elasticsearch简介和倒排序索引介绍
介绍
我们为什么要用搜索引擎?我们的所有数据在数据库里面都有,而且 Oracle、SQL Server 等数据库里也能提供查询检索或者聚类分析功能,直接通过数据库查询不就可以了吗?确实,我们大部分的查询功能都可以通过数据库查询获得,如果查询效率低下,还可以通过建数据库索引,优化SQL等方式进行提升效率,甚至通过引入缓存来加快数据的返回速度。如果数据量更大,就可以分库分表来分担查询压力。
那为什么还要全文搜索引擎呢?我们主要从以下几个原因分析:
数据类型
全文索引搜索支持非结构化数据的搜索,可以更好地快速搜索大量存在的任何单词或单词组的非结构化文本。
例如 Google,百度类的网站搜索,它们都是根据网页中的关键字生成索引,我们在搜索的时候输入关键字,它们会将该关键字即索引匹配到的所有网页返回;还有常见的项目中应用日志的搜索等等。对于这些非结构化的数据文本,关系型数据库搜索不是能很好的支持。索引的维护
一般传统数据库,全文检索都实现的很鸡肋,因为一般也没人用数据库存文本字段。进行全文检索需要扫描整个表,如果数据量大的话即使对SQL的语法优化,也收效甚微。建立了索引,但是维护起来也很麻烦,对于 insert 和 update 操作都会重新构建索引。
什么时候使用全文搜索引擎:
- 搜索的数据对象是大量的非结构化的文本数据。
- 文件记录量达到数十万或数百万个甚至更多。
- 支持大量基于交互式文本的查询。
- 需求非常灵活的全文搜索查询。
- 对高度相关的搜索结果的有特殊需求,但是没有可用的关系数据库可以满足。
- 对不同记录类型、非文本数据操作或安全事务处理的需求相对较少的情况。
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎.
Elasticsearch 是一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎. 当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作:
分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
实时分析的分布式搜索引擎。
可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
基本概念
先说Elasticsearch的文件存储,Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式,比如下面这条用户数据:
{"name":"John","sex":"Male","age":25,"birthDate":"1990/05/01","about":"I love to go rock climbing","interests":["sports","music"]}
用Mysql这样的数据库存储就会容易想到建立一张User表,有balabala的字段等,在Elasticsearch里这就是一个文档,当然这个文档会属于一个User的类型,各种各样的类型存在于一个索引当中。这里有一份简易的将Elasticsearch和关系型数据术语对照表:
关系数据库 ⇒ 数据库 ⇒ 表 ⇒ 行 ⇒ 列(Columns)
Elasticsearch ⇒ 索引 ⇒ 类型 ⇒ 文档 ⇒ 字段(Fields)
一个 Elasticsearch 集群可以包含多个索引(数据库),也就是说其中包含了很多类型(表)。这些类型中包含了很多的文档(行),然后每个文档中又包含了很多的字段(列)。
Elasticsearch的交互,可以使用Java API,也可以直接使用HTTP的Restful API方式,比如我们打算插入一条记录,可以简单发送一个HTTP的请求:
PUT/megacorp/employee/1{"name":"John","sex":"Male","age":25,"about":"I love to go rock climbing","interests":["sports","music"]}
更新,查询也是类似这样的操作,具体操作手册可以参见Elasticsearch权威指南
倒排序索引
Elasticsearch最关键的就是提供强大的索引能力了。
Elasticsearch索引的精髓:
一切设计都是为了提高搜索的性能
另一层意思:为了提高搜索的性能,难免会牺牲某些其他方面,比如插入/更新,否则其他数据库不用混了:)
前面看到往Elasticsearch里插入一条记录,其实就是直接PUT一个json的对象,这个对象有多个fields,那么在插入这些数据到Elasticsearch的同时,Elasticsearch还默默的为这些字段建立索引–倒排索引,因为Elasticsearch最核心功能是搜索。
Elasticsearch是如何做到快速索引的
InfoQ那篇文章里说Elasticsearch使用的倒排索引比关系型数据库的B-Tree索引快,为什么呢?
什么是B-Tree索引?
二叉树查找效率是logN,同时插入新的节点不必移动全部节点,所以用树型结构存储索引,能同时兼顾插入和查询的性能。
因此在这个基础上,再结合磁盘的读取特性(顺序读/随机读),传统关系型数据库采用了B-Tree/B+Tree这样的数据结构:
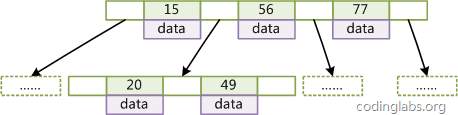
为了提高查询的效率,减少磁盘读取次数,将多个值作为一个数组通过连续区间存放,一次读取多个数据,同时也降低树的高度。
什么是倒排索引?

继续上面的例子,假设有这么几条数据(为了简单,去掉about, interests这两个field):
| ID | Name | Age | Sex |
|---|---|---|---|
| 1 | Kate | 24 | Female |
| 2 | John | 24 | Male |
| 3 | Bill | 29 | Male |
ID是Elasticsearch自建的文档id,那么Elasticsearch建立的索引如下:
Name:
| Term | Posting List |
|---|---|
| Kate | 1 |
| John | 2 |
| Bill | 3 |
Age:
| Term | Posting List |
|---|---|
| 24 | [1,2] |
| 29 | 3 |
Sex:
| Term | Posting List |
|---|---|
| Female | 1 |
| Male | [2,3] |
Posting List
Elasticsearch分别为每个field都建立了一个倒排索引,Kate, John, 24, Female这些叫term,而[1,2]就是Posting List。Posting list就是一个int的数组,存储了所有符合某个term的文档id。
看到这里,不要认为就结束了,精彩的部分才刚开始…
通过posting list这种索引方式似乎可以很快进行查找,比如要找age=24的同学,爱回答问题的小明马上就举手回答:我知道,id是1,2的同学。但是,如果这里有上千万的记录呢?如果是想通过name来查找呢?
Term Dictionary
Elasticsearch为了能快速找到某个term,将所有的term排个序,二分法查找term,logN的查找效率,就像通过字典查找一样,这就是Term Dictionary。现在再看起来,似乎和传统数据库通过B-Tree的方式类似啊,为什么说比B-Tree的查询快呢?
Term Index
B-Tree通过减少磁盘读取次数来提高查询性能,Elasticsearch也是采用同样的思路,直接通过内存查找term,不读磁盘,但是如果term太多,term dictionary也会很大,放内存不现实,于是有了Term Index,就像字典里的索引页一样,A开头的有哪些term,分别在哪页,可以理解term index是一颗树: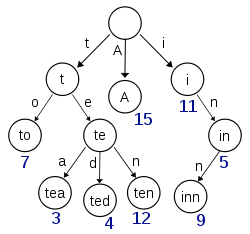
这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。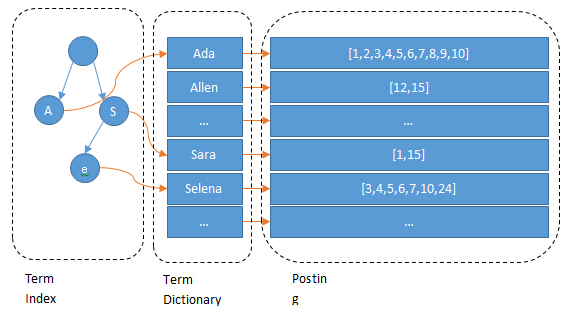
所以term index不需要存下所有的term,而仅仅是他们的一些前缀与Term Dictionary的block之间的映射关系,再结合FST(Finite State Transducers)的压缩技术,可以使term index缓存到内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘随机读的次数。
这时候爱提问的小明又举手了:”那个FST是神马东东啊?”
假设我们现在要将mop, moth, pop, star, stop and top(term index里的term前缀)映射到序号:0,1,2,3,4,5(term dictionary的block位置)。最简单的做法就是定义个Map<String, Integer>,大家找到自己的位置对应入座就好了,但从内存占用少的角度想想,有没有更优的办法呢?答案就是:FST(理论依据在此,但我相信99%的人不会认真看完的)
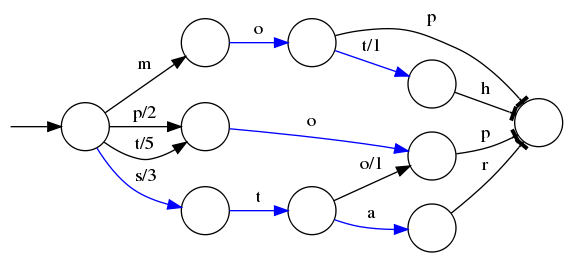
⭕️表示一种状态
–>表示状态的变化过程,上面的字母/数字表示状态变化和权重
将单词分成单个字母通过⭕️和–>表示出来,0权重不显示。如果⭕️后面出现分支,就标记权重,最后整条路径上的权重加起来就是这个单词对应的序号。
FSTs are finite-state machines that map a term (byte sequence) to an arbitrary output.
FST以字节的方式存储所有的term,这种压缩方式可以有效的缩减存储空间,使得term index足以放进内存,但这种方式也会导致查找时需要更多的CPU资源。
后面的更精彩,看累了的同学可以喝杯咖啡……
压缩技巧
Elasticsearch里除了上面说到用FST压缩term index外,对posting list也有压缩技巧。 小明喝完咖啡又举手了:”posting list不是已经只存储文档id了吗?还需要压缩?”
嗯,我们再看回最开始的例子,如果Elasticsearch需要对同学的性别进行索引(这时传统关系型数据库已经哭晕在厕所……),会怎样?如果有上千万个同学,而世界上只有男/女这样两个性别,每个posting list都会有至少百万个文档id。 Elasticsearch是如何有效的对这些文档id压缩的呢?
Frame Of Reference
增量编码压缩,将大数变小数,按字节存储
首先,Elasticsearch要求posting list是有序的(为了提高搜索的性能,再任性的要求也得满足),这样做的一个好处是方便压缩,看下面这个图例: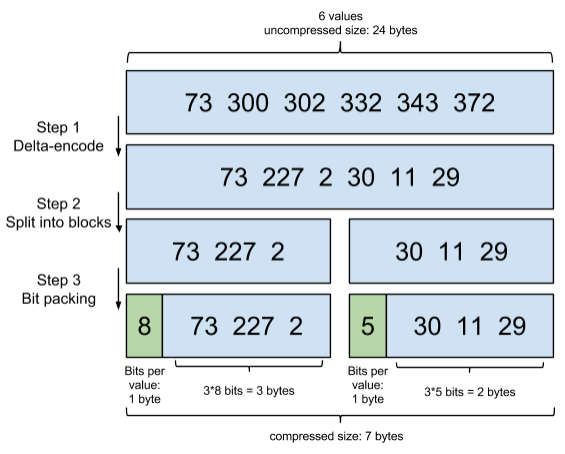
如果数学不是体育老师教的话,还是比较容易看出来这种压缩技巧的。
原理就是通过增量,将原来的大数变成小数仅存储增量值,再精打细算按bit排好队,最后通过字节存储,而不是大大咧咧的尽管是2也是用int(4个字节)来存储。
Roaring bitmaps
说到Roaring bitmaps,就必须先从bitmap说起。Bitmap是一种数据结构,假设有某个posting list:
[1,3,4,7,10]
对应的bitmap就是:
[1,0,1,1,0,0,1,0,0,1]
非常直观,用0/1表示某个值是否存在,比如10这个值就对应第10位,对应的bit值是1,这样用一个字节就可以代表8个文档id,旧版本(5.0之前)的Lucene就是用这样的方式来压缩的,但这样的压缩方式仍然不够高效,如果有1亿个文档,那么需要12.5MB的存储空间,这仅仅是对应一个索引字段(我们往往会有很多个索引字段)。于是有人想出了Roaring bitmaps这样更高效的数据结构。
Bitmap的缺点是存储空间随着文档个数线性增长,Roaring bitmaps需要打破这个魔咒就一定要用到某些指数特性:
将posting list按照65535为界限分块,比如第一块所包含的文档id范围在0~65535之间,第二块的id范围是65536~131071,以此类推。再用<商,余数>的组合表示每一组id,这样每组里的id范围都在0~65535内了,剩下的就好办了,既然每组id不会变得无限大,那么我们就可以通过最有效的方式对这里的id存储。
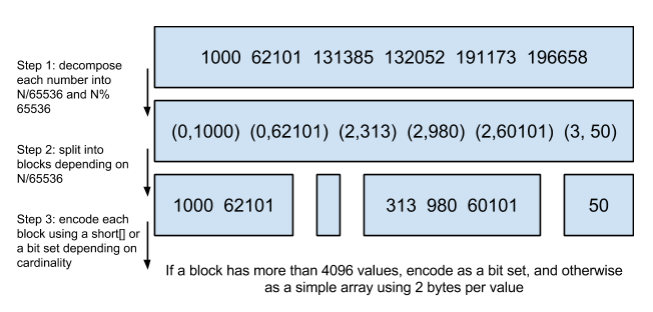
细心的小明这时候又举手了:”为什么是以65535为界限?”
程序员的世界里除了1024外,65535也是一个经典值,因为它=2^16-1,正好是用2个字节能表示的最大数,一个short的存储单位,注意到上图里的最后一行“If a block has more than 4096 values, encode as a bit set, and otherwise as a simple array using 2 bytes per value”,如果是大块,用节省点用bitset存,小块就豪爽点,2个字节我也不计较了,用一个short[]存着方便。
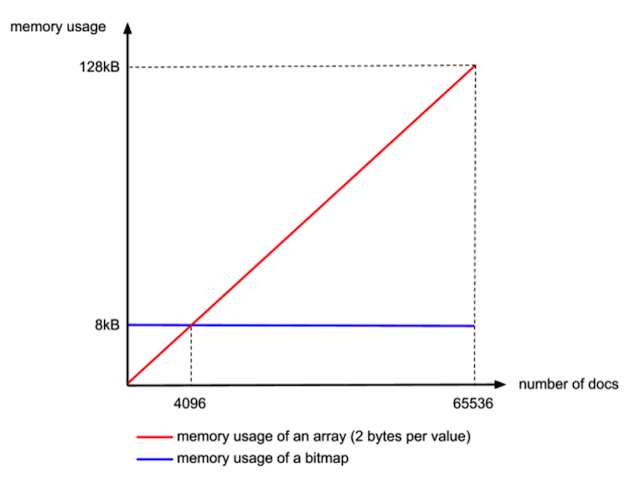
那为什么用4096来区分采用数组还是bitmap的阀值呢?
这个是从内存大小考虑的,当block块里元素超过4096后,用bitmap更剩空间: 采用bitmap需要的空间是恒定的: 65536/8 = 8192bytes 而如果采用short[],所需的空间是: 2*N(N为数组元素个数) 小明手指一掐N=4096刚好是边界:
联合索引
上面说了半天都是单field索引,如果多个field索引的联合查询,倒排索引如何满足快速查询的要求呢?
- 利用跳表(Skip list)的数据结构快速做“与”运算,或者
- 利用上面提到的bitset按位“与”
先看看跳表的数据结构:
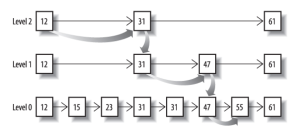
将一个有序链表level0,挑出其中几个元素到level1及level2,每个level越往上,选出来的指针元素越少,查找时依次从高level往低查找,比如55,先找到level2的31,再找到level1的47,最后找到55,一共3次查找,查找效率和2叉树的效率相当,但也是用了一定的空间冗余来换取的。
假设有下面三个posting list需要联合索引:
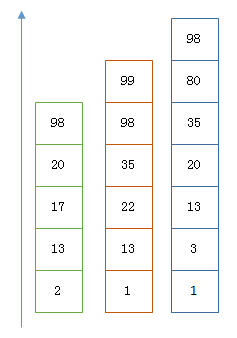
如果使用跳表,对最短的posting list中的每个id,逐个在另外两个posting list中查找看是否存在,最后得到交集的结果。
如果使用bitset,就很直观了,直接按位与,得到的结果就是最后的交集。
总结和思考
Elasticsearch的索引思路:
将磁盘里的东西尽量搬进内存,减少磁盘随机读取次数(同时也利用磁盘顺序读特性),结合各种奇技淫巧的压缩算法,用及其苛刻的态度使用内存。
所以,对于使用Elasticsearch进行索引时需要注意:
- 不需要索引的字段,一定要明确定义出来,因为默认是自动建索引的
- 同样的道理,对于String类型的字段,不需要analysis的也需要明确定义出来,因为默认也是会analysis的
- 选择有规律的ID很重要,随机性太大的ID(比如java的UUID)不利于查询
关于最后一点,个人认为有多个因素:
其中一个(也许不是最重要的)因素: 上面看到的压缩算法,都是对Posting list里的大量ID进行压缩的,那如果ID是顺序的,或者是有公共前缀等具有一定规律性的ID,压缩比会比较高;
另外一个因素: 可能是最影响查询性能的,应该是最后通过Posting list里的ID到磁盘中查找Document信息的那步,因为Elasticsearch是分Segment存储的,根据ID这个大范围的Term定位到Segment的效率直接影响了最后查询的性能,如果ID是有规律的,可以快速跳过不包含该ID的Segment,从而减少不必要的磁盘读次数,具体可以参考这篇如何选择一个高效的全局ID方案(评论也很精彩)
elasticsearch简介和倒排序索引介绍的更多相关文章
- Elasticsearch简介、倒排索引、文档基本操作、分词器
lucene.Solr.Elasticsearch 1.倒排序索引 2.Lucene是类库 3.solr基于lucene 4.ES基于lucene 一.Elasticsearch 核心术语 特点: 1 ...
- Elasticsearch 简介
1. 背景 Elasticsearch 在公司的使用越来越广,很多同事之前并没有接触过 Elasticsearch,所以,最近在公司准备了一次关于 Elasticsearch 的分享,整理成此文.此文 ...
- 第01章 ElasticSearch简介
本章内容 Apache Lucene是什么. Lucene的整体架构. 文本分析过程是如何实现的. Apache Lucene的查询语言及其使用方法. ElasticSearch的基本概念. ELas ...
- mysql性能优化-慢查询分析、优化索引和配置 MySQL索引介绍
MySQL索引介绍 聚集索引(Clustered Index)----叶子节点存放整行记录辅助索引(Secondary Index)----叶子节点存放row identifier-------Inn ...
- ElasticSearch中倒排索引和正向索引
ElasticSearch搜索使用的是倒排索引,但是排序.聚合等不适合倒排索引使用的是正向索引 倒排索引 倒排索引表以字或词为关键字进行索引,表中关键字所对应的记录项记录了出现这个字或词的所有文档,每 ...
- ElasticSearch简介和快速实战
ElasticSearch简介和快速实战 ElasticSearch与Lucene Lucene可以被认为是迄今为止最先进.性能最好的.功能最全的搜索引擎库(框架) 但是想要使用Lucene,必须使用 ...
- nls_sort和nlssort 排序功能介绍
nls_sort和nlssort 排序功能介绍 博客分类: oracle ALTER SESSION SET NLS_SORT=''; 排序影响整个会话 Oracle9i之前,中文是按照二进制编码 ...
- 技术分享会(二):SQLSERVER索引介绍
SQLSERVER索引介绍 一.SQLSERVER索引类型? 1.聚集索引: 2.非聚集索引: 3.包含索引: 4.列存储索引: 5.无索引(堆表): 二.如何创建索引? 索引示例: 建表 creat ...
- MySQL索引介绍
引言 今天Qi号与大家分享什么是索引.其实索引:索引就相当于书的目录 索引介绍 用官方的话说就是 索引是为了加速对表中数据行的检索而创建的一种分散的存储结构.索引是针对表而建立的,它是由数据页面以外的 ...
随机推荐
- Linux下axel多线程下载
axel插件是基于yum下的一个多线程下载 01.下载 wget http://www.ha97.com/code/axel-2.4.tar.gz wget https://files.cnblogs ...
- 抗衡Win Linux全凭这些桌面环境
2012年01月25日 元老级桌面环境KDE Linux操作系统最早使用在服务器上,而桌面操作系统并不是Linux的重点突围.但是,近几年Linux桌面操作系统有崛起的趋势,抢夺了部分桌面操作 ...
- iOS获取真机沙盒文件、获取真机本地数据
有时我们需要对真机内的数据进行分析,那么如何获取沙盒所有数据文件呢? 1.设备连接到电脑,打开xcode 2.打开window-devices 3.打开后,选择设备名,选择app,导出数据 4.最后拿 ...
- HDUOJ-------The Hardest Problem Ever
The Hardest Problem Ever Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java ...
- python+stomp+activemq
python也可以连接MQ,以ActiveMQ为例,安装stomp.py: https://github.com/jasonrbriggs/stomp.py 下载后安装: python setup.p ...
- k8s官方安装版本
一.概述 官方安装链接:https://kubernetes.io/docs/getting-started-guides/kubeadm/ 之前使用是yum直接安装组件,现由kubeadm来自动安装 ...
- 重整ADO.NET连接池相关资料
https://msdn.microsoft.com/zh-cn/library/system.data.sqlclient.sqlconnection.connectionstring(VS.80) ...
- 【Spring】SpringMVC之上传文件
这里笔者介绍利用SpringMVC上传图片的操作. 步骤 1. 引入jar文件 不仅需要导入开发SpringMVC相关的包,还需要导入 commons-fileupload-1.2.1.jar 和 ...
- Eclipse中创建Maven多模块工程
1.先创建父项目 在Eclipse里面New -> Maven Project: 在弹出界面中选择“Create a simple project” 这样,我们就按常规模版创建了一个Maven工 ...
- OpenCV 学习笔记 01 安装OpenCV及相关依赖库
本次学习是基于Window10进行的.语言为python3. 1 与opencv相关的库简介 1.1 numpy numpy 是 OpenCV 绑定 python 时所依赖的库,此意味着numpy在安 ...