端到端文本识别CRNN论文解读
CRNN不定长中文识别项目下载地址: https://download.csdn.net/download/dcrmg/10248818
CRNN是一种卷积循环神经网络结构,用于解决基于图像的序列识别问题,特别是场景文字识别问题。CRNN网络结构:
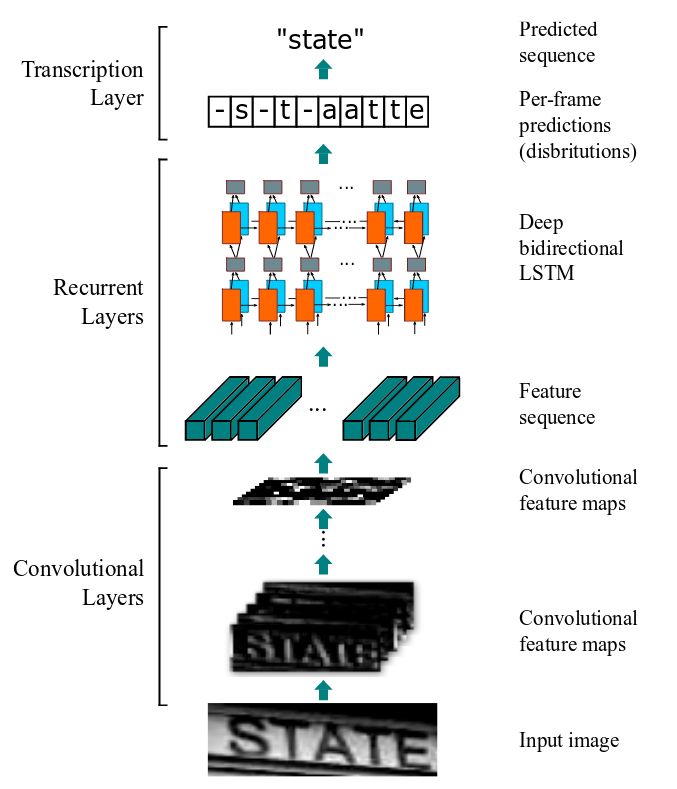
网络结构包含三部分,从下到上依次为:
1. 卷积层,作用是从输入图像中提取特征序列;
2. 循环层,作用是预测从卷积层获取的特征序列的标签(真实值)分布;
3. 转录层,作用是把从循环层获取的标签分布通过去重整合等操作转换成最终的识别结果;
卷积层
CRNN卷积层由标准的CNN模型中的卷积层和最大池化层组成,自动提取出输入图像的特征序列。
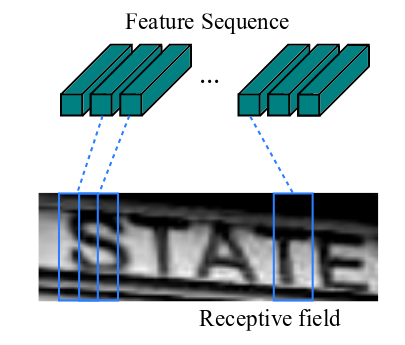
与普通CNN网络不同的是,CRNN在训练之前,先把输入图像缩放到相同高度(图像宽度维持原样),论文中使用的高度值是32。
提取的特征序列中的向量是从特征图上从左到右按照顺序生成的,每个特征向量表示了图像上一定宽度上的特征,论文中使用的这个宽度是1,就是单个像素。
特别强调序列的顺序是因为在之后的循环层中,先后顺序是LSTM训练中的一个重要参考量。
循环层
循环层由一个双向LSTM循环神经网络构成,预测特征序列中的每一个特征向量的标签分布(真实结果的概率列表),循环层的误差被反向传播,最后会转换成特征序列,再把特征序列反馈到卷积层,这个转换操作由论文中定义的“Map-to-Sequence”自定义网络层完成,作为卷积层和循环层之间连接的桥梁。
转录层
转录是将LSTM网络预测的特征序列的所有可能的结果进行整合,转换为最终结果的过程。论文中实在双向LSTM网络的最后连接上一个CTC模型,做到端对端的识别。
CTC模型(Connectionist temporal classification) 联接时间分类,CTC可以执行端到端的训练,不要求训练数据对齐和一一标注,直接输出不定长的序列结果。
CTC一般连接在RNN网络的最后一层用于序列学习和训练。对于一段长度为T的序列来说,每个样本点t(t远大于T)在RNN网络的最后一层都会输出一个softmax向量,表示该样本点的预测概率,所有样本点的这些概率传输给CTC模型后,输出最可能的标签,再经过去除空格(blank)和去重操作,就可以得到最终的序列标签。
网络结构简图:
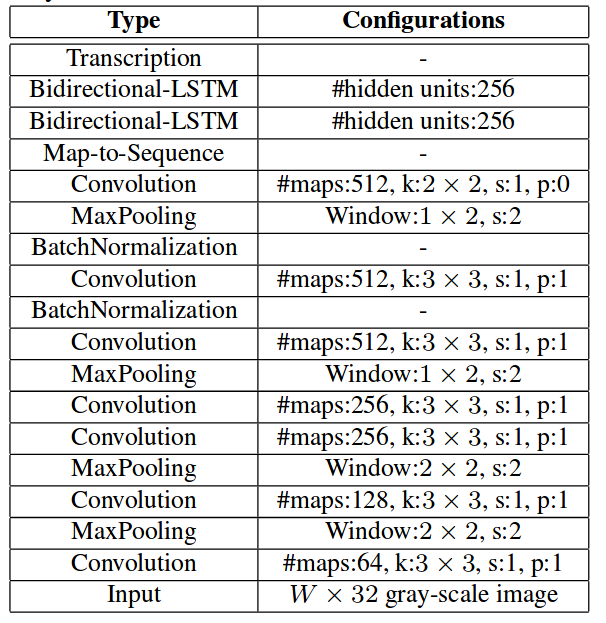
网络结构Keras定义:
def get_model(height,nclass):
input = Input(shape=(height,None,1),name='the_input')
m = Conv2D(64,kernel_size=(3,3),activation='relu',padding='same',name='conv1')(input)
m = MaxPooling2D(pool_size=(2,2),strides=(2,2),name='pool1')(m)
m = Conv2D(128,kernel_size=(3,3),activation='relu',padding='same',name='conv2')(m)
m = MaxPooling2D(pool_size=(2,2),strides=(2,2),name='pool2')(m)
m = Conv2D(256,kernel_size=(3,3),activation='relu',padding='same',name='conv3')(m)
m = Conv2D(256,kernel_size=(3,3),activation='relu',padding='same',name='conv4')(m)
m = ZeroPadding2D(padding=(0,1))(m)
m = MaxPooling2D(pool_size=(2,2),strides=(2,1),padding='valid',name='pool3')(m)
m = Conv2D(512,kernel_size=(3,3),activation='relu',padding='same',name='conv5')(m)
m = BatchNormalization(axis=1)(m)
m = Conv2D(512,kernel_size=(3,3),activation='relu',padding='same',name='conv6')(m)
m = BatchNormalization(axis=1)(m)
m = ZeroPadding2D(padding=(0,1))(m)
m = MaxPooling2D(pool_size=(2,2),strides=(2,1),padding='valid',name='pool4')(m)
m = Conv2D(512,kernel_size=(2,2),activation='relu',padding='valid',name='conv7')(m)
m = Permute((2,1,3),name='permute')(m)
m = TimeDistributed(Flatten(),name='timedistrib')(m)
m = Bidirectional(GRU(rnnunit,return_sequences=True),name='blstm1')(m)
m = Dense(rnnunit,name='blstm1_out',activation='linear')(m)
m = Bidirectional(GRU(rnnunit,return_sequences=True),name='blstm2')(m)
y_pred = Dense(nclass,name='blstm2_out',activation='softmax')(m)
basemodel = Model(inputs=input,outputs=y_pred)
labels = Input(name='the_labels', shape=[None,], dtype='float32')
input_length = Input(name='input_length', shape=[1], dtype='int64')
label_length = Input(name='label_length', shape=[1], dtype='int64')
loss_out = Lambda(ctc_lambda_func, output_shape=(1,), name='ctc')([y_pred, labels, input_length, label_length])
model = Model(inputs=[input, labels, input_length, label_length], outputs=[loss_out])
# sgd = SGD(lr=0.001, decay=1e-6, momentum=0.9, nesterov=True, clipnorm=5)
sgd = SGD(lr=0.0003, decay=1e-6, momentum=0.6, nesterov=True, clipnorm=5)
#model.compile(loss={'ctc': lambda y_true, y_pred: y_pred}, optimizer='adadelta')
model.compile(loss={'ctc': lambda y_true, y_pred: y_pred}, optimizer=sgd)
model.summary()
return model,basemodel端到端文本识别CRNN论文解读的更多相关文章
- 【OCR技术系列之八】端到端不定长文本识别CRNN代码实现
CRNN是OCR领域非常经典且被广泛使用的识别算法,其理论基础可以参考我上一篇文章,本文将着重讲解CRNN代码实现过程以及识别效果. 数据处理 利用图像处理技术我们手工大批量生成文字图像,一共360万 ...
- CVPR2020行人重识别算法论文解读
CVPR2020行人重识别算法论文解读 Cross-modalityPersonre-identificationwithShared-SpecificFeatureTransfer 具有特定共享特征变换 ...
- 【OCR技术系列之七】端到端不定长文字识别CRNN算法详解
在以前的OCR任务中,识别过程分为两步:单字切割和分类任务.我们一般都会讲一连串文字的文本文件先利用投影法切割出单个字体,在送入CNN里进行文字分类.但是此法已经有点过时了,现在更流行的是基于深度学习 ...
- CVPR2020论文解读:OCR场景文本识别
CVPR2020论文解读:OCR场景文本识别 ABCNet: Real-time Scene Text Spotting with Adaptive Bezier-Curve Network∗ 论文 ...
- 点云配准的端到端深度神经网络:ICCV2019论文解读
点云配准的端到端深度神经网络:ICCV2019论文解读 DeepVCP: An End-to-End Deep Neural Network for Point Cloud Registration ...
- 论文解读丨表格识别模型TableMaster
摘要:在此解决方案中把表格识别分成了四个部分:表格结构序列识别.文字检测.文字识别.单元格和文字框对齐.其中表格结构序列识别用到的模型是基于Master修改的,文字检测模型用到的是PSENet,文字识 ...
- 带你读AI论文丨LaneNet基于实体分割的端到端车道线检测
摘要:LaneNet是一种端到端的车道线检测方法,包含 LanNet + H-Net 两个网络模型. 本文分享自华为云社区<[论文解读]LaneNet基于实体分割的端到端车道线检测>,作者 ...
- 基于tensorflow的‘端到端’的字符型验证码识别源码整理(github源码分享)
基于tensorflow的‘端到端’的字符型验证码识别 1 Abstract 验证码(CAPTCHA)的诞生本身是为了自动区分 自然人 和 机器人 的一套公开方法, 但是近几年的人工智能技术的发展 ...
- 基于python语言的tensorflow的‘端到端’的字符型验证码识别源码整理(github源码分享)
基于python语言的tensorflow的‘端到端’的字符型验证码识别 1 Abstract 验证码(CAPTCHA)的诞生本身是为了自动区分 自然人 和 机器人 的一套公开方法, 但是近几年的 ...
随机推荐
- Js页面自动跳转
//声明 t = 1 var t = 10; function openwin() { t -= 1; if(t==0){ location.href='index2.html'; } setTime ...
- python 本地化 local
locale 模块提供了 C 本地化( localization )函数的接口, 如 Example 8-1 所示. 同时提供相关函数, 实现基于当前 locale 设置的数字, 字符串转换. (而 ...
- shell 去掉字符串的单引号
echo \'deded\' | sed $'s/\'//g'
- Flutter学习笔记(二)
*.assets 当引用图片的时候,需要在pubspec.yaml的文件中的flutter下添加assets,类似于下面的样子: image.png 这里需要注意的是文件里的assets只要一个缩进即 ...
- 远程SqlServer服务器
①,安装net framework3.5. ②,安装sqlserver2014(例). ③,基本配置. 安装sqlserver2014时,开启混合认证模式.当然,也可以在安装后,通过sqlserver ...
- Codeforces 918D - MADMAX
918D - MADMAX 思路: dp+记忆化搜索 状态:dp[i][j][w]表示先手在i节点,后手在j节点,这一轮的字母为w的结果,如果为true,则表示先手必赢,否则后手必赢. 状态转移:如果 ...
- PWA小记
前言 中国有不一样的MobileFirst战略,重原生应用,轻移动网页: 移动网页的弱势:页面设计优化有限,用户体验受网络环境影响,网页开启不方便: web优势是产品分发 app优势是产品使用和交互 ...
- Spring Cloud常用组件介绍
一.Eureka (Netfix下) 云端服务发现,一个基于 REST 的服务,用于定位服务,以实现云端中间层服务发现和故障转移. 二.Spring Cloud Config (Spring下) 配置 ...
- 20170324xlVBA最简单分类计数
Sub NextSeven_CodeFrame() Application.ScreenUpdating = False Application.DisplayAlerts = False Appli ...
- bzoj1202: [HNOI2005]狡猾的商人 floyd
刁姹接到一个任务,为税务部门调查一位商人的账本,看看账本是不是伪造的.账本上记录了n个月以来的收入情况,其中第i 个月的收入额为Ai(i=1,2,3...n-1,n), .当 Ai大于0时表示这个月盈 ...