RabbitMQ进程结构分析与性能调优
RabbitMQ是一个流行的开源消息队列系统,是AMQP(高级消息队列协议)标准的实现,由以高性能、健壮、可伸缩性出名的Erlang语言开发,并继承了这些优点。业界有较多项目使用RabbitMQ,包括OpenStack、spring、Logstash等。
腾讯云在开发云消息队列系统(CMQ)时,对RabbitMQ进行了大量的学习和优化,包括瓶颈分析、内存管理、参数调优等。下文结合Erlang和RabbitMQ架构来分析实践中遇到的问题,并探讨相应的优化方案。
一. RabbitMQ架构分析
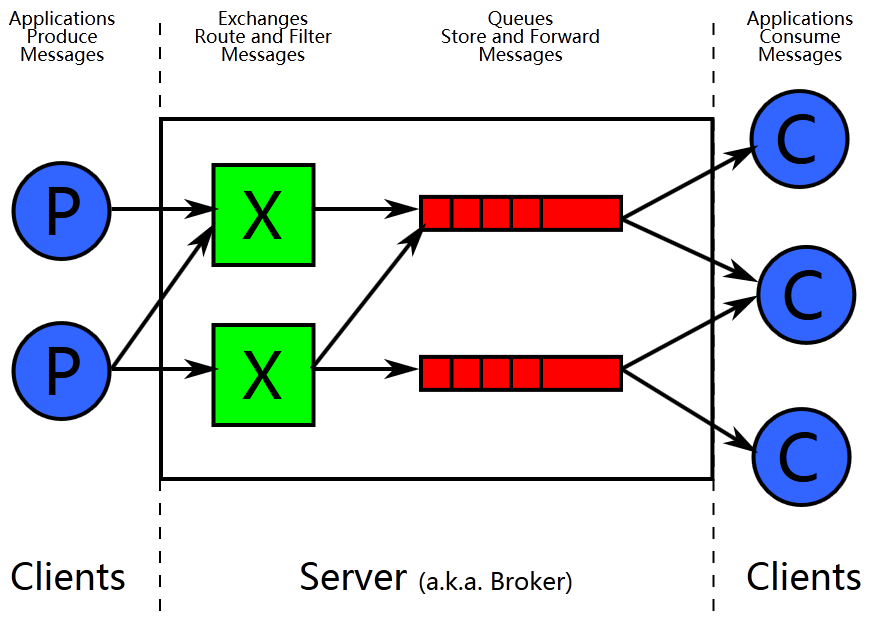
图1 AMQP模型
AMQP是一个异步消息传递所使用的应用层协议规范,AMQP客户端能够无视消息来源任意发送和接受消息,Broker提供消息的路由、队列等功能。Broker主要由Exchange和Queue组成:Exchange负责接收消息、转发消息到绑定的队列;Queue存储消息,提供持久化、队列等功能。AMQP客户端通过Channel与Broker通信,Channel是多路复用连接中的一条独立的双向数据流通道。
1. RabbitMQ进程模型
RabbitMQ Server实现了AMQP模型中Broker部分,将Channel和Queue设计成了Erlang进程,并用Channel进程的运算实现Exchange的功能。
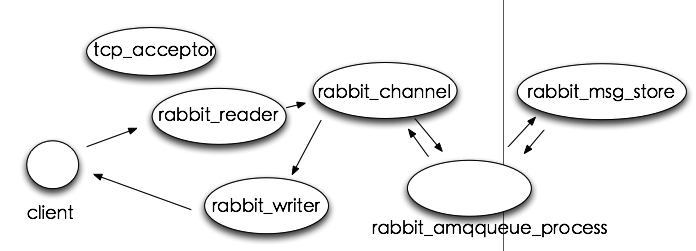
图2 RabbitMQ进程模型
图2中,tcp_acceptor进程接收客户端连接,创建rabbit_reader、rabbit_writer、rabbit_channel进程。rabbit_reader接收客户端连接,解析AMQP帧;rabbit_writer向客户端返回数据;rabbit_channel解析AMQP方法,对消息进行路由,然后发给相应队列进程。rabbit_amqqueue_process是队列进程,在RabbitMQ启动(恢复durable类型队列)或创建队列时创建。rabbit_msg_store是负责消息持久化的进程。
在整个系统中,存在一个tcp_accepter进程,一个rabbit_msg_store进程,有多少个队列就有多少个rabbit_amqqueue_process进程,每个客户端连接对应一个rabbit_reader和rabbit_writer进程。
2. RabbitMQ流控
RabbitMQ可以对内存和磁盘使用量设置阈值,当达到阈值后,生产者将被阻塞(block),直到对应项恢复正常。除了这两个阈值,RabbitMQ在正常情况下还用流控(Flow Control)机制来确保稳定性。
Erlang进程之间并不共享内存(binaries类型除外),而是通过消息传递来通信,每个进程都有自己的进程邮箱。Erlang默认没有对进程邮箱大小设限制,所以当有大量消息持续发往某个进程时,会导致该进程邮箱过大,最终内存溢出并崩溃。
在RabbitMQ中,如果生产者持续高速发送,而消费者消费速度较低时,如果没有流控,很快就会使内部进程邮箱大小达到内存阈值,阻塞生产者(得益于block机制,并不会崩溃)。然后RabbitMQ会进行page操作,将内存中的数据持久化到磁盘中。
为了解决该问题,RabbitMQ使用了一种基于信用证的流控机制。消息处理进程有一个信用组{InitialCredit,MoreCreditAfter},默认值为{200, 50}。消息发送者进程A向接收者进程B发消息,每发一条消息,Credit数量减1,直到为0,A被block住;对于接收者B,每接收MoreCreditAfter条消息,会向A发送一条消息,给予A MoreCreditAfter个Credit,当A的Credit>0时,A可以继续向B发送消息。
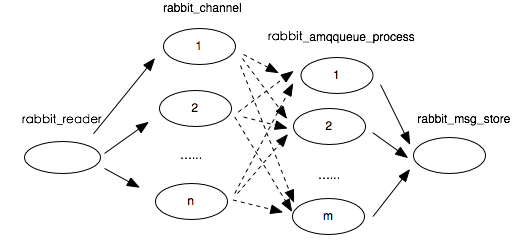
图3 RabbitMQ生产消息传输路径
可以看出基于信用证的流控最终将消息发送进程的发送速度限制在消息处理进程的处理速度内。RabbitMQ中与流控有关的进程构成了一个有向无环图。
3. amqqueue进程与Paging
如上所述,消息的存储和队列功能是在amqqueue进程中实现。为了高效处理入队和出队的消息、避免不必要的磁盘IO,amqqueue进程为消息设计了4种状态和5个内部队列。
4种状态包括:alpha,消息的内容和索引都在内存中;beta,消息的内容在磁盘,索引在内存;gamma,消息的内容在磁盘,索引在磁盘和内存中都有;delta,消息的内容和索引都在磁盘。对于持久化消息,RabbitMQ先将消息的内容和索引保存在磁盘中,然后才处于上面的某种状态(即只可能处于alpha、gamma、delta三种状态之一)。
5个内部队列包括:q1、q2、delta、q3、q4。q1和q4队列中只有alpha状态的消息;q2和q3包含beta和gamma状态的消息;delta队列是消息按序存盘后的一种逻辑队列,只有delta状态的消息。所以delta队列并不在内存中,其他4个队列则是由erlang queue模块实现。

图4 内部队列消息传递顺序
消息从q1入队,q4出队,在内部队列中传递的过程一般是经q1顺序到q4。实际执行并非必然如此:开始时所有队列都为空,消息直接进入q4(没有消息堆积时);内存紧张时将q4队尾部分消息转入q3,进而再由q3转入delta,此时新来的消息将存入q1(有消息堆积时)。
Paging就是在内存紧张时触发的,paging将大量alpha状态的消息转换为beta和gamma;如果内存依然紧张,继续将beta和gamma状态转换为delta状态。Paging是一个持续过程,涉及到大量消息的多种状态转换,所以Paging的开销较大,严重影响系统性能。
二. 问题分析
在生产者、消费者均正常情况下,RabbitMQ压测性能非常稳定,保持在一个恒定的速度。当消费者异常或不消费时,RabbitMQ则表现极不稳定。


图5 消息持久化、无消费场景
测试场景如下,exchange和队列都是持久化的,消息也是持久化的、固定为1K,并且无消费者。如上图所示,在达到内存paging阈值后,生产速率降低,并持续较长时间。内存使用情况表明,在内存中的消息数目只有18M内容,其他消息已经page到磁盘中,然而进程内存仍占用2G。Erlang内存使用表明,Queues占用了2G,Binaries占用了2.1G。
该情况说明在消息从内存page到磁盘后(即从q2、q3队列转到delta后),系统中产生了大量的垃圾(garbage),而Erlang VM没有进行及时的垃圾回收(GC)。这导致RabbitMQ错误的计算了内存使用量,并持续调用paging流程,直到Erlang VM隐式垃圾回收。
三. 内存管理优化
RabbitMQ内存使用量的计算是在memory_monitor进程内执行的,该进程周期性计算系统内存使用量。同时amqqueue进程会周期性拉取内存使用量,当内存达到paging阈值时,触发amqqueue进程进行paging。paging发生后,amqqueue进程每收到一条新消息都会对内部队列进行page(每次page都会计算出一定数目的消息存盘)。
该过程可行的优化方案是:在amqqueue进程将大部分消息paging到磁盘后,显式调用GC,同时将memory_monitor周期设为0.5s、amqqueue拉取周期设为1s,这样就能够达到秒级恢复;去掉对每条消息执行paging的操作,用amqqueue周期性拉取内存使用量的操作来触发page,这样能够更快将消息paging到磁盘,而且保持这个周期内生产速度不下降。
具体修改可查看:
https://github.com/rabbitmq/rabbitmq-server/compare/stable...javaforfun:stable
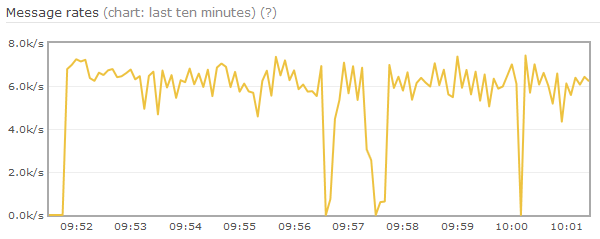
图6 paging时主动垃圾回收
从修改后效果可以看出,三次paging都很快结束,前两次paging相邻较近是因为两个镜像节点分别执行了paging。
该问题已反馈至RabbitMQ社区:
从图5中还可以发现,在22:01时生产速度有一个明显的下降(此时未发生paging)。通过流控分析,链路被block在amqqueue进程;经观察发现节点内存使用下降了,说明该节点执行了GC。Erlang GC是按进程级别的标记-清扫模式,会将当前进程暂停,直至GC结束。由于在RabbitMQ中,一个队列只有一个amqqueue进程,该进程又会处理大量的消息,产生大量的垃圾。这就导致该进程GC较慢,进而流控block上游更长时间。
查看RabbitMQ代码发现,amqqueue进程的gen_server模型在正常的逻辑中调用了hibernate,该操作可能导致两次不必要的GC。优化掉hibernate对系统稳定性有一些帮助。
对流控可能比较好的优化方案是:用多个amqqueue进程来实现一个队列,这样可以降低rabbit_channel被单个amqqueue进程block的概率,同时在单队列的场景下也能更好利用多核的特性。不过该方案对RabbitMQ现有的架构改动很大,难度也很大。
四. 参数调优
RabbitMQ可优化的参数分为两个部分,Erlang部分和RabbitMQ自身。
IO_THREAD_POOL_SIZE:CPU大于或等于16核时,将Erlang异步线程池数目设为100左右,提高文件IO性能。
hipe_compile:开启Erlang HiPE编译选项(相当于Erlang的jit技术),能够提高性能20%-50%。在Erlang R17后HiPE已经相当稳定,RabbitMQ官方也建议开启此选项。
queue_index_embed_msgs_below:RabbitMQ 3.5版本引入了将小消息直接存入队列索引(queue_index)的优化,消息持久化直接在amqqueue进程中处理,不再通过msg_store进程。由于消息在5个内部队列中是有序的,所以不再需要额外的位置索引(msg_store_index)。该优化提高了系统性能10%左右。
vm_memory_high_watermark:用于配置内存阈值,建议小于0.5,因为Erlang GC在最坏情况下会消耗一倍的内存。
vm_memory_high_watermark_paging_ratio:用于配置paging阈值,该值为1时,直接触发内存满阈值,block生产者。
queue_index_max_journal_entries:journal文件是queue_index为避免过多磁盘寻址添加的一层缓冲(内存文件)。对于生产消费正常的情况,消息生产和消费的记录在journal文件中一致,则不用再保存;对于无消费者情况,该文件增加了一次多余的IO操作。
五. 总结
RabbitMQ在2007年发布第一个版本时,只有5000行Erlang代码,到现在已经加入了非常多的特性,但基本架构没有变。从多核的角度看,流控机制和单amqqueue进程之间存在一些冲突,对消费者异常这种场景,还需要从整个架构方面做更多优化。
除了上述内容,RabbitMQ在Cluster、HA、可靠交付、扩展支持等方面也做了大量的工作,这些都值得深入的学习。
RabbitMQ进程结构分析与性能调优的更多相关文章
- Advacned Puppet: Puppet Master性能调优
本文是Advanced Puppet系列的第一篇:Puppet master性能调优,谈一谈如何优化和提高C/S架构下master端的性能. 故事情节往往惊人地类似:你是一名使用Puppet管理线上业 ...
- sqlserver性能调优第一步
相信不少的朋友,无论是做开发.架构的,还是DBA等,都经常听说“调优”这个词.说起“调优”,可能会让很多技术人员心头激情澎湃,也可能会让很多人感觉苦恼,不知道如何入手.当然,也有很多人对此不屑一顾,因 ...
- hadoop 性能调优与运维
hadoop 性能调优与运维 . 硬件选择 . 操作系统调优与jvm调优 . hadoop运维 硬件选择 1) hadoop运行环境 2) 原则一: 主节点可靠性要好于从节点 原则二:多路多核,高频 ...
- JVM性能调优监控工具jps、jstack、jmap、jhat、jstat、hprof使用详解
摘要: JDK本身提供了很多方便的JVM性能调优监控工具,除了集成式的VisualVM和jConsole外,还有jps.jstack.jmap.jhat.jstat.hprof等小巧的工具,本博客希望 ...
- JVM内存模型与性能调优
堆内存(Heap) 堆是由Java虚拟机(JVM,下文提到的JVM特指Sun hotspot JVM)用来存放Java类.对象和静态成员的内存空间,Java程序中创建的所有对象都在堆中分配空间,堆只用 ...
- iOS-------应用性能调优的25个建议和技巧
性能对 iOS 应用的开发尤其重要,如果你的应用失去反应或者很慢,失望的用户会把他们的失望写满App Store的评论.然而由于iOS设备的限制,有时搞好性能是一件难事.开发过程中你会有很多需要注意的 ...
- JVM性能调优监控工具jps、jstack、jmap、jhat、jstat使用详解(转VIII)
JVM本身就是一个java进程,一个java程序运行在一个jvm进程中.多个java程序同时运行就会有多个jvm进程.一个jvm进程有多个线程至少有一个gc线程和一个用户线程. JDK本身提供了很多方 ...
- iOS应用性能调优建议
本文来自iOS Tutorial Team 的 Marcelo Fabri,他是Movile的一名 iOS 程序员.这是他的个人网站:http://www.marcelofabri.com/,你还可以 ...
- Java 应用性能调优实践
Java 应用性能优化是一个老生常谈的话题,笔者根据个人经验,将 Java 性能优化分为 4 个层级:应用层.数据库层.框架层.JVM 层.通过介绍 Java 性能诊断工具和思路,给出搜狗商业平台的性 ...
随机推荐
- js 字符串切割
对于字符串的切割截取平时所用可能不是特别多,而且分的比较细,所以自备自查.有备无患. 由于之前所有均在一个demo测试,若是哪里打错了,敬请谅解.一些其余属性找时间继续添加. 1.函数:split() ...
- MongoDB数据库(一):基本操作
1.NoSQL的概念 "NoSQL"一词最早于1998年被用于一个轻量级的关系数据库的名字 随着web2.0的快速发展,NoSQL概念在2009年被提了出来 NoSQL最常见的解释 ...
- jQuery概念
- [原创]基于Zynq PS与PL之间寄存器映射 Standalone & Linux 例程
基于Zynq PS与PL之间寄存器映射 Standalone & Linux 例程 待添加完善中
- Java练习2
1 编写一个应用程序,模拟机动车的加速和减速功能.机动车类Vehicle的UML图如下,其中speedUp()方法实现加速功能,速度上限为240 km/h:speedDown()实现降速功能,下限为0 ...
- So, How About UMD模块-Universal Module Definition
在ES6模块解决方案出现之前,工具库或包常用三种解决方案提供对外使用的接口,最早是直接暴露给全局变量,比如我们熟知的Jquery暴露的全局变量是$,Lodash对外暴露的全局变量是_,后来出现了AMD ...
- Python 实现整数线性规划:分枝定界法(Branch and Bound)
今天做作业,要实现整数线性规划的分枝定界法算法.找了一些网上的博客,发现都很屎,感觉自己写的这个比较清楚.规范,所以在此记录.如有错误,请指正. from scipy.optimize import ...
- 【MSVC】_invalid_parameter和_invoke_watson
最近遇到一个崩溃问题,崩溃在CRT中,最后调用的函数是_invoke_watson.调用关系大概如下: _invoke_watson _invalid_parameter _invalid_param ...
- zabbix-tomcat监控
安装tomcat 1安装jdk # yum install lrzsz -y #tar xvf jdk # ln -sv /usr/local/src/jdk1..0_79/ /usr/local/j ...
- 2018-2019-2 网络对抗技术 20165220 Exp2 后门原理与实践
实验内容 1.使用netcat获取主机操作Shell,cron启动2.使用socat获取主机操作Shell, 任务计划启动3.使用MSF meterpreter(或其他软件)生成可执行文件,利用nca ...