GO语言系列(四)- 内置函数、闭包与高级数据类型
一、内置函数、递归函数、闭包
内置函数
- 1. close:主要用来关闭channel
- 2. len:用来求长度,比如string、array、slice、map、channel
- 3. new:用来分配内存,主要用来分配值类型,比如int、struct。返回的是指针
- 4. make:用来分配内存,主要用来分配引用类型,比如chan、map、slice
- 5. append:用来追加元素到数组、slice中
- 6. panic和recover:用来做错误处理
- 7. new和make的区别

- package main
- import (
- "errors"
- "fmt"
- )
- func initConfig() (err error) {
- return errors.New("init config failed")
- }
- func test() {
- /*
- defer func() {
- if err := recover(); err != nil {
- fmt.Println(err)
- }
- }()
- */
- err := initConfig()
- if err != nil {
- panic(err)
- }
- return
- }
- func main() {
- test()
- var i int
- fmt.Println(i) // 0
- fmt.Println(&i) // 0xc0000100a8
- j := new(int)
- *j = 100
- fmt.Println(j) // 0xc00005a088
- fmt.Println(*j) // 100
- var a []int // 定义slice
- a = append(a, 10, 20, 354)
- a = append(a, a...) // ...可变参数 slice展开
- fmt.Println(a)
- }
内置函数案例
- package main
- import "fmt"
- func test() {
- s1 := new([]int)
- fmt.Println(s1)
- s2 := make([]int, 10)
- fmt.Println(s2)
- *s1 = make([]int, 5)
- (*s1)[0] = 100
- s2[0] = 100
- fmt.Println(s1)
- fmt.Println(s2)
- return
- }
- func main() {
- test()
- }
内置函数2
- func main() {
- testError()
- afterErrorfunc()
- }
- func testError() {
- defer func() {
- if r := recover(); r != nil {
- fmt.Println("testError() 遇到错误:", r)
- }
- }()
- panic(" \"panic 错误\"")
- fmt.Println("抛出一个错误后继续执行代码")
- }
- func afterErrorfunc() {
- fmt.Println("遇到错误之后 func ")
- }
panic和recover
- func main() {
- err := testError()
- if err != nil {
- fmt.Println("main 函数得到错误类型:", err)
- }
- afterErrorfunc()
- }
- func testError() (err error) {
- defer func() {
- if r := recover(); r != nil {
- fmt.Println("testError() 遇到错误:", r)
- switch x := r.(type) {
- case string:
- err = errors.New(x)
- case error:
- err = x
- default:
- err = errors.New("")
- }
- }
- }()
- panic(" \"panic 错误\"")
- fmt.Println("抛出一个错误后继续执行代码")
- return nil
- }
- func afterErrorfunc() {
- fmt.Println("遇到错误之后 func ")
- }
panic和recover有返回值
递归函数
1. 一个函数调用自己,就叫做递归。
2. 递归设计原则
1)一个大的问题能够分解成相似的小问题
2)定义好出口条件
案例:递归输出hello,实现阶乘,实现斐波那契数
- package main
- import (
- "fmt"
- "time"
- )
- // 递归
- func recusive(n int) {
- fmt.Println("hello", n)
- time.Sleep(time.Second)
- if n > 10 {
- return
- }
- recusive(n + 1) // 至少上百万上千万次递归
- }
- // 阶乘
- func factor(n int) int {
- if n == 1 {
- return 1
- }
- return factor(n-1) * n
- }
- //斐波那契数
- func fab(n int) int {
- if n <= 1 {
- return 1
- }
- return fab(n-1) + fab(n-2)
- }
- func main() {
- // fmt.Println(factor(5))
- recusive(0)
- // for i := 0; i < 10; i++ {
- // fmt.Println(fab(i))
- // }
- }
闭包
闭包:一个函数和与其相关的引用环境组合而成的实体
案例:Adder和为文件名添加后缀
- package main
- import (
- "fmt"
- "strings"
- )
- func Adder() func(int) int {
- var x int
- return func(d int) int {
- x += d
- return x
- }
- }
- func makeSuffix(suffix string) func(string) string {
- return func(name string) string {
- if strings.HasSuffix(name, suffix) == false {
- return name + suffix
- }
- return name
- }
- }
- func main() {
- f := Adder()
- fmt.Println(f(1))
- fmt.Println(f(100))
- fmt.Println(f(1000))
- f1 := makeSuffix(".bmp")
- fmt.Println(f1("test"))
- fmt.Println(f1("pic"))
- f2 := makeSuffix(".jpg")
- fmt.Println(f2("test"))
- fmt.Println(f2("pic"))
- }
二、数组和切片
数组
- 1. 数组:是同一种数据类型的固定长度的序列。
- 2. 数组定义:var a [len]int,比如:var a[5]int,一旦定义,长度不能变
- 3. 长度是数组类型的一部分,因此,var a[5] int和var a[10]int是不同的类型
- 4. 数组可以通过下标进行访问,下标是从0开始,最后一个元素下标是:len-1
- for i := 0; i < len(a); i++ {
- }
- for index, v := range a {
- }
- 5. 访问越界,如果下标在数组合法范围之外,则触发访问越界,会panic
- 6. 数组是值类型,因此改变副本的值,不会改变本身的值
- package main
- import "fmt"
- func test1() {
- var a [10]int
- a[0] = 10
- a[9] = 100
- fmt.Println(a)
- for i := 0; i < len(a); i++ {
- fmt.Println(a[i])
- }
- for index, val := range a {
- fmt.Printf("a[%d]=%d\n", index, val)
- }
- }
- func test2() {
- var a [10]int
- b := a
- b[0] = 100
- fmt.Println(a)
- }
- func test3(arr *[5]int) {
- (*arr)[0] = 1000
- }
- func main() {
- test1()
- test2()
- var a [5]int
- test3(&a)
- fmt.Println(a)
- }
- /*
- [10 0 0 0 0 0 0 0 0 100]
- 10
- 0
- 0
- 0
- 0
- 0
- 0
- 0
- 0
- 100
- a[0]=10
- a[1]=0
- a[2]=0
- a[3]=0
- a[4]=0
- a[5]=0
- a[6]=0
- a[7]=0
- a[8]=0
- a[9]=100
- [0 0 0 0 0 0 0 0 0 0]
- [1000 0 0 0 0]
- */
数组示例一
数组初始化
- a. var age0 [5]int = [5]int{1,2,3}
- b. var age1 = [5]int{1,2,3,4,5}
- c. var age2 = […]int{1,2,3,4,5,6}
- d. var str = [5]string{3:”hello world”, 4:”tom”}
多维数组
- a. var age [5][3]int
- b. var f [2][3]int = [...][3]int{{1, 2, 3}, {7, 8, 9}}
多维数组遍历
- package main
- import (
- "fmt"
- )
- func main() {
- var f [2][3]int = [...][3]int{{1, 2, 3}, {7, 8, 9}}
- for k1, v1 := range f {
- for k2, v2 := range v1 {
- fmt.Printf("(%d,%d)=%d ", k1, k2, v2)
- }
- fmt.Println()
- }
- }
数组示例
- package main
- import (
- "fmt"
- )
- func fab(n int) {
- var a []int
- a = make([]int, n)
- a[0] = 1
- a[1] = 1
- for i := 2; i < n; i++ {
- a[i] = a[i-1] + a[i-2]
- }
- for _, v := range a {
- fmt.Println(v)
- }
- }
- func testArray() {
- var a [5]int = [5]int{1, 2, 3, 4, 5}
- var a1 = [5]int{1, 2, 3, 4, 5}
- var a2 = [...]int{38, 283, 48, 38, 348, 387, 484}
- var a3 = [...]int{1: 100, 3: 200}
- var a4 = [...]string{1: "hello", 3: "world"}
- fmt.Println(a)
- fmt.Println(a1)
- fmt.Println(a2)
- fmt.Println(a3)
- fmt.Println(a4)
- /*
- [1 2 3 4 5]
- [1 2 3 4 5]
- [38 283 48 38 348 387 484]
- [0 100 0 200]
- [ hello world]
- */
- }
- func testArray2() {
- var a [2][5]int = [...][5]int{{1, 2, 3, 4, 5}, {6, 7, 8, 9, 10}}
- for row, v := range a {
- for col, v1 := range v {
- fmt.Printf("(%d,%d)=%d ", row, col, v1)
- }
- fmt.Println()
- }
- }
- func main() {
- fab(10)
- testArray()
- testArray2()
- }
数组示例二
切片
1. 切片相关概念
- 1. 切片:切片是数组的一个引用,因此切片是引用类型
- 2. 切片的长度可以改变,因此,切片是一个可变的数组
- 3. 切片遍历方式和数组一样,可以用len()求长度
- 4. cap可以求出slice最大的容量,0 <= len(slice) <= (array),其中array是slice引用的数组
- 5. 切片的定义:var 变量名 []类型,比如 var str []string var arr []int
2. 切片的相关语法
- 1. 切片初始化:var slice []int = arr[start:end] 包含start到end之间的元素,但不包含end
- 2. Var slice []int = arr[0:end]可以简写为 var slice []int=arr[:end]
- 3. Var slice []int = arr[start:len(arr)] 可以简写为 var slice[]int = arr[start:]
- 4. Var slice []int = arr[0, len(arr)] 可以简写为 var slice[]int = arr[:]
- 5. 如果要切片最后一个元素去掉,可以这么写: Slice = slice[:len(slice)-1]
3. 切片的内存布局
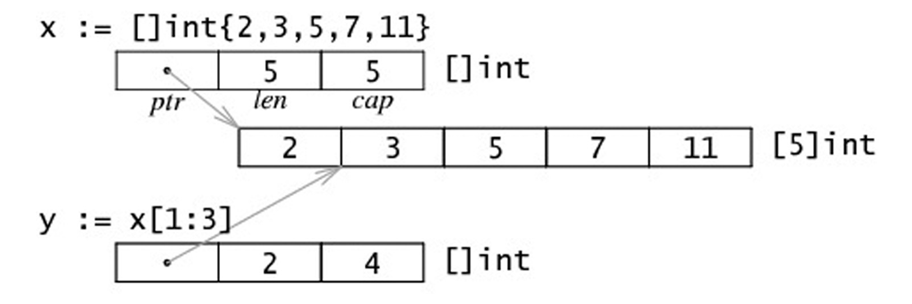
4. 通过make来创建切片
- var slice []type = make([]type, len)
- slice := make([]type, len)
- slice := make([]type, len, cap)
5. 用append内置函数操作切片
- slice = append(slice, 10)
- var a = []int{1,2,3}
- var b = []int{4,5,6}
- a = append(a, b…)
6. For range 遍历切片
- for index, val := range slice {
- }
7. 切片resize
- var a = []int {1,3,4,5}
- b := a[1:2]
- b = b[0:3]
8. 切片拷贝
- s1 := []int{1,2,3,4,5}
- s2 := make([]int, 10)
- copy(s2, s1)
- s3 := []int{1,2,3}
- s3 = append(s3, s2…)
- s3 = append(s3, 4,5,6)
9. string与slice
string底层就是一个byte的数组,因此,也可以进行切片操作
- str := “hello world”
- s1 := str[0:5]
- fmt.Println(s1)
- s2 := str[5:]
- fmt.Println(s2)
10. string的底层布局
11. 如何改变string中的字符值?
string本身是不可变的,因此要改变string中字符,需要如下操作:
- str := “hello world”
- s := []byte(str)
- s[0] = ‘o’
- str = string(s)
12. 排序和查找操作
排序操作主要都在 sort包中,导入就可以使用了
- sort.Ints对整数进行排序, sort.Strings对字符串进行排序, sort.Float64s对
- 浮点数进行排序.
- sort.SearchInts(a []int, b int) 从数组a中查找b,前提是a必须有序
- sort.SearchFloats(a []float64, b float64) 从数组a中查找b,前提是a必须有序
- sort.SearchStrings(a []string, b string) 从数组a中查找b,前提是a必须有序
示例
- package main
- import "fmt"
- type slice struct {
- ptr *[100]int
- len int
- cap int
- }
- func make1(s slice, cap int) slice {
- s.ptr = new([100]int)
- s.cap = cap
- s.len = 0
- return s
- }
- func testSlice() {
- var slice []int
- var arr [5]int = [...]int{1, 2, 3, 4, 5}
- slice = arr[:]
- fmt.Println(slice)
- fmt.Println(arr[2:4]) // [3,4]
- fmt.Println(arr[2:]) // [3,4,5]
- fmt.Println(arr[0:1]) // [1]
- fmt.Println(arr[:len(arr)-1])
- }
- func modify(s slice) {
- s.ptr[1] = 1000
- }
- func testSlice2() {
- var s1 slice
- s1 = make1(s1, 10)
- s1.ptr[0] = 100
- modify(s1)
- fmt.Println(s1.ptr)
- }
- func modify1(a []int) {
- a[1] = 1000
- }
- func testSlice3() {
- var b []int = []int{1, 2, 3, 4}
- modify1(b)
- fmt.Println(b)
- }
- func testSlcie4() {
- var a = [10]int{1, 2, 3, 4}
- b := a[1:5]
- fmt.Printf("%p\n", b) // 0xc000014238
- fmt.Printf("%p\n", &a[1]) // 0xc000014238
- }
- func main() {
- // testSlice()
- testSlice2()
- testSlice3()
- testSlcie4()
- }
切片的用法示例一
- package main
- import "fmt"
- func testSlice() {
- var a [5]int = [...]int{1, 2, 3, 4, 5}
- s := a[1:]
- fmt.Println("a:", a)
- s[1] = 100
- fmt.Printf("s=%p a[1]=%p\n", s, &a[1])
- fmt.Println("before a:", a)
- s = append(s, 10)
- s = append(s, 10)
- s = append(s, 10)
- s = append(s, 10)
- s = append(s, 10)
- s[1] = 1000
- fmt.Println("after a:", a)
- fmt.Println(s)
- fmt.Printf("s=%p a[1]=%p\n", s, &a[1])
- }
- func testCopy() {
- var a []int = []int{1, 2, 3, 4, 5}
- b := make([]int, 10)
- copy(b, a)
- fmt.Println(b)
- }
- func testString() {
- s := "hello world"
- s1 := s[0:5]
- s2 := s[6:]
- fmt.Println(s1)
- fmt.Println(s2)
- }
- func testModifyString() {
- s := "我hello world"
- s1 := []rune(s)
- s1[0] = 200
- s1[1] = 128
- s1[2] = 256
- str := string(s1)
- fmt.Println(str)
- }
- func main() {
- // testSlice()
- testCopy()
- testString()
- testModifyString()
- }
切片的用法示例二
- package main
- import (
- "fmt"
- "sort"
- )
- func testIntSort() {
- var a = [...]int{1, 8, 43, 2, 456}
- sort.Ints(a[:])
- fmt.Println(a)
- }
- func testStrings() {
- var a = [...]string{"abc", "efg", "b", "A", "eeee"}
- sort.Strings(a[:])
- fmt.Println(a)
- }
- func testFloat() {
- var a = [...]float64{2.3, 0.8, 28.2, 392342.2, 0.6}
- sort.Float64s(a[:])
- fmt.Println(a)
- }
- func testIntSearch() {
- var a = [...]int{1, 8, 43, 2, 456}
- index := sort.SearchInts(a[:], 2)
- fmt.Println(index)
- }
- func main() {
- testIntSort()
- testStrings()
- testFloat()
- testIntSearch()
- }
切片的用法示例三
三、map数据结构
1.map简介
key-value的数据结构,又叫字典或关联数组
a.声明
- var map1 map[keytype]valuetype
- var a map[string]string
- var a map[string]int
- var a map[int]string
- var a map[string]map[string]string
声明是不会分配内存的,初始化需要make
2. map相关操作
- var a map[string]string = map[string]string{“hello”: “world”}
- a = make(map[string]string, 10)
- a[“hello”] = “world” // 插入和更新
- Val, ok := a[“hello”] //查找
- for k, v := range a { //遍历
- fmt.Println(k,v)
- }
- delete(a, “hello”) // 删除
- len(a) // 长度
3. map是引用类型
- func modify(a map[string]int) {
- a[“one”] = 134
- }
4. slice of map
- Items := make([]map[int][int], 5)
- For I := 0; I < 5; i++ {
- items[i] = make(map[int][int])
- }
5. map排序
- a. 先获取所有key,把key进行排序
- b. 按照排序好的key,进行遍历
6. Map反转
- a. 初始化另外一个map,把key、value互换即可
示例
- package main
- import "fmt"
- func trans(a map[string]map[string]string) {
- for k, v := range a {
- fmt.Println(k)
- for k1, v1 := range v {
- fmt.Println("\t", k1, v1)
- }
- }
- }
- func testMap() {
- var a map[string]string = map[string]string{
- "key": "value",
- }
- // a := make(map[string]string, 10)
- a["abc"] = "efg"
- a["abc1"] = "wew"
- fmt.Println(a)
- }
- func testMap2() {
- a := make(map[string]map[string]string, 100)
- a["key1"] = make(map[string]string)
- a["key1"]["key2"] = "val2"
- a["key1"]["key3"] = "val3"
- a["key1"]["key4"] = "val4"
- a["key1"]["key5"] = "val5"
- a["key1"]["key6"] = "val6"
- fmt.Println(a)
- }
- func modify(a map[string]map[string]string) {
- _, ok := a["zhangsan"]
- if !ok {
- a["zhangsan"] = make(map[string]string)
- }
- a["zhangsan"]["pwd"] = ""
- a["zhangsan"]["nickname"] = "superman"
- return
- }
- func testMap3() {
- a := make(map[string]map[string]string, 100)
- modify(a)
- fmt.Println(a)
- }
- func testMap4() {
- a := make(map[string]map[string]string, 100)
- a["key1"] = make(map[string]string)
- a["key1"]["key2"] = "val2"
- a["key1"]["key3"] = "val3"
- a["key1"]["key4"] = "val4"
- a["key1"]["key5"] = "val5"
- a["key2"] = make(map[string]string)
- a["key2"]["key22"] = "val22"
- a["key2"]["key23"] = "val23"
- trans(a)
- delete(a, "key1")
- fmt.Println()
- trans(a)
- }
- func testMap5() {
- var a []map[int]int
- a = make([]map[int]int, 5)
- if a[0] == nil {
- a[0] = make(map[int]int)
- }
- a[0][10] = 10
- fmt.Println(a)
- }
- func main() {
- testMap()
- testMap2()
- testMap3()
- testMap4()
- testMap5()
- }
map示例
- package main
- import (
- "fmt"
- "sort"
- )
- func testMapSort() {
- var a map[int]int
- a = make(map[int]int, 5)
- a[8] = 10
- a[3] = 10
- a[2] = 10
- a[1] = 10
- a[18] = 10
- var keys []int
- for k, _ := range a {
- keys = append(keys, k)
- // fmt.Println(k, v)
- }
- sort.Ints(keys)
- for _, v := range keys {
- fmt.Println(v, a[v])
- }
- }
- func testMapSort2() {
- var a map[string]int
- var b map[int]string
- a = make(map[string]int, 5)
- b = make(map[int]string, 5)
- a[""] = 10
- a[""] = 11
- a[""] = 12
- a[""] = 13
- a[""] = 14
- for k, v := range a {
- b[v] = k
- }
- fmt.Println(b)
- }
- func main() {
- testMapSort()
- testMapSort2()
- }
map示例2
四、包
1. golang中的包
a. golang目前有150个标准的包,覆盖了几乎所有的基础库
b. golang.org有所有包的文档,没事都翻翻
2. 线程同步
- a. import(“sync”)
- b. 互斥锁, var mu sync.Mutex
- c. 读写锁, var mu sync.RWMutex
- package main
- import (
- "fmt"
- "math/rand"
- "sync"
- "sync/atomic"
- "time"
- )
- var rwLock *sync.RWMutex
- func testLock() {
- var a map[int]int
- a = make(map[int]int, 5)
- a[8] = 10
- a[3] = 10
- a[2] = 10
- a[1] = 10
- a[18] = 10
- for i := 0; i < 2; i++ {
- go func(b map[int]int) {
- rwLock.RLock()
- b[8] = rand.Intn(100)
- rwLock.Unlock()
- }(a)
- }
- rwLock.RLock()
- fmt.Println(a)
- rwLock.Unlock()
- }
- func testRWLock() {
- // var rwLock myLocker = new(sync.RWMutex)
- // var rwLock sync.RWMutex
- // var rwLock sync.Mutex
- var a map[int]int
- a = make(map[int]int, 5)
- var count int32
- a[8] = 10
- a[3] = 10
- a[2] = 10
- a[1] = 10
- a[18] = 10
- for i := 0; i < 2; i++ {
- go func(b map[int]int) {
- rwLock.Lock()
- // lock.Lock()
- b[8] = rand.Intn(100)
- time.Sleep(time.Millisecond)
- rwLock.Unlock()
- // lock.Unlock()
- }(a)
- }
- for i := 0; i < 100; i++ {
- go func(b map[int]int) {
- for {
- rwLock.Lock()
- time.Sleep(time.Millisecond)
- // fmt.Println(a)
- rwLock.Unlock()
- atomic.AddInt32(&count, 1)
- }
- }(a)
- }
- time.Sleep(time.Second * 3)
- fmt.Println(atomic.LoadInt32(&count))
- }
- func main() {
- rwLock = new(sync.RWMutex)
- // testLock()
- testRWLock()
- }
线程同步锁示例
3. go get安装第三方包
- go get github.com/go-sql-driver/mysql
本节作业
1. 冒泡排序
2. 选择排序
3. 插入排序
4.快速排序
参考
- package main
- import "fmt"
- // 冒泡排序:本质上是交换排序的一种
- func bsort(a []int) {
- for i := 0; i < len(a); i++ {
- for j := 1; j < len(a)-i; j++ {
- if a[j] < a[j-1] {
- a[j], a[j-1] = a[j-1], a[j]
- }
- }
- }
- }
- func main() {
- b := [...]int{8, 7, 4, 5, 3, 2, 1}
- bsort(b[:])
- fmt.Println(b)
- }
冒泡排序
- package main
- import "fmt"
- // 选择排序
- func ssort(a []int) {
- for i := 0; i < len(a); i++ {
- var min int = i
- for j := i + 1; j < len(a); j++ {
- if a[min] > a[j] {
- min = j
- }
- }
- if min != i {
- a[i], a[min] = a[min], a[i]
- }
- }
- }
- func main() {
- b := [...]int{8, 7, 4, 5, 3, 2, 1}
- ssort(b[:])
- fmt.Println(b)
- }
选择排序
- package main
- import "fmt"
- // 插入排序, 每次将一个数插入到有序序列当中合适的位置
- func isort(a []int) {
- for i := 1; i < len(a); i++ {
- for j := i; j > 0; j-- {
- if a[j] > a[j-1] {
- break
- }
- a[j], a[j-1] = a[j-1], a[j]
- }
- }
- }
- func main() {
- b := [...]int{8, 7, 4, 5, 3, 2, 1}
- isort(b[:])
- fmt.Println(b)
- }
插入排序
- package main
- import "fmt"
- // 快速排序, 一次排序确定一个元素的位置, 使左边的元素都比它小,右边的元素都比它大
- func qsort(a []int, left, right int) {
- if left >= right {
- return
- }
- val := a[left]
- // 确定val所在的位置
- k := left
- for i := left + 1; i <= right; i++ {
- if a[i] < val {
- a[k] = a[i]
- a[i] = a[k+1]
- k++
- }
- }
- a[k] = val
- qsort(a, left, k-1)
- qsort(a, k+1, right)
- }
- func main() {
- b := [...]int{8, 7, 4, 5, 3, 2, 1}
- qsort(b[:], 0, len(b)-1)
- fmt.Println(b)
- }
快速排序
GO语言系列(四)- 内置函数、闭包与高级数据类型的更多相关文章
- 12.Python略有小成(生成器,推导式,内置函数,闭包)
Python(生成器,推导式,内置函数,闭包) 一.生成器初始 生成器的本质就是迭代器,python社区中认为生成器与迭代器是一种 生成器与迭代器的唯一区别,生成器是我们自己用python代码构建成的 ...
- Python函数05/内置函数/闭包
Python函数05/内置函数/闭包 目录 Python函数05/内置函数/闭包 内容大纲 1.内置函数(二) 2.匿名函数及内置函数(重要) 3.闭包 4.今日总结 5.今日练习 内容大纲 1.内置 ...
- 面向对象 反射 和item系列和内置函数和__getattr__和__setattr__
反射 反射主要用在网络编程中, python面向对象的反射:通过字符串的形式操作对象相关的属性.python的一切事物都是对象. 反射就是通过字符串的形式,导入模块:通过字符串的形式,去模块寻找指定函 ...
- go:内置函数 | 闭包 | 数组 | 切片 | 排序 | map | 锁
内置函数 1.close: 主要是用来关闭channel 2.len:用来求长度,比如string.array.slice.map.channel 3.new与make都是用来分配内存 new用来分配 ...
- Python系列-python内置函数
abs(x) 返回数字的绝对值,参数可以是整数.也可以是浮点数.如果是复数,则返回它的大小 all(iterable) 对参数中的所有元素进行迭代,如果所有的元素都是True,则返回True,函数等价 ...
- PYTHON语言之常用内置函数
一 写在开头本文列举了一些常用的python内置函数.完整详细的python内置函数列表请参见python文档的Built-in Functions章节. 二 python常用内置函数请注意,有关内置 ...
- C语言基础:内置函数的调用
#include<stdio.h>#include<math.h>#include<stdlib.h>#include<ctype.h>#include ...
- Python 内置函数sorted()在高级用法
对于Python内置函数sorted(),先拿来跟list(列表)中的成员函数list.sort()进行下对比.在本质上,list的排序和内建函数sorted的排序是差不多的,连参数都基本上是一样的. ...
- python 使用内置函数sorted对各种数据类型进行排序
python有两个内置的函数用于实现排序,一个是list.sort()函数,一个是sorted()函数. 区别1:list.sort()函数只能处理list类型数据的排序:sorted()则可以处理多 ...
- 【LESS系列】内置函数说明
本文转自 http://www.cnblogs.com/zfc2201/p/3493335.html escape(@string); // 通过 URL-encoding 编码字符串 e(@stri ...
随机推荐
- python 之 查找某目录中最新的文件
记录一下这个方法,感觉很有用!>.< import os def find_newest_file(path_file): lists = os.listdir(path_file) li ...
- 上传本地文件到GitHub上
问题解决 今天在windows上上传本地文件到github,出现用户名和仓库不匹配的情况,解决方式如下: 打开控制面板,选择用户账户 把该删除的账户删除一下就行了. 上传文件的步骤如下: 将上传的文件 ...
- SQL NULL 值
NULL 值是遗漏的未知数据. 默认地,表的列可以存放 NULL 值. 本章讲解 IS NULL 和 IS NOT NULL 操作符. SQL NULL 值 如果表中的某个列是可选的,那么我们可以在不 ...
- 文本分类实战(二)—— textCNN 模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 监控glusterfs
监控集群状态 [4ajr@elk1 scripts]$ cat glusterfs_peer_status.sh #!/bin/bash peer_status=`sudo gluster peer ...
- Linux soft lockup分析
关键词:watchdog.soft lockup.percpu thread.lockdep等. 近日遇到一个soft lockup问题,打印类似“[ 56.032356] NMI watchdog: ...
- 如何用ABP框架快速完成项目(6) - 用ABP一个人快速完成项目(2) - 使用多个成熟控件框架
正如我在<office365的开发者训练营,免费,在微软广州举办>课程里面所讲的, 站在巨人的肩膀上的其中一项就是, 尽量使用别人成熟的框架. 其中也包括了控件框架 abp和52abp ...
- Django生命周期 URL ----> CBV 源码解析-------------- 及rest_framework APIView 源码流程解析
一.一个请求来到Django 的生命周期 FBV 不讨论 CBV: 请求被代理转发到uwsgi: 开始Django的流程: 首先经过中间件process_request (session等) 然后 ...
- mybatis 使用缓存策略
mybatis中默认开启缓存 1.mybatis中,默认是开启缓存的,缓存的是一个statement对象. 不同情况下是否会使用缓存 同一个SqlSession对象,重复调用同一个id的<sel ...
- php函数 array_chunk
array_chunk ( array $array , int $size [, bool $preserve_keys = false ] ) : array 将一个数组分割成多个数组,其中每个数 ...