Python学习笔记,day4
Python学习第四天
一、装饰器
函数调用顺序:
其他高级语言类似,Python 不允许在函数未声明之前,对其进行引用或者调用
高阶函数:
满足下列条件之一就可成函数为高阶函数
某一函数当做参数传入另一个函数中
函数的返回值包含n个函数,n>0
内嵌函数和变量作用域:
定义:在一个函数体内创建另外一个函数,这种函数就叫内嵌函数(基于python支持静态嵌套域)
闭包:
如果在一个内部函数里,对在外部作用域(但不是在全局作用域)的变量进行引用,那么内部函数就被认为是 closure
内嵌函数+高阶函数+闭包=》装饰器
范例一:函数参数固定
def decorartor(func):
def wrapper(n):
print 'starting'
func(n)
print 'stopping'
return wrapper def test(n):
print 'in the test arg is %s' %n decorartor(test)('alex')
范例二:函数参数不固定
def decorartor(func):
def wrapper(*args,**kwargs):
print 'starting'
func(*args,**kwargs)
print 'stopping'
return wrapper def test(n,x=1):
print 'in the test arg is %s' %n decorartor(test)('alex',x=2)
范例三:无参装饰器
import time
def decorator(func):
def wrapper(*args,**kwargs):
start=time.time()
func(*args,**kwargs)
stop=time.time()
print 'run time is %s ' %(stop-start)
print timeout
return wrapper @decorator
def test(list_test):
for i in list_test:
time.sleep(0.1)
print '-'*20,i #decorator(test)(range(10))
test(range(10))
范例四:有参装饰器
import time
def timer(timeout=0):
def decorator(func):
def wrapper(*args,**kwargs):
start=time.time()
func(*args,**kwargs)
stop=time.time()
print 'run time is %s ' %(stop-start)
print timeout
return wrapper
return decorator
@timer(2)
def test(list_test):
for i in list_test:
time.sleep(0.1)
print '-'*20,i #timer(timeout=10)(test)(range(10))
test(range(10))
二、生成器
1、列表生成式
>>> a = [i+1 for i in range(10)]
>>> a
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
2、生成器
通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。
要创建一个generator,有很多种方法。第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个generator:
>>> L = [x * x for x in range(10)]
>>> L
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> g = (x * x for x in range(10))
>>> g
<generator object <genexpr> at 0x1022ef630>
斐波拉契数列用列表生成式写不出来,但是,用函数把它打印出来却很容易:
def fib(max):
n, a, b = 0, 0, 1
while n < max:
print(b)
a, b = b, a + b
n = n + 1
return 'done'
仔细观察,可以看出,fib函数实际上是定义了斐波拉契数列的推算规则,可以从第一个元素开始,推算出后续任意的元素,这种逻辑其实非常类似generator。
也就是说,上面的函数和generator仅一步之遥。要把fib函数变成generator,只需要把print(b)改为yield b就可以了:
def fib(max):
n,a,b = 0,0,1 while n < max:
#print(b)
yield b
a,b = b,a+b n += 1 return 'done'
这就是定义generator的另一种方法。如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator:
>>> f = fib(6)
>>> f
<generator object fib at 0x104feaaa0>
这里,最难理解的就是generator和函数的执行流程不一样。函数是顺序执行,遇到return语句或者最后一行函数语句就返回。而变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
data = fib(10)
print(data) print(data.__next__())
print(data.__next__())
print("干点别的事")
print(data.__next__())
print(data.__next__())
print(data.__next__())
print(data.__next__())
print(data.__next__()) #输出
<generator object fib at 0x101be02b0>
1
干点别的事
3
8
但是用for循环调用generator时,发现拿不到generator的return语句的返回值。如果想要拿到返回值,必须捕获StopIteration错误,返回值包含在StopIteration的value中:
>>> g = fib(6)
>>> while True:
... try:
... x = next(g)
... print('g:', x)
... except StopIteration as e:
... print('Generator return value:', e.value)
... break
...
g: 1
g: 1
g: 2
g: 3
g: 5
g: 8
Generator return value: done
三、迭代器
我们已经知道,可以直接作用于for循环的数据类型有以下几种:
一类是集合数据类型,如list、tuple、dict、set、str等;
一类是generator,包括生成器和带yield的generator function。
这些可以直接作用于for循环的对象统称为可迭代对象:Iterable。
可以使用isinstance()判断一个对象是否是Iterable对象
>>> from collections import Iterable
>>> isinstance([], Iterable)
True
>>> isinstance({}, Iterable)
True
>>> isinstance('abc', Iterable)
True
>>> isinstance((x for x in range(10)), Iterable)
True
>>> isinstance(100, Iterable)
False
*可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
可以使用isinstance()判断一个对象是否是Iterator对象: >>> from collections import Iterator
>>> isinstance((x for x in range(10)), Iterator)
True
>>> isinstance([], Iterator)
False
>>> isinstance({}, Iterator)
False
>>> isinstance('abc', Iterator)
False
生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。
把list、dict、str等Iterable变成Iterator可以使用iter()函数:
>>> isinstance(iter([]), Iterator)
True
>>> isinstance(iter('abc'), Iterator)
True
你可能会问,为什么list、dict、str等数据类型不是Iterator?
这是因为Python的Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
Iterator甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。
小结
凡是可作用于for循环的对象都是Iterable类型;
凡是可作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列;
集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
Python的for循环本质上就是通过不断调用next()函数实现的,例如:
for x in [1, 2, 3, 4, 5]:
pass
实际上完全等价于:
# 首先获得Iterator对象:
it = iter([1, 2, 3, 4, 5])
# 循环:
while True:
try:
# 获得下一个值:
x = next(it)
except StopIteration:
# 遇到StopIteration就退出循环
break
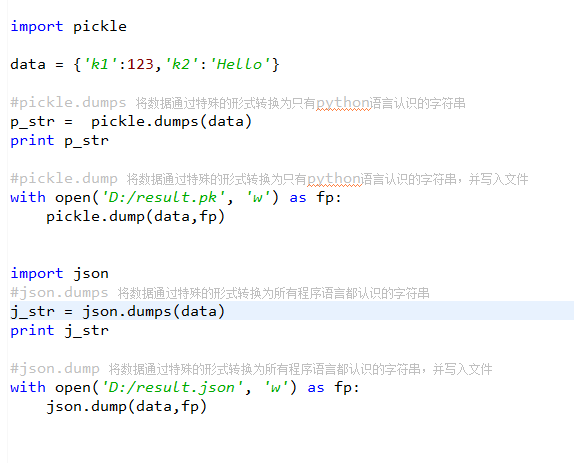
四、json&pickle序列化
用于序列化的两个模块
- json,用于字符串 和 python数据类型间进行转换
- pickle,用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
五、目录开发规范
假设你的项目名为foo:
Foo/
|-- bin/
| |-- foo
|
|-- foo/
| |-- tests/
| | |-- __init__.py
| | |-- test_main.py
| |
| |-- __init__.py
| |-- main.py
|
|-- docs/
| |-- conf.py
| |-- abc.rst
|
|-- setup.py
|-- requirements.txt
|-- README
简要解释一下:
bin/: 存放项目的一些可执行文件,当然你可以起名script/之类的也行。foo/: 存放项目的所有源代码。(1) 源代码中的所有模块、包都应该放在此目录。不要置于顶层目录。(2) 其子目录tests/存放单元测试代码; (3) 程序的入口最好命名为main.py。docs/: 存放一些文档。setup.py: 安装、部署、打包的脚本。requirements.txt: 存放软件依赖的外部Python包列表。README: 项目说明文件。
关于README的内容
目的是能简要描述该项目的信息,让读者快速了解这个项目。
它需要说明以下几个事项:
- 软件定位,软件的基本功能。
- 运行代码的方法: 安装环境、启动命令等。
- 简要的使用说明。
- 代码目录结构说明,更详细点可以说明软件的基本原理。
- 常见问题说明。
Python学习笔记,day4的更多相关文章
- Python学习笔记 - day4 - 流程控制
Python流程控制 Python中的流程控制主要包含两部分:条件判断和循环. Python的缩进和语法 为什么要在这里说缩进和语法,是因为将要学习的条件判断和分支将会涉及到多行代码,在java.c等 ...
- Python学习笔记——Day4
字符串操作 string典型的内置方法: count() center() startswith() find() format() lower() upper() strip() replace() ...
- python学习笔记-Day4(2)
正则表达式 语法: import re #导入模块名 p = re.compile("^[0-9]") #生成要匹配的正则对象 , ^代表从开头匹配,[0-9]代表匹配0至9的任意 ...
- python学习笔记-day4笔记 常用内置函数与装饰器
1.常用的python函数 abs 求绝对值 all 判断迭代器中所有的数据是否为真或者可迭代数据为空,返回真,否则返回假 any ...
- python学习笔记 Day4
1.函数返回值分析 li = [1,2,3,4] li2 = [1,2,3,4] def f1(args): args.append(55) li = f1(li) print(li) f1(li2) ...
- python学习笔记-Day4(1)
迭代器 迭代器是访问集合元素的一种方式.迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束.迭代器只能往前不会后退,不过这也没什么,因为人们很少在迭代途中往后退.另外,迭代器的一大优点是 ...
- 【目录】Python学习笔记
目录:Python学习笔记 目标:坚持每天学习,每周一篇博文 1. Python学习笔记 - day1 - 概述及安装 2.Python学习笔记 - day2 - PyCharm的基本使用 3.Pyt ...
- python学习笔记整理——字典
python学习笔记整理 数据结构--字典 无序的 {键:值} 对集合 用于查询的方法 len(d) Return the number of items in the dictionary d. 返 ...
- VS2013中Python学习笔记[Django Web的第一个网页]
前言 前面我简单介绍了Python的Hello World.看到有人问我搞搞Python的Web,一时兴起,就来试试看. 第一篇 VS2013中Python学习笔记[环境搭建] 简单介绍Python环 ...
- python学习笔记之module && package
个人总结: import module,module就是文件名,导入那个python文件 import package,package就是一个文件夹,导入的文件夹下有一个__init__.py的文件, ...
随机推荐
- Problem after converting keras model into Tensorflow pb - 将keras模型转换为Tensorflow pb后的问题
I'm using keras 2.1.* with tensorflow 1.13.* backend. I save my model during training with .h5 forma ...
- 嵌入式单片机,ATmega328P,外部中断INT0,INT1,INT2,中断标志位介绍
body, table{font-family: 微软雅黑; font-size: 13.5pt} table{border-collapse: collapse; border: solid gra ...
- 设计模式-builder(构造器模式)
好处: 多个属性时,可以清楚明了知道属性, 重叠构造起器的安全性和JavaBeans模式的可读性 只需要制定需要建造的类型就可以得到他们 实例: public class NutritionFacts ...
- R语言求根
求根是数值计算的一个基本问题,一般采用的都是迭代算法求解,主要有不动点迭代法.牛顿-拉富生算法.割线法和二分法. 不动点迭代法 所谓的不动点是指x=f(x)的那些点,而所谓的不懂点迭代法是指将原方程化 ...
- Hive中数据加载失败:root:supergroup:drwxr-xr-x
Hive中数据加载失败:inode=:root:supergroup:drwxr-xr-x 在执行hive,数据加载的时候,遇到了一个错误,如下图: 在执行程序的过程中,遇到权限问题很正常,背后原理也 ...
- EFCore Owned Entity Types,彩蛋乎?鸡肋乎?之彩蛋篇
EFCore Owned Entity Types的定义 EFCore Owned Entity Types的文档在这里:https://docs.microsoft.com/zh-cn/ef/cor ...
- css中width:auto和width:100%的区别是什么
width的值一般是这样设置的: 1,width:50px://宽度设为50px 2,width:50%://宽度设为父类宽度的50% 3,还有一个值是auto(默认值),宽度是自动的,随着内容的增加 ...
- mysql建表时
问题:Incorrect column specifier for column 'id' 答案:原来自动增长列用int数据类型,不用varchar
- Annotation(注解)介绍
Annotation(注解)是什么: Annotation(注解) 官方的定义: An annotation is a form of metadata, that can be added t ...
- MAC Homebrew安装和简单使用
前言: 这个周六日在刚刚买的macbookpro(系统版本是:10.13.5)上面安装angular,一开始是按照windows上的顺序安装的,先安装node.js,然后在安装angular的时候报错 ...