数据仓库中的Inmon与Kimball架构
对于数据仓库体系结构的最佳问题,始终存在许多不同的看法,甚至有人把Inmon和Kimball之争称之为数据仓库界的“宗教战争”,那么本文就通过对两位提倡的数据仓库体系和市场流行的另一种体系做简单描述和比较,不是为了下定义那个好,那个不好,而是让初学者更明白两位数据仓库鼻祖对数据仓库体系的见解而已。
首先,我们谈Inmon的企业信息化工厂。
2000年5月,W.H.Inmon在DM Review杂志上发表一篇文章,里面写到一句话“……如果明天非得设计一个数据集市,我将不考虑使用其他的方法”;正是揭示了他的企业信息化工厂的特点。下图是关于他的企业信息化工厂的架构图: 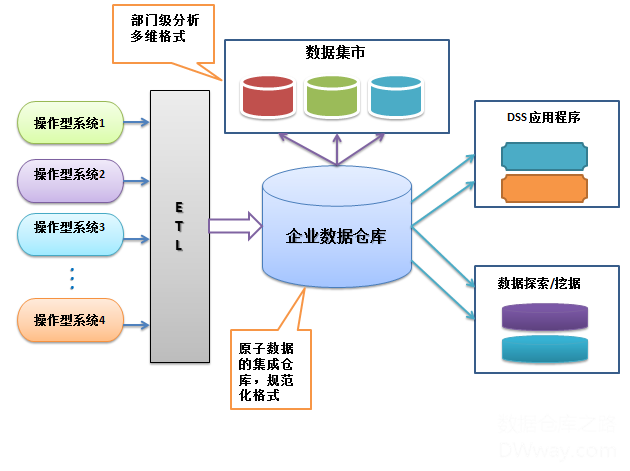
我们理解一下这个体系架构,左边是操作型系统或者事务系统,里面包括很多种系统,有数据库在线系统,有文本文件系统…等等。而这些系统的数据经过ETL的过程,加载数据到企业数据仓库中,ETL的过程是整合不同系统的数据,经过整合,清洗和统一,因此我们可以称之为数据集成。
企业数据仓库是企业信息化工厂的枢纽,是原子数据的集成仓库,但是由于企业数据仓库不是多维格式,因此不适合分析型应用程序,BI工具直接查询。他的目的是将附加的数据存储用于各种分析型系统。
数据集市,是针对不同的主题区域,从企业数据仓库中获取的信息,转换成多维格式,然后通过不同手段的聚集、计算,最后提供最终用户分析使用,因此Inmon把信息从企业数据仓库移动到数据集市的过程描述为“数据交付”。
接下来我们来看Kimball的维度数据仓库:
kimball的维度数据仓库是基于维度模型建立的企业级数据仓库,它的架构有的时候可以称之为“总线体系结构”,和inmon提出的企业信息化工厂有很多相似之处,都是考虑原子数据的集成仓库;我们来根据下面的架构来分析他的观点: 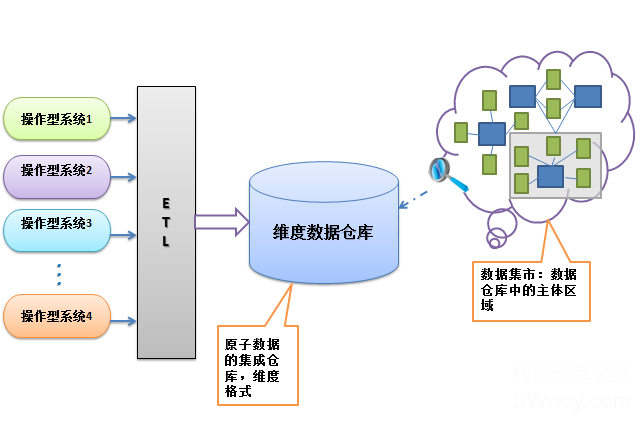
虽然初看两个图有很多不一样的地方,但是这两种结构有很多相似之处:一,都是假设操作型系统和分析型系统是分离的;二,数据源(操作型系统)都是众多;三,ETL整合了多种操作型系统的信息,集中到一个企业数据仓库。
当然如果去区别他们的不同,最大的不同就是企业数据仓库的模式不同,inmon是采用第三范式的格式,而kimball则采用了多维模型–星型模型,并且还是最低粒度的数据存储。其次是,维度数据仓库可以被分析系统直接访问,当然这种访问方式毕竟在分析过程中很少使用。最后就是数据集市的概念有逻辑上的区别,在kimball的架构中,数据集市有维度数据仓库的高亮显示的表的子集来表示。
当然有的时候,在kimball的架构中,有一个可变通的设计,就是在ETL的过程中加入ODS层,使得ODS层中能保留第三范式的一组表来作为ETL过程的过度。但是这个思想,Kimball看来只是ETL的过程辅助而已。另外,还可以把数据集市和企业维度数据仓库分离开来,这样多一层所谓的展现层(presentationlayer),这些变通的设计都是可以接受的,只要符合企业本身分析的需求。
最后一种是独立型数据集市,来自市场的实施过程被广泛使用,下面是独立型数据集市的架构:特点是非常简单,容易实现,而且实施时间段。但是最大的问题是,由于快速的实施,廉价的过程,导致长期费用的提供和效率的低下。 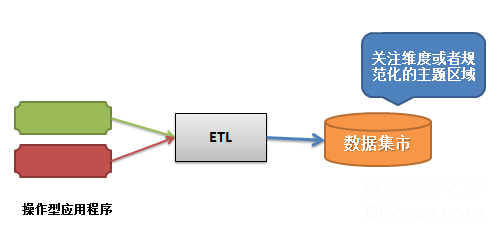
开发一个独立的数据集市是获得可见结果的最有效的方法,因为不需要做跨部门,跨功能的分析,并且数据集市可以很快投入到生产中,因此能够迅速和廉价地获得结果,所以很多机构应用这种方法。而且很多ERP集成商的系统中也自带了类似的功能作为一个卖点来吸引客户。虽然它有很多有点,但是最致命的缺点,短期的成功却带来长期的棘手问题。特别是独立型数据集市支持多主题区域时,会导致多个部门数据不一致,就是数据打架的现象。并且使得各个数据集市成为信息孤岛,缺乏兼容性。因此这种方案很多时候是不可接受的。
通过本文的简要的介绍3种体系结构,希望能帮助你准确的理解数据仓库的体系结构和实施方法。
数据仓库中的Inmon与Kimball架构的更多相关文章
- Inmon和Kimball数仓建模思想
Inmon和Kimball是数据仓库领域伟大的开拓者,他们均多年从事数据仓库的研究,Inmon还被称为“数据仓库之父”.Inmon的<数据仓库>和Kimball的<数据仓库工具箱&g ...
- 深入浅出数据仓库中SQL性能优化之Hive篇
转自:http://www.csdn.net/article/2015-01-13/2823530 一个Hive查询生成多个Map Reduce Job,一个Map Reduce Job又有Map,R ...
- 【SQL系列】深入浅出数据仓库中SQL性能优化之Hive篇
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[SQL系列]深入浅出数据仓库中SQL性能优化之 ...
- 数仓建设中最常用模型--Kimball维度建模详解
数仓建模首推书籍<数据仓库工具箱:维度建模权威指南>,本篇文章参考此书而作.文章首发公众号:五分钟学大数据,公众号中发送"维度建模"即可获取此书籍第三版电子书 先来介绍 ...
- Android Multimedia框架总结(七)C++中MediaPlayer的C/S架构补充及MediaService介绍
转载请把头部出处链接和尾部二维码一起转载,本文出自逆流的鱼,文章链接: http://blog.csdn.net/hejjunlin/article/details/52465168 前面一篇主要介绍 ...
- 微软BI 之SSIS 系列 - 数据仓库中实现 Slowly Changing Dimension 缓慢渐变维度的三种方式
开篇介绍 关于 Slowly Changing Dimension 缓慢渐变维度的理论概念请参看 数据仓库系列 - 缓慢渐变维度 (Slowly Changing Dimension) 常见的三种类型 ...
- Linux 4.21包含对AMD Rome处理器中新的Zen 2架构重要的新优化
导读 Phoronix的Linux爱好者报告说,Linux 4.21里包含对AMD Rome处理器中新的Zen 2架构重要的新优化.AMD新推出的7nm EPYC Rome芯片带来了一种全新的独特架构 ...
- 数据仓库模型建设基础及kimball建模方法总结
观察数据的角度称之为维.决策数据市多为数据,多维数据分析是决策分析的组要内容. OLAP是在OLTP的基础上发展起来的,OLTP是以数据库为基础的,面对的是操作人员和底层管理人员,对基本数据进行查询和 ...
- Spring 中基于 AOP 的 XML架构
Spring 中基于 AOP 的 XML架构 为了使用 aop 命名空间标签,你需要导入 spring-aop j架构,如下所述: <?xml version="1.0" e ...
随机推荐
- mysql普通用户本机无法登录的解决办法
背景 mysql和mariadb的用户表里存在匿名用户时,普通用户出现无法登录的情况 分析 先查看下用户表 mysql> select user, host, password from mys ...
- SpringBoot系列: Pebble模板引擎
===============================Java 模板引擎选择===============================SpringBoot Starter项目向导中可选的J ...
- 算法第四版Question
1.ECLIPES标准输入流 ①Run As-->Run Configurations-->Commom-->Input File在Input File里面输入要读取的文本文件 这对 ...
- 在JS中如何判断所输入的是一个数、整数、正数、非数值?
1.判断是否为一个数字: Number(num)不为 NaN,说明为数字 2. 判断一个数为正数: var num=prompt("请输入:"); if(Number(num)&g ...
- sqlserver 获取所有表的字段类型等信息
USE [MultipleAnalysisDataFY] GO /****** Object: View [dbo].[selectfieldtype] Script Date: 2018/11/7 ...
- SpringBoot学习笔记<二>注解
此篇为项目作结之笔记,关于注解. 项目启动入口@SpringBootApplication[必选] @ServletComponentScan[可选] 注解后: Servlet.Filter.Lis ...
- token的设置与获取
以用户登录为例: application-resources.yml: #用户session在redis中保存的key REDIS_STU_SESSION_KEY: REDIS_USER_SESSIO ...
- django中sqlite迁移mysql
sqlite数据迁移 1 数据备份 django中打开terminalpython manage.py dumpdata authorization > authorization_data.j ...
- 克隆虚拟机+Linux互相登录+秘钥认证(四)
1.虚拟机右键管理_克隆 修改虚拟机名称后完成! 2.开机启动虚拟机 随时保存快照 3.开启两台虚拟机,进行互相登录切换!(W命令查看系统负载) 补充: IP登录: ssh IP: 例如:ssh 19 ...
- 微信小程序:将中文语音直接转化成英文语音
作者:瘟小驹 文章来源<微信小程序个人开发全过程> 准备工作: 准备工具:Eclipse.FileZilla.微信开发者工具.一个配置好SSL证书(https)的有域名的服务器 所需 ...