Python爬虫与一汽项目【二】爬取中国东方电气集中采购平台
网站地址:https://srm.dongfang.com/bid_detail.screen
东方电气采购的页面看似很友好,实际上并不好爬取
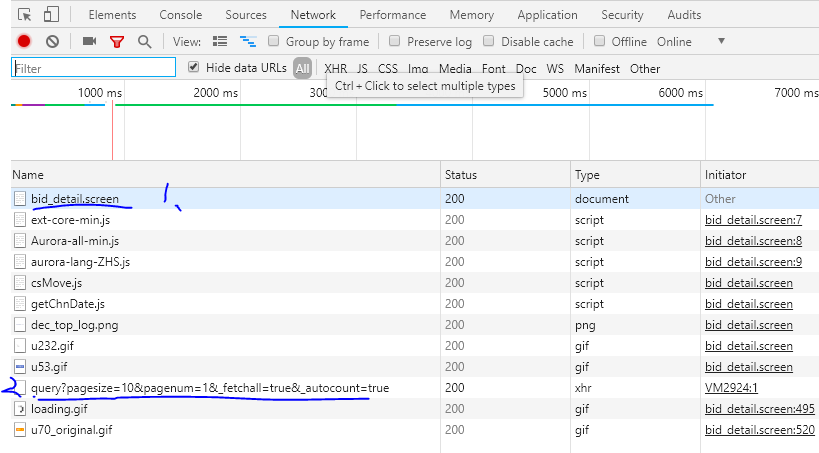
在观察网页的审查元素之后发现,1处的网页响应只是单纯的一些js代码,并没有我们想要的数据信息,因此很明显该网页是经过js修饰的
另外再翻页时,发现该网页的url始终不变,所以这是一个以post方式提交的页面。
果断转向2出的url,点开之后可以看到,
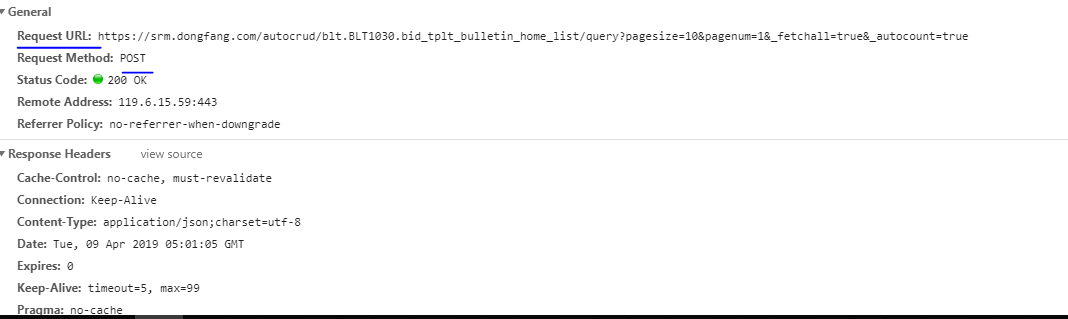
此处有一新的url,并且请求方式的确四post方式,因此不能直接用网站地址获取我们所需的数据。

查看新的url的响应发现,得到的是一串非常长的字典,而经过观察发现,我们所需要的时间,标题,二级页面的参数等内容均在字典中
因此,采取的方式的为
通过新的url获取网页响应的内容—>通过解析json数据,获取Python可读的数据—>从得到的字典中获取所求的数据
代码如下:
from urllib.request import urlopen url = "https://srm.dongfang.com/autocrud/blt.BLT1030.bid_tplt_bulletin_home_list/query?pagesize=10&pagenum=2&_fetchall=true&_autocount=true"
urlObj = urlopen(url) # 服务端返回的页面信息, 此处为字符串类型
pageContent = urlObj.read().decode('utf-8')
# print(pageContent)
# print(type(pageContent)) # 2. 处理Json数据
import json
# 解码: 将json数据格式解码为python可以识别的对象;
dict_data = json.loads(pageContent) # print(type(dict_data))
# print(data['release_date'],data['bid_project_name'],data['tplt_blt_id'])
k = 0#查看信息条数
for i in dict_data['result']['record']:
print(i['creation_date'],i['bid_project_name'],i['tplt_blt_id'])
k = k+1
print(k)
这里获得了发布时间['creation_date'],招标项目名['bid_project_name'],二级页面参数['tplt_blt_id']
这里说明一下,响应的数据的格式
响应的数据是个字典嵌套了字典,大字典的第一个key值是"result",它的value值是一个小字典,
该小字典的key值是"record",而小字典的value值是一个列表,列表中保存了我们需要的信息,
而列表元素同样是个字典的形式,每个字典对应着一个招标信息的具体信息
因此采用for循环,将小字典中的值依次取出来
{"result":{"record":[{"created_by":1329210,...},{...},...],"totalCount":5265},"success":true}
输出:
2019-04-08 17:34:08 2019年年度防堵取样装置框架合同 72084
2019-04-09 09:17:15 【电机事业部】2D-HD199001-1~2-12东丰中众泰德110MW发电机配套励磁系统采购 72110
2019-04-04 09:42:03 ZB(ZK)2019069-文昌项目仪表阀(项目) 71870
2019-04-08 08:48:51 物资保障部国电九江改造凹凸法兰毛坯采购 71990
2019-04-09 08:35:02 进口铣刀及铣刀片采购(住友) 72092
2019-04-09 08:48:49 中广核河南永城项目自动润滑系统 72098
...
本以为获取到这儿就可以直接拼接二级页面的url获取内容了,谁知道它连二级页面都是个这样的形式,可给我无语了......
Python爬虫与一汽项目【二】爬取中国东方电气集中采购平台的更多相关文章
- Python爬虫学习三------requests+BeautifulSoup爬取简单网页
第一次第一次用MarkDown来写博客,先试试效果吧! 昨天2018俄罗斯世界杯拉开了大幕,作为一个伪球迷,当然也得为世界杯做出一点贡献啦. 于是今天就编写了一个爬虫程序将腾讯新闻下世界杯专题的相关新 ...
- Python爬虫与一汽项目【一】爬取中海油,邮政,国家电网问题总结
项目介绍 中国海洋石油是爬取的第一个企业,之后依次爬取了,国家电网,中国邮政,这三家公司的源码并没有多大难度, 采购信息地址: 国家电网电子商务平台 http://ecp.sgcc.com.cn/pr ...
- Python爬虫与一汽项目【综述】
项目来源 这个爬虫项目是 去年实验室去一汽后的第一个项目(基本交工,现在处于更新维护阶段).内容大概是,获取到全国31个省份政府的关于汽车的招标公告,再用图形界面的方式展示爬虫内容.在完成政府招标采购 ...
- Python爬虫初探 - selenium+beautifulsoup4+chromedriver爬取需要登录的网页信息
目标 之前的自动答复机器人需要从一个内部网页上获取的消息用于回复一些问题,但是没有对应的查询api,于是想到了用脚本模拟浏览器访问网站爬取内容返回给用户.详细介绍了第一次探索python爬虫的坑. 准 ...
- 小白学 Python 爬虫(25):爬取股票信息
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- Python爬虫教程:验证码的爬取和识别详解
今天要给大家介绍的是验证码的爬取和识别,不过只涉及到最简单的图形验证码,也是现在比较常见的一种类型. 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻 ...
- Python爬虫学习(6): 爬取MM图片
为了有趣我们今天就主要去爬取以下MM的图片,并将其按名保存在本地.要爬取的网站为: 大秀台模特网 1. 分析网站 进入官网后我们发现有很多分类: 而我们要爬取的模特中的女模内容,点进入之后其网址为:h ...
- Python爬虫学习之使用beautifulsoup爬取招聘网站信息
菜鸟一只,也是在尝试并学习和摸索爬虫相关知识. 1.首先分析要爬取页面结构.可以看到一列搜索的结果,现在需要得到每一个链接,然后才能爬取对应页面. 关键代码思路如下: html = getHtml(& ...
- python爬虫-上期所持仓排名数据爬取
摘要:笔记记录爬取上期所持仓数据的过程,本次爬取使用的工具是python,使用的IDE是pycharm 一.查看网页属性,分析数据结构 在浏览器中打开上期所网页,按F12或者选择表格文字-右键-审查元 ...
随机推荐
- javaweb中的乱码问题(初次接触时写)
javaweb中的乱码问题 在初次接触javaweb中就遇到了乱码问题,下面是我遇到这些问题的解决办法 1. 页面乱码(jsp) 1. 在页面最前方加上 <%@ page language=&q ...
- dtIntersectSegmentPoly2D 2D上的线段与多边形相交计算 产生结果:是否相交,线段跨越的开始和结束百分比,相交的边
dtIntersectSegmentPoly2D(startPos, endPos, verts, nv, tmin, tmax, segMin, segMax): http://geomalgori ...
- Akka并发编程框架 -概念模型(Akka.net或者Orleans)
Akka 来构建具备高容错性.可以横向扩展的分布式网络应用程序. Akka 通常是指一个强大的分布式工具集,用于协调远程计算资源来进行一些工作 Akka 工具集以及Actor 模型的介绍. Actor ...
- mongodb 笔记
1.java驱动下的mongo操作 1.1 数据库连接 package com.mongodb.text; import java.net.UnknownHostException; import c ...
- list的基本操作实现
有关list的相关实现,主函数没有写很多,每个部分目前没发现有问题: #include <iostream> #include <stdio.h> using namespac ...
- Mysql笔试题(二)
(1)表名:购物信息购物人 商品名称 数量A 甲 2B 乙 4C 丙 ...
- Python加密保护-对可执行的exe进行保护
Python 是一种面向对象的解释型计算机程序设计语言,Python 语言写的程序不需要编译成二进制代码,可以直接从源代码运行程序. 在计算机内部,Python解释器把源代码转换成称为字节的中间形式, ...
- input type = file 在部分安卓手机上无法调起摄像头和相册
移动端H5web 用input type = file 在部分安卓手机上无法调起摄像头拍照,有的也无法访问相册而是直接访问了文档,解决办法是: 加上 accept = "image/*&qu ...
- Java 基础 多线程和线程池基础
一,多线程 1.1 多线程介绍 进程:进程指正在运行的程序.确切的来说,当一个程序进入内存运行,即变成一个进程,进程是处于运行过程中的程序,并且具有一定独立功能. 线程:线程是进程中的一个执行单元,负 ...
- sublime There are no packages available for installation 问题的解决办法
这个是因为IPv6的原因, 因此我们需要修改我们的 /etc/hosts文件. 第一步: 执行: nm-tool 获取DNS的信息 例如: DNS: 192.168.1.11 第二步: 在/etc/h ...