Note of Jieba ( 词云图实例 )
Note of Jieba
jieba库是python 一个重要的第三方中文分词函数库,但需要用户自行安装。
一、jieba 库简介
(1) jieba 库的分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动态规划方法找到最大概率的词组;除此之外,jieba 库还提供了增加自定义中文单词的功能。
(2) jieba 库支持3种分词模式:
精确模式:将句子最精确地切开,适合文本分析。
全模式:将句子中所以可以成词的词语都扫描出来,速度非常快,但是不能消除歧义。
搜索引擎模式:在精确模式的基础上,对长分词再次切分,提高召回率,适合搜索引擎分词。
二、安装库函数
(1) 在命令行下输入指令:
pip install jieba
(2) 安装进程:

三、调用库函数
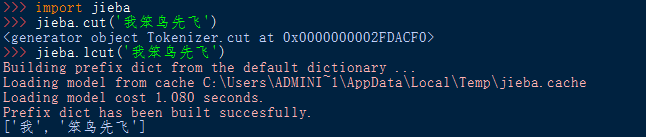
(1) 导入库函数:import <库名>
使用库中函数:<库名> . <函数名> (<函数参数>)
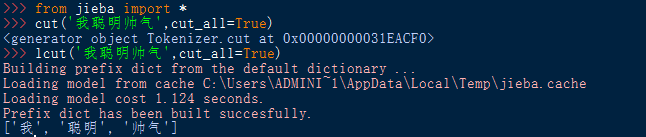
(2) 导入库函数:from <库名> import * ( *为通配符 )
使用库中函数:<函数名> (<函数参数>)
四、jieba 库函数
(1) 库函数功能
|
模式 |
函数 |
说明 |
|
精确模式 |
cut(s) |
返回一个可迭代数据类型 |
|
lcut(s) |
返回一个列表类型 (建议使用) |
|
|
全模式 |
cut(s,cut_all=True) |
输出s中所以可能的分词 |
|
lcut(s,cut_all=True) |
返回一个列表类型 (建议使用) |
|
|
搜索引擎模式 |
cut_for_search(s) |
适合搜索引擎建立索引的分词结果 |
|
lcut_for_search(s) |
返回一个列表类型 (建议使用) |
|
|
自定义新词 |
add_word(w) |
向分词词典中增加新词w |
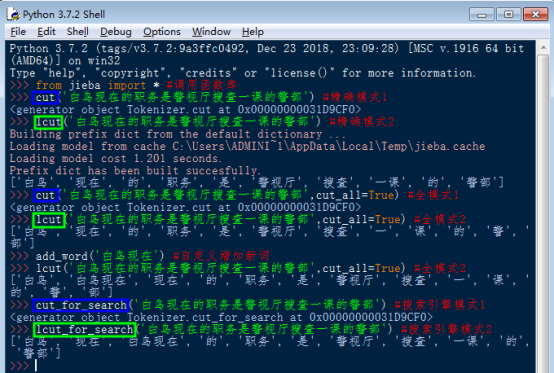
(2) 函数使用实例
五、对一篇文档进行词频统计
(1) jieba 库单枪匹马
A. 代码实现
注:代码使用的文档 >>> Detective_Novel(utf-8).zip[点击下载],也可自行找 utf-8 编码格式的txt文件。
# -*- coding:utf-8 -*-
from jieba import * def Replace(text,old,new): #替换列表的字符串
for char in old:
text = text.replace(char,new)
return text def getText(filename): #读取文件内容(utf-8 编码格式)
#特殊符号和部分无意义的词
sign = '''!~·@¥……*“”‘’\n(){}【】;:"'「,」。-、?'''
txt = open('{}.txt'.format(filename),encoding='utf-8').read()
return Replace(txt,sign," ") def word_count(passage,N): #计算passage文件中的词频数,并将前N个输出
words = lcut(passage) #精确模式分词形式
counts = {} #创建计数器 --- 字典类型
for word in words: #消除同意义的词和遍历计数
if word == '小五' or word == '小五郎' or word == '五郎':
rword = '毛利'
elif word == '柯' or word == '南':
rword = '柯南'
elif word == '小' or word == '兰':
rword = '小兰'
elif word == '目' or word == '暮' or word == '警官':
rword = '暮目'
else:
rword = word
counts[rword] = counts.get(rword,0) + 1
excludes = lcut_for_search("你我事他和她在这也有什么的是就吧啊吗哦呢都了一个")
for word in excludes: #除去意义不大的词语
del(counts[word])
items = list(counts.items()) #转换成列表形式
items.sort(key = lambda x : x[1], reverse = True ) #按次数排序
for i in range(N): #依次输出
word,count = items[i]
print("{:<7}{:>6}".format(word,count)) if __name__ == '__main__':
passage = getText('Detective_Novel') #输入文件名称读入文件内容
word_count(passage,20) #调用函数得到词频数
B. 执行结果
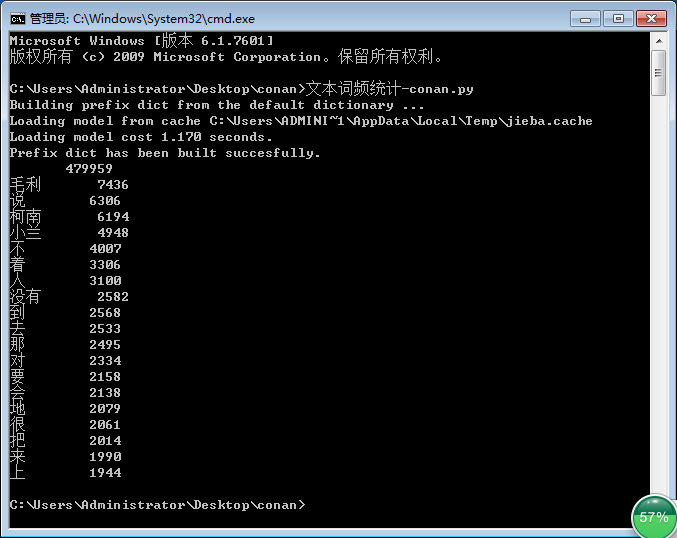
(2) jieba 库 和 wordcloud 库 强强联合 --- 词云图
A. 代码实现
# -*- coding:utf-8 -*-
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
from jieba import * def Replace(text,old,new): #替换列表的字符串
for char in old:
text = text.replace(char,new)
return text def getText(filename): #读取文件内容(utf-8 编码格式)
#特殊符号和部分无意义的词
sign = '''!~·@¥……*“”‘’\n(){}【】;:"'「,」。-、?'''
txt = open('{}.txt'.format(filename),encoding='utf-8').read()
return Replace(txt,sign," ") def creat_word_cloud(filename): #将filename 文件的词语按出现次数输出为词云图
text = getText(filename) #读取文件
wordlist = lcut(text) #jieba库精确模式分词
wl = ' '.join(wordlist) #生成新的字符串 #设置词云图
font = r'C:\Windows\Fonts\simfang.ttf' #设置字体路径
wc = WordCloud(
background_color = 'black', #背景颜色
max_words = 2000, #设置最大显示的词云数
font_path = font, #设置字体形式(在本机系统中)
height = 1200, #图片高度
width = 1600, #图片宽度
max_font_size = 100, #字体最大值
random_state = 100, #配色方案的种类
)
myword = wc.generate(wl) #生成词云
#展示词云图
plt.imshow(myword)
plt.axis('off')
plt.show()
#以原本的filename命名保存词云图
wc.to_file('{}.png'.format(filename)) if __name__ == '__main__':
creat_word_cloud('Detective_Novel') #输入文件名生成词云图
B. 执行结果

Note of Jieba ( 词云图实例 )的更多相关文章
- 超详细:Python(wordcloud+jieba)生成中文词云图
# coding: utf-8 import jieba from scipy.misc import imread # 这是一个处理图像的函数 from wordcloud import WordC ...
- Note of Jieba
Note of Jieba jieba库是python 一个重要的第三方中文分词函数库,但需要用户自行安装. 一.jieba 库简介 (1) jieba 库的分词原理是利用一个中文词库,将待分词的内容 ...
- python 可视化 词云图
文本挖掘及可视化知识链接 我的代码: # -*- coding: utf-8 -*- from pandas import read_csv import numpy as np from sklea ...
- 特朗普退出《巴黎协定》:python词云图舆情分析
1 前言 2017年6月1日,美国特朗普总统正式宣布美国退出<巴黎协定>.宣布退出<巴黎协定>后,特朗普似乎成了“全球公敌”. 特斯拉总裁马斯克宣布退出总统顾问团队 迪士尼董事 ...
- 使用 wordcloud 构建词云图
from wordcloud import WordCloudfrom matplotlib import pyplot as pltfrom PIL import Imageimport numpy ...
- python绘制中文词云图
准备工作 主要用到Python的两个第三方库 jieba:中文分词工具 wordcloud:python下的词云生成工具 步骤 准备语料库,词云图需要的背景图片 使用jieba进行分词,去停用词,词频 ...
- python爬虫+词云图,爬取网易云音乐评论
又到了清明时节,用python爬取了网易云音乐<清明雨上>的评论,统计词频和绘制词云图,记录过程中遇到一些问题 爬取网易云音乐的评论 一开始是按照常规思路,分析网页ajax的传参情况.看到 ...
- [超详细] Python3爬取豆瓣影评、去停用词、词云图、评论关键词绘图处理
爬取豆瓣电影<大侦探皮卡丘>的影评,并做词云图和关键词绘图第一步:找到评论的网页url.https://movie.douban.com/subject/26835471/comments ...
- 已知词频生成词云图(数据库到生成词云)--generate_from_frequencies(WordCloud)
词云图是根据词出现的频率生成词云,词的字体大小表现了其频率大小. 写在前面: 用wc.generate(text)直接生成词频的方法使用很多,所以不再赘述. 但是对于根据generate_from_f ...
随机推荐
- TypeScript体系调研报告
作者简介:aoto 蚂蚁金服·数据体验技术团队 Q:为什么要写这边文章?这篇文章要表达什么? A:我们考虑在SPA应用中使用TS作为开发语言,我们需要一篇系统性介绍TS本身及周边的文章来论证在项目中使 ...
- Linux(1)-卸载挂载分区
> df -lh > fuser -m -v /dev/mapper/autovg-autolv > fuser -m -k -v /dev/mapper/autovg-autolv ...
- JS学习笔记Day10
一.设置或获取元素对象中(标签中)的属性和自定义属性 对象.属性 对象['属性'] 对象.getAttribute('属性名') 对象.setAttribute('属性名','属性值'); 对象.re ...
- 网页三剑客之HTML
Web服务本质 import socket def handle_request(client): request_data = client.recv(1024) print(request_dat ...
- spring定时任务详解(@Scheduled注解)
Spring配置文件xmlns加入 xmlns:task="http://www.springframework.org/schema/task" xsi:schemaLocati ...
- 流程控制if、while、for
if判断 if判断想执行第一个条件,if后的判断必须是True 1 什么是if判断 判断一个条件如果成立则做...不成立则做....2 为何要有if判断 让计算机能够像人一样具有判断的能力3 如何 ...
- 第十七节: EF的CodeFirst模式的四种初始化策略和通过Migration进行数据的迁移
一. 四种初始化策略 EF的CodeFirst模式下数据库的初始化有四种策略: 1. CreateDatabaseIfNotExists:EF的默认策略,数据库不存在,生成数据库:一旦model发生变 ...
- VSCode CSS自动补充前缀
1.安装AuotPrefixer. 2.代码里写css样式后,Ctrl+Shift+P,选择AutoPrefix CSS执行 结果如下
- C#控件数组批量生成控件
在编写C#窗体应用程序的时候,有时候需要生成好多个功能相似的同一种控件(比如数字键盘按键.单选框等),这时候使用窗体编辑器,费时费力,不便于修改.因此可以采用批量生成控件的形式. 以批量生成按钮为例 ...
- python之使用单元测试框架unittest执行自动化测试
Python中有一个自带的单元测试框架是unittest模块,用它来做单元测试,它里面封装好了一些校验返回的结果方法和一些用例执行前的初始化操作. 单元测试框架即一堆工具的集合. 在说unittest ...