python爬虫实践(二)——爬取张艺谋导演的电影《影》的豆瓣影评并进行简单分析
学了爬虫之后,都只是爬取一些简单的小页面,觉得没意思,所以我现在准备爬取一下豆瓣上张艺谋导演的“影”的短评,存入数据库,并进行简单的分析和数据可视化,因为用到的只是比较多,所以写一篇博客当做笔记。
第一步:想要存入数据库就必须与数据库进行链接,并建立相应的数据表,这里我是在win10下使用oracle数据库。
经过思考,我认为我们爬取一个短评的时候,只需要用到几个字段:
1.用户名
2.评论的日期
3.这个评论有多少人点赞
4.这个用户给电影打几分
5.用户的评价
接下来写一个函数,这个函数的功能是:根据传入的参数来判断在指定用户下是否存在指定的表,如果存在,就先删除表,再创建表,如果不存在,就直接创建表。这样做可以保证你创建表的时候不会报错,因为函数会根据传入的参数进行建表,代码如下
import cx_Oracle #导入连接oracle需要的包
def begin(table_name): #参数是你要创建的表的名称
db = cx_Oracle.connect('scott/tiger@localhost:1521/mldn')
#连接数据库scott是用户名,tiger是密码,@localhost:1521/mldn是监听,根据自己实际情况来填写
cr = db.cursor() #创建sursor
drop_sql="drop table " + table_name
#这个sql语句是删除表
gudge_sql = "SELECT COUNT(*) FROM ALL_TABLES WHERE OWNER = UPPER('scott') AND TABLE_NAME = UPPER('"+ table_name +"')"
#这个sql语句是判断在scott用户下下是否存在table_name表,不存在,则返回值为0
s = "(name varchar2(50),comment_date varchar2(50),vote varchar2(40),star varchar2(40),user_comment varchar2(3000))"
create_sql = "create table " + table_name + s
#这是创建表的sql语句
cr.execute(gudge_sql) #查询table_name表是否存在
rs = cr.fetchall() #接收返回值
t = str(rs)[2:-3] #把返回值转化为字符串
if t not in [ '0',]: #如果返回值不为零,即table_name表存在
cr.execute(drop_sql) # 执行删除语句
cr.execute(create_sql) #创建table_name表
db.close() #关闭数据库连接
这个函数根据你传入的表名来创建数据表
第二步:构造请求头
现在有了数据表,你以为可以开始编写爬了?并不能,经过我实践,发现如果以游客身份爬取,爬不了多少数据,需要登录后才可以爬取更多的数据,我不想去爬虫来模拟登录,第一,太繁琐,第二,因为有图片验证码,目前我还不会用算法来自动识别图片。所以我的方法是:首先用浏览器人工登陆一次,然后按下F12或者Fn+F12,选中Network,刷新一下页面,在Name栏选中最顶上的一项点击,就会如下图所示,
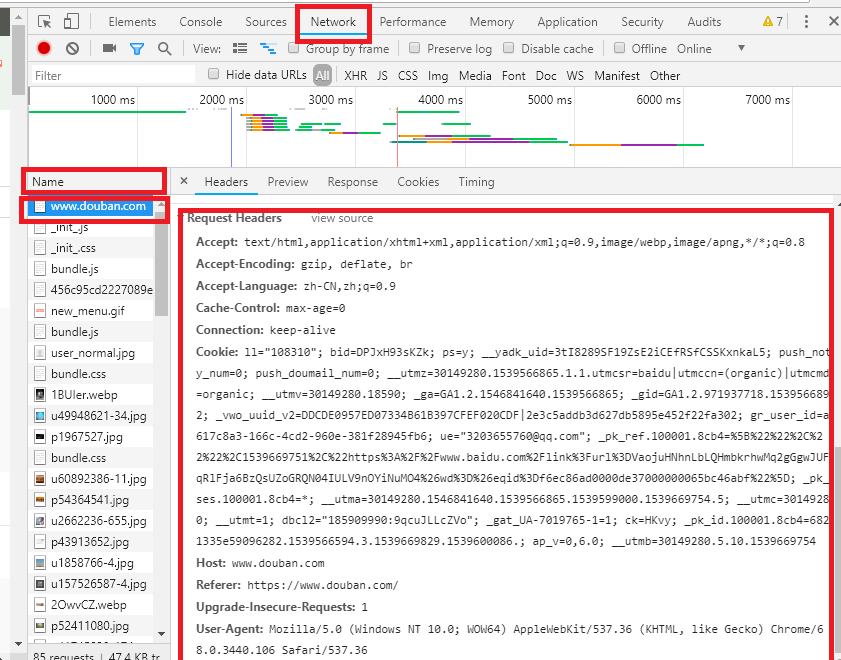
把这个Request Headers下的内容复制下来,做成一个字典,再装载成请求头,就可以爬取所有数据了
设置headers的代码如下:
from urllib import request
def set_hesders(url):
'''
设置请求头
:param url: url链接
:return: 装载后的url链接
'''
heraders = {
'Accep': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Cookie': 'll="108310"; bid=DPJxH93sKZk; ps=y; push_noty_num=0; push_doumail_num=0; __utmz=30149280.1539566865.1.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmv=30149280.18590; _ga=GA1.2.1546841640.1539566865; _gid=GA1.2.971937718.1539566892; __utmz=223695111.1539567345.1.1.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __yadk_uid=9XHtMuB2idRYlXP8XsRsmPElvO1oUwKN; _vwo_uuid_v2=DDCDE0957ED07334B61B397CFEF020CDF|2e3c5addb3d627db5895e452f22fa302; gr_user_id=a617c8a3-166c-4cd2-960e-381f28945fb6; ap_v=0,6.0; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1539599000%2C%22https%3A%2F%2Fwww.douban.com%2F%22%5D; _pk_ses.100001.4cf6=*; __utma=30149280.1546841640.1539566865.1539588868.1539599000.4; __utma=223695111.1546841640.1539566865.1539588868.1539599001.4; __utmb=223695111.0.10.1539599001; ue="3203655760@qq.com"; __utmc=30149280; __utmt=1; dbcl2="185909990:9qcuJLLcZVo"; ck=HKvy; __utmb=30149280.4.10.1539599000; __utmc=223695111; _pk_id.100001.4cf6=39d7c14ac0d6bd63.1539567345.4.1539600176.1539589195.',
'Host': 'movie.douban.com',
'Referer': 'https://movie.douban.com/',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (iPad; CPU OS 5_0 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko) Version/5.1 Mobile/9A334 Safari/7534.48.3'
}
return request.Request(url,headers = heraders)
第三步:生成url
通过观察,我们知道,在影评的每一页的url链接都差不多,所以用一个函数来生成每一页的url
代码如下:
def get_pageurl():
pageurl_list = []
for i in range(25):
url = "https://movie.douban.com/subject/4864908/comments?start=" + str(i * 20) + "&limit=20&sort=new_score&status=P"
pageurl_list.append(url)
return pageurl_list
第四步:爬取页面并解析页面,运用xpath解析,然后把数据存入数据库
此过程需要用到sqlalchemy库、pandas库
from sqlalchemy import create_engine
from urllib import request
from lxml import etree
import pandas as pd
import os
os.environ['NLS_LANG'] = 'SIMPLIFIED CHINESE_CHINA.UTF8'
#我这行代码是因为我向数据库写入或者读取时有中文会报错,所以才写这行代码
def spyder_and_insert(table_name,url):
engjine = create_engine('oracle://scott:tiger@localhost:1521/mldn')
url = set_hesders(url)
try:
rsp = request.urlopen(url) #url请求
except:
print("url错误")
html = rsp.read()
html = etree.HTML(html)
try:
comment_List = html.xpath("//div[@class='comment']")
except:
print("cookie错误")
for i in range(len(comment_List)):
name = str(comment_List[i].xpath("./h3/span[@class = 'comment-info']/a/text()"))[2:-2]
comment_date = str(comment_List[i].xpath("./h3/span[@class = 'comment-info']/span[@class='comment-time ']/text()"))[24:-20]
vote = str(comment_List[i].xpath("./h3/span[@class='comment-vote']/span/text()"))[2:-2]
star = str(comment_List[i].xpath("./h3/span[@class = 'comment-info']/span[last()-1]/@title"))[2:-2]
user_comment = str(comment_List[i].xpath("./p/span/text()"))[2:-2]
if star not in ['很差','还行','较差','力荐','推荐']:
star = "未打分"
d = [{"comment_date": comment_date, "name": name, "vote": vote, "star": star, "user_comment": user_comment},]
df = pd.DataFrame(d) #转化为DataFrame类型
try:
#向数据库写入数据
df.to_sql("douban_comments", con=engjine, index=False, if_exists="append")
except:
print("向数据库插入数据出错")
第五步:爬取所有评论并存入数据库,为了更直观的查看爬虫爬取的进度,我编写了一个进度条代码,效果如下
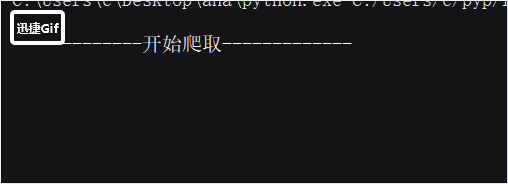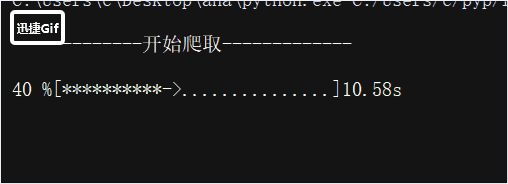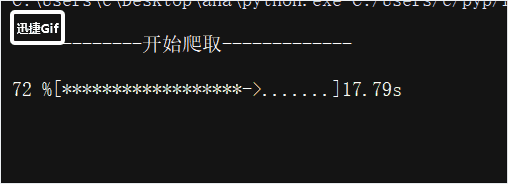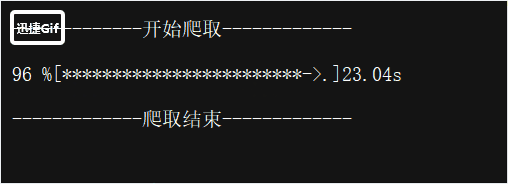
函数的代码如下:
def gather():
print("开始爬取".center(30, "-"))
start = time.perf_counter()
print(" 0 %[->************************.]0.45s",end="")
table_name = "douban_comments"
user_name = "scott"
begin(user_name, table_name)
douban_pageurls = get_pageurl()
lo = len(douban_pageurls)
for i in range(lo):
spyder_and_insert(table_name,douban_pageurls[i])
a = '*' * i
b = '.' * (lo - i)
c = (i / lo) * 100
dur = time.perf_counter() - start
print("\r{:^3.0f}%[{}->{}]{:.2f}s".format(c, a, b, dur), end='')
time.sleep(0.1)
print("\n" + "爬取结束".center(30, '-'))
现在数据已经存入数据库了,现在我们用代码对数据进行简单分析,使数据可视化
该过程会用到numpy库、matplotlib库,
首先,我们对评价进行统计,分别画出直方图和饼状图,代码如下
from sqlalchemy import create_engine
import cx_Oracle
import pandas as pd
import numpy as np
import os
import matplotlib.pyplot as plt
os.environ['NLS_LANG'] = 'SIMPLIFIED CHINESE_CHINA.UTF8'
engjine = create_engine('oracle://scott:tiger@localhost:1521/mldn')
def begin():
aaa = pd.read_sql_table("douban_comments",con=engjine)
s1 = aaa.loc[aaa["star"]=="很差",["star"]].count()["star"]
s2 = aaa.loc[aaa["star"]=="较差",["star"]].count()["star"]
s3 = aaa.loc[aaa["star"]=="还行",["star"]].count()["star"]
s4 = aaa.loc[aaa["star"]=="推荐",["star"]].count()["star"]
s5 = aaa.loc[aaa["star"]=="力荐",["star"]].count()["star"]
s6 = aaa.loc[aaa["star"]=="未打分",["star"]].count()["star"]
a = np.array([s1,s2,s3,s4,s5,s6])
b = np.array(["一星","两星","三星","四星","五星","未打分"])
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
return a,b
def zhifangtu(a,b):
plt.bar(b,a,width = 0.8)
plt.title("“影”的评分")
#plt.show()
plt.savefig('./ying1.png',dpi=200)
def bingzhuangtu(a,b):
plt.figure(figsize=(6, 6))
plt.pie(a, labels=b, autopct='%1.1f%%')
plt.title("“影”的评分")
plt.savefig('./ying2.png', dpi=200)
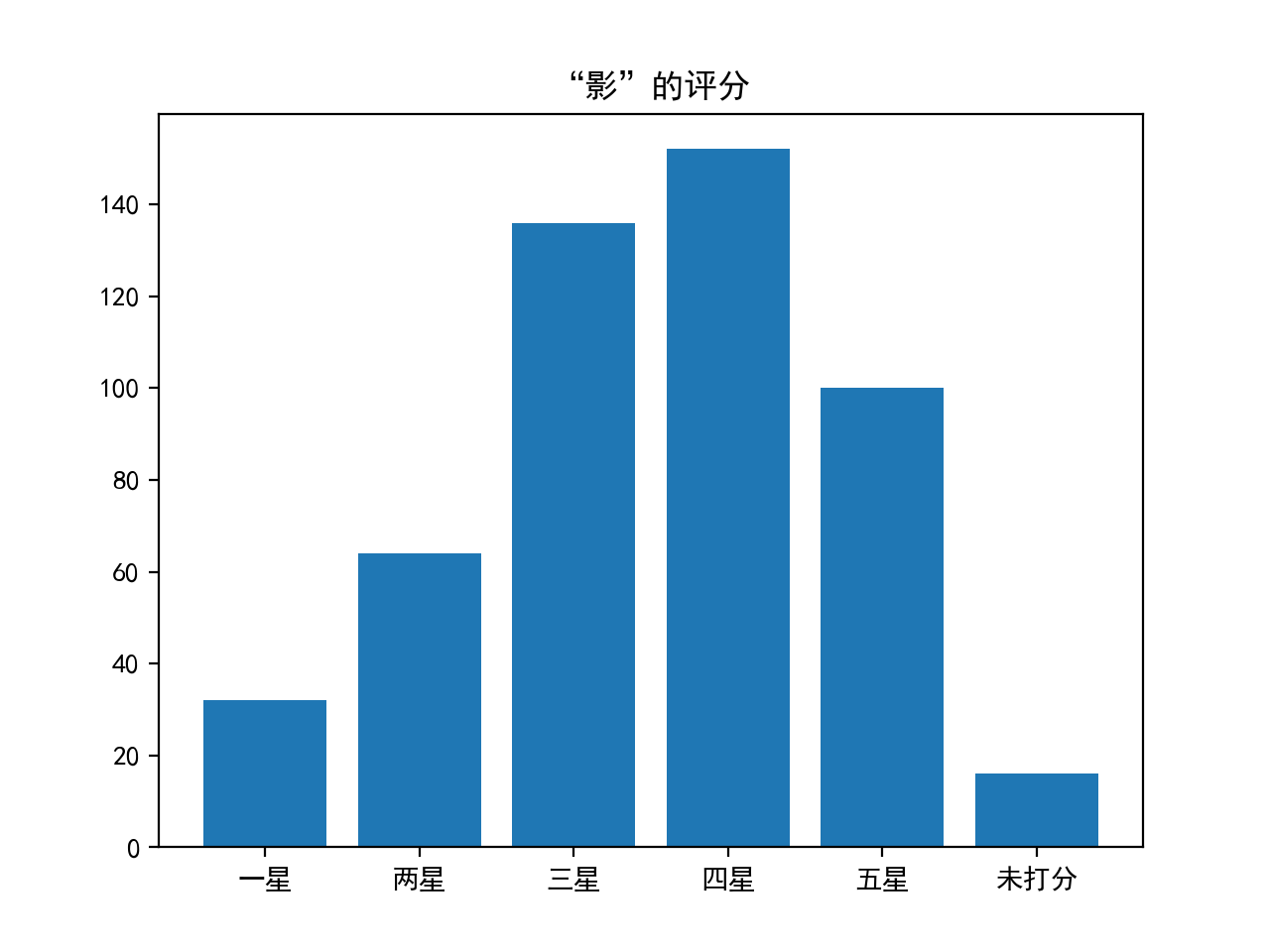
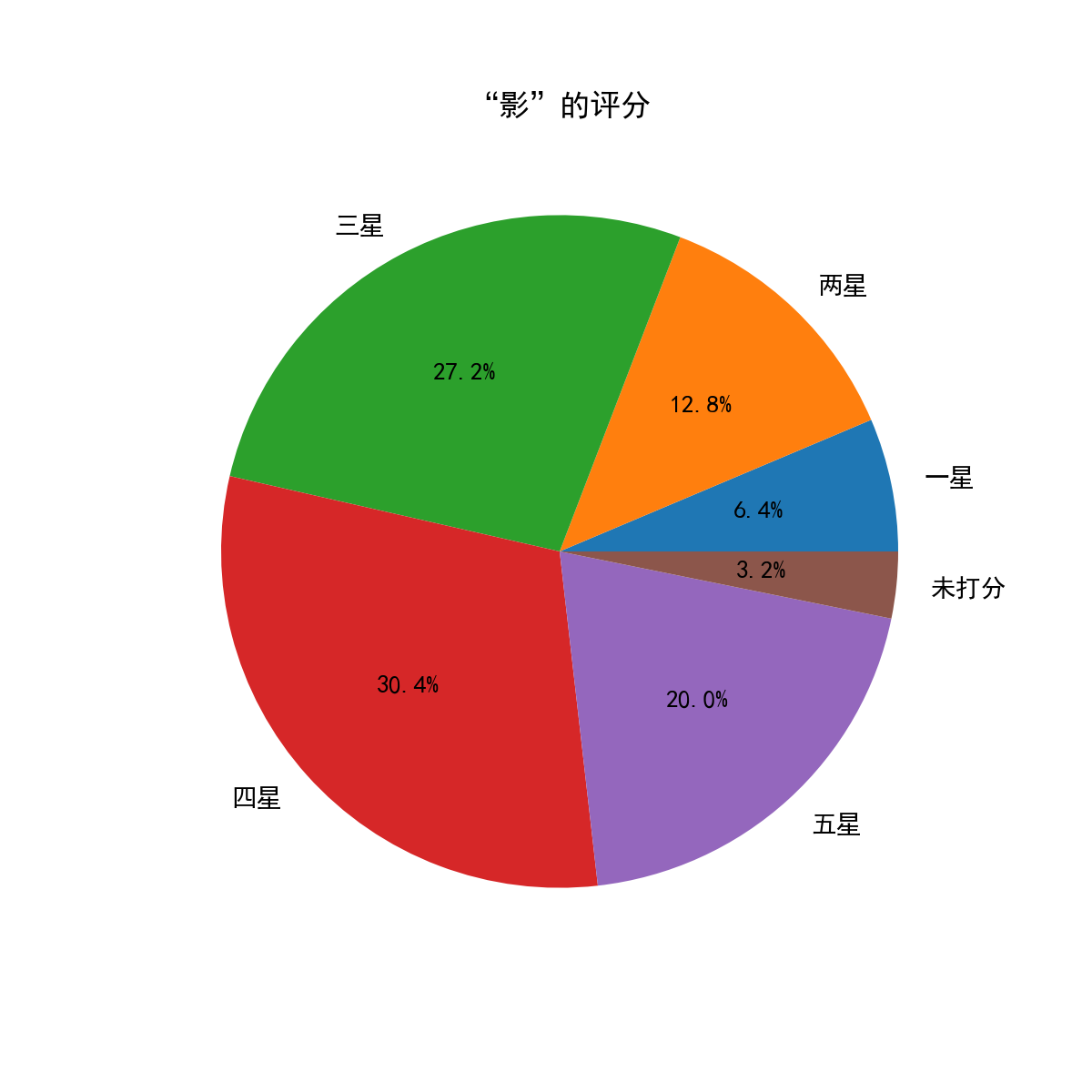
运行函数后,得到下面两幅图:
 还可以对评论进行统计,这里我用jieba库和wordcloud库来对所有评论进行中文分词并生成词云
还可以对评论进行统计,这里我用jieba库和wordcloud库来对所有评论进行中文分词并生成词云
代码如下:
import jieba
from sqlalchemy import create_engine
import pandas as pd
import numpy as np
import os
import re
import wordcloud
def ciying():
os.environ['NLS_LANG'] = 'SIMPLIFIED CHINESE_CHINA.UTF8'
engjine = create_engine('oracle://scott:tiger@localhost:1521/mldn')
aaa = pd.read_sql_table("douban_comments",con=engjine)
a = ""
for i in range(len(aaa['user_comment'])): #循环取出所有评论并拼接字符串
a += str(aaa.loc[i,'user_comment'])
ls = jieba.lcut(a) #用jieba库分词
txt = " ".join(ls)
w = wordcloud.WordCloud(
width=1000, height=700,
background_color="white",
font_path="msyh.ttc"
)
w.generate(txt) #生成词云
w.to_file("ying3.png") #保存图片
ciying()
运行函数后的图片如下:

通过上面几个图面,我们发现其实评价也还好,打三分四分的占了近60%,毕竟可是从豆瓣爬取的评论,豆瓣大家都懂的。。。
总结:因为涉及到的知识点比较杂,所以我就想着写篇博客,当作自己的学习笔记了,我的代码还有许多写的差的的地方,函数命名也不专业,但是这是我第一个把数据写入数据库的爬虫,自己心里还是有点小激动的....
python爬虫实践(二)——爬取张艺谋导演的电影《影》的豆瓣影评并进行简单分析的更多相关文章
- Python 爬虫入门(二)——爬取妹子图
Python 爬虫入门 听说你写代码没动力?本文就给你动力,爬取妹子图.如果这也没动力那就没救了. GitHub 地址: https://github.com/injetlee/Python/blob ...
- Python爬虫学习(二) ——————爬取前程无忧招聘信息并写入excel
作为一名Pythoner,相信大家对Python的就业前景或多或少会有一些关注.索性我们就写一个爬虫去获取一些我们需要的信息,今天我们要爬取的是前程无忧!说干就干!进入到前程无忧的官网,输入关键字&q ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- Python 爬虫入门之爬取妹子图
Python 爬虫入门之爬取妹子图 来源:李英杰 链接: https://segmentfault.com/a/1190000015798452 听说你写代码没动力?本文就给你动力,爬取妹子图.如果 ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
随机推荐
- linux下安装svn1.7
转自 https://blog.csdn.net/u011752559/article/details/11559573?locationNum=11&fps=1 1.下载svn安装包 wge ...
- E: Unable to locate package clang-7 E: Unable to locate package clang++-7 E: Couldn't find any package by regex 'clang++-7'
我的系统是Debian 9.8, 然后在装下面这两个包的时候老是提示找不到.然后再github上一问,过了几分钟就有大佬回复了,而且亲测有效 ~$ sudo apt-get -y install cl ...
- ESLint学习小记
一.关于配置文件,优先级从上到下: eslintrc.js .eslintrc.yaml .eslintrc.yml .eslintrc.json .eslintrc package.json 在官方 ...
- 论文笔记:Learning wrapped guidance for blind face restoration
这篇论文主要是讲人脸修复的,所谓人脸修复,其实就是将低清的,或者经过压缩等操作的人脸图像进行高清复原.这可以近似为针对人脸的图像修复工作.在图像修复中,我们都会假设退化的图像是高清图像经过某种函数映射 ...
- SVM小白教程(1):目标函数
关于 SVM(支持向量机),网上教程实在太多了,但真正能把内容讲清楚的少之又少.这段时间在网上看到一个老外的 svm 教程,几乎是我看过的所有教程中最好的.这里打算通过几篇文章,把我对教程的理解记录成 ...
- RCNN论文学习
[Rich feature hierarchies for accurate object detection and semantic segmentation] Abstract 论文的方 ...
- js变量传递
基本类型.引用类型 基本类型: undefined.Null.Boolean.Number.String五种 (简单的数据段);引用类型: object (由多个值构成). 两种类型在使用上的区别: ...
- javaweb c3p0连接oracle12c
最近在搞javaweb,在连接池上碰到了一系列的问题,在Junit测试时,oracle12c报错: ORA-28040: 没有匹配的验证协议 百度解决:修改 $ORACLE_HOME/network/ ...
- Java中三种代理模式
代理模式 代理(Proxy)是一种设计模式,提供了间接对目标对象进行访问的方式;即通过代理对象访问目标对象.这样做的好处是:可以在目标对象实现的功能上,增加额外的功能补充,即扩展目标对象的功能. 这就 ...
- Justoj 2389: 拼接三角形 二分查找
2389: 拼接三角形 时间限制: C/C++ 1 s Java/Python 3 s 内存限制: 128 MB 答案正确: 7 提交: 21 提交 我的状态 ...