大数据-hadoop生态之-HDFS
一、HDFS初识
hdfs的概念:
HDFS,它是一个文件系统,用于存储文件,通过目录树定位文件,其次,他是分布式的,由很多服务器联合起来 实现功能,集群中的服务器各有各自的角色
HDFS设计适合一次写入,多次读出的场景,且不支持文件的修改,适合用来做数据分析,并不适合做网盘等应用
HDFS的组成:
HDFS集群包括,NameNode和DataNode以及Secondary NameNode
NameNode负责管理整个文件系统的元数据,以及每一个路径(文件) 所对应的数据块信息
DataNode负责管理用户的文件数据块,每一个数据块可以在多个NameNode上存储多副本
SecondNameNode 用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照
HDFS的快比磁盘块大的原因:
目的是为了最小寻址开销 寻址时间为传输时间的1%时,则为最佳状态。
hdfs-默认Block块大小是128M hadoop2.0以下默认块是64M,通过hdfs的web端 可以看到数据块的BlockId 和 当前数据分为多少个Block 例如2G的数据, 会分成16个Block块. 而且如果最后一个块分配不满的话,会动态伸缩 不会固定占用128M
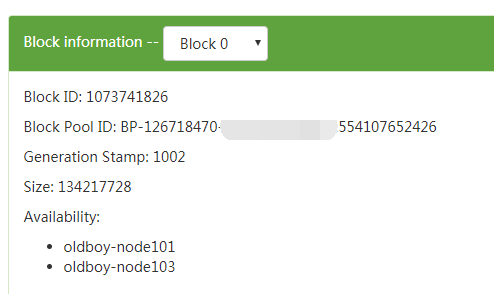
二、当一个DataNode进程挂掉,数据还会继续同步吗?
会的hdfs-client会报错,但是数据会继续上传, 通过web端查看 还会显示3副本,可用副本为2,当DataNode启动后,副本会进行重建, 如果datanode出现问题 client会重新获取datanode节点 进行同步

查看DataNode的日志

三、HDFS启动和停止说明
sbin/hadoop-daemon.sh start namenode 单独启动NameNode守护进程 sbin/hadoop-daemon.sh stop namenode 单独停止NameNode守护进程 sbin/hadoop-daemon.sh start datanode 单独启动DataNode守护进程 sbin/hadoop-daemon.sh stop datanode 单独停止DataNode守护进程
四、HDFS操作命令大全
- -help 输出这个命令的参数




五、HDFS的数据流之文件写入
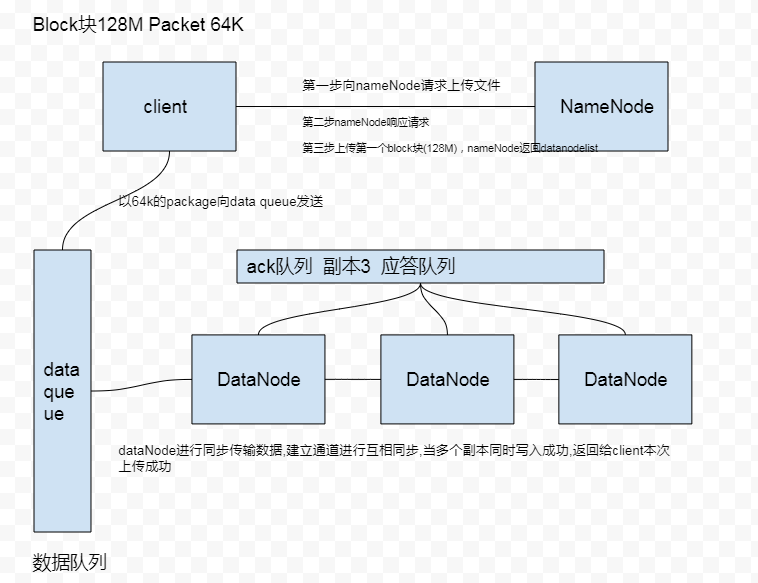
- 客户端向namenode请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
- namenode 返回是否可以上传
- 客户端请求第一个block上传到哪个datanode服务器上
- namenode返回三个datanode节点,分别为dn1,dn2,dn3
- 客户端请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3将这个通信管道建立完成
- dn1、dn2、dn3逐级应答客户端
- 客户端开始往dn1上传第一个block(先从磁盘读取数据放到本地缓存),以packet为单位dn1收到一个packet就会传给dn2,dn2传给dn3,dn1每传一个packet会放入一个应答队列等待应答
- 当一个block传输完成之后,客户端会再次请求namenode上传第二个block
六、HDFS的数据流之文件读取
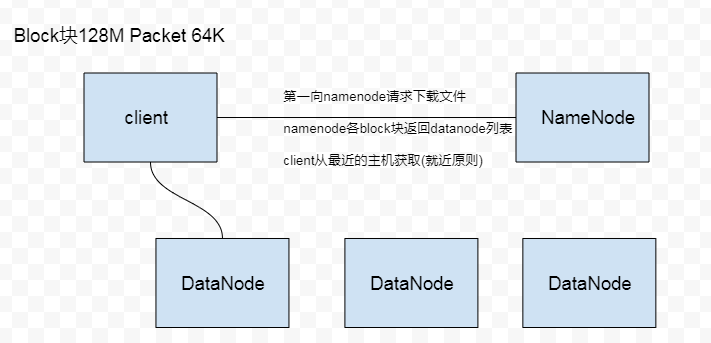
- 客户端向namenode请求下载文件,namenode通过查询元数据,找到文件所在的datanode 地址(多个)
- 通过就近原则 然后随机挑选一台datanode 请求读取数据
- datanode 开始传输数据给客户端(从磁盘里读取数据放入流,以packet为单位校验)
- 客户端以packet为单位接收,现在本地缓存,在写入目标文件
7、HDFS的机架感知
1、查看是否开启机架感知
hdfs dfsadmin -printTopology

hadoop2.7.2副本节点选择
第一个副本在client所处的节点上,如果客户端在集群外,随机选择一个
第二个副本和第一个副本在相同机架,随机节点
第三个副本位于不同机架,随机节点
通过web配置 或者 生成规定格式的Topology文件 在启动hdfs
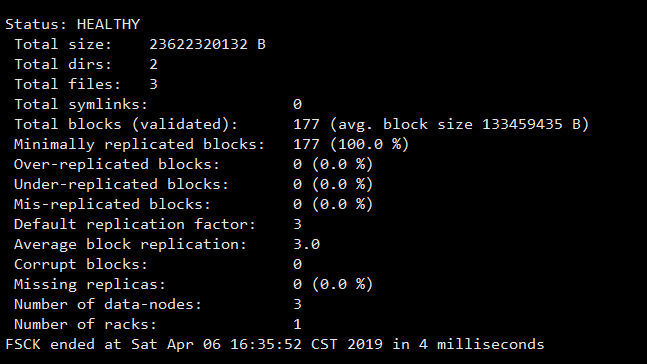
8、HDFS查看Block详细信息
hdfs fsck /data -files -blocks
9、HDFS让编辑日志 进行滚动
hdfs dfsadmin -rollEdits

10、HDFS之NameNode和SecondNameNode工作机制
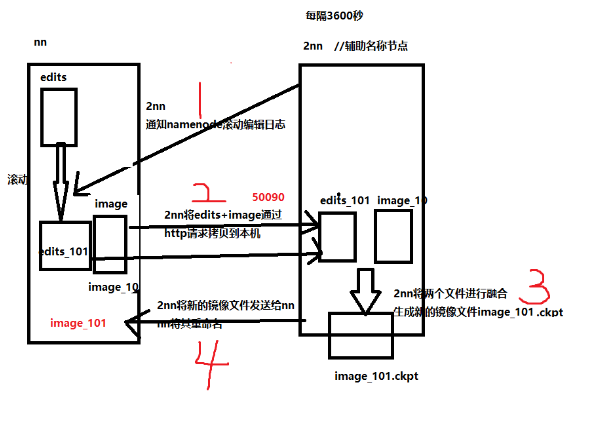
- 第一阶段:nameNode启动
1.第一次启动namenode格式化后,创建fsimage和edits文件,如果不是第一次启动,直接加载编辑日志和镜像文件到内存中
2.客户端对元数据进行增删改的请求
3.NameNode记录操作日志,更新滚动日志 --编辑日志,fsimage只在启动读取(索引)
4.nameNode在内存对数据进行增删改查
2.第二阶段 SecondNameNode工作
1.SecondNameNode询问namenode是否需要checkpoint。直接返回namenode是否检查结果
2.Second NameNode请求执行checkpoint
3.nameNode滚动正在写的edits日志
4.将滚动前的编辑日志和镜像文件拷贝到Second NameNode
5.SecondNameNode加载编辑日志和镜像文件 进行合并
6.生成新的镜像文件fsimage.chkpoint
7.拷贝fsimage.chkpoint到namenode
8.namenode将新的fsimage.chkpoint重命名为fsimage
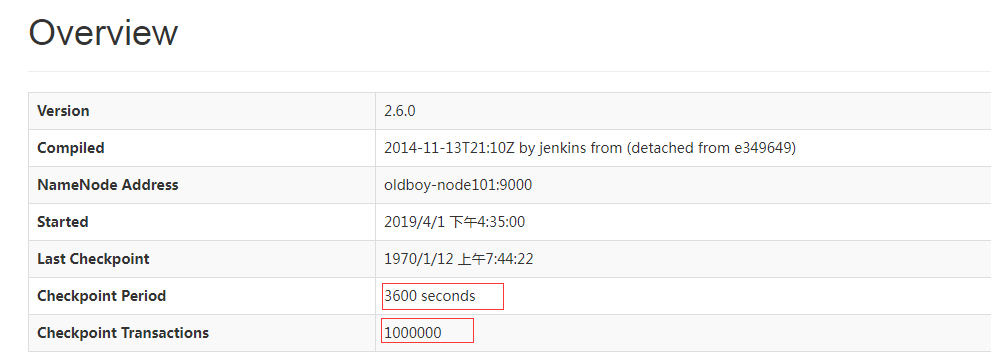
3.web查看Second NameNode http://xxxxx:50090
4.chkpoint检查时间参数设置
通常情况下每隔一个小时执行一次,或者一分钟检查一次操作次数,当操作次数达到1百万时候 执行一次
11、当datanode挂了,通过web端查看 LastContact会一直增加

12、查看namenode版本号
/tmp/dfs/name/current这目录下有个VERSION
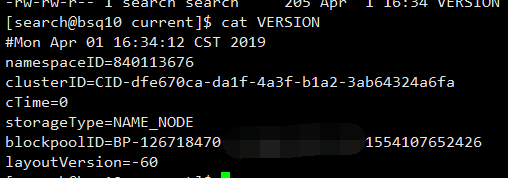
ClusterID 集群的唯一ID 全局唯一
PS:
我今天不小心格式化了两次hdfs 为啥出现datanode就起不来?
解决方案1:
将所有节点的VERSION文件的clusterID改为一致
解决方案2:
将所有节点的临时目录全部删除(data/tmp),重新格式化namenode即可
单独启动所有节点的datanode
hadoop-daemons.sh start datanode
注意:
在格式化hdfs的时候务必要关闭hdfs进程
13、集群安全模式
1.NameNode启动时,首先将镜像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作,一旦在内存成功建立文件系统元数据镜像,则创建一个新的fsimage文件和一个空的编辑日志,此时,nameNode开始监听datanode请求,但是此刻,namenode运行的安全模式,即namenode的文件系统对于客户端是只读的.
系统中的数据块的位置并不是由namenode维护的,而是以块列表的形式存储在datanode中,在系统正常操作期间,namenode会在内存中保留所有的块的映射信息,在安全模式下,各个datanode会向namenode发送最新块列表信息,namenode了解到足够多的块位置之后,既可高效运行文件系统
如果满足"最小副本条件",namenode会在30秒之后退出安全模式,最小条件:整个文件系统99.9%的块满足最小副本级别(默认值:dfs.replication.min=1),在启动一个刚格式化 没有任何块的集群,不会进入安全模式
[search@bsq10 current]$ hdfs dfsadmin -safemode get 查看安全模式
Safe mode is OFF
hdfs dfsadmin -safemode enter 进入安全模式
hdfs dfsadmin -safemode leave 退出安全模式
hdfs dfsadmin -safemode wait 等待安全模式

14、HDFS之DataNode工作机制
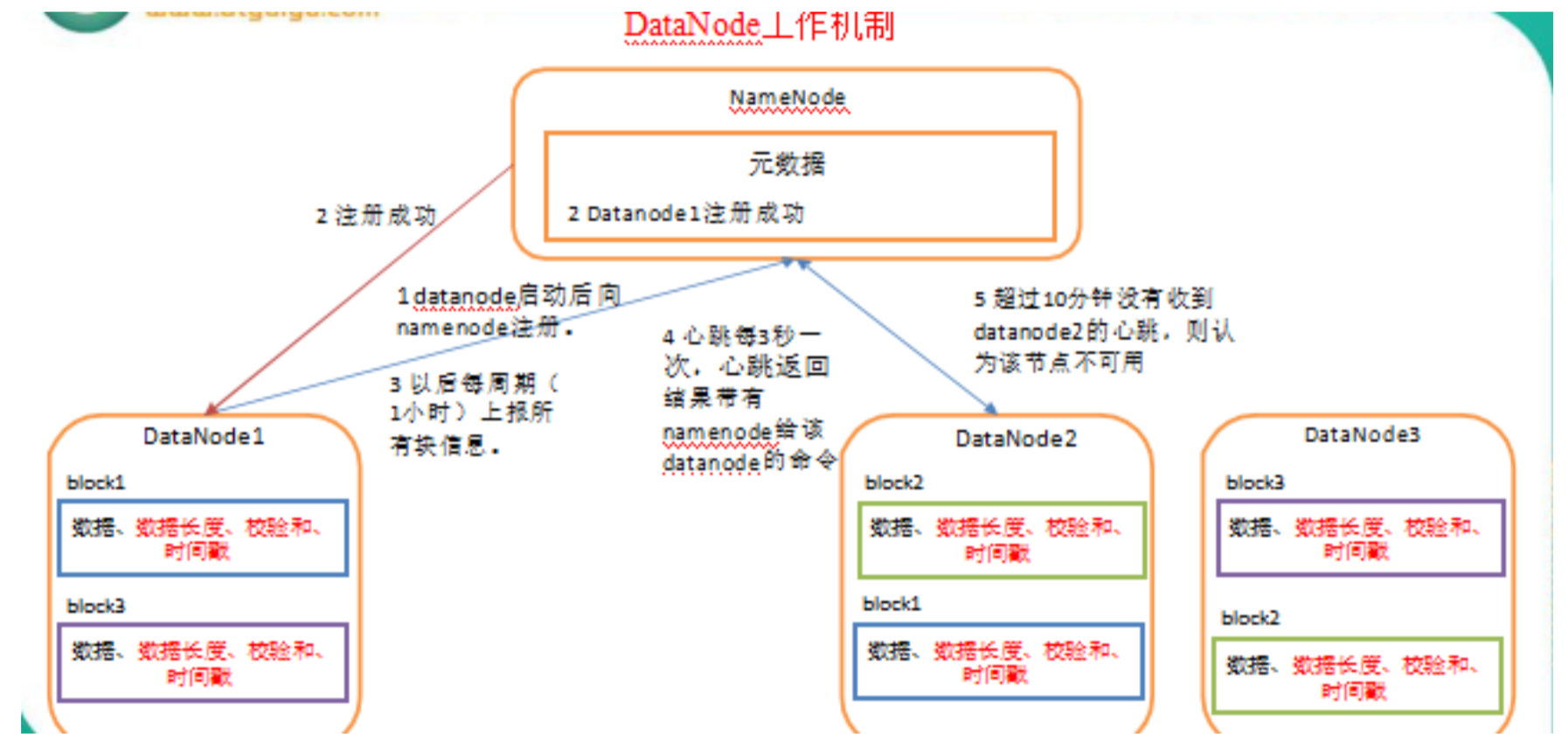
- 一个数据块在datanode上以文件形式存储在磁盘上,包括两个文件 一个是数据本身,一个是元数据包括数据块的长度、块数据的校验和,以及时间戳
- DataNode启动后向namenode注册 通过 周期性(1小时) 向namenode上报所有块的信息
- 心跳是每3秒一次,心跳返回结果带有namenode给该datanode的命令如复制块数据到另外一台机器,或者删除某个数据块,如果超过10分钟没有收到某个datanode的心跳 则确认该节点不可用
- 集群运行中可以安全加入和退出一些机器
15、补充
2nn如何恢复namenode的数据:
1、将2nn的数据放置到namenode的工作目录
2、通过hdfs namenode -recover恢复数据
3、重启hdfs
namenode和Datanode的真实数据(工作目录)
===========================================================
namenode存储HDFS的fsimage(镜像文件) + edits(编辑日志)
(1) Fsimage 文件:HDFS 文件系统元数据的一个永久性的检查点,其中包含 HDFS文件系统的所有目录和文件 idnode 的序列化信息。 //存放所有文件(夹)的索引
(2) Edits 文件:存放 HDFS 文件系统的所有更新的操作,文件系统客户端执行的所有写操作首先会被记录到 edits 文件中。 //存放操作
大数据-hadoop生态之-HDFS的更多相关文章
- 大数据 - hadoop基础概念 - HDFS
Hadoop之HDFS的概念及用法 1.概念介绍 Hadoop是Apache旗下的一个项目.他由HDFS.MapReduce.Hive.HBase和ZooKeeper等成员组成. HDFS是一个高度容 ...
- 大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- 我要进大厂之大数据Hadoop HDFS知识点(1)
01 我们一起学大数据 老刘今天开始了大数据Hadoop知识点的复习,Hadoop包含三个模块,这次先分享出Hadoop中的HDFS模块的基础知识点,也算是对今天复习的内容进行一次总结,希望能够给想学 ...
- 云计算分布式大数据Hadoop实战高手之路第七讲Hadoop图文训练课程:通过HDFS的心跳来测试replication具体的工作机制和流程
这一讲主要深入使用HDFS命令行工具操作Hadoop分布式集群,主要是通过实验的配置hdfs-site.xml文件的心跳来测试replication具体的工作和流程. 通过HDFS的心跳来测试repl ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
- 云计算分布式大数据Hadoop实战高手之路第八讲Hadoop图文训练课程:Hadoop文件系统的操作实战
本讲通过实验的方式讲解Hadoop文件系统的操作. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发布云 ...
- 14周事情总结-机器人-大数据hadoop
14周随着考试的进行,其他该准备的事情也在并行的处理着,考试内容这里不赘述了 首先说下,关于机器人大赛的事情,受益颇多,机器人的制作需要机械和电控两方面 昨天参与舵机的测试,遇到的问题:舵机不动 排查 ...
- 成都大数据Hadoop与Spark技术培训班
成都大数据Hadoop与Spark技术培训班 中国信息化培训中心特推出了大数据技术架构及应用实战课程培训班,通过专业的大数据Hadoop与Spark技术架构体系与业界真实案例来全面提升大数据工程师 ...
- 大数据Hadoop学习之搭建hadoop平台(2.2)
关于大数据,一看就懂,一懂就懵. 一.概述 本文介绍如何搭建hadoop分布式集群环境,前面文章已经介绍了如何搭建hadoop单机环境和伪分布式环境,如需要,请参看:大数据Hadoop学习之搭建had ...
随机推荐
- java压缩指定目录下的所有文件和文件夹的代码
将代码过程较好的代码段备份一下,下边资料是关于java压缩指定目录下的所有文件和文件夹的代码,希望对码农有帮助. String sourceDir="E:\test";int pa ...
- mysql表与表之间数据的转移
1.相同表结构 INSERT INTO table1 SELECT * FROM table2; 2.不同表结构 INSERT INTO table1(filed1,...,filedn) SELEC ...
- java拦截器(interceptor)
1.声明式 (1)注解,使用Aspect的@Aspect (2)实现HandlerInterceptor /** * 拦截请求 * * @author Administrator * */ @Comp ...
- NT路径,DOS路径和Device路径互相转换
项目中遇到的比较奇葩的问题,从网上找到一份源码,https://blog.csdn.net/qq125096885/article/details/70766206 稍微整理了下,VS可以直接编译 # ...
- MongoDB索引基本操作
一.简介 在MongoDB建立索引能提高查询效率,只需要扫描索引只存储的这个集合的一小部分,并只把这小部分加载到内存中,效率大大的提高,如果没有建立索引,在查询时,MongoDB必须执行全表扫描,在数 ...
- 编译装php7.2 && nginx-1.14
环境准备 # cat /etc/centos-release CentOS Linux release 7.6.1810 (Core) # uname -r 3.10.0-957.el7.x86_64 ...
- 如何在FineUIMvc(ASP.NET MVC)中显示复杂的表格列数据(列表和对象)?
起源 最初,这个问题是知识星球内的一个网友提出的,如何在FineUIMvc中展现复杂的列数据? 在FineUIPro中,我们都知道有一个 TemplateField 模板列可以使用,我们只需要在后台定 ...
- 求导程序编写(oo-java编程)
本单元的任务为求导. 即将一个含自变量x的多项式F求导成为另外一个含自变量x的多项式f.使得 dF/dx = f 为降低我们的难度,这个任务被分解成了三个阶段: (1)对幂函数进行求导(不允许嵌套) ...
- 前后端分离与 restful api
为什么要前后端分离(优点): PC,APP,PAD 多端适应 单页面应用(Single Page Application)SPA开发模式开始流行 前后端开发职责不清 开发效率问题,前后端互相等待 前端 ...
- Vim安装使用和配置
卸载vim sudo apt-get remove --purge vim (--purge 是完全删除,会连配置文件一起删除) 也可以使用yum等其它方式安装 ,如果提示apt-get命令不存在可以 ...