Convolutional Neural Networks
卷积神经网络(Convolutional Neural Networks/ CNN/ConvNets)
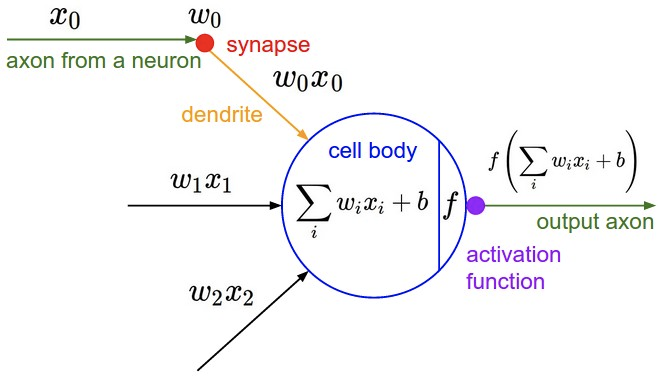
卷积神经网络和普通神经网络十分相似: 组成它们的神经元都具有可学习的权重(weights)和偏置(biases)。每个神经元接受一些输入,执行一个点积操作,并且可能执行一个非线性函数最后得到该神经元的输出。整个网络仍然可以表示为一个可微评分函数。这个函数在一端输入图像的像素,在另一端得到某个类别的分数。同时卷积神经网络在做后一个层(fully-connected)上仍然具有损失函数——例如SVM/Softmax——并且我们为常规神经网络而开发的所有技巧,仍然是有该网络。
那么,卷积神经网络有什么不同呢?ConvNet的结构明确地假设了输入是图像,这是我们能够将某些属性集成到网络体系结构中。使得前向传播功能能够更有效率,并且极大地减少了网络中的参数数量。
架构概述
复习: 常规的神经网络接受一个输入(向量),并且将该向量传递过一系列的隐藏层。每一个隐藏层都包含了一系列的神经元,这些神经元都和之前一层的神经元做全连接,并且即使是同一层,每一个神经元都完全相互独立,之间没有共享任何连接。
常规神经网络在完整大图上没有办法很好的扩展。以CIFAR-10为例,图像大小只是 \(32\times32\times3\)(32宽 32高 3颜色通道),所以在神经网络的第一个隐藏层中,每一个神经元都有 \(32*32*3=3072\)权重参数,这个数量貌似还可以管理,但显然,全联接网络无法扩展到大图像上。举个例子,如果一个比较可观的尺寸 \(200\times200\times3\)的图像,会导致每个神经元有 12000个权重参数,并且我们需要很多个这样子的神经元,那么参数的数量会增加得十分的快!很显然,这样子进行全联接是十分浪费的,而且大量的参数会产生过拟合。
3D神经元(3D volumes of neurons)。 卷积神经网络充分利用了输入是图像的事实,并且用合理的方式对网络结构进行了约束。与常规的神经网络不同,卷积神经网络的神经元在3个维度上进行了安排: 宽度(width), 高度(height), 深度(depth)。例如,CIFAR-10中输入图像是激活的输入卷,这个卷的维度是\(32\times32\times3\)。层中的神经元只连接之前层神经元的一小部分区域而不是使用全联接网络的方法。最终CIFAR-10的维度为 \(1\times1\times10\)。下面是可视化图:
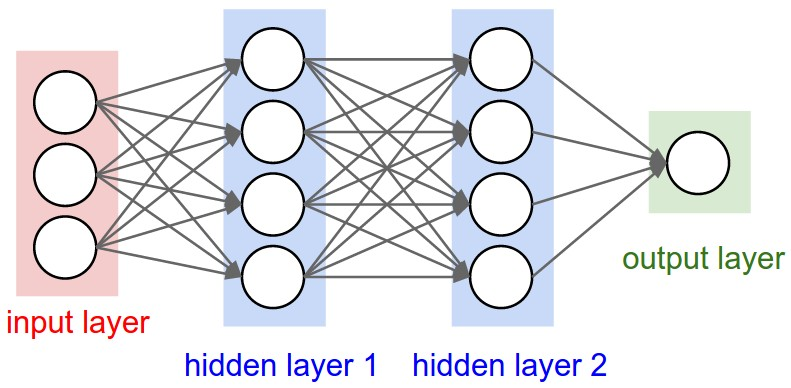
上图: 常规的3层神经网络。
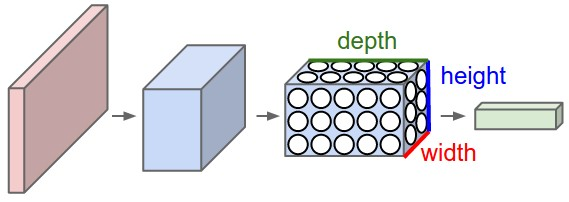
下图: ConvNet将其神经元安排了在3个维度上(width, height, depth), 正如图展示的其中一层一样。ConvNet的每一层将一个3D的输入卷转化为3D的神经元激励。在右图这个例子中,红色的输入层代表了输入图像,所以这一层的width和height应该等于图像的维度大小,depth应该为3(RGB通道)
一个卷积神经网络包含了许多的层,每一个层包含了一个简单的API: 使用一个可以有参数的可微函数,将输入的3D卷转化为另一个3D卷输出。
构建卷积神经网络使用的层(Layers used to build ConvNets)
如上所述,一个简单的卷积神经网络是一系列的层,每一个层通过一个可微函数将一个3D卷转换为另一个3D卷。我们使用3种主要的层来搭建我们的卷积神经网络架构: 卷积层(Convolutional Layer)、池化层(Pooling Layer)和全联接层(Full-Connected Layer)。我们通过堆叠这些网络层来构建我们的ConvNet架构。
举个例子
CIFAR-10分类任务的简单卷积神经网络有这样的结构
\[\text{INPUT}\to\text{CONV}\to\text{RELU}\to\text{POOL}\to\text{FC}\]
- INPUT [\(32\times32\times3\)]: 输入层将记录这输入图片的像素值,这个场景下 width 32,height 32,并且有3种颜色通道
- CONV 层会计算连接到局部区域的神经元的输出,将权重和输入卷相连接的局部区域进行点积运算,得到每个神经元的计算结果。如果我们使用12个过滤器,那么每个过滤器是\(1*1\),那么可以得到 [\(32\times32\times12\)]的输出卷
- RELU 层将会应用元素激活函数, 例如 \(max(0,x)\), 经过这一层,得到的volume维数未变,仍为[\(32\times32\times12\)]
- POOL 层会在空间尺寸(width, height)执行下采样操作。得到的volume为[\(16\times16\times12\)]
- FC(全联接) 层会计算类别的分数,得到的volume为 [\(1\times1\times10\)]。顾名思义,和普通神经网络一样全联接层的每一个神经元都将连接到前一层的所有神经元。
通过这种方法,ConvNets将原始图片的原始像素值一层一层地,最终转化成类别的分数(scores)。注意的是一些层包含参数,而另一些层则没有。卷积层和全联接层的参数将通过梯度下降法进行训练,来使得ConvNet计算的类别标签和训练集的相一致。
现在我们将描述每一个单独层的相关细节,例如超参数,连通性
卷积层(Convolutional Layer)
卷积层是卷积网络构造的核心模块,并且完成大部分计算繁重的工作。
卷积层包含了一些可学习的过滤器,每一个过滤器在空间上(width和height)都很小,不过在depth方向上和输入卷一致,例如ConvNet第一个卷积层经典的过滤器的尺寸为 \(5*5*3\)
在前向传播阶段,我们沿着输入卷的宽度和高度滑动(精确地讲,是卷积)每个滤波器,并计算整个滤波器和任意位置输入的点积。 当我们在输入卷的width和height上滑动滤波器时,我们将生成一个2维的激活图,该激活图表明了滤波器在空间位置的响应。直观地说,网络将学习到当它看到某种类型的视觉特征时激活的滤波器,例如第一层上的某个方向的边缘或某种颜色的斑点,或者最终整个网络的更高层上的整个蜂窝或轮状图案。在CIFAR-10的例子中,我们有每个CONV层有一整套滤波器,并且它们都会生成一个单独的2维激活图。我们将沿着depth维度堆叠这些激活图来产生输出Volume
局部连接(Local Connectivity)。我们在解决高维输入如图像的时候看到,将神经元全部连接到之前的层是不实际的。相反,我们使每个神经元仅仅连接到输入volume的一个局部区域。这个局部连接的空间范围是神经元的一个超参数,我们称之为感受野(receptive field)。沿着depth轴的连通深度等于输入卷depth的深度。在这里值得再一次强调我们在处理空间尺寸(width和height)和深度尺寸(depth)时的不一样的做法:"在空间尺寸上的连接是局部的,但始终沿着输入Volume的整个深度"。
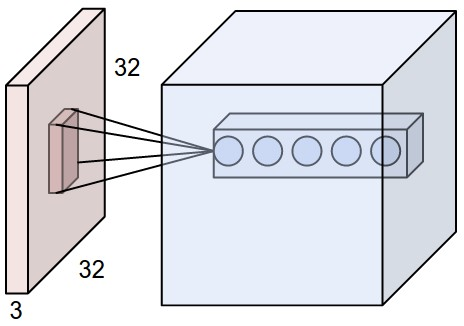
上图:红色的是输入volume,蓝色的是第一个卷积层的例子。卷积层的每个神经元仅在空间上连接到输入volume的局部区域,但是连接到全部深度(即所有颜色通道)。
下图:神经元的操作仍然不变。它们仍然计算权重和输入之间的点积,然后再使用非线性激活函数\(f(x)\),但是它们现在的连通性仅局限于局部空间。
空间排列(Spatial arrangement), 上面我们讨论了卷积层每个神经元和输入volume的连通性。但是我们还没有讨论输出卷有多少神经元以及它们是如何排列的。有三个超参数用来控制输出Volume的大小 depth深度, stride步幅 和 zero-padding零-填充。
- 首先,输出Volume的深度(depth)就是一个超参数: 它和我们采用的滤波器的数量一样。我们将一组观测相同输入区域的神经元作为输出Volume深度列depth column
- 然后,另一个超参数指的是我们滑动滤波器的步幅stride。例如,如果stride为1,那么我们每次将滤波器移动一个像素,如果stride为2,以此类推。在实际应用中步幅超过3的超参数一般较少应用。采用更大的stride会产生更小的输出Volume。
- 有时候,在输入Volume的周围用0填充会很方便。zero-padding的数量也是一个超参数,zero-padding有一个有点,也就是它可以让我们控制输出Volume的空间大小
假设卷积层的感受野大小为\(F\), 滤波器的滑动步幅为 \(S\), 边界使用零-填充的数量为 \(P\), 给定输入卷的大小为 \(W\) 我们可以计算出输出卷的大小。
\[(W-F+2P)/S+1\]
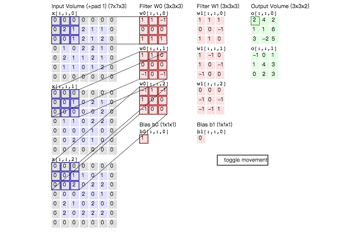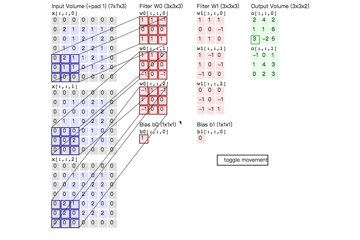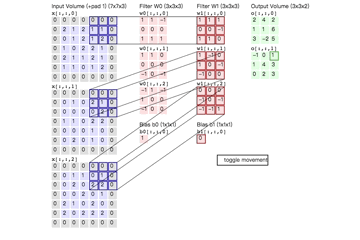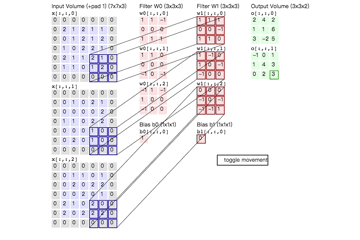
例如,对\(7\times7\)输入使用 \(3\times3\)的滤波器和数量为1的“零-填充”,在stride为1和2时可以得到\(5\times5\)和\(3\times3\)的输出,如下图

神经元之间共享的权重值为[1, 0, -1],并且偏置为0。
使用零-填充zero-padding.就上图左边例子来说,我们看到输入的维度等于5并且输出的维度也是等于5.如果没有使用“零-填充”的话。输出卷的空间维度就只有3. 在通常情况下,如果假设步幅 \(S=1\),为了使输入卷和输出卷有相同的尺度,将设置\(P=\frac{F-1}{2}\)。通常这么使用“零-填充”这个操作,具体原因,我们将会在后面谈到ConvNet结构时进行讨论。
步幅的局限(Constrains on strides), 再强调一下,空间排列(spatial arrangement)的超参数有相互的限制。假设,当输入的大小\(W=10\), 不使用“零-填充” \(P=0\), 并且滤波器的大小 \(F=3\),那么将无法使用步幅\(S=2\),因为\((W-F+2P)/S+1 = 4.5\)。由于不是整数,表明了神经元不能整齐对称地“适合”整个输入。因此,这个超参数设置将是不合理的,ConvNet库有可能会抛出异常或者填充0来使其能够匹配,又或者对输入进行剪裁来使其有效。调整ConvNets的大小使所有维度都能够"解决"是一件非常头疼的事情。使用零填充和某些设计会显著的减轻这种负担。
参数共享,卷积层使用参数共享方案来控制参数的数量。事实证明,我们可以通过一个合理的假设来大大减少参数的数量,那就是:
如果某一个特征在某一个空间位置\((x,y)\)上的计算是有用的,那么在另一个位置\((x_2,y_2)\)上计算也应该是有用的。
使用参数共享方案,我们的参数数量将会大大地减少。在实际的反向传播中,Volume中的每个神经元都会计算其权重梯度,这些梯度在每个深度切片上叠加,并且每个切片的权重更新相互独立。
池化层(Pooling Layer)
在ConvNet体系机构中的连续卷积层之间周期性地插入池化层是很常见的。它的功能是逐步减少图片表达的空间大小,控制参数数量和整个网络的计算量,由此来控制过拟合。池化层在使用MAX操作在输入的每个深度切片上独立地计算。最常见的池化层使用的滤波器尺寸为2×2,该滤波器在输入的每个深度切片上沿着宽度和高度以2为步幅进行下采样操作,丢弃75%的激活(activation)。每次进行MAX操作需要在4个数取max操作。深度维度仍保持不变。
- 假设层输入卷的大小为 \(W_1\times H_1\times D_1\)
- 假设两个超参数
- 滤波器的空间尺寸 \(F\)
- 步幅 \(S\)
- 假设输出卷的尺寸为 \(W_2\times H_2\times D_2\),那么
- \(W_2 = (W_1 - F)/S +1\)
- \(H_2 = (H_1 - F)/S +1\)
- \(D_2 = D_1\)
- 由于在输入上执行固定的函数,所以这里没有引入参数
- 在池化层中使用 “零-填充”是相对比较少见
值得注意的是,在实践中发现,最大池化层通常只有两种常见的变体
- 重叠池化: \(F=3, S=2\), 池化核大小 大于 步幅
- 非重叠池化: \(F=2, S=2\)
大尺寸感受野的池化破坏性比较大
常用池化操作。除了最大池化外,池化单元还可以执行其他函数如平均池化甚至是L2-norm池化。平均池化在历史发展过程中有它的地位,但是相比与最大池化,平均池化渐渐失宠。主要的原因是最大池化操作在实践中效果比较好。
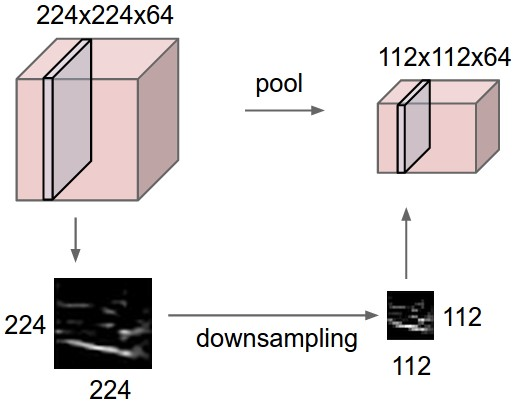
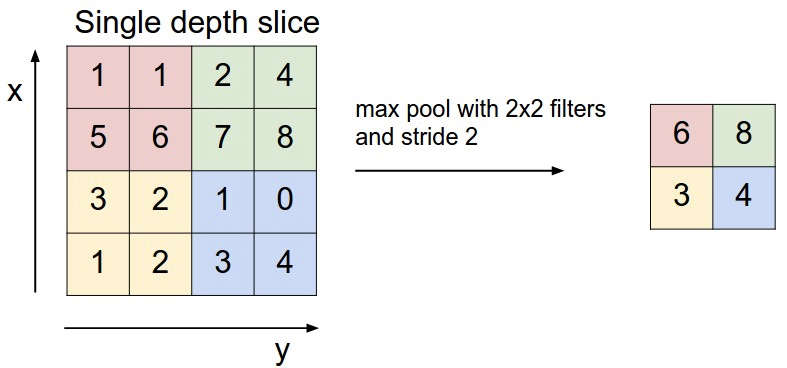
池化层在输入Volume的每个深度切片的空间上独立地进行下采样操作
上图: 这个例子中,输入Volume的尺寸为[224×224×3],进过尺寸为2,步幅为2的池化操作后,输出Volume的尺寸为[224×224×3]
下图:展现了最大池化操作的过程,尺寸为2×2 步幅为2
摆脱池化层 许多人不喜欢池化层,并且想方设法地想去掉它。举个例子在 Striving for Simplicity: The All Convolutional Net 一文中就提倡废弃掉池化层,转而只使用包含卷积层的体系结构。为了减少表示大小,文中建议在卷积层中使用更大的stride。在训练有良好泛化能力的模型时,丢弃池化层也被认为是十分重要的。例如变分自动编码器(VAEs)和生成对抗网络(GANs)
卷积神经网络架构(ConvNet Architectures)
卷积神经网络通常由3种类型的层构成: 卷积层, 池化层(默认使用最大池化)和全联接层。我们还将显式地将RELU编写成一个层。这个部分我们将讨论通常以什么形式堆叠形成卷积神经网络。
层模式(Layer Patterns)
ConvNets体系结构最常见的形式是叠加一些CONV-RELU 层,并且在每个CONV-RELU层后跟随一个POOL层。重复这个模式直到图像空间尺寸被合为一个小尺寸。在某些情况下,过渡到全联接层是常见的情况。最后的全联接层将产生输出,如类别的置信度。总而言之,最常见的ConvNets结构遵循一下模式
INPUT -> [[CONV -> RELU]*N -> POOL?]*M -> [FC -> RELU]*K -> FC
上面的模式中,* 表示重复, POOL?表示可选的池化层。此外 N>=0(通常N<=3), M>=0, K>=0(通常K<=3),下面是常见的卷积神经网络的结构,你会发现它们均满足上述的模式
INPUT -> FC实现了一个。线性分类器,N=M=K=0INPUT -> CONV -> RELU -> FCINPUT -> [CONV -> RELU -> POOL]*2 -> FC -> RELU -> FC这里我们看到每个POOL层之间都有一个CONV层。INPUT -> [CONV -> RELU -> CONV -> RELU -> POOL]*3 -> [FC -> RELU]*2 -> FC这里我们看到在每个POOL层之前堆叠了两个CONV层。对于更深更大的网络来说这通常是一个好主意,因为在有破坏性的池化操作之前,多个堆叠的卷积层能够从输入Volume构造出更加复杂的特征。
相对于使用一个大感受野的卷积层,我们更倾向于叠加多个小过滤器的卷积层。假设我们在神经网络的顶层堆叠三个3×3的卷积层(当然层与层之间有非线性激活函数)。这样子安排,第一个卷积层的每个神经元对输入有3×3的视野, 第二个卷积层的每个神经网络对第一个层也有3×3的视野,相当于对于输入Volume的5×5视野。同样的第三层相当于对于输入的7×7的视野。假设我们不使用三个3×3的卷积层,转而使用一个具有7×7感受野的卷积层,同样的在空间上可以得到一样的结果,但是相较于第一种,有一些缺点。
- 神经元在输入上进行的是线性的运算。而堆叠的Conv层间有非线性操作,使得提取出来的特征更加有表现力。
- 假设我们的输入有\(C\)个通道,那么使用一个单独的7×7的卷积层将包含 \(C\times(7\times7\times C) = 49C^2\),而3×3的卷积层只有\(3\times(C\times(3\times3\times C)) = 27C^2\)个参数。直观上来讲,堆叠小滤波器的卷积层比使用大滤波器的卷积层更能从输入提取有表现力的特征,并且具备更少量的参数。在实际上应用中有一个缺点,就是在执行反向传播的时候,需要更多的内存来存储卷积层的中间结果。
近来的尝试。
要注意到的是,近来线性堆叠模型屡屡收到挑战,包括Google的 Inception 架构和微软亚洲研究院的残差神经网络ResNet(目前最先进的)。这两者都具有更复杂和不同的连接结构。
层大小
到现在,我们忽略了ConvNet中使用的超参数。
输入层(即包含了图像)
输入层的大小应该可以被2多次划分,常用的大小例如32(CIFAR-10),64,96(STL-10), 224(常见于ImageNet的卷积网络),384,512
卷积层
卷积层应该使用小卷积核(滤波器,3×3 最大5×5),并且stride为1。最关键的是使用0填充输入卷,使得卷积层不会改变输入的空间维度。也就是说,如果\(F=3\),\(P=1\)将会保留输入的原始维度,同样的\(F=5\)则\(P=2\)。总的来说,\(P=(F-1)/2\) 那么输入的维度将会得到保留。如果要使用更大的卷积和(如7×7),通常只会在第一个卷积层上看到。
池化层
池化层负责对输入的空间维度进行下采样,通常使用的是感受野为2×2并且步长为2的max-pooling操作。这样做将会丢弃前一个层75%的激活值。另一个稍微不太常见的设置是使用3x3感受野,步幅为2。感受野大于3的池化操作是非常罕见的,因为池化操作有非常大的损耗和非常激进,通常会导致性能下降。
上面描述的模式中卷积层保留了输入的空间尺寸,而池化层负责对输入的空间维度进行下采样。减轻了考虑大小的烦恼,在另一个可行的模式中,卷积层使用大于1的步幅,并且不使用零填充,这样的话我们需要仔细考虑输入卷在整个网络的大小变化,并且确保步幅和滤波器能够正常工作。
为什么卷积的步幅为1?
在实践中,小的步幅有良好的表现。步幅为1允许我们将所有的空间下采样保留到池化层,而在卷积层只仅仅在深度方向转换输入Volume。
内存限制所做的妥协
在某些情况下(特别是卷积网络的前几层),上面描述的规则,内存的增长变得非常快。例如使用使用三个3×3的卷积层(每层64个卷积核,并且使用“零-填充”) 应用在[224×224×3]的图像上,将会有10,000,000 个激活值。由于内存是GPU的瓶颈,所以做这个妥协是很重要的。在实际应用上,人们通常在第一个卷积层上做妥协。例如在第一个卷积层上使用7×7的卷积核,并且步幅为2(如ZF net),另一个例子是AlexNet,使用 11×11的卷积核, 步幅为4.
为什么要padding
除了上面所说的在CONV之后保持空间大小恒定之外。如果CONV层没有对输入进行“零-填充”并且只执行有效的卷积,那么在每个CONV之后卷的大小会减少一小部分,并且边界处的信息将被“冲走”得太快。
Convolutional Neural Networks的更多相关文章
- tensorfolw配置过程中遇到的一些问题及其解决过程的记录(配置SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real-Time Object Detection for Autonomous Driving)
今天看到一篇关于检测的论文<SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real- ...
- Notes on Convolutional Neural Networks
这是Jake Bouvrie在2006年写的关于CNN的训练原理,虽然文献老了点,不过对理解经典CNN的训练过程还是很有帮助的.该作者是剑桥的研究认知科学的.翻译如有不对之处,还望告知,我好及时改正, ...
- 《ImageNet Classification with Deep Convolutional Neural Networks》 剖析
<ImageNet Classification with Deep Convolutional Neural Networks> 剖析 CNN 领域的经典之作, 作者训练了一个面向数量为 ...
- 卷积神经网络CNN(Convolutional Neural Networks)没有原理只有实现
零.说明: 本文的所有代码均可在 DML 找到,欢迎点星星. 注.CNN的这份代码非常慢,基本上没有实际使用的可能,所以我只是发出来,代表我还是实践过而已 一.引入: CNN这个模型实在是有些年份了, ...
- A Beginner's Guide To Understanding Convolutional Neural Networks(转)
A Beginner's Guide To Understanding Convolutional Neural Networks Introduction Convolutional neural ...
- 阅读笔记 The Impact of Imbalanced Training Data for Convolutional Neural Networks [DegreeProject2015] 数据分析型
The Impact of Imbalanced Training Data for Convolutional Neural Networks Paulina Hensman and David M ...
- 读convolutional Neural Networks Applied to House Numbers Digit Classification 的收获。
本文以下内容来自读论文以后认为有价值的地方,论文来自:convolutional Neural Networks Applied to House Numbers Digit Classificati ...
- (转)A Beginner's Guide To Understanding Convolutional Neural Networks Part 2
Adit Deshpande CS Undergrad at UCLA ('19) Blog About A Beginner's Guide To Understanding Convolution ...
- 论文笔记之:Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking
Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking arXiv Paper ...
- (转)A Beginner's Guide To Understanding Convolutional Neural Networks
Adit Deshpande CS Undergrad at UCLA ('19) Blog About A Beginner's Guide To Understanding Convolution ...
随机推荐
- JavaScript中实现最高效的数组乱序方法
数组乱序的意思是,把数组内的所有元素排列顺序打乱. 常用的办法是给数组原生的sort方法传入一个函数,此函数随机返回1或-1,达到随机排列数组元素的目的. 复制代码代码如下: arr.sort(fun ...
- SUST OJ 1642: 绝地求生—死亡顺序
1642: 绝地求生-死亡顺序 时间限制: 1 Sec 内存限制: 128 MB提交: 81 解决: 53[提交][状态][讨论版] 题目描述 最近陕西科技大学六公寓的小东同学深深的入迷了一款游戏 ...
- Centos(linux)下的Python
Centos(linux)下安装python3(python2和python3共存) yum -y install lrzsz 首先安装lrzsz工具,lrzsz是一款在linux里可代替ftp上传和 ...
- java8 array、list操作 汇【3】)(-Java8新特性之Collectors 详解
//编写一个定制的收集器 public static class MultisetCollector<T> implements Collector<T, Multiset<T ...
- LG2945 【[USACO09MAR]沙堡Sand Castle】
经典的贪心模型,常规思路:将M和B排序即可 看到没有人用优先队列,于是我的showtime到了 说下思路: 读入时将数加入啊a,b堆中,不用处理(二叉堆本来就有有序的性质) 读完后逐个判断,照题目模拟 ...
- TensorFlow笔记-05-反向传播,搭建神经网络的八股
TensorFlow笔记-05-反向传播,搭建神经网络的八股 反向传播 反向传播: 训练模型参数,在所有参数上用梯度下降,使用神经网络模型在训练数据上的损失函数最小 损失函数:(loss) 计算得到的 ...
- asterisk channel driver dev ref
入口函数load_module load_config ast_channel_register console_tech ast_cli_register_multiple ...
- JUC集合之 LinkedBlockingQueue
LinkedBlockingQueue介绍 LinkedBlockingQueue是一个单向链表实现的阻塞队列.该队列按 FIFO(先进先出)排序元素,新元素插入到队列的尾部,并且队列获取操作会获得位 ...
- java 设计模式:单例模式
Java中单例模式是一种常见的设计模式,单例模式的写法有好几种,这里主要介绍三种:懒汉式单例.饿汉式单例.登记式单例. 单例模式有以下特点: 1.单例类只能有一个实例. 2.单例类必须自己创建自己的唯 ...
- dede的织梦问答模块也可以支持arclist标签
dedecms织梦问答等模块支持arclist标签,实现随机调用其他栏目文章 就是让模块模板文件支持调用主站的模板,因为调用主站下的/templets/default/模板,也就实现了支持调用所有标签 ...