用jieba库统计文本词频及云词图的生成
一、安装jieba库
:\>pip install jieba #或者 pip3 install jieba
二、jieba库解析
jieba库主要提供提供分词功能,可以辅助自定义分词词典。
jieba库中包含的主要函数如下:
jieba.cut(s) 精确模式,返回一个可迭代的数据类型
jieba.cut(s,cut_all=True) 全模式,输出文本s中所有可能的单词
jieba.cut_for_search(s) 搜索引擎模式,适合搜索引擎建立索引的分词结果
jieba.lcut(s) 精确模式,返回一个列表类型,建议使用
jieba.lcut(s,cut_all=True) 全模式,返回一个列表类型,建议使用
jieba.lcut_for_search(s) 搜索引擎模式,返回一个列表类型,建议使用
jieba.add_word(w) 向分词词典中增加新词w
三、用jieba库统计文本的词频
《流浪地球》是刘慈欣的一部作品。该书讲述了庞大的地球逃脱计划,逃离太阳系,前往新家园。从网上获取该书的文本文件,保存于桌面上,命名为“流浪地球。”
现统计其文本中出现次数最多的是个词语,源代码如下:
import jieba
txt = open("C:\\Users\\Administrator\\Desktop\\流浪地球.txt", "r", encoding='utf-8').read()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1: #排除单个字符的分词结果
continue
else:
counts[word] = counts.get(word,0) + 1
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
for i in range(10):
word, count = items[i]
print ("{0:<10}{1:>5}".format(word, count))
运行程序后,输出结果如下:

故容易得知流浪地球中出现频次较高的词语
四、结合jieba库的词频统计制作词云图
1、准备工作:pip 安装 jieba , wordcloud ,matplotlib
2以阿Q正传为例:
源代码为:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba #生成词云
def create_word_cloud(filename):
text = open("{}.txt".format(filename)).read()
# 结巴分词
wordlist = jieba.cut(text, cut_all=True)
wl = " ".join(wordlist) # 设置词云
wc = WordCloud(
# 设置背景颜色
background_color="white",
# 设置最大显示的词云数
max_words=2000,
# 这种字体都在电脑字体中,一般路径
font_path='C:\Windows\Fonts\simfang.ttf',
height=1200,
width=1600,
# 设置字体最大值
max_font_size=200,
# 设置有多少种随机生成状态,即有多少种配色方案
random_state=100,
) myword = wc.generate(wl) # 生成词云
# 展示词云图
plt.imshow(myword)
plt.axis("off")
plt.show()
wc.to_file('p.png') # 把词云保存下 if __name__ == '__main__':
create_word_cloud('C:\\Users\\Administrator\\Desktop\\阿Q正传')
运行程序后,输出结果如下:
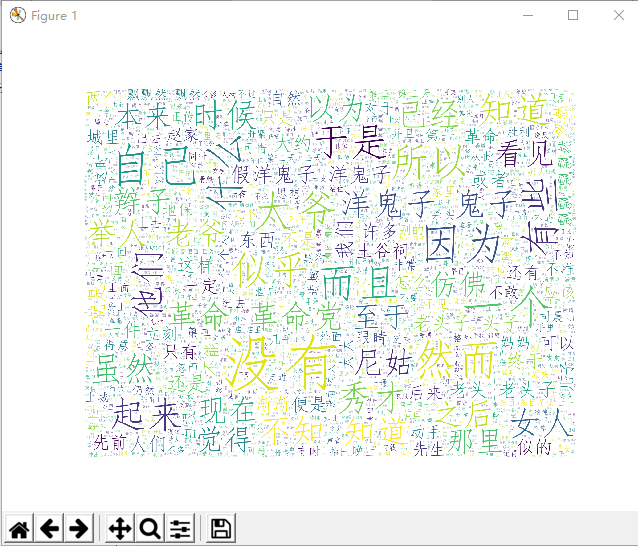
故可得出文本的云词图。
用jieba库统计文本词频及云词图的生成的更多相关文章
- 用Python搞出自己的云词图 | 【带你装起来】
作者:AI算法与图像处理 参考:http://www.sohu.com/a/149657007_236714 云词图简介 什么词云 由词汇组成类似云的彩色图形.“词云”就是对网络文本中出现频率较高的“ ...
- 利用python jieba库统计政府工作报告词频
1.安装jieba库 舍友帮装的,我也不会( ╯□╰ ) 2.上网寻找政府工作报告 3.参照课本三国演义词频统计代码编写 import jieba txt = open("D:\政府工作报告 ...
- jieba库的使用和好玩的词云
1.jieba库基本介绍 (1).jieba库概述 jieba是优秀的中文分词第三方库 - 中文文本需要通过分词获得单个的词语 - jieba是优秀的中文分词第三方库,需要额外安装 - ...
- jieba 库的使用和好玩的词云
jieba库的使用: (1) jieba库是一款优秀的 Python 第三方中文分词库,jieba 支持三种分词模式:精确模式.全模式和搜索引擎模式,下面是三种模式的特点. 精确模式:试图将语句最精 ...
- 运用jieba库统计词频及制作词云
一.对中国十九大报告做词频分析 import jieba txt = open("中国十九大报告.txt.txt","r",encoding="utf ...
- jieba库初级应用
1.jieba库基本介绍 (1).jieba库概述 jieba是优秀的中文分词第三方库 - 中文文本需要通过分词获得单个的词语 - jieba是优秀的中文分词第三方库,需要额外安装 - ...
- 广师大学习笔记之文本统计(jieba库好玩的词云)
1.jieba库,介绍如下: (1) jieba 库的分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动态规划方法找到最大概率的词组:除此之外,jieba 库还提供了增加自定 ...
- jieba库词频统计
一.jieba 库简介 (1) jieba 库的分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动态规划方法找到最大概率的词组:除此之外,jieba 库还提供了增加自定义中文 ...
- python实例:利用jieba库,分析统计金庸名著《倚天屠龙记》中人物名出现次数并排序
本实例主要用到python的jieba库 首先当然是安装pip install jieba 这里比较关键的是如下几个步骤: 加载文本,分析文本 txt=open("C:\\Users\\Be ...
随机推荐
- 设计模式十: 生成器模式(Builder Pattern)
简介 生成器模式属于创建型模式的一种, 又叫建造者模式. 生成器模式涉及4个关键角色:产品(Product),抽象生成器(builder),具体生成器(ConcreteBuilder),指挥者(Dir ...
- 如何让vue项目兼容IE浏览器
一般来说项目开发到后期都需要做各种兼容性处理例如:360.IE9以上.QQ浏览器....等等 那么现在来介绍一个工具 babel-cli 跟 babel-preset-es2015 babel-cli ...
- Django之Xadmin
零.预备知识 单例对象 方式一:__new__方法 方式二:模块导入,只要在引入的文件中实例了这个对象,不管引道哪里,这个对象都指向同一个内存空间 class My_singleton(object) ...
- 【转】QPainter中坐标系变换问题
转自:http://blog.sina.com.cn/s/blog_67cf08270100ww0p.html 一.坐标系简介. Qt中每一个窗口都有一个坐标系,默认的,窗口左上角为坐标原点,然后水平 ...
- 新手如何理解JS面向对象开发?
今天有时间讲讲我对面向对象的理解跟看法,尽量用通俗的语言来表达,多多指教! 如今前端开发已经越来越火了,对于前端开发的要求也是越来越高了,在面试中,经常有面试官会问:你对JS面向对象熟悉吗? 其实,也 ...
- 【算法】K最近邻算法(K-NEAREST NEIGHBOURS,KNN)
K最近邻算法(k-nearest neighbours,KNN) 算法 对一个元素进行分类 查看它k个最近的邻居 在这些邻居中,哪个种类多,这个元素有更大概率是这个种类 使用 使用KNN来做两项基本工 ...
- windows下的node环境搭建
node环境的搭建过程: 1.首先在nodejs.org官网上下载一个msi安装文件,安装(过程很简单,基本上是一路next) 2.安装完成后,简单测试下是否安装成功,在cmd下输入两个命令: nod ...
- HBuilder只提示html 不提示js
1. 右键行号,点击语法验证器设置 点开Javascript语法验证器 然后修复你js代码中的不规范代码,就会有提示了.
- 关于CentOS
dd if=/dev/cdrom of=centos72.iso 自动挂载镜像: vi /etc/fstab /root/centos72.iso /mnt/cdrom iso9660 de ...
- 大数据项目之_15_帮助文档_NTP 配置时间服务器+Linux 集群服务群起脚本+CentOS6.8 升级到 python 到 2.7
一.NTP 配置时间服务器1.1.检查当前系统时区1.2.同步时间1.3.检查软件包1.4.修改 ntp 配置文件1.5.重启 ntp 服务1.6.设置定时同步任务二.Linux 集群服务群起脚本2. ...