Apache Flink系列(1)-概述
一、设计思想及介绍
基本思想:“一切数据都是流,批是流的特例”
1.Micro Batching 模式
在Micro-Batching模式的架构实现上就有一个自然流数据流入系统进行攒批的过程,这在一定程度上就增加了延时。具体如下示意图:

2.Native Streaming 模式
Native Streaming 计算模式每条数据的到来都进行计算,这种计算模式显得更自然,并且延时性能达到更低。具体如下示意图:
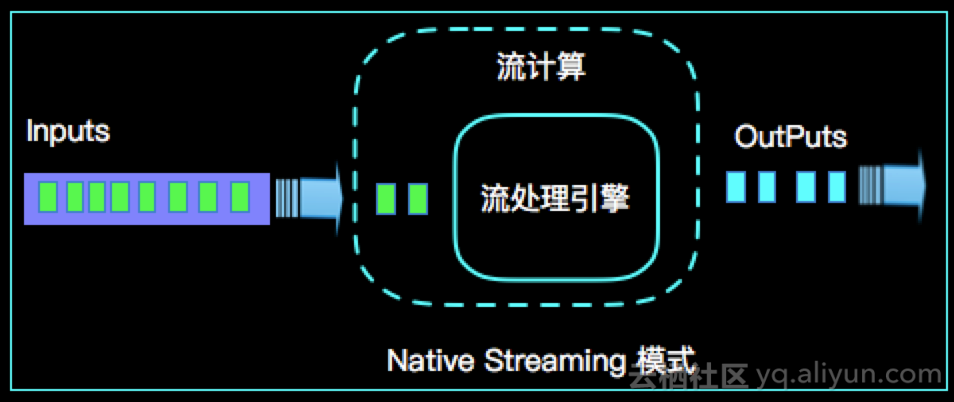
很明显Native Streaming模式占据了流计算领域 "低延时" 的核心竞争力
当然Native Streaming模式的框架实现上面很容易实现Micro-Batching和Batching模式的计算,Apache Flink就是Native Streaming计算模式的流批统一的计算引擎。
二、丰富的部署模式
Apache Flink 按不同的需求支持Local,Cluster,Cloud三种部署模式,同时Apache Flink在部署上能够与其他成熟的生态产品进行完美集成,如 Cluster模式下可以利用YARN(Yet Another Resource Negotiator)/Mesos集成进行资源管理,在Cloud部署模式下可以与GCE(Google Compute Engine), EC2(Elastic Compute Cloud)进行集成。
1.Local 模式
该模式下Apache Flink 整体运行在Single JVM中,在开发学习中使用,同时也可以安装到很多端类设备上。参考
2. Cluster模式
该模式是典型的投产的集群模式,Apache Flink 既可以Standalone的方式进行部署,也可以与其他资源管理系统进行集成部署,比如与YARN进行集成。
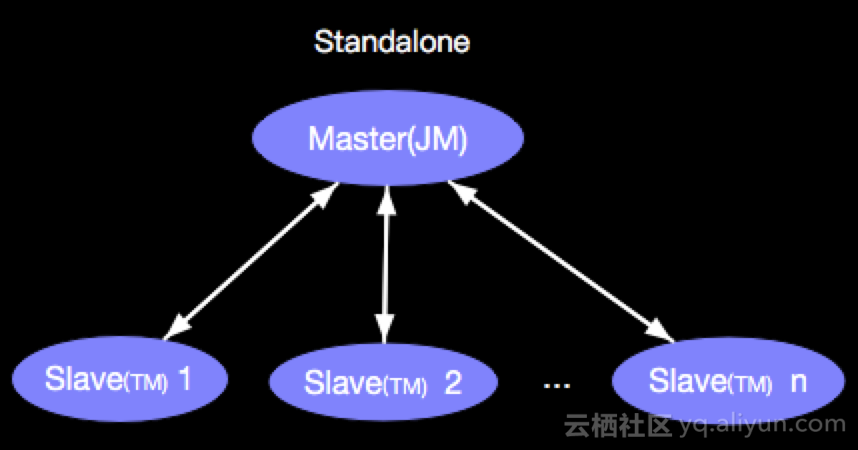
其中JM(JobManager)是Master,TM(TaskManager)是Slave,这种Master/Slave模式有一个典型的问题就是SPOF(single point of failure), SPOF如何解决呢?Apache Flink 又提供了HA(High Availability)方案,也就是提供多个Master,在任何时候总有一个JM服役,N(N>=1)个JM候选,进而解决SPOF问题,示意如下:
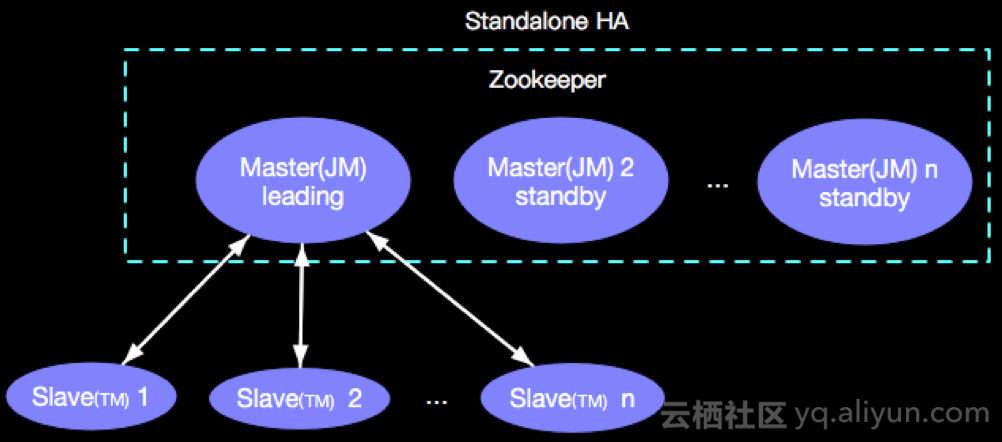
在实际的生产环境我们都会配置HA方案,目前是基于YARN Cluster的HA方案。
3.Cloud 模式
该模式主要是与成熟的云产品进行集成,Apache Flink官网介绍了Google的GCE,Amazon的EC2 ,在Alibaba我们也可以将Apache Flink部署到Alibaba的ECS(Elastic Compute Service)。
三、完善的容错机制
1.什么是容错
容错(Fault Tolerance) 是指容忍故障,在故障发生时能够自动检测出来并使系统能够自动回复正常运行。当出现某些指定的网络故障、硬件故障、软件错误时,系统仍能执行规定的一组程序,或者说程序不会因系统中的故障而中止,并且执行结果也不会因系统故障而引起计算差错。
2.容错的处理模式
在一个分布式系统中由于单个进程或者节点宕机都有可能导致整个Job失败,那么容错机制除了要保证在遇到非预期情况系统能够"运行"外,还要求能"正确运行",也就是数据能按预期的处理方式进行处理,保证计算结果的正确性。计算结果的正确性取决于系统对每一条计算数据处理机制,一般有如下三种处理机制:
- At Most Once:最多消费一次,这种处理机制会存在数据丢失的可能。
- At Least Once:最少消费一次,这种处理机制数据不会丢失,但是有可能重复消费。
- Exactly Once:精确一次,无论何种情况下,数据都只会消费一次,这种机制是对数据准确性的最高要求,在金融支付,银行账务等领域必须采用这种模式。
3.Apache Flink的容错机制
Apache Flink的Job会涉及到3个部分,外部数据源(External Input), Flink内部数据处理(Flink Data Flow)和外部输出(External Output)。如下示意图:
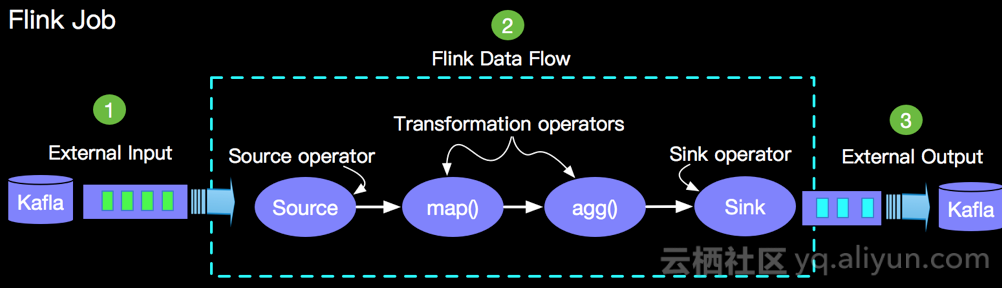
目前Apache Flink 支持两种数据容错机制:
- At Least Once
- Exactly Once
其中 Exactly Once 是最严格的容错机制,该模式要求每条数据必须处理且仅处理一次。那么对于这种严格容错机制,一个完整的Flink Job容错要做到 End-to-End 的 容错必须结合三个部分进行联合处理,根据上图我们考虑三个场景:
场景一:Flink的Source Operator 在读取到Kafla中pos=2000的数据时候,由于某种原因宕机了,这个时候Flink框架会分配一个新的节点继续读取Kafla数据,那么新的处理节点怎样处理才能保证数据处理且只被处理一次呢?

场景二:Flink Data Flow内部某个节点,如果上图的agg()节点发生问题,在恢复之后怎样处理才能保持map()流出的数据处理且只被处理一次?
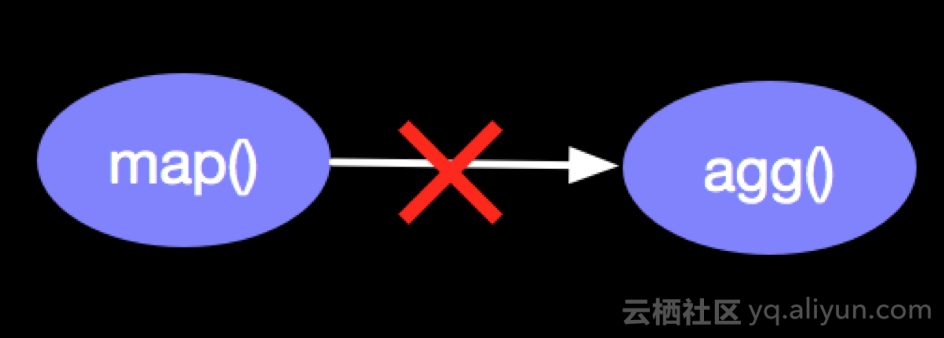
场景三:Flink的Sink Operator 在写入Kafka过程中自身节点出现问题,在恢复之后如何处理,计算结果才能保证写入且只被写入一次?
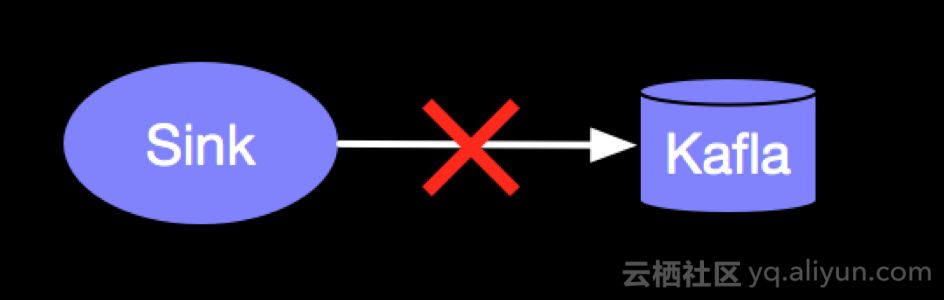
4.系统内部容错
Apache Flink利用Checkpointing机制来处理容错,Checkpointing的理论基础 Stephan 在 Lightweight Asynchronous Snapshots for Distributed Dataflows 进行了细节描述,该机制源于有K. MANI CHANDY和LESLIE LAMPORT 发表的 Determining-Global-States-of-a-Distributed-System Paper。Apache Flink 基于Checkpointing机制对Flink Data Flow实现了At Least Once 和 Exactly Once 两种容错处理模式。
Apache Flink Checkpointing的内部实现会利用 Barriers,StateBackend等后续章节会详细介绍的技术来将数据的处理进行Marker。Apache Flink会利用Barrier将整个流进行标记切分,如下示意图:

这样Apache Flink的每个Operator都会记录当前成功处理的Checkpoint,如果发生错误,就会从上一个成功的Checkpoint开始继续处理后续数据。比如 Soruce Operator会将读取外部数据源的Position实时的记录到Checkpoint中,失败时候会从Checkpoint中读取成功的position继续精准的消费数据。每个算子会在Checkpoint中记录自己恢复时候必须的数据,比如流的原始数据和中间计算结果等信息,在恢复的时候从Checkpoint中读取并持续处理流数据。
5.外部Source容错
Apache Flink 要做到 End-to-End 的 Exactly Once 需要外部Source的支持,比如上面我们说过 Apache Flink的Checkpointing机制会在Source节点记录读取的Position,那就需要外部数据提供读取的Position和支持根据Position进行数据读取。
6.外部Sink容错
Apache Flink 要做到 End-to-End 的 Exactly Once 相对比较困难,如上场景三所述,当Sink Operator节点宕机,重新恢复时候根据Apache Flink 内部系统容错 exactly once的保证,系统会回滚到上次成功的Checkpoin继续写入,但是上次成功Checkpoint之后当前Checkpoint未完成之前已经把一部分新数据写入到kafka了. Apache Flink自上次成功的Checkpoint继续写入kafka,就造成了kafka再次接收到一份同样的来自Sink Operator的数据,进而破坏了End-to-End 的 Exactly Once 语义(重复写入就变成了At Least Once了),如果要解决这一问题,Apache Flink 利用Two phase commit(两阶段提交)的方式来进行处理。本质上是Sink Operator 需要感知整体Checkpoint的完成,并在整体Checkpoint完成时候将计算结果写入Kafka。
四、流批统一的计算引擎
批与流是两种不同的数据处理模式,如Apache Storm只支持流模式的数据处理,Apache Spark只支持批(Micro Batching)模式的数据处理。那么Apache Flink 是如何做到既支持流处理模式也支持批处理模式呢?
1.统一的数据传输层
开篇我们就介绍Apache Flink 的 "命脉"是以"批是流的特例"为导向来进行引擎的设计的,系统设计成为 "Native Streaming"的模式进行数据处理。那么Apache FLink将批模式执行的任务看做是流式处理任务的特殊情况,只是在数据上批是有界的(有限数量的元素)。
Apache Flink 在网络传输层面有两种数据传输模式:
- PIPELINED模式 - 即一条数据被处理完成以后,立刻传输到下一个节点进行处理。
- BATCH 模式 - 即一条数据被处理完成后,并不会立刻传输到下一个节点进行处理,而是写入到缓存区,如果缓存写满就持久化到本地硬盘上,最后当所有数据都被处理完成后,才将数据传输到下一个节点进行处理。
对于批任务而言同样可以利用PIPELINED模式,比如我要做count统计,利用PIPELINED模式能拿到更好的执行性能。只有在特殊情况,比如SortMergeJoin,这时候我们需要全局数据排序,才需要BATCH模式。大部分情况流与批可用统一的传输策略,只有特殊情况,才将批看做是流的一个特例继续特殊处理。
2.统一任务调度层
Apache Flink 在任务调度上流与批共享统一的资源和任务调度机制(后续)
3.统一的用户API层
Apache Flink 在DataStremAPI和DataSetAPI基础上,为用户提供了流批统一的上层TableAPI和SQL,在语法和语义上流批进行高度统一。(其中DataStremAPI和DataSetAPI对流和批进行了分别抽象,这一点并不优雅,在Alibaba内部对其进行了统一抽象)。
4.求同存异
Apache Flink 是流批统一的计算引擎,并不意味着流与批的任务都走统一的code path,在对底层的具体算子的实现也是有各自的处理的,在具体功能上面会根据不同的特性区别处理。比如 批没有Checkpoint机制,流上不能做SortMergeJoin。
五、Apache Flink 架构
1.组件栈
我们上面内容已经介绍了很多Apache Flink的各种组件,下面我们整体概览一下全貌,如下:
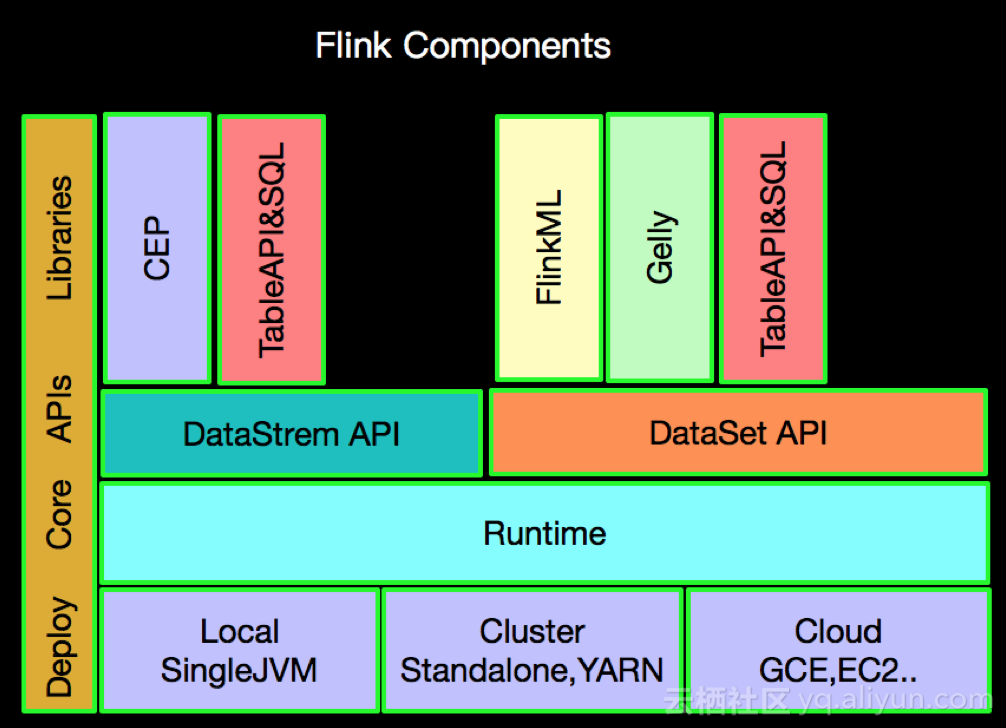
TableAPI和SQL都建立在DataSetAPI和DataStreamAPI的基础之上,那么TableAPI和SQL是如何转换为DataStream和DataSet的呢?
2.TableAPI&SQL到DataStrem&DataSet的架构
TableAPI&SQL最终会经过Calcite优化之后转换为DataStream和DataSet,具体转换示意如下:
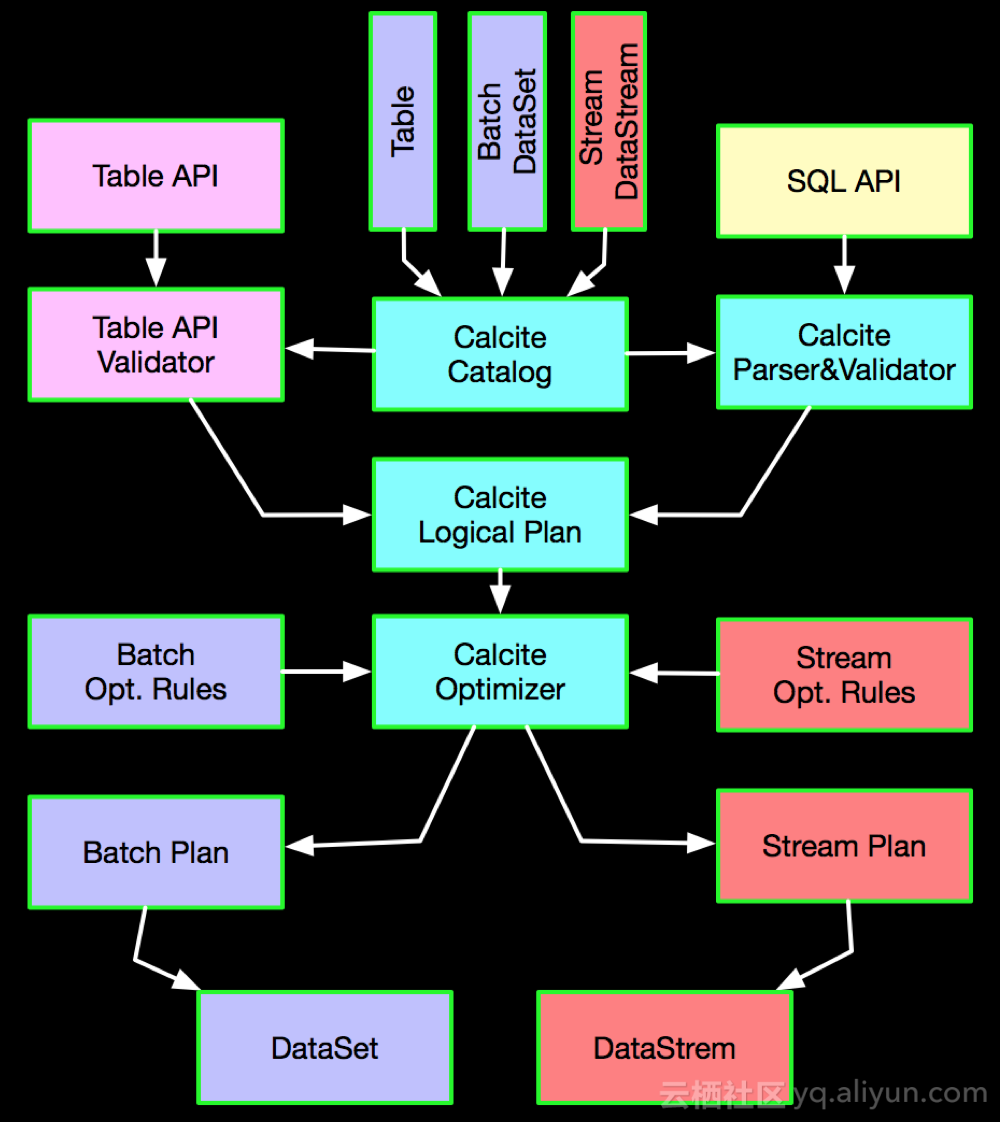
对于流任务最终会转换成DataStream,对于批任务最终会转换成DataSet。
3.ANSI-SQL的支持
Apache Flink 之所以利用ANSI-SQL作为用户统一的开发语言,是因为SQL有着非常明显的优点,如下:

- Declarative - 用户只需要表达我想要什么,不用关心如何计算。
- Optimized - 查询优化器可以为用户的 SQL 生成最优的执行计划,获取最好的查询性能。
- Understandable - SQL语言被不同领域的人所熟知,用SQL 作为跨团队的开发语言可以很大地提高效率。
- Stable - SQL 是一个拥有几十年历史的语言,是一个非常稳定的语言,很少有变动。
- Unify - Apache Flink在引擎上对流与批进行统一,同时又利用ANSI-SQL在语法和语义层面进行统一。
4.无限扩展的优化机制
Apache Flink 利用Apache Calcite对SQL进行解析和优化,Apache Calcite采用Calcite是开源的一套查询引擎,实现了两套Planner:
- HepPlanner - 是RBO(Rule Base Optimize)模式,基于规则的优化。
- VolcanoPlanner - 是CBO(Cost Base Optimize)模式,基于成本的优化。
Flink SQL会利用Calcite解析优化之后,最终转换为底层的DataStrem和Dataset。上图中 Batch rules和Stream rules可以根据优化需要无限添加优化规则。
5.丰富的类库和算子
类库:
- CEP - 复杂事件处理类库,核心是一个状态机,广泛应用于事件驱动的监控预警类业务场景。
- ML - 机器学习类库,机器学习主要是识别数据中的关系、趋势和模式,一般应用在预测类业务场景。
- GELLY - 图计算类库,图计算更多的是考虑边和点的概念,一般被用来解决网状关系的业务场景。
算子:
Apache Flink 提供了丰富的功能算子,对于数据流的处理来讲,可以分为单流处理(一个数据源)和多流处理(多个数据源)。
6.多流操作
- UNION - 将多个字段类型一致数据流合并为一个数据流,如下示意:

- JOIN - 将多个数据流(数据类型可以不一致)联接为一个数据流,如下示意:

如上通过UION和JOIN我们可以将多流最终变成单流,Apache Flink 在单流上提供了更多的操作算子。
7.单流操作
将多流变成单流之后,我们按数据输入输出的不同归类如下:
| 类型 | 输入 | 输出 | Table/SQL算子 | DataStream/DataSet算子 |
|---|---|---|---|---|
| Scalar Function | 1 | 1 | Built-in & UDF, | Map |
| Table Function | 1 | N(N>=0) | Built-in & UDTF | FlatMap |
| Aggregate Function | N(N>=0) | 1 | Built-in & UDAF | Reduce |
如上表格对单流上面操作做简单归类,除此之外还可以做 过滤,排序,窗口等操作,后续章节会逐一介绍。
8.存在的问题
Apache Flink 目前的架构还存在很大的优化空间,比如前面提到的DataStreamAPI和DataSetAPI其实是流与批在API层面不统一的体现,同时看具体实现会发现DataStreamAPI会生成Transformation tree然后生成StreamGraph,最后生成JobGraph,底层对应StreamTask,但DataSetAPI会形成Operator tree,flink-optimize模块会对Batch Plan进行优化,形成Optimized Plan 后形成JobGraph,最后形成BatchTask。具体示意如下: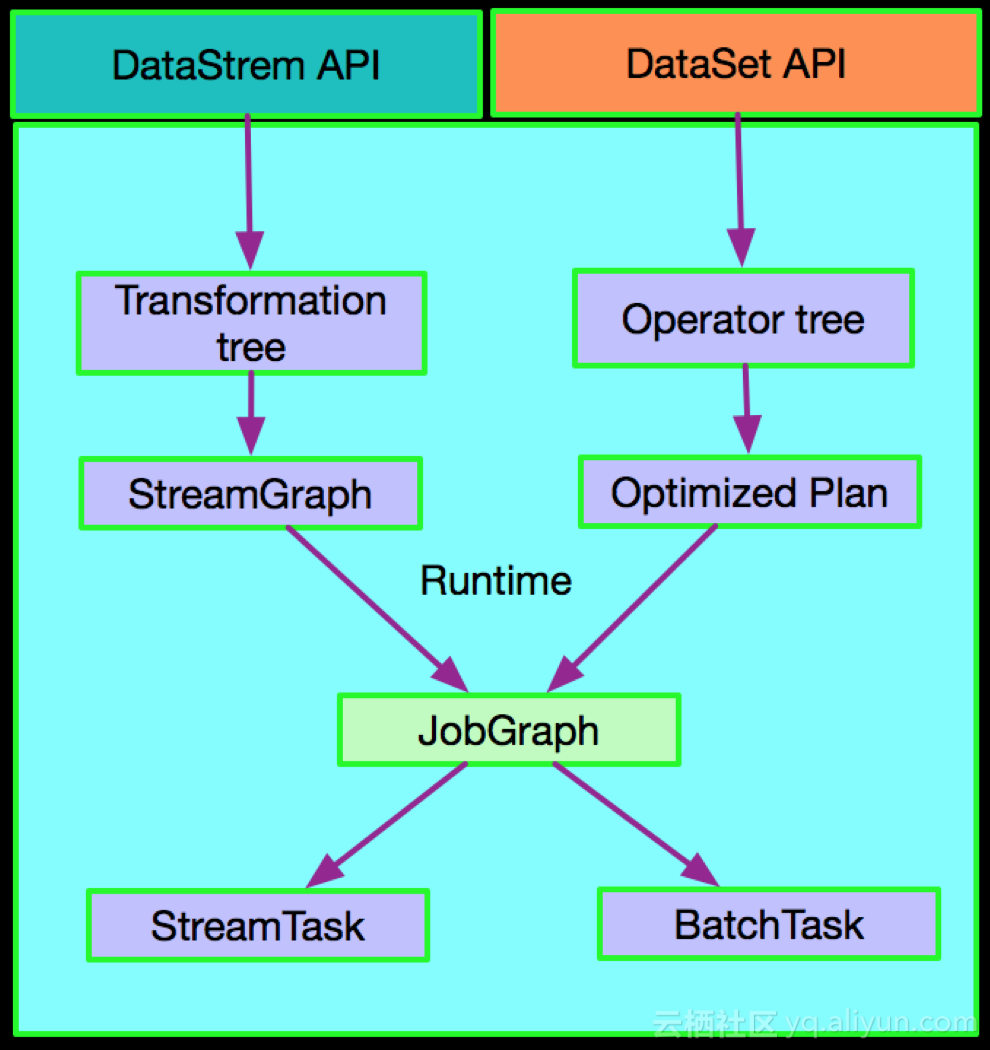
这种情况其实 DataStreamAPI到Runtime 和 DataSetAPI到Runtime的实现上并没有得到最大程度的统一和复用。在这一点上面Aalibab 企业版的Flink在架构和实现上都进行了进一步优化。
六、小结
本篇概要的介绍了"批是流的特例"这一设计观点是Apache Flink的"命脉",它决定了Apache Flink的运行模式是纯流式的,这在实时计算场景的"低延迟"需求上,相对于Micro Batching模式占据了架构的绝对优势。
介绍了Apache Flink的部署模式,容错处理,引擎的统一性和Apache Flink的架构。
Apache Flink系列(1)-概述的更多相关文章
- Apache Flink系列-④有状态函数
有状态函数:独立于平台的有状态无服务器堆栈 这是一种在现代基础设施上创建高效.可扩展且一致的应用程序的简单方法,无论规模大小. 有状态函数是一种API,它通过为无服务器架构构建的运行时简化了分 ...
- Apache Flink 开发环境搭建和应用的配置、部署及运行
https://mp.weixin.qq.com/s/noD2Jv6m-somEMtjWTJh3w 本文是根据 Apache Flink 系列直播课程整理而成,由阿里巴巴高级开发工程师沙晟阳分享,主要 ...
- Apache Flink 进阶(六):Flink 作业执行深度解析
本文根据 Apache Flink 系列直播课程整理而成,由 Apache Flink Contributor.网易云音乐实时计算平台研发工程师岳猛分享.主要分享内容为 Flink Job 执行作业的 ...
- 如何在 Apache Flink 中使用 Python API?
本文根据 Apache Flink 系列直播课程整理而成,由 Apache Flink PMC,阿里巴巴高级技术专家 孙金城 分享.重点为大家介绍 Flink Python API 的现状及未来规划, ...
- Apache Shiro系列之五,概述 —— 配置
Shiro设计的初衷就是可以运行于任何环境:无论是简单的命令行应用程序还是复杂的企业集群应用.由于运行环境的多样性,所以有多种配置机制可用于配置,本节我们将介绍Shiro内核支持的这几种配置机制. ...
- Apache Shiro系列四,概述 —— Shiro的架构
Shiro的设计目标就是让应用程序的安全管理更简单.更直观. 软件系统一般是基于用户故事来做设计.也就是我们会基于一个客户如何与这个软件系统交互来设计用户界面和服务接口.比如,你可能会说:“如 ...
- Apache Shiro系列三,概述 —— 10分钟入门
一.介绍 看完这个10分钟入门之后,你就知道如何在你的应用程序中引入和使用Shiro.以后你再在自己的应用程序中使用Shiro,也应该可以在10分钟内搞定. 二.概述 关于Shiro的废话就不多说了 ...
- Apache Flink 漫谈系列 - JOIN 算子
聊什么 在<Apache Flink 漫谈系列 - SQL概览>中我们介绍了JOIN算子的语义和基本的使用方式,介绍过程中大家发现Apache Flink在语法语义上是遵循ANSI-SQL ...
- Apache Flink流式处理
花了四小时,看完Flink的内容,基本了解了原理. 挖个坑,待总结后填一下. 2019-06-02 01:22:57等欧冠决赛中,填坑. 一.概述 storm最大的特点是快,它的实时性非常好(毫秒级延 ...
随机推荐
- 数据结构Java实现04---树及其相关操作
首先什么是树结构? 树是一种描述非线性层次关系的数据结构,树是n个数据结点的集合,这些集结点包含一个根节点,根节点下有着互相不交叉的子集合,这些子集合便是根节点的子树. 树的特点 在一个树结构中,有且 ...
- $\be$-QGE 的弱强唯一性
在 [Zhao, Jihong; Liu, Qiao. Weak-strong uniqueness criterion for the $\beta$-generalized surface qua ...
- Codeforces 1100F(线性基+贪心)
题目链接 题意 给定序列,$q(1\leq q \leq 100000) $次询问,每次查询给定区间内的最大异或子集. 思路 涉及到最大异或子集肯定从线性基角度入手.将询问按右端点排序后离线处理询问, ...
- MacOS下好用的截图软件snip
1 官网下载,腾讯出的 https://snip.qq.com/ 2 下一步下一步安装就好,然后设置一下自己喜欢的快捷键,我的是command + control+J,选择自己喜欢的或者默认都可以 3 ...
- 第九节,MXNet:用im2rec.py将图像打包生成.rec文件
1.生成.lst文件 制作一个文件路径和标签的列表: import os import sys #第一个参数是输入路径 input_path=sys.argv[1].rstrip(os.sep) #第 ...
- Jhipster 一个Spring Boot + Angular/React 全栈框架
Jhipster 一个Spring Boot + Angular/React 全栈框架: https://www.jhipster.tech/
- sed追加文本-sed脚本追加文本
input为sed输入文件,内容如下: [root@node1 gitlab-test-]# cat inppu.txt aa bb cc dd 追加文本: 1.匹配 aa 行之后追加文本 We a ...
- 038_nginx backlog配置
一. backlog=number sets the backlog parameter in the listen() call that limits the maximum length for ...
- centos7环境下apache2.2.34的编译安装
.获取apache2..34的源码包 http://archive.apache.org/dist/httpd/httpd-2.2.34.tar.gz .获取apache的编译参数 apache的编译 ...
- 【oracle唯一主键SYS_GUID()】
现在给大伙介绍另外的一钟防止主键相同的方法. 唯一主键 使用 SYS_GUID() 生成32位的唯一编码.来生成唯一主键 例如: create table test ( id raw(16) defa ...