Hadoop| YARN| 计数器| 压缩| 调优
1. 计数器应用

2. 数据清洗(ETL)
在运行核心业务MapReduce程序之前,往往要先对数据进行清洗,清理掉不符合用户要求的数据。清理的过程往往只需要运行Mapper程序,不需要运行Reduce程序。
LogMapper.java
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] fields = value.toString().split(" ");
if (fields.length > 11){ //过滤掉log长度< 11的;
context.write(value, NullWritable.get());
context.getCounter("ETL", "true").increment(1);
}else {
/*ETL
false=849
true=13770
*/
context.getCounter("ETL", "false").increment(1);
} 在LogDriver.java中添加:
job.setMapperClass(LogMapper.class);
job.setNumReduceTasks(0);
3. Hadoop数据压缩
开源的7zip、rar;减少数据量IO(网络传输、磁盘读写) ;压缩默认是关闭;
① 压缩策略

运算密集型大量需CPU,IO密集型是大量用磁盘;
存储数据主要用的Gzip,Linux和hadoop都支持,使用方便;
Snappy一般用在Map输入,Reduce输出的时候启用;
为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器,如下:
压缩格式 对应的编码/解码器
DEFLATE org.apache.hadoop.io.compress.DefaultCodec
gzip org.apache.hadoop.io.compress.GzipCodec
bzip2 org.apache.hadoop.io.compress.BZip2Codec
LZO com.hadoop.compression.lzo.LzopCodec
Snappy org.apache.hadoop.io.compress.SnappyCodec 压缩性能的比较
压缩算法 原始文件大小 压缩文件大小 压缩速度 解压速度
gzip .3GB .8GB .5MB/s 58MB/s
bzip2 .3GB .1GB .4MB/s .5MB/s
LZO .3GB .9GB .3MB/s .6MB/s
① Gzip压缩| 常用的,用在头| 尾数据

tar.gz输入的数据不能太大,不然一个MapTask处理的数据太多
②LZO压缩

③ Bzip2

④ Snappy
主要用在shuffle阶段;如在Map最后的输出阶段

⑤ 压缩位置
头、中间的shuffle、尾部

压缩的配置
输入端:放一个压缩文件它能自动识别,不需要配置;
参数mapreduce.map.output.compress(在mapred-site.xml中配置) 默认false 在mapper输出阶段 这个参数设为true启用压缩 mapreduce.map.output.compress.codec(在mapred-site.xml中配置) 默认org.apache.hadoop.io.compress.DefaultCodec mapper输出 企业多使用LZO或Snappy编解码器在此阶段压缩数据
编码格式可写gzip格式,默认用的snappy但现hadoop不支持 mapreduce.output.fileoutputformat.compress(在mapred-site.xml中配置) false reducer输出 这个参数设为true启用压缩
mapreduce.output.fileoutputformat.compress.codec(在mapred-site.xml中配置) org.apache.hadoop.io.compress. DefaultCodec reducer输出 使用标准工具或者编解码器,如gzip和bzip2
mapreduce.output.fileoutputformat.compress.type(在mapred-site.xml中配置) RECORD reducer输出 SequenceFile输出使用的压缩类型:NONE和BLOCK
自定义压缩和解压
public class TestCompress {
public static void main(String[] args) throws IOException {
compress("F://web.log", BZip2Codec.class); //压缩
//decompress("F://web.log.bz2"); //解压缩
} //传入一个压缩类,通过这个类反射进来一个实例codec,通过实例把流包装起来
private static void compress(String path, Class<? extends CompressionCodec> codecClass) throws IOException {
CompressionCodec codec = ReflectionUtils.newInstance(codecClass, new Configuration());
String extension = codec.getDefaultExtension(); //压缩格式为默认的扩展名,默认的为.bz2;与上边的BZip2Codec.class对应的
/*public String getDefaultExtension() {
return ".bz2";
}*/
//开流
FileInputStream fis = new FileInputStream(path);
FileOutputStream fos = new FileOutputStream(path + extension);//加个扩展名
CompressionOutputStream cos = codec.createOutputStream(fos); //包装流,创建输出流的压缩流
//流要对口
IOUtils.copyBytes(fis, cos, 1024);
IOUtils.closeStream(fis);
IOUtils.closeStream(cos);
}
private static void decompress(String path) throws IOException {
CompressionCodecFactory codecFactory = new CompressionCodecFactory(new Configuration());
//工厂模式,通过文件名path,getCodec返回一个具体的类,这叫工厂模式,在编码写代码的时候很好用;没工厂模式就要不断的判断if或switch
CompressionCodec codec = codecFactory.getCodec(new Path(path));
FileInputStream fis = new FileInputStream(path);
FileOutputStream fos = new FileOutputStream("F://1.log");
CompressionInputStream cis = codec.createInputStream(fis); //输出的就不是压缩的了
//谁被压缩就包谁,这里得是cis
IOUtils.copyBytes(cis, fos, 1024);
IOUtils.closeStream(cis);
IOUtils.closeStream(fis);
}
}
① Map输出端采用压缩也就是在shuffle阶段的配置:
在Driver.java
Configuration configuration = new Configuration();
// 开启map端输出压缩
configuration.setBoolean("mapreduce.map.output.compress", true);
// 设置map端输出压缩方式
configuration.setClass("mapreduce.map.output.compress.codec", BZip2Codec.class, CompressionCodec.class);
//在工作中不能采用Bzip压缩,文件大点 2M/S的速度,会很慢!!
//1.获取一个任务实例; 获取配置信息和封装任务
Job job = Job.getInstance(configuration); //new Configuration()
--->结果看不出什么区别的
INFO [org.apache.hadoop.io.compress.CodecPool] - Got brand-new compressor [.bz2] ##在shuffle阶段采用压缩
② 输入端的压缩不需配置,可自动识别
[org.apache.hadoop.io.compress.CodecPool] - Got brand-new decompressor [.bz2]
③ 在Reduce输出端采用压缩的设置
// 设置reduce端输出压缩开启
FileOutputFormat.setCompressOutput(job, true);
// 设置压缩的方式
FileOutputFormat.setOutputCompressorClass(job, BZip2Codec.class); //6.提交任务
boolean b = job.waitForCompletion(true); --->最后的结果是part-r-00000.bz2格式的
4. Yarn资源调度器
Yarn资源池;形如cpu和内存;
1、YARN架构
RM、NM不关心Job的运行情况;RM只关心客户端的申请、Task和Task的调度;
NM只听命令(RM、AM)
Job的整个运行是由ApplicationMaster(AM)负责
MapTask、ReduceTask、ApplicationMaster都是运行在Container内部
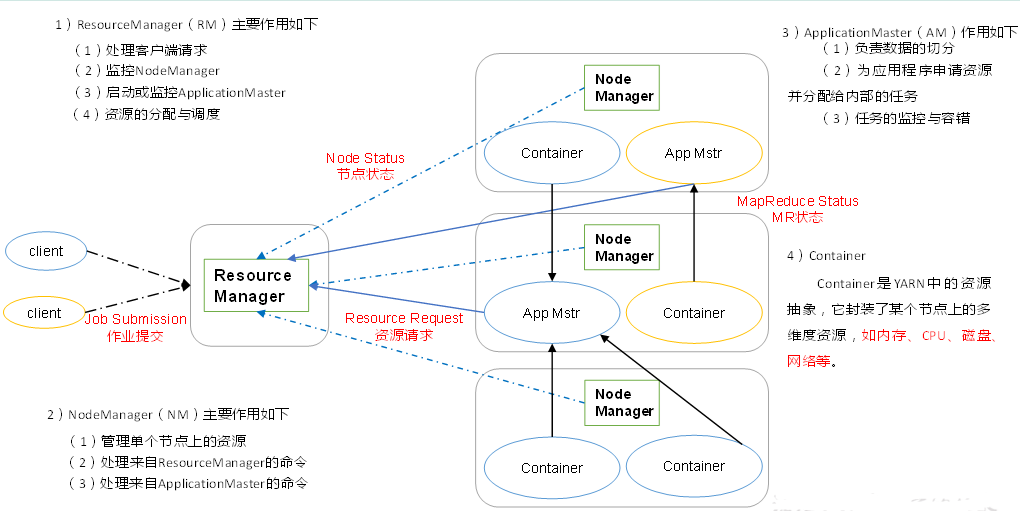
2、YARN的工作运行机制
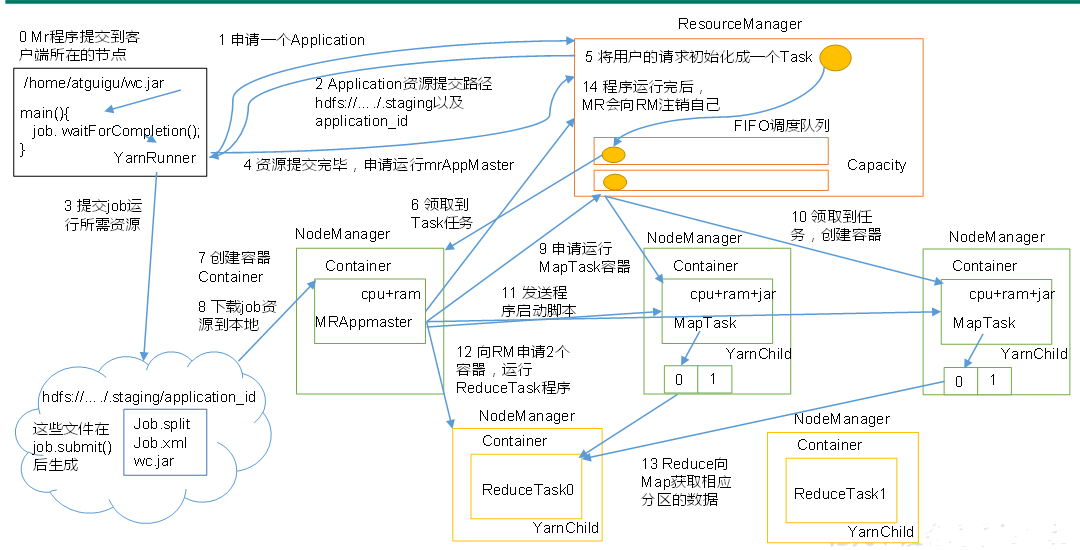
提交作业
Client调用job.waitForCompletion方法让整个集群提交MapReduce作业任务;
Client----->向ResourceManager申请一个Application,RM给Client返回该job资源的提交路径和作业id即application_id告诉这个任务是几号;
---->Client--Drever就会把资源(Job.split、Job.xml、wc.jar)提交到指定的资源提交路径--HDFS上的临时文件夹
---Client资源提交完---->向ResourceManager申请运行MrAppMaster(是mapreduce的ApplicationMaster的实现 );
作业初始化
------>RM将用户请求包装成一个Task---->把Task添加到容量调度队列里 ----->某一个空闲的NodeManager(领取到Task即Job任务)
---->该NM创建Container并产生且运行MrAppMaster(这个任务才真正执行) ----->把Client提交的资源下载到本地,
任务分配
MrAppMaster根据切片的数量向RM申请MapTask容器任务资源 --->RM把它包装成Task添加到队列---->RM将运行MapTask这个任务分配给另外两个NodeManager,另外两个NodeManager分别领取任务并创建Container容器。
任务运行
NM分别启动MapTask(程序启动代码是由MrAppmaster发送给各个NM来启动相应MapTask),MapTask对数据分区排序 ---- >执行完之后输出文件(一个MapTask输出一个分区且内部有序的文件),执行完之后它们的Container就会被回收;
MrAppmaster等待所有的MapTask运行完毕之后,进一步根据分区文件的数量 job设置的数量向RM申请相应的ReduceTask容器 ---->ReduceTask向MapTask获取相应分区数据,把相应数据下载到本地开始执行,它执行完后它的Container被回收;
---->把最后结果写到HDFS中;----最后程序执行完之后MrAppMaster向RM注销自己,Container被回收;
进度和状态更新
YARN中的任务将其进度和状态(包括counter)返回给应用管理器, 客户端每秒(通过mapreduce.client.progressmonitor.pollinterval设置)向应用管理器请求进度更新, 展示给用户。
作业完成
除了向应用管理器请求作业进度外, 客户端每5秒都会通过调用waitForCompletion()来检查作业是否完成。时间间隔可以通过mapreduce.client.completion.pollinterval来设置。作业完成之后, 应用管理器和Container会清理工作状态。作业的信息会被作业历史服务器存储以备之后用户核查。
3、 资源调度器
Hadoop作业调度器主要有三种:FIFO、Capacity Scheduler和Fair Scheduler。Hadoop2.7.2默认的资源调度器是Capacity Scheduler。
1.先进先出调度器(FIFO)

存在的问题:如果有紧急的任务,却要等到前面的先执行完;
2.容量调度器(Capacity Scheduler)就是多个FIFO队列并行 (默认的调度器)
占据集群的资源

存在的问题:如果queueC很闲,它所占据的资源不会给queueA和queueB;
3.公平调度器(Fair Scheduler)
可插拔(任务可来可不来,可以运行各种任务(如MapReduce| spark等任务))式分层队列
缺额:按照所需要的资源数量来分配资源;
如果queueB中有任务了,而A和C是空闲的,则A和C中的资源会都给queueB(占据集群所有资源),如果C有其他任务了,会从B中抢资源过来;
多级队列叠加:queueB中还可以再分queueD和queueE各占50%,相当于各占整个集群的25%;如果某个任务优先级比较低就可以把它放到队列的深层级处(按队列的层级来管理任务的优先级—公平);
每个队列所占据的资源不是死的,取决于任务的紧迫度;根据任务公平的按比例分配资源;
http://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/FairScheduler.html
4、 任务的推测执行
在map阶段启动mapTask,每个mapTask是并行,运行的时间不一样;
1.作业完成时间取决于最慢的任务完成时间
一个作业由若干个Map任务和Reduce任务构成。因硬件老化、软件Bug等,某些任务可能运行非常慢。
思考:系统中有99%的Map任务都完成了,只有少数几个Map老是进度很慢,完不成,怎么办?
2.推测执行机制
发现拖后腿的任务,比如某个任务运行速度远慢于任务平均速度。为拖后腿任务启动一个备份任务,同时运行。谁先运行完,则采用谁的结果。
3.执行推测任务的前提条件
(1)每个Task只能有一个备份任务;(消耗yarn的资源)
(2)当前Job已完成的Task必须不小于0.05(这个任务至少完成5%才会开始去推测执行,太长太短都不好; )
(3)开启推测执行参数设置。mapred-site.xml文件中默认是打开的。
<property>
<name>mapreduce.map.speculative</name>
<value>true</value>
<description>If true, then multiple instances of some map tasks may be executed in parallel.</description>
</property> <property>
<name>mapreduce.reduce.speculative</name>
<value>true</value>
<description>If true, then multiple instances of some reduce tasks may be executed in parallel.</description>
</property>
4.不能启用推测执行机制情况
(1)任务间存在严重的负载倾斜;( 不是因为它算的慢是因为数据量大,再启动一个也是没用的 )
(2)特殊任务,比如任务向数据库中写数据。(两个Task写同样的,会产生冲突)
算法原理
推算任务执行时间、看看任务什么时候结束、推算下备份任务如果启动了什么时候结束、
最后选择差值(新启动的备份任务的时间 — 目前任务的时间)最大的为之启动备份任务;

5. Hadoop企业优化

看什么导致的Map运行时间过长;加快Map、开启Map| Reduce共存;
小文件过多可使用combineTextFormat、打Ha包、最好不弄小文件;
压缩以后文件不可分块会导致map阶段过长;
Spill溢出次数过多,把环形缓冲区改大;Merge合并,如要合并20个文件,先合并前10个,然后把合并的放到文件末尾,剩下11个文件,再取前10个合并,剩2个,再把它俩合并;较少merger次数,一次多合并几个文件;
5.1 MapReduce优化方法
MapReduce优化方法主要从六个方面考虑:数据输入、Map阶段、Reduce阶段、IO传输、数据倾斜问题和常用的调优参数。
1.数据输入:

处理小文件慢:处理小文件的计算开销< 建立虚拟机JVM的开销,一次MapTask就要建立一次JVM;JVM重用,一个MapTask运行完一个数据不会立刻被杀掉,再运行一段其他数据,因为同一个任务的Map阶段都是一样的,处理2条数据分配资源只分配一次,规避了资源分配>>事务处理的时间;
2.Map阶段

io.sort.mb、sort.spill.percent 由100M,0.8 --->500M,0.95
开多少个线程取决于磁盘的能力
3.Reduce阶段


4. IO传输

5.数据倾斜


spark采用的方法是缩放key的粒度;
5.2 HDFS小文件优化方法
HDFS小文件弊端
HDFS上每个文件都要在NameNode上建立一个索引,这个索引的大小约为150byte,这样当小文件比较多的时候,就会产生很多的索引文件,一方面会大量占用NameNode的内存空间,另一方面就是索引文件过大使得索引速度变慢。
HDFS小文件解决方案
小文件的优化无非以下几种方式:
(1)在数据采集的时候,就将小文件或小批数据合成大文件再上传HDFS。
(2)在业务处理之前,在HDFS上使用MapReduce程序对小文件进行合并。
(3)在MapReduce处理时,可采用CombineTextInputFormat提高效率。


JVM重用内存不会立即释放,JVM中内存靠GC回收但它并不能保证内存100%回收。
Hadoop| YARN| 计数器| 压缩| 调优的更多相关文章
- CentOS7安装CDH 第十二章:YARN的资源调优
相关文章链接 CentOS7安装CDH 第一章:CentOS7系统安装 CentOS7安装CDH 第二章:CentOS7各个软件安装和启动 CentOS7安装CDH 第三章:CDH中的问题和解决方法 ...
- Hbase和Hadoop的内存参数调优 + 前端控制台
1.hadoop的内存配置调优 mapred-site.xml的内存调整 <property> <name>mapreduce.map.memory.mb</name&g ...
- Yarn的资源调优
一.概述 每个job提交到yarn上执行时,都会分配Container容器去运行,而这个容器需要资源才能运行,这个资源就是Cpu和内存. 1.CPU资源调度 目前的CPU被Yarn划分为虚拟CPU,这 ...
- hadoop 集群调优实践总结
调优概述# 几乎在很多场景,MapRdeuce或者说分布式架构,都会在IO受限,硬盘或者网络读取数据遇到瓶颈.处理数据瓶颈CPU受限.大量的硬盘读写数据是海量数据分析常见情况. IO受限例子: 索引 ...
- Cloudera Hadoop 5& Hadoop高阶管理及调优课程(CDH5,Hadoop2.0,HA,安全,管理,调优)
1.课程环境 本课程涉及的技术产品及相关版本: 技术 版本 Linux CentOS 6.5 Java 1.7 Hadoop2.0 2.6.0 Hadoop1.0 1.2.1 Zookeeper 3. ...
- hadoop MapReduce - 从作业、任务(task)、管理员角度调优
Hadoop为用户作业提供了多种可配置的参数,以允许用户根据作业特点调整这些参数值使作业运行效率达到最优. 一 应用程序编写规范 1.设置Combiner 对于一大批MapReduce ...
- hadoop 参数调优重点参数
yarn的参数调优,必调参数 28>.yarn.nodemanager.resource.memory-mb 默认为8192.每个节点可分配多少物理内存给YARN使用,考虑到节点上还 可能有其 ...
- 【Spark学习】Apache Spark调优
Spark版本:1.1.0 本文系以开源中国社区的译文为基础,结合官方文档翻译修订而来,转载请注明以下链接: http://www.cnblogs.com/zhangningbo/p/4117981. ...
- spark submit参数及调优
park submit参数介绍 你可以通过spark-submit --help或者spark-shell --help来查看这些参数. 使用格式: ./bin/spark-submit \ ...
随机推荐
- mpvue——另类支持v-html
前言 最近在用mpvue将之前写的vue项目转化为小程序,但是不支持v-html,也不能说不支持,只不过转化为了rich-text的富文本组件,但是图片显示不全啊 本来想让后端内嵌个样式的,还是算了, ...
- Android查看联系人简单记录
简单实现打印联系人信息,可以作为插入联系人的基础和主要代码块,作为个人记录的小逻辑 package com.lgqrlchinese.contactstest; import android.Mani ...
- BZOJ 3669 魔法森林
LCT维护生成树 先按照a的权值把边排序,离线维护b的最小生成树. 将a排序后,依次动态加边,我们只需要关注b的值.要保证1-n花费最少,两点间的b值肯定是越小越好,所以我们可以考虑以b为关键字维护最 ...
- PHP 加解密方法大全
最近看见一篇文章讲的是PHP的加解密方法,正好也自己学习下,顺便以后有用到的地方也好能快速用上,仅供自己学习和复习,好了不多BB,上代码. 基于这几个函数可逆转的加密为:base64_encode() ...
- JS正则与PHP正则
- 第二十节: 深入理解并发机制以及解决方案(锁机制、EF自有机制、队列模式等)
一. 理解并发机制 1. 什么是并发,并发与多线程有什么关系? ①. 先从广义上来说,或者从实际场景上来说. 高并发通常是海量用户同时访问(比如:12306买票.淘宝的双十一抢购),如果把一个用户看做 ...
- pymysql常见问题
1.Python中pymysql出现乱码的解决方法 一般来说,在使用mysql最麻烦的问题在于乱码. 查看mysql的编码: show variables like 'character_set_%' ...
- django - 总结 - 用户认证组件
用户认证组件 from django.contrib import auth 从auth_user表中获取对象,没有返回None,其中密码为密文,使用了加密算法 user = auth.authent ...
- table 表格固定表头和第一列、内容可滚动
整理了下: <!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" c ...
- JGUI源码:解决手机端点击出现半透明阴影(4)
下面开始进入正题,问题发现与解决 1.According解决手机浏览器点击出现半透明阴影 手机下点击有白色蒙版,原始效果如下,看起来很不协调 2.解决办法:增加 -webkit-tap-highlig ...