Hadoop Compatibility in Flink
18 Nov 2014 by Fabian Hüske (@fhueske)
Apache Hadoop is an industry standard for scalable analytical data processing. Many data analysis applications have been implemented as Hadoop MapReduce jobs and run in clusters around the world. Apache Flink can be an alternative to MapReduce and improves it in many dimensions. Among other features, Flink provides much better performance and offers APIs in Java and Scala, which are very easy to use. Similar to Hadoop, Flink’s APIs provide interfaces for Mapper and Reducer functions, as well as Input- and OutputFormats along with many more operators. While being conceptually equivalent, Hadoop’s MapReduce and Flink’s interfaces for these functions are unfortunately not source compatible.
Flink’s Hadoop Compatibility Package

To close this gap, Flink provides a Hadoop Compatibility package to wrap functions implemented against Hadoop’s MapReduce interfaces and embed them in Flink programs. This package was developed as part of a Google Summer of Code 2014 project.
With the Hadoop Compatibility package, you can reuse all your Hadoop
InputFormats(mapred and mapreduce APIs)OutputFormats(mapred and mapreduce APIs)Mappers(mapred API)Reducers(mapred API)
in Flink programs without changing a line of code. Moreover, Flink also natively supports all Hadoop data types (Writables and WritableComparable).
The following code snippet shows a simple Flink WordCount program that solely uses Hadoop data types, InputFormat, OutputFormat, Mapper, and Reducer functions.
// Definition of Hadoop Mapper function
public class Tokenizer implements Mapper<LongWritable, Text, Text, LongWritable> { ... }
// Definition of Hadoop Reducer function
public class Counter implements Reducer<Text, LongWritable, Text, LongWritable> { ... } public static void main(String[] args) {
final String inputPath = args[0];
final String outputPath = args[1]; final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); // Setup Hadoop’s TextInputFormat
HadoopInputFormat<LongWritable, Text> hadoopInputFormat =
new HadoopInputFormat<LongWritable, Text>(
new TextInputFormat(), LongWritable.class, Text.class, new JobConf());
TextInputFormat.addInputPath(hadoopInputFormat.getJobConf(), new Path(inputPath)); // Read a DataSet with the Hadoop InputFormat
DataSet<Tuple2<LongWritable, Text>> text = env.createInput(hadoopInputFormat);
DataSet<Tuple2<Text, LongWritable>> words = text
// Wrap Tokenizer Mapper function
.flatMap(new HadoopMapFunction<LongWritable, Text, Text, LongWritable>(new Tokenizer()))
.groupBy(0)
// Wrap Counter Reducer function (used as Reducer and Combiner)
.reduceGroup(new HadoopReduceCombineFunction<Text, LongWritable, Text, LongWritable>(
new Counter(), new Counter())); // Setup Hadoop’s TextOutputFormat
HadoopOutputFormat<Text, LongWritable> hadoopOutputFormat =
new HadoopOutputFormat<Text, LongWritable>(
new TextOutputFormat<Text, LongWritable>(), new JobConf());
hadoopOutputFormat.getJobConf().set("mapred.textoutputformat.separator", " ");
TextOutputFormat.setOutputPath(hadoopOutputFormat.getJobConf(), new Path(outputPath)); // Output & Execute
words.output(hadoopOutputFormat);
env.execute("Hadoop Compat WordCount");
}
As you can see, Flink represents Hadoop key-value pairs as Tuple2<key, value> tuples. Note, that the program uses Flink’s groupBy() transformation to group data on the key field (field 0 of the Tuple2<key, value>) before it is given to the Reducer function. At the moment, the compatibility package does not evaluate custom Hadoop partitioners, sorting comparators, or grouping comparators.
Hadoop functions can be used at any position within a Flink program and of course also be mixed with native Flink functions. This means that instead of assembling a workflow of Hadoop jobs in an external driver method or using a workflow scheduler such as Apache Oozie, you can implement an arbitrary complex Flink program consisting of multiple Hadoop Input- and OutputFormats, Mapper and Reducer functions. When executing such a Flink program, data will be pipelined between your Hadoop functions and will not be written to HDFS just for the purpose of data exchange.
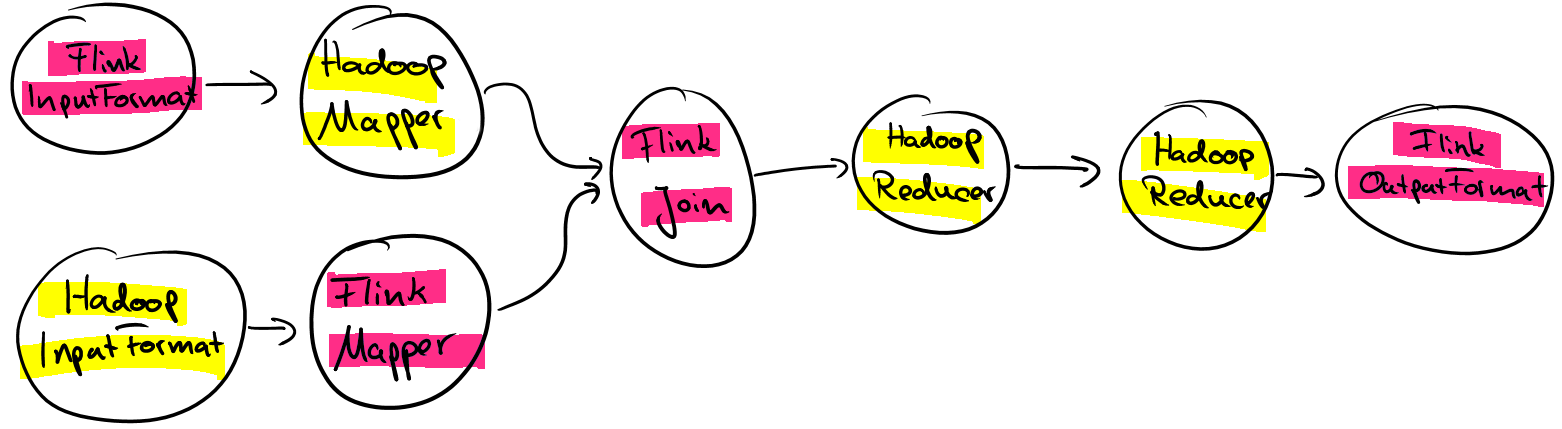
What comes next?
While the Hadoop compatibility package is already very useful, we are currently working on a dedicated Hadoop Job operation to embed and execute Hadoop jobs as a whole in Flink programs, including their custom partitioning, sorting, and grouping code. With this feature, you will be able to chain multiple Hadoop jobs, mix them with Flink functions, and other operations such as Spargel operations (Pregel/Giraph-style jobs).
Summary
Flink lets you reuse a lot of the code you wrote for Hadoop MapReduce, including all data types, all Input- and OutputFormats, and Mapper and Reducers of the mapred-API. Hadoop functions can be used within Flink programs and mixed with all other Flink functions. Due to Flink’s pipelined execution, Hadoop functions can arbitrarily be assembled without data exchange via HDFS. Moreover, the Flink community is currently working on a dedicated Hadoop Job operation to supporting the execution of Hadoop jobs as a whole.
If you want to use Flink’s Hadoop compatibility package checkout our documentation.
Hadoop Compatibility in Flink的更多相关文章
- Hadoop,Spark,Flink 相关KB
Hive: https://stackoverflow.com/questions/17038414/difference-between-hive-internal-tables-and-exter ...
- flink hadoop yarn
新一代大数据处理引擎 Apache Flink https://www.ibm.com/developerworks/cn/opensource/os-cn-apache-flink/ 新一代大数据处 ...
- Flink学习笔记:Flink开发环境搭建
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- flink学习笔记-各种Time
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink Program Guide (1) -- 基本API概念(Basic API Concepts -- For Java)
false false false false EN-US ZH-CN X-NONE /* Style Definitions */ table.MsoNormalTable {mso-style-n ...
- 新一代大数据处理引擎 Apache Flink
https://www.ibm.com/developerworks/cn/opensource/os-cn-apache-flink/index.html 大数据计算引擎的发展 这几年大数据的飞速发 ...
- Flink知识点
1. Flink.Storm.Sparkstreaming对比 Storm只支持流处理任务,数据是一条一条的源源不断地处理,而MapReduce.spark只支持批处理任务,spark-streami ...
- 什么是Apache Flink
大数据计算引擎的发展 这几年大数据的飞速发展,出现了很多热门的开源社区,其中著名的有 Hadoop.Storm,以及后来的 Spark,他们都有着各自专注的应用场景.Spark 掀开了内存计算的先河, ...
- Flink 部署文档
Flink 部署文档 1 先决条件 2 下载 Flink 二进制文件 3 配置 Flink 3.1 flink-conf.yaml 3.2 slaves 4 将配置好的 Flink 分发到其他节点 5 ...
随机推荐
- .netcore使用SocketAsyncEventArgs Pool需要注意!
在.net中做网络通讯往往都会用到SocketAsyncEventArgs,为了得到更好的性能配合Pool复用SocketAsyncEventArgs可以得到一个更好的效果,但在dotnet core ...
- [图解]ARP协议(一)
一.ARP概述 如果要在TCP/IP协议栈中选择一个"最不安全的协议",那么我会毫不犹豫把票投给ARP协议.我们经常听到的这些术语,包括"网络扫描"." ...
- 深度学习(Deep Learning)资料大全(不断更新)
Deep Learning(深度学习)学习笔记(不断更新): Deep Learning(深度学习)学习笔记之系列(一) 深度学习(Deep Learning)资料(不断更新):新增数据集,微信公众号 ...
- [java]static关键字的四种用法
在java的关键字中,static和final是两个我们必须掌握的关键字.不同于其他关键字,他们都有多种用法,而且在一定环境下使用,可以提高程序的运行性能,优化程序的结构.下面我们先来了解一下stat ...
- 一统江湖的大前端(2)—— Mock.js + Node.js 如何与后端潇洒分手
<一统江湖的大前端>系列是自己的前端学习笔记,旨在介绍javascript在非网页开发领域的应用案例和发现各类好玩的js库,不定期更新.如果你对前端的理解还是写写页面绑绑事件,那你真的是有 ...
- HTTP与HTTPS的理解
最近一直也在面试的过程中,可能由于各个方面的问题,导致没有时间抽出更新博客,今天开始陆续更新!!!以后自己的博客,会向React Native,swift ,以及H5延展,成为一个全栈的技术人员.本篇 ...
- IDEA写scala简单操作
今天尝试了一下在IntelliJ IDEA里面写Scala代码,并且做到和Java代码相互调用,折腾了一下把过程记录下来. 首先需要给IntelliJ IDEA安装一下Scala的插件,在IDEA的启 ...
- spring boot 2.0 整合 elasticsearch6.5.3,spring boot 2.0 整合 elasticsearch NoNodeAvailableException
原文地址:spring boot 2.0 整合 elasticsearch NoNodeAvailableException 原文说的有点问题,下面贴出我的配置: 原码云项目地址:https://gi ...
- C# 消息队列-Microsoft Azure service bus 服务总线
先决条件 Visual Studio 2015或更高版本.本教程中的示例使用Visual Studio 2015. Azure订阅. 注意 要完成本教程,您需要一个Azure帐户.您可以激活MSDN订 ...
- 解决echarts饼图不显示数据为0的数据
如图所示 饼图数据为0但是还是会显示lableline和lable 解决方法 var echartData = [{ value: data_arry[0]==0?null:data_arry[0], ...