Beautiful用法总结





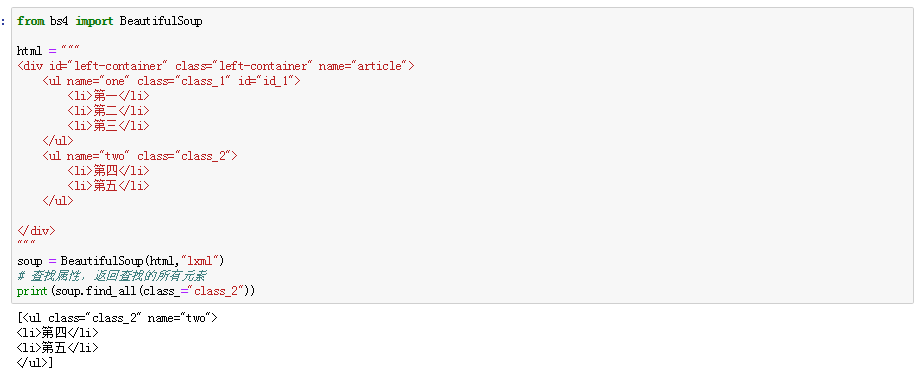
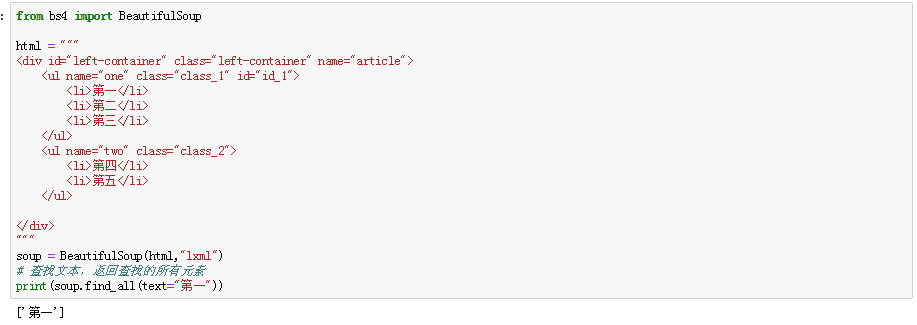



Beautiful用法总结的更多相关文章
- Python之Beautiful Soup的用法
1. Beautiful Soup的简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.pyt ...
- Python爬虫利器二之Beautiful Soup的用法
上一节我们介绍了正则表达式,它的内容其实还是蛮多的,如果一个正则匹配稍有差池,那可能程序就处在永久的循环之中,而且有的小伙伴们也对写正则表达式的写法用得不熟练,没关系,我们还有一个更强大的工具,叫Be ...
- python beautiful soup库的超详细用法
原文地址https://blog.csdn.net/love666666shen/article/details/77512353 参考文章https://cuiqingcai.com/1319.ht ...
- python爬虫(7)--Beautiful Soup的用法
1.Beautiful Soup简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据. Beautiful Soup提供一些简单的.python式的函数用来 ...
- Beautiful Soup库基础用法(爬虫)
初识Beautiful Soup 官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/# 中文文档:https://www.crumm ...
- Beautiful Soup的用法
BEAUTIFUL SOUP的介绍 就是一个非常好用.漂亮.牛逼的第三方库,是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖析树(parse tree). 它提供简 ...
- python 爬虫5 Beautiful Soup的用法
1.创建 Beautiful Soup 对象 from bs4 import BeautifulSoup html = """ <html><head& ...
- Python爬虫利器之Beautiful Soup,Requests,正则的用法(转)
https://cuiqingcai.com/1319.html https://cuiqingcai.com/2556.html https://cuiqingcai.com/977.html
- Beautiful Soup的用法(五):select的使用
原文地址:http://www.bugingcode.com/blog/beautiful_soup_select.html select 的功能跟find和find_all 一样用来选取特定的标签, ...
随机推荐
- servlet(6) 链接数据库
一.servlet链接mysql步骤: 1.注册驱动器:Class.forName("com.mysql.jdbc.Driver"); 加载类并执行下面的静态语句块,将Driver ...
- [算法]浅谈求n范围以内的质数(素数)
汗颜,数学符号表达今天才学会呀-_-# 下面是百度百科对质数的定义 质数(prime number)又称素数,有无限个. 质数定义为在大于1的自然数中,除了1和它本身以外不再有其他因数. 求质数的方法 ...
- dp-棋盘形dp
luogu类似题很多的. P1006 传纸条 有不少做法.这里提一个三维做法. 找两条路,可以模拟为有两个人同从(1,1)走到(m,n),走不同的路. 设有k步,则显然2<=k<m+n ( ...
- k8s集群Canal的网络控制 原
1 简介 直接上干货 public class DispatcherServlet extends HttpServlet { private Properties contextConfigProp ...
- vue+typescript基础练习
环境 win10 node -v 8.9.3 vue-cli 3.4 typescript 3.1.5 编辑器 vscode 目标 使用vuecli工具,建立一个项目,使用typescript.并实现 ...
- [Windows Doc]微软官方文档
desktop: https://docs.microsoft.com/en-us/windows/desktop/index server:https://docs.microsoft.com/en ...
- jmeter笔记(8)--关联
关联是jmeter中比较重要的一个点,在测试过程中有些数据是经常发生变化的,要获取这些数据,就需要使用关联,Jmeter可以通过“后置处理器”中的“正则表达式提取器”来处理关联.. 正则表达式提取器 ...
- js下拉框:从数组中筛选出匹配的数据
handleChange(val) { let obj = {} // 遍历数组 obj = this.options.find(item => { // 筛选出匹配的数据 return ite ...
- DirectX11--实现一个3D魔方(3)
前言 (2019/1/9 09:23)上一章我们主要讲述了魔方的旋转,这个旋转真是有毒啊,搞完这个部分搭键鼠操作不到半天应该就可以搭完了吧... (2019/1/9 21:25)啊,真香 有人发这张图 ...
- mysqldump 备份数据和恢复
命令行下具体用法如下: mysqldump -u用戶名 -p密码 -d 数据库名 表名 > 脚本名; 一.导出数据: 导出整个数据库结构和数据mysqldump -h localhost -u ...