cat my cat's name is bettyThis is my dog my dog's name is frankThis is my fish my fish's name is georgeThis is my goat my goat's name is adam |
把其中的my字符串替换成Hao Chen’s,下面的语句应该很好理解(s表示替换命令,/my/表示匹配my,/Hao Chen’s/表示把匹配替换成Hao Chen’s,/g 表示一行上的替换所有的匹配):
|
1
2
3
4
5
6
7
8
9
|
$ sed "s/my/Hao Chen's/g" pets.txtThis is Hao Chen's cat Hao Chen's cat's name is bettyThis is Hao Chen's dog Hao Chen's dog's name is frankThis is Hao Chen's fish Hao Chen's fish's name is georgeThis is Hao Chen's goat Hao Chen's goat's name is adam |
注意:如果你要使用单引号,那么你没办法通过\’这样来转义,就有双引号就可以了,在双引号内可以用\”来转义。
再注意:上面的sed并没有对文件的内容改变,只是把处理过后的内容输出,如果你要写回文件,你可以使用重定向,如:
|
1
|
$ sed "s/my/Hao Chen's/g" pets.txt > hao_pets.txt |
或使用 -i 参数直接修改文件内容:
|
1
|
$ sed -i "s/my/Hao Chen's/g" pets.txt |
在每一行最前面加点东西:
|
1
2
3
4
5
6
7
8
9
|
$ sed 's/^/#/g' pets.txt#This is my cat# my cat's name is betty#This is my dog# my dog's name is frank#This is my fish# my fish's name is george#This is my goat# my goat's name is adam |
在每一行最后面加点东西:
|
1
2
3
4
5
6
7
8
9
|
$ sed 's/$/ --- /g' pets.txtThis is my cat --- my cat's name is betty ---This is my dog --- my dog's name is frank ---This is my fish --- my fish's name is george ---This is my goat --- my goat's name is adam --- |
顺手介绍一下正则表达式的一些最基本的东西:
^表示一行的开头。如:/^#/以#开头的匹配。$表示一行的结尾。如:/}$/以}结尾的匹配。\<表示词首。 如:\<abc表示以 abc 为首的詞。\>表示词尾。 如:abc\>表示以 abc 結尾的詞。.表示任何单个字符。*表示某个字符出现了0次或多次。[ ]字符集合。 如:[abc]表示匹配a或b或c,还有[a-zA-Z]表示匹配所有的26个字符。如果其中有^表示反,如[^a]表示非a的字符
正规则表达式是一些很牛的事,比如我们要去掉某html中的tags:
|
1
|
<b>This</b> is what <span style="text-decoration: underline;">I</span> meant. Understand? |
看看我们的sed命令
|
1
2
3
4
5
6
7
8
|
# 如果你这样搞的话,就会有问题$ sed 's/<.*>//g' html.txt Understand?# 要解决上面的那个问题,就得像下面这样。# 其中的'[^>]' 指定了除了>的字符重复0次或多次。$ sed 's/<[^>]*>//g' html.txtThis is what I meant. Understand? |
我们再来看看指定需要替换的内容:
|
1
2
3
4
5
6
7
8
9
|
$ sed "3s/my/your/g" pets.txtThis is my cat my cat's name is bettyThis is your dog my dog's name is frankThis is my fish my fish's name is georgeThis is my goat my goat's name is adam |
下面的命令只替换第3到第6行的文本。
|
1
2
3
4
5
6
7
8
9
|
$ sed "3,6s/my/your/g" pets.txtThis is my cat my cat's name is bettyThis is your dog your dog's name is frankThis is your fish your fish's name is georgeThis is my goat my goat's name is adam |
|
1
2
3
4
5
|
$ cat my.txtThis is my cat, my cat's name is bettyThis is my dog, my dog's name is frankThis is my fish, my fish's name is georgeThis is my goat, my goat's name is adam |
只替换每一行的第一个s:
|
1
2
3
4
5
|
$ sed 's/s/S/1' my.txtThiS is my cat, my cat's name is bettyThiS is my dog, my dog's name is frankThiS is my fish, my fish's name is georgeThiS is my goat, my goat's name is adam |
只替换每一行的第二个s:
|
1
2
3
4
5
|
$ sed 's/s/S/2' my.txtThis iS my cat, my cat's name is bettyThis iS my dog, my dog's name is frankThis iS my fish, my fish's name is georgeThis iS my goat, my goat's name is adam |
只替换第一行的第3个以后的s:
|
1
2
3
4
5
|
$ sed 's/s/S/3g' my.txtThis is my cat, my cat'S name iS bettyThis is my dog, my dog'S name iS frankThis is my fiSh, my fiSh'S name iS georgeThis is my goat, my goat'S name iS adam |
多个匹配
如果我们需要一次替换多个模式,可参看下面的示例:(第一个模式把第一行到第三行的my替换成your,第二个则把第3行以后的This替换成了That)
|
1
2
3
4
5
|
$ sed '1,3s/my/your/g; 3,$s/This/That/g' my.txtThis is your cat, your cat's name is bettyThis is your dog, your dog's name is frankThat is your fish, your fish's name is georgeThat is my goat, my goat's name is adam |
上面的命令等价于:(注:下面使用的是sed的-e命令行参数)
|
1
|
sed -e '1,3s/my/your/g' -e '3,$s/This/That/g' my.txt |
我们可以使用&来当做被匹配的变量,然后可以在基本左右加点东西。如下所示:
|
1
2
3
4
5
|
$ sed 's/my/[&]/g' my.txtThis is [my] cat, [my] cat's name is bettyThis is [my] dog, [my] dog's name is frankThis is [my] fish, [my] fish's name is georgeThis is [my] goat, [my] goat's name is adam |
圆括号匹配
使用圆括号匹配的示例:(圆括号括起来的正则表达式所匹配的字符串会可以当成变量来使用,sed中使用的是\1,\2…)
|
1
2
3
4
5
|
$ sed 's/This is my \([^,&]*\),.*is \(.*\)/\1:\2/g' my.txtcat:bettydog:frankfish:georgegoat:adam |
上面这个例子中的正则表达式有点复杂,解开如下(去掉转义字符):
正则为:This is my ([^,]*),.*is (.*)
匹配为:This is my (cat),……….is (betty)
然后:\1就是cat,\2就是betty
sed的命令
让我们回到最一开始的例子pets.txt,让我们来看几个命令:
N命令
先来看N命令 —— 把下一行的内容纳入当成缓冲区做匹配。
下面的的示例会把原文本中的偶数行纳入奇数行匹配,而s只匹配并替换一次,所以,就成了下面的结果:
|
1
2
3
4
5
6
7
8
9
|
$ sed 'N;s/my/your/' pets.txtThis is your cat my cat's name is bettyThis is your dog my dog's name is frankThis is your fish my fish's name is georgeThis is your goat my goat's name is adam |
也就是说,原来的文件成了:
|
1
2
3
4
|
This is my cat\n my cat's name is bettyThis is my dog\n my dog's name is frankThis is my fish\n my fish's name is georgeThis is my goat\n my goat's name is adam |
这样一来,下面的例子你就明白了,
|
1
2
3
4
5
|
$ sed 'N;s/\n/,/' pets.txtThis is my cat, my cat's name is bettyThis is my dog, my dog's name is frankThis is my fish, my fish's name is georgeThis is my goat, my goat's name is adam |
a命令和i命令
a命令就是append, i命令就是insert,它们是用来添加行的。如:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# 其中的1i表明,其要在第1行前插入一行(insert)$ sed "1 i This is my monkey, my monkey's name is wukong" my.txtThis is my monkey, my monkey's name is wukongThis is my cat, my cat's name is bettyThis is my dog, my dog's name is frankThis is my fish, my fish's name is georgeThis is my goat, my goat's name is adam# 其中的1a表明,其要在最后一行后追加一行(append)$ sed "$ a This is my monkey, my monkey's name is wukong" my.txtThis is my cat, my cat's name is bettyThis is my monkey, my monkey's name is wukongThis is my dog, my dog's name is frankThis is my fish, my fish's name is georgeThis is my goat, my goat's name is adam |
我们可以运用匹配来添加文本:
|
1
2
3
4
5
6
7
|
# 注意其中的/fish/a,这意思是匹配到/fish/后就追加一行$ sed "/fish/a This is my monkey, my monkey's name is wukong" my.txtThis is my cat, my cat's name is bettyThis is my dog, my dog's name is frankThis is my fish, my fish's name is georgeThis is my monkey, my monkey's name is wukongThis is my goat, my goat's name is adam |
下面这个例子是对每一行都挺插入:
|
1
2
3
4
5
6
7
8
9
|
$ sed "/my/a ----" my.txtThis is my cat, my cat's name is betty----This is my dog, my dog's name is frank----This is my fish, my fish's name is george----This is my goat, my goat's name is adam---- |
c命令
c 命令是替换匹配行
|
1
2
3
4
5
6
7
8
9
10
11
|
$ sed "2 c This is my monkey, my monkey's name is wukong" my.txtThis is my cat, my cat's name is bettyThis is my monkey, my monkey's name is wukongThis is my fish, my fish's name is georgeThis is my goat, my goat's name is adam$ sed "/fish/c This is my monkey, my monkey's name is wukong" my.txtThis is my cat, my cat's name is bettyThis is my dog, my dog's name is frankThis is my monkey, my monkey's name is wukongThis is my goat, my goat's name is adam |
d命令
删除匹配行
|
1
2
3
4
5
6
7
8
9
10
11
12
|
$ sed '/fish/d' my.txtThis is my cat, my cat's name is bettyThis is my dog, my dog's name is frankThis is my goat, my goat's name is adam$ sed '2d' my.txtThis is my cat, my cat's name is bettyThis is my fish, my fish's name is georgeThis is my goat, my goat's name is adam$ sed '2,$d' my.txtThis is my cat, my cat's name is betty |
shell 查看 具体某行的值
sed:
查看第5行
sed '5!d' file
查看5-7行
sed '5,7!d' file
或者使用
sed -n '5,7p' filename 这样你就可以只查看文件的第5行到第7行。
p命令
打印命令
你可以把这个命令当成grep式的命令
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# 匹配fish并输出,可以看到fish的那一行被打了两遍,# 这是因为sed处理时会把处理的信息输出$ sed '/fish/p' my.txtThis is my cat, my cat's name is bettyThis is my dog, my dog's name is frankThis is my fish, my fish's name is georgeThis is my fish, my fish's name is georgeThis is my goat, my goat's name is adam# 使用n参数就好了$ sed -n '/fish/p' my.txtThis is my fish, my fish's name is george# 从一个模式到另一个模式$ sed -n '/dog/,/fish/p' my.txtThis is my dog, my dog's name is frankThis is my fish, my fish's name is george#从第一行打印到匹配fish成功的那一行$ sed -n '1,/fish/p' my.txtThis is my cat, my cat's name is bettyThis is my dog, my dog's name is frankThis is my fish, my fish's name is george |
几个知识点
好了,下面我们要介绍四个sed的基本知识点:
Pattern Space
第零个是关于-n参数的,大家也许没看懂,没关系,我们来看一下sed处理文本的伪代码,并了解一下Pattern Space的概念:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
foreach line in file { //放入把行Pattern_Space Pattern_Space <= line; // 对每个pattern space执行sed命令 Pattern_Space <= EXEC(sed_cmd, Pattern_Space); // 如果没有指定 -n 则输出处理后的Pattern_Space if (sed option hasn't "-n") { print Pattern_Space }} |
Address
第一个是关于address,几乎上述所有的命令都是这样的(注:其中的!表示匹配成功后是否执行命令)
[address[,address]][!]{cmd}
address可以是一个数字,也可以是一个模式,你可以通过逗号要分隔两个address 表示两个address的区间,参执行命令cmd,伪代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
bool bexec = falseforeach line in file { if ( match(address1) ){ bexec = true; } if ( bexec == true) { EXEC(sed_cmd); } if ( match (address2) ) { bexec = false; }} |
关于address可以使用相对位置,如:
|
1
2
3
4
5
6
7
8
9
10
|
# 其中的+3表示后面连续3行$ sed '/dog/,+3s/^/# /g' pets.txtThis is my cat my cat's name is betty# This is my dog# my dog's name is frank# This is my fish# my fish's name is georgeThis is my goat my goat's name is adam |
命令打包
第二个是cmd可以是多个,它们可以用分号分开,可以用大括号括起来作为嵌套命令。下面是几个例子:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
$ cat pets.txtThis is my cat my cat's name is bettyThis is my dog my dog's name is frankThis is my fish my fish's name is georgeThis is my goat my goat's name is adam# 对3行到第6行,执行命令/This/d$ sed '3,6 {/This/d}' pets.txtThis is my cat my cat's name is betty my dog's name is frank my fish's name is georgeThis is my goat my goat's name is adam# 对3行到第6行,匹配/This/成功后,再匹配/fish/,成功后执行d命令$ sed '3,6 {/This/{/fish/d}}' pets.txtThis is my cat my cat's name is bettyThis is my dog my dog's name is frank my fish's name is georgeThis is my goat my goat's name is adam# 从第一行到最后一行,如果匹配到This,则删除之;如果前面有空格,则去除空格$ sed '1,${/This/d;s/^ *//g}' pets.txtmy cat's name is bettymy dog's name is frankmy fish's name is georgemy goat's name is adam |
Hold Space
第三个我们再来看一下 Hold Space
接下来,我们需要了解一下Hold Space的概念,我们先来看四个命令:
g: 将hold space中的内容拷贝到pattern space中,原来pattern space里的内容清除
G: 将hold space中的内容append到pattern space\n后
h: 将pattern space中的内容拷贝到hold space中,原来的hold space里的内容被清除
H: 将pattern space中的内容append到hold space\n后
x: 交换pattern space和hold space的内容
这些命令有什么用?我们来看两个示例吧,用到的示例文件是:
|
1
2
3
4
|
$ cat t.txtonetwothree |
第一个示例:
|
1
2
3
4
5
6
7
8
9
|
$ sed 'H;g' t.txtoneonetwoonetwothree |
是不是有点没看懂,我作个图你就看懂了。
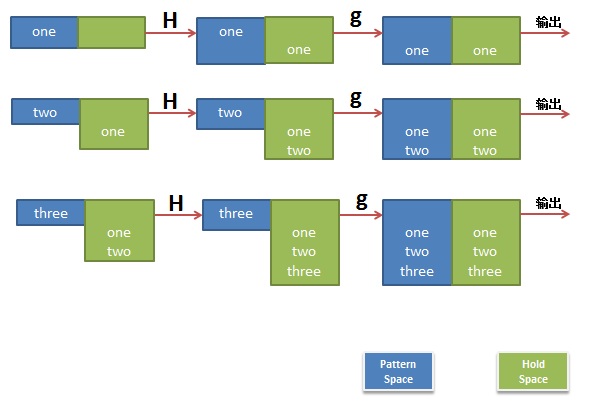
第二个示例,反序了一个文件的行:
|
1
2
3
4
|
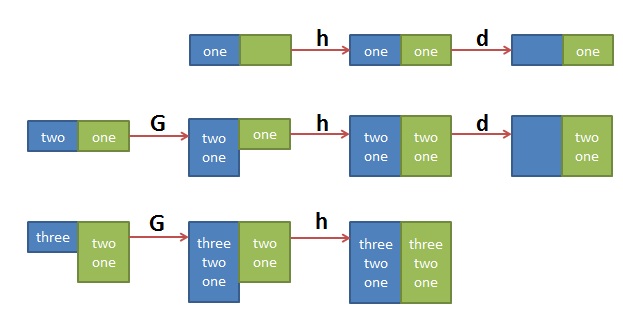
$ sed '1!G;h;$!d' t.txtthreetwoone |
其中的 ‘1!G;h;$!d’ 可拆解为三个命令
- 1!G —— 只有第一行不执行G命令,将hold space中的内容append回到pattern space
- h —— 第一行都执行h命令,将pattern space中的内容拷贝到hold space中
- $!d —— 除了最后一行不执行d命令,其它行都执行d命令,删除当前行
这个执行序列很难理解,做个图如下大家就明白了:
sed 很棒的介绍的更多相关文章
- 介绍一种很棒的wince 如何替换系统声音的方法
Topic:介绍一种很棒的wince 如何替换系统声音的方法(作者:Baiduluckyboy) //------------------------------------------------- ...
- IOS学习资源收集--关于动画的代码学习资源总汇(很棒的动画效果哦)
目录大纲: 1.很棒的iOS加载动画. github网址:https://github.com/NghiaTranUIT/FeSpinner 游老师的译文blog:http://www.cnblogs ...
- EasyDropDown – 很棒的下拉菜单,含精美主题
EasyDropDown 是一个 jQuery 插件,你可以毫不费力地将简陋的 Select 元素设置为可定制风格的下拉菜单,用于表单或者一般的导航.和著名的下拉插件 Chosen 很像,但是具有自己 ...
- 优秀工具推荐:两款很棒的 HTML5 游戏开发工具
HTML5 众多强大特性让我们不需要多么高深技术就能创建好玩的网页游戏,同时证明了开放的 Web 技术能与任何其他在游戏开发中使用的技术竞争.正如标题所说,这篇文章推荐的几款很棒 HTML5 游戏开发 ...
- 10个很棒的学习Android 开发的网站(转)
看到江湖旅人 写的<10个很棒的学习iOS开发的网站 - 简书>,所以就忍不住写Android 啦,也希望对大家有帮助.我推荐的网站,都是我在学习Android 开发过程中发现的好网站,给 ...
- 推荐几款很棒的 JavaScript 表单美化和验证插件
表单元素让人爱恨交加.作为网页最重要的组成部分,表单几乎无处不在,从简单的邮件订阅.登陆注册到复杂的需要多页填写的信息提交功能,表单都让开发者花费了大量的时间和精力去处理,以期实现好用又漂亮的表单功能 ...
- 30 个很棒的 PHP 开源 CMS 内容管理系统
本文汇集了30个优秀的开源CMS建站系统,采用PHP开发.以下列表不分先后顺序. 1. AdaptCMS AdaptCMS Lite 是一个开源的CMS系统,主要特点是易用,而且可以轻松和其他系统接驳 ...
- 21个很棒的jQuery分页插件下载
分页是指将一个大内容划分为各种不同的页面,因此网站的分页是一个很重要的部分,必须让内容有组织性和易于访问.分页有各两种不同的方式,手动跟自动.最受欢迎简单和广泛的方法是jQuery插件.下面我们收集了 ...
- 50个很棒的Python模块
50个很棒的Python模块 我很喜欢Python,Python具有强大的扩展能力,我列出了50个很棒的Python模块,包含几乎所有的需要:比如Databases,GUIs,Images, Soun ...
随机推荐
- 洛谷P1273 有线电视网 (树上分组背包)
洛谷P1273 有线电视网 题目描述 某收费有线电视网计划转播一场重要的足球比赛.他们的转播网和用户终端构成一棵树状结构,这棵树的根结点位于足球比赛的现场,树叶为各个用户终端,其他中转站为该树的内部节 ...
- 解析json方式之net.sf.json
前面转载了json解析的技术:fastjson,今天说下另外一种技术. 下载地址 本次使用版本:http://sourceforge.net/projects/json-lib/files/json- ...
- Grep basic and practice
定义:Grep (Globally search for the reqular expression and print out the line). 好处:Grep 在执行时不需要先调用编辑程序, ...
- video视频在结束之后回到初始状态
目前尝试了两种解决方案,但是方案1在安卓移动端无法生效(猜测是因为移动端安卓启动的是原生的视频播放控件的原因) 方案一: 重新load资源,这种方法比较简洁,但是在安卓下不适用 video.addEv ...
- MVC前台获取ViewData的数组中的值
查了一上午资料,找到了一种比较有效的方法 后台控制器:public ActionResult Index() { List<string> colors = new List<str ...
- 51nod1031(简单斐波拉契数列)
题目链接:https://www.51nod.com/onlineJudge/questionCode.html#!problemId=1031 题意:中文题诶- 思路:对于第x块骨牌的情况,我们用a ...
- hive的体系架构及安装
1,什么是Hive? Hive是能够用类SQL的方式操作HDFS里面数据一个数据仓库的框架,这个类SQL我们称之为HQL(Hive Query Language) 2,什么是数据仓库? 存放数据的地方 ...
- DOM创建和删除节点
一.创建节点 3步 1.创建空元素对象: var newElem=document.createElement("标签名"); 例如:var a=document.createEl ...
- bzoj 2330 SCOI2011糖果 查分约束系统
就根据题目中给的约束条件建图就行了 需要注意的是,我们要做的是最长路,因为需要约束每个点都是大于0 那么可以建一个超级源指向所有点,超级源的dis是1,边长为0 那么这样做最长路就可以了 好了我们这么 ...
- hdu 1518 Square(深搜+剪枝)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1518 题目大意:根据题目所给的几条边,来判断是否能构成正方形,一个很好的深搜应用,注意剪枝,以防超时! ...