Coursera, Big Data 2, Modeling and Management Systems (week 4/5/6)
week4
streaming data format
下面讲 data lakes

schema-on-read: 从数据源读取raw data 直接放到 data lake 里,然后再读到model里
schema-on-write: 传统模式,把raw data 经过处理后放到data warehouse里,此时已经是结构化的数据,然后直接load 出来

data lake summary

week5 - big data management
针对大数据,传统DBMS 需要提高的地方

some solutiion

from DBMS to BDMS
BDMS 应该具有的特征



BASE 就是基于CAP理论的

一些常用的BDMS及其优缺点
Redis: an enhanced key-value store




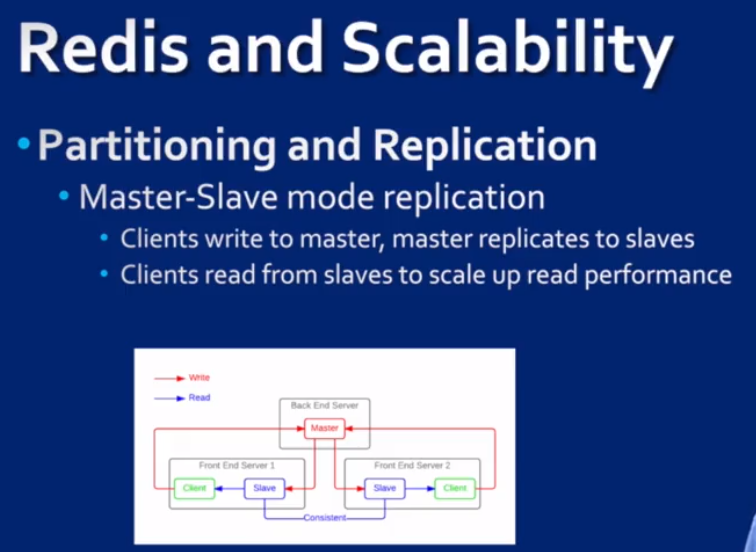
Aerospike: a new generation KV store
这是一个分布式NoSQL database + KV store. 是强一致性的



AsterixDB: a DBMS for semistructured data. 大家都知道的mongodb 以json 格式存储j数据, 这个Asterix 和 mongodb 类似. 它提供ACID保证.

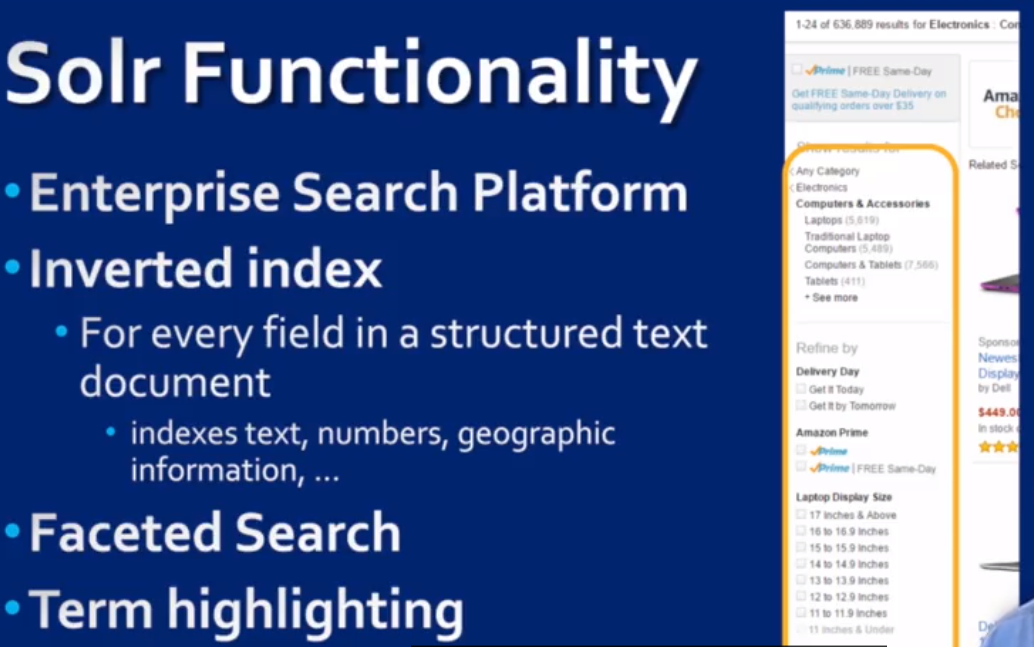
Solr : Text data searching. 基于Lucene的
应该是一种search engine, 不知道和 ES 什么区别.

反向索引,至少要包含 doc id list, 也可以包含更多信息

除了full text search, 还有下面的功能
Vertica:a columnar DBMS

Coursera, Big Data 2, Modeling and Management Systems (week 4/5/6)的更多相关文章
- Coursera, Big Data 2, Modeling and Management Systems (week 1/2/3)
Introduction to data management 整个coures 2 是讲data management and storage 的,主要内容就是分布式文件系统,HDFS, Redis ...
- Coursera, Big Data 3, Integration and Processing (week 4)
Week 4 Big Data Precessing Pipeline 上图可以generalize 成下图,也就是Big data pipeline some high level processi ...
- Coursera, Big Data 4, Machine Learning With Big Data (week 1/2)
Week 1 Machine Learning with Big Data KNime - GUI based Spark MLlib - inside Spark CRISP-DM Week 2, ...
- Coursera, Big Data 3, Integration and Processing (week 5)
Week 5, Big Data Analytics using Spark Programing in Spark Spark Core: Programming in Spark us ...
- Coursera, Big Data 3, Integration and Processing (week 1/2/3)
This is the 3rd course in big data specification courses. Data model reivew 1, data model 的特点: Struc ...
- Coursera, Big Data 1, Introduction (week 3)
什么是分布式文件系统?为什么需要分布式文件系统? 如果文件系统可以管理用网络连接的很多个存储单元,叫分布式文件系统. 分布式文件系统提供了数据可扩展性,容错性,高并发. 这些是传统文件系统不具有的. ...
- Coursera, Big Data 1, Introduction (week 1/2)
Status: week 2 done. Week 1, 主要讲了大数据的的来源 - 机器产生的数据,人产生的数据(比如社交软件上的update, 一般是unstructed data), 组织产生的 ...
- Coursera, Big Data 4, Machine Learning With Big Data (week 3/4/5)
week 3 Classification KNN :基本思想是 input value 类似,就可能是同一类的 Decision Tree Naive Bayes Week 4 Evaluating ...
- [label][Node.js] Three content management systems base on Node.js
1. Keystonejs http://keystonejs.com/ 2. Apostrophe http://apostrophenow.org/
随机推荐
- SpringBoot整合RabbitMQ-服务安装
本系列是学习SpringBoot整合RabbitMQ的练手,包含服务安装,RabbitMQ整合SpringBoot2.x,消息可靠性投递实现等三篇博客. 学习路径:https://www.imooc. ...
- 最简单易懂的Spring Security 身份认证流程讲解
最简单易懂的Spring Security 身份认证流程讲解 导言 相信大伙对Spring Security这个框架又爱又恨,爱它的强大,恨它的繁琐,其实这是一个误区,Spring Security确 ...
- 服务网关Ocelot 入门Demo系列(01-Ocelot极简单Demo及负载均衡的配置)
[前言] Ocelot是一个用.NET Core实现并且开源的API网关,它功能强大,包括了:路由.请求聚合.服务发现.认证.鉴权.限流熔断.并内置了负载均衡器与Service Fabric.Butt ...
- 最速下降方法和Newton方法
目录 最速下降方法 Euclid范数和二次范数 采用\(\ell_1\)-范数的最速下降方向 Newton 方法 Newton 步径 二阶近似的最优解 线性化最优性条件的解 Newton 步径的仿射不 ...
- RabbitMQ学习笔记一:本地Windows环境安装RabbitMQ Server
一:安装RabbitMQ需要先安装Erlang语言开发包,百度网盘地址:http://pan.baidu.com/s/1jH8S2u6.直接下载地址:http://erlang.org/downloa ...
- 基于开发者中心DevOps流水线快速上云
导读:“DevOps”这个词现在很流行,它具体指的是什么呢?本文介绍了DevOps和开发者中心DevOps流水线,图文并茂,解答您的疑惑. 那么DevOps是什么?开发者中心<DevOps流水线 ...
- [转帖]Linux中的15个基本‘ls’命令示例
Linux中的15个基本‘ls’命令示例 https://linux.cn/article-5109-1.html ls -lt 和 ls -ltr 来查看文件新旧顺序. list time rese ...
- SharedPreferences类的使用
SharedPreferences,用xml文件保存用户的偏好设置,是一个轻量级的存储类. 效果图: 代码: activity_main <?xml version="1.0" ...
- 解决多线程安全问题-无非两个方法synchronized和lock 具体原理(百度-美团)
还有其他的锁,如果想要了解,参考:JAVA锁机制-可重入锁,可中断锁,公平锁,读写锁,自旋锁, 用synchronized实现ReentrantLock 美团面试题参考:使用synchronized ...
- EasyTouch5ForSiki学院
总结: 这里面的一些功能,就可以拿来做移动或者PC的很多功能了,这是一个很有用的插件. 禁用0618错误 EasyTouch4_x的写法: using HedgehogTeam.EasyTouch; ...