分布式 并行软件平台 Dryad Hadoop HPCC
1.为了 能够方便记忆, 总结一下。
2. 并行软件平台,不是 一个。
(1)这个特别熟悉的 以 hadoop 为平台的 生态系统
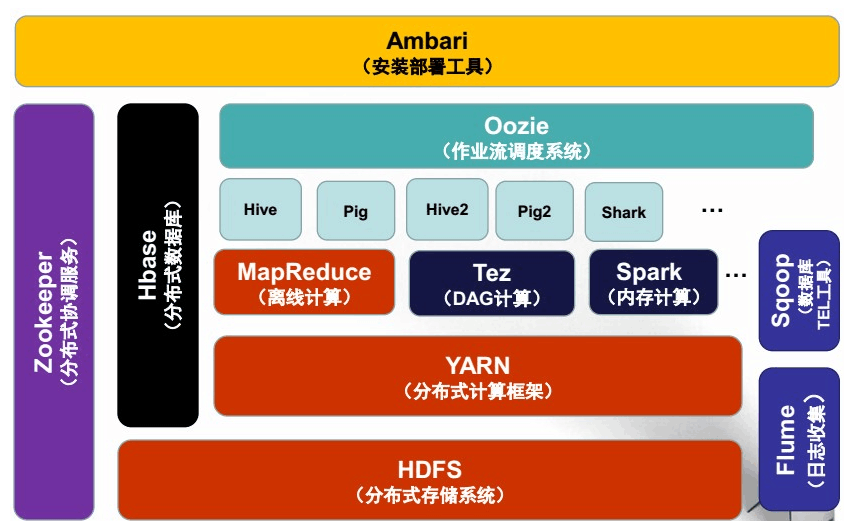
(2)还有以 微软的 并行软件平台 生态系统
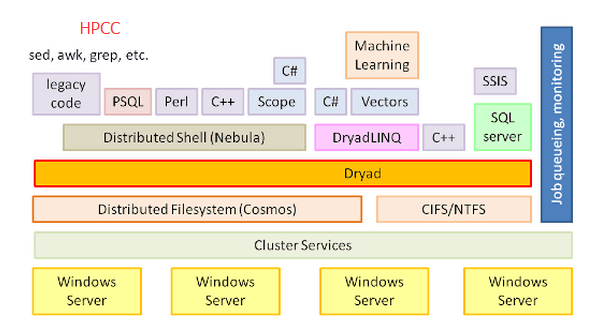
(3) 还有LexisNexis公司的 基于 C++ 开发的 HPCC
下面补充(1) 有介绍

补充说明:
(一)HPCC 与 hadoop
1.Hadoop是许多年前由当时的Yahoo员工Doug Cutting在Apache软件基金会创建的项目。Hadoop现已成为网络公司的重要工具。包括Yahoo、Facebook,并帮助他们处理不断增长的非结构化数据。Hadoop催生了一批用于商业的基于分布式技术的产品,包括Cloudera,EMC和IBM等公司。
2. LexisNexis公司将发布一款开源的数据处理工具,LexisNexis公司宣称其处理工作负载的能力要优于Hadoop。该技术被称为HPCC系统,并在10年前帮助LexusNexis公司Risk Solutions分析大量的客户数据。并在金融
LexisNexis公司将发布一款开源的数据处理方案,LexisNexis公司宣称其处理工作负载的能力要优于Hadoop。该技术被称为HPCC系统,该系统在10年前帮助LexusNexis公司的Risk Solutions分析大量的客户数据。并在金融业和其他重要的行业中应用。看来HPCC(High-Performance Cluster Computing 高性能集群计算)似乎有能力成为替代Hadoop的解决方案。
据LexisNexis Risk Solutions部门CTO Armando Escalante表示,LexisNexis公司决定发布HPCC系统,目前的状况是Hadoop技术已经成为处理海量数据的首选。Armando Escalante表示Hadoop虽然在海量数据处理方面走在前边,但他认为HPCC系统更为优越。
但重要的是,Hadoop的开源模式吸引了大量相关人员对其进行开发和创新。Armando Escalante解释说,如果公司想要继续保持HPCC的影响力就需要通过一个新社区提供应用和好的创意。
3.HPCC如何工作
Hadoop依靠两个核心组件来存储和处理海量数据——Hadoop分布式文件系统和Hadoop Mapreduce。Cloudant公司CEO Mike Miller认为MapReduce在编写并行处理工作流时依然相对复杂,HPCC旨在通过ECL(Enterprise Control Language)改善这一局面。
Escalante表示ECL是一种声明式并以数据为中心的语言,它剥离了大量MapReduce必要的工作。对于某些千行代码的MapReduce任务ECL只需要99行。此外,他还表示ECL对集群中节点的数量没有要求,系统会自动将数据分布式的存放在当前节点之中。从技术上讲,HPCC还可以运行在单一的虚拟机上。HPCC基于C++,如同Google最早的Mapreduce,这使得HPCC天生在效率上就优于基于Java开发的Hadoop。
4. HPCC提供两种数据处理和服务的方式——Thor Data Refinery Cluster和Roxy Rapid Data Delivery Cluster。Escalante表示如此命名是因为其能像Thor(北欧神话中司雷、战争及农业的神)一样解决困难的问题,Thor主要用来分析和索引大量的Hadoop数据。而Roxy则更像一个传统的关系型数据库或数据仓库,甚至还可以处理Web前端的服务。
虽然没有深入探讨HPCC存储组件的细节,但Escalante表示HPCC基于分布式文件系统,并可支持各种off-node存储架构和本地的SSD。
Escalante认为为了确保LexisNexis产品质量,应采用“eating its own dogfood”(指软件公司强调自己的软件产品首先应内部使用,如果希望顾客购买公司的产品,公司内部也应该愿意使用它们)做法。HPCC开发团队还聘请了Hadoop专家帮助检验其产品是否有问题疏漏。HPCC还构建了一个转换器,用于迁移Hadoop Pig编写的应用并转换为ECL。
5. HPCC具有竞争力吗?
一个关键的问题是HPCC是否能吸引到业界的构建者和用户,这将有助于提升其在海量数据领域的话语权。Escalante认为HPCC能够成功,因为HPCC已经证明了自己,它已处理LexisNexis Risk Solutions的35000个数据源。同时HPCC还可以每秒处理5000次的和支付客户打交道的交易事物。
6. Hadoop已经证明了自己,其潜在的巨大核心业务每天都在增长,现在企业和组织在海量数据上依托于Hadoop。但Hadoop并不满足这些成就。这使得微软也在海量数据的竞争中推出了自己的分布式计算技术Dryad。(李智/译)
原文链接:GIGAOM
分布式 并行软件平台 Dryad Hadoop HPCC的更多相关文章
- 学习笔记TF041:分布式并行
TensorFlow分布式并行基于gRPC通信框架,一个master负责创建Session,多个worker负责执行计算图任务. 先创建TensorFlow Cluster对象,包含一组task(每个 ...
- 在Linux(Centos7)系统上对进行Hadoop分布式配置以及运行Hadoop伪分布式实例
在Linux(Centos7)系统上对进行Hadoop分布式配置以及运行Hadoop伪分布式实例 ...
- Hadoop与分布式数据处理 Spark VS Hadoop有哪些异同点?
Spark是一个开源的通用并行分布式计算框架,由加州大学伯克利分校的AMP实验室开发,支持内存计算.多迭代批量处理.即席查询.流处理和图计算等多种范式.Spark内存计算框架适合各种迭代算法和交互式数 ...
- Ubuntu16.04下伪分布式环境搭建之hadoop、jdk、Hbase、phoenix的安装与配置
一.准备工作 安装包链接: https://pan.baidu.com/s/1i6oNmOd 密码: i6nc 环境准备 修改hostname: $ sudo vi /etc/hostname why ...
- HA分布式集群一hadoop+zookeeper
一:HA分布式配置的优势: 1,防止由于一台namenode挂掉,集群失败的情形 2,适合工业生产的需求 二:HA安装步骤: 1,安装虚拟机 1,型号:VMware_workstation_full_ ...
- hadoop2.2.0伪分布式搭建3--安装Hadoop
3.1上传hadoop安装包 3.2解压hadoop安装包 mkdir /cloud #解压到/cloud/目录下 tar -zxvf hadoop-2.2.0.tar.gz -C /cloud/ 3 ...
- HDFS分布式文件系统(The Hadoop Distributed File System)
The Hadoop Distributed File System (HDFS) is designed to store very large data sets reliably, and to ...
- 大数据学习笔记1-大数据处理架构Hadoop
Hadoop:一个开源的.可运行于大规模集群上的分布式计算平台.实现了MapReduce计算模型和分布式文件系统HDFS等功能,方便用户轻松编写分布式并行程序. Hadoop生态系统: HDFS:Ha ...
- 互联网大规模数据分析技术(自主模式)第五章 大数据平台与技术 第10讲 大数据处理平台Hadoop
大规模的数据计算对于数据挖掘领域当中的作用.两大主要挑战:第一.如何实现分布式的计算 第二.分布式并行编程.Hadoop平台以及Map-reduce的编程方式解决了上面的几个问题.这是谷歌的一个最基本 ...
随机推荐
- Verilog 加法器和减法器(3)
手工加法运算时候,我们都是从最低位的数字开始,逐位相加,直到最高位.如果第i位产生进位,就把该位作为第i+1位输入.同样的,在逻辑电路中,我们可以把一位全加器串联起来,实现多位加法,比如下面的四位加法 ...
- Construct Binary Tree from Preorder and Inorder Traversal leetcode java
题目: Given preorder and inorder traversal of a tree, construct the binary tree. Note: You may assume ...
- Swift编程语言学习1.7——断言
断言 可选能够让你推断值是否存在,你能够在代码中优雅地处理值缺失的情况.然而,在某些情况下,假设值缺失或者值并不满足特定的条件,你的代码可能并不须要继续执行.这时.你能够在你的代码中触发一个断言(as ...
- bash: php: command not found
bash: php: command not found 解决:export PATH=$PATH:/usr/local/php/bin
- 我们为何放弃Eclipse,投奔IntelliJ IDEA
本文来源于我在InfoQ中文站原创的文章,原文地址是:http://www.infoq.com/cn/news/2013/11/why-drop-eclipse-use-intellij Nikita ...
- java中正则表达式基本用法(转)
https://www.cnblogs.com/xhj123/p/6032683.html 正则表达式是一种可以用于模式匹配和替换的规范,一个正则表达式就是由普通的字符(例如字符a到z)以及特殊字符( ...
- SearchBySql
Java: public List<Accountingdisclosure> searchAccountingdisclosuresBySql(String sqlStr)throws ...
- 10个在UNIX或Linux终端上快速工作的建议
你有没有惊讶地看到有人在Unix/ Linux中工作得非常快,噼里啪啦的敲键盘,快速的启动命令,飞快地执行命令? 在本文中,我共享了一些在Linux中快速.高效工作所遵循的Unix/ Linux命令实 ...
- Everything常见问题及搜索技巧,附Demo
1 Everything 1.1 "Everything"是什么? "Everything"是一个运行于Windows系统,基于文件.文件夹名称的快速搜索引擎. ...
- oauth2-server-php-docs 存储 学说2
学说2 创建客户端和访问令牌存储 要把学说融入到你的项目中,首先要建立你的实体.我们先从客户端,用户和访问令牌模型开始: yaml YourNamespace\Entity\OAuthClient: ...