数据规整化:pandas 求合并数据集(交集并集等)
数据集的合并或连接运算是通过一个或多个键将行链接起来的。这些运算是关系型数据库的核心。pandas的merge函数是对数据应用这些算法的这样切入点。
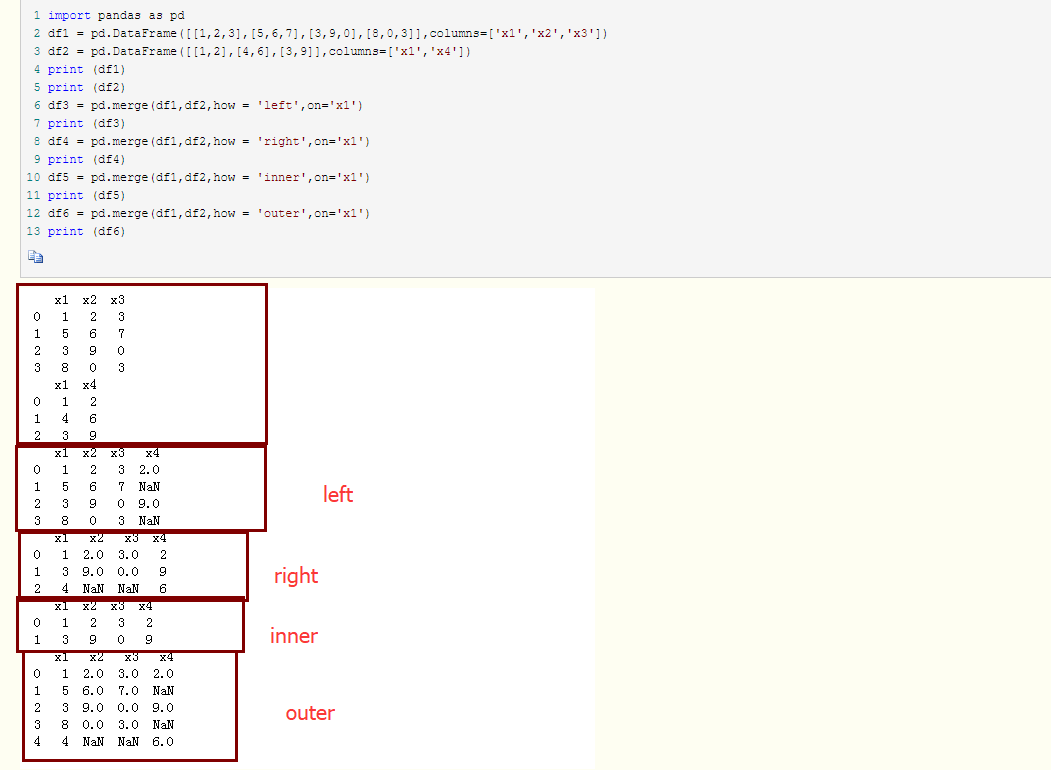
默认是交集, inner连接
列名不同可以分别指定:

其他方式还要‘left’、‘right’以及“outer”。外链接求取的是键的并集, 组合了左连接和右连接的效果。

how 的作用是合并时候以谁为标准,是否保留NaN值
多对多

多对多 连接产生的行的笛卡尔积。由于左边的DataFrame有3个‘b’行, 右边的有2个,所以最终结果中
就有6个‘b’行。

根据多个键进行合并, 传入一个由列明组成的列表即可:
left = DataFrame(
{"key1": ['foo', 'foo', 'bar'],
"key2": ['one', 'two', 'one'],
"lval": [, , ]
}
)
right = DataFrame(
{"key1": ['foo', 'foo', 'bar', 'bar'],
"key2": ['one', 'one', 'one', 'two'],
"rval": [, , , ]
}
)
print(left)
print(right)
pm = pd.merge(left, right, on=["key1", "key2"], how="outer")
print(pm)


on与left_on 和right_on的区别

这个是left_on 和right_on

去重或更改后缀

merge函数的参数

索引上的合并

merge方法求取连接键的并集

对于层次化索引的数据
这个时候必须以列表的形式指明用作合并键的多个列(注意对重复索引的处理)
lefth = DataFrame({'key1':[ 'Ohio', 'Ohio', 'Ohio','Nevada', 'Nevada',],
"key2":[, , ,, ],
"data":np.arange(.)
})
righth = DataFrame(np.arange().reshape((, )),
index=[['Nevada', 'Nevada', 'Ohio', 'Ohio', 'Ohio', 'Ohio'],
[, , , , , ]],
columns=['event1', 'event2']
)
print(lefth)
print(righth)
pm = pd.merge(lefth, righth,left_on=['key1', 'key2'], right_index=True)
print(pm)

索引并集

DataFrame.join实例方法
它能更为方便地实现索引合并。它还可用于和合并多个带有相同或相似索引的DataFrame对象, 而不管他们
之间有重叠的列。

print(left1.join(right1, how='inner')) left2.join([1, 2], how='outer') #多个
数据规整化:pandas 求合并数据集(交集并集等)的更多相关文章
- Python之数据规整化:清理、转换、合并、重塑
Python之数据规整化:清理.转换.合并.重塑 1. 合并数据集 pandas.merge可根据一个或者多个不同DataFrame中的行连接起来. pandas.concat可以沿着一条轴将多个对象 ...
- 《python for data analysis》第七章,数据规整化
<利用Python进行数据分析>第七章的代码. # -*- coding:utf-8 -*-# <python for data analysis>第七章, 数据规整化 imp ...
- 【学习】数据规整化:清理、转换、合并、重塑【pandas】
这一部分非常关键! 数据分析和建模方面的大量编程工作都是用在数据准备上的:加载.清理.转换以及重塑. 1.合并数据集 pandas对象中的数据可以通过 一些内置的方式进行合并: pandas.merg ...
- 利用Python进行数据分析——数据规整化:清理、转换、合并、重塑(七)(1)
数据分析和建模方面的大量编程工作都是用在数据准备上的:载入.清理.转换以及重塑.有时候,存放在文件或数据库中的数据并不能满足你的数据处理应用的要求.很多人都选择使用通用编程语言(如Python.Per ...
- 利用Python进行数据分析-Pandas(第五部分-数据规整:聚合、合并和重塑)
在许多应用中,数据可能分散在许多文件或数据库中,存储的形式也不利于分析.本部分关注可以聚合.合并.重塑数据的方法. 1.层次化索引 层次化索引(hierarchical indexing)是panda ...
- Python 数据分析(一) 本实验将学习 pandas 基础,数据加载、存储与文件格式,数据规整化,绘图和可视化的知识
第1节 pandas 回顾 第2节 读写文本格式的数据 第3节 使用 HTML 和 Web API 第4节 使用数据库 第5节 合并数据集 第6节 重塑和轴向旋转 第7节 数据转换 第8节 字符串操作 ...
- 利用python进行数据分析之数据规整化
数据分析和建模大部分时间都用在数据准备上,数据的准备过程包括:加载,清理,转换与重塑. 合并数据集 pandas对象中的数据可以通过一些内置方法来进行合并: pandas.merge可根据一个或多个键 ...
- 利用Python进行数据分析 第8章 数据规整:聚合、合并和重塑.md
学习时间:2019/11/03 周日晚上23点半开始,计划1110学完 学习目标:Page218-249,共32页:目标6天学完(按每页20min.每天1小时/每天3页,需10天) 实际反馈:实际XX ...
- 第三章 python数据规整化
本章概要 1.去重 2.缺失值处理 3.清洗字符型数据的空格 4.字段抽取 去重 把数据结构中,行相同的数据只保留一行 函数语法: drop_duplicates() #导入pandas包中的read ...
随机推荐
- 【Unity】第7章 输入控制
分类:Unity.C#.VS2015 创建日期:2016-04-21 一.简介 Unity提供了-个非常易用和强大的用于处理输入信息的类:Input,利用该类可以处理鼠标.键盘.摇杆/方向盘/手柄等游 ...
- 行为类模式(八):状态(State)
定义 当一个对象的内在状态改变时允许改变其行为,这个对象看起来像是改变了其类. 状态模式主要解决的是当控制一个对象状态的条件表达式过于复杂时的情况.把状态的判断逻辑转移到表示不同状态的一系列类中,可以 ...
- (原创)C++11改进我们的程序之简化我们的程序(三)
这次要讲的是:C++11如何通过auto.decltype和返回值后置来简化我们的程序. auto和c#中的var类似,都是在初始化时自动推断出数据类型.当某个变量的返回值难于书写时,或者不太确定返回 ...
- Android中XML文件的序列化生成与解析
xml文件是非常常用的,在android中json和xml是非常常用的两种封装数据的形式,从服务器中获取数据也经常是这两种形式的,所以学会生成和解析xml和json是非常有用的,json相对来说是比较 ...
- flex布局知识点(阮一峰博客)
任何一个容器都可以指定为flex布局: 行内元素也可以使用flex布局: 设为flex布局以后,子元素的float,clear,vertical-align属性都将失效: flex容器的属性: fle ...
- 内部排序比较(Java版)
内部排序比较(Java版) 2017-06-21 目录 1 三种基本排序算法1.1 插入排序1.2 交换排序(冒泡)1.3 选择排序(简单)2 比较3 补充3.1 快速排序3.2 什么是桶排序3.3 ...
- js判断是否安装flash player及当前版本 和 检查flash版本是否需要升级
一.js检查flash版本升级 for (var i = 0, len = navigator.plugins.length; i < len; i++) { var plugin = navi ...
- 【iCore4 双核心板_FPGA】例程三:计数器实验——计数器使用
实验现象: 绿色led闪烁 核心源代码: //--------------------module_counter_ctrl--------------------// module counter_ ...
- CSS一个元素同时使用多个类选择器(class selector)
CSS类选择器参考手册 一个元素同时使用多个类选择器 CSS中类选择器用点号表示.实际项目中一个div元素为了能被多个样式表匹配到(样式复用),通常div的class中由好几段组成,如<div ...
- Writing your first Django
Quick install guide 1.1 Install Python, it works with Python2.6, 2.7, 3.2, 3.3. All these version ...