关于Kafka幂等producer的讨论
众所周知,Kafka 0.11.0.0版本正式支持精确一次处理语义(exactly once semantics,下称EOS)。Kafka的EOS主要体现在3个方面:
- 幂等producer:保证发送单个分区的消息只会发送一次,不会出现重复消息
- 事务(transaction):保证原子性地写入到多个分区,即写入到多个分区的消息要么全部成功,要么全部回滚
- 流处理EOS:流处理本质上可看成是“读取-处理-写入”的管道。此EOS保证整个过程的操作是原子性。注意,这只适用于Kafka Streams
上面3种EOS语义有着不同的应用范围,幂等producr只能保证单分区上无重复消息;事务可以保证多分区写入消息的完整性;而流处理EOS保证的是端到端(E2E)消息处理的EOS。用户在使用过程中需要根据自己的需求选择不同的EOS。以下是启用方法:
- 启用幂等producer:在producer程序中设置属性enable.idempotence=true,但不要设置transactional.id。注意是不要设置,而不是设置成空字符串或"null"
- 启用事务支持:在producer程序中设置属性transcational.id为一个指定字符串(你可以认为这是你的事务名称,故最好起个有意义的名字),同时设置enable.idempotence=true
- 启用流处理EOS:在Kafka Streams程序中设置processing.guarantee=exactly_once
本文主要讨论幂等producer的设计与实现。
-----------------------------------------------------------------------
所谓幂等producer指producer.send的逻辑是幂等的,即发送相同的Kafka消息,broker端不会重复写入消息。同一条消息Kafka保证底层日志中只会持久化一次,既不会丢失也不会重复。幂等性可以极大地减轻下游consumer系统实现消息去重的工作负担,因此是非常实用的功能。值得注意的是,幂等producer提供的语义保证是有条件的:
- 单分区幂等性:幂等producer无法实现多分区上的幂等性。如前所述,若要实现多分区上的原子性,需要引入事务
- 单会话幂等性:幂等producer无法跨会话实现幂等性。即使同一个producer宕机并重启也无法保证消息的EOS语义
虽然有上面两个限制,幂等producer依然是一个非常实用的新功能。下面我们来讨论下它的设计原理。如果要实现幂等性, 通常都需要花费额外的空间来保存状态以执行消息去重。Kafka的幂等producer整体上也是这样的思想。
首先,producer对象引入了一个新的字段:Producer ID(下称PID),它唯一标识一个producer,当producer启动时Kafka会为每个producer分配一个PID(64位整数),因此PID的生成和分配对用户来说是完全透明的,用户无需考虑PID的事情,甚至都感受不到PID的存在。其次,0.11 Kafka重构了消息格式(有兴趣的参见Kafka 0.11消息设计),引入了序列号字段(sequence number,下称seq number)来标识某个PID producer发送的消息。和consumer端的offset类似,seq number从0开始计数并严格单调增加。同时在broker端会为每个PID(即每个producer)保存该producer发送过来的消息batch的某些元信息,比如PID信息、消息batch的起始seq number及结束seq number等。这样每当该PID发送新的消息batch时,Kafka broker就会对比这些信息,如果发生冲突(比如起始seq number和结束seq number与当前缓存的相同),那么broker就会拒绝这次写入请求。倘若没有冲突,那么broker端就会更新这部分缓存然后再开始写入消息。这就是Kafka实现幂等producer的设计思路:1. 为每个producer设置唯一的PID;2. 引入seq number以及broker端seq number缓存更新机制来去重。
介绍了设计思想,我们来看下具体的实现,如下图所示:
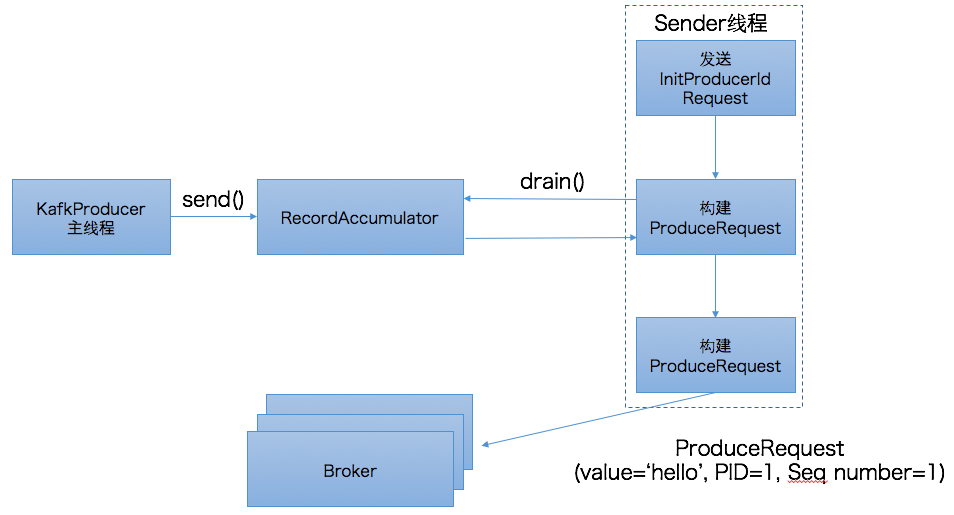
以前的博客中提到过,Java producer(区别于Scala producer)是双线程的设计,分为KafkaProducer用户主线程和Sender线程。前者调用send方法将消息写入到producer的内存缓冲区中,即RecordAccumulator中,而后者会定期地从RecordAccumulator中获取消息并将消息归入不同的batch中发送到对应的broker上。在幂等producer中,用户主线程的逻辑变动不大。send方法依然是将消息写入到RecordAccumulator。而Sender线程却有着很大的改动。我们首先来看下上图中的第一步:发送InitProducerIdRequest请求。
InitProducerIdRequest是0.11.0.0版本新引入的请求类型,它由两个字段组成:transactionalId和timeout,其中transactionalId就是producer端参数transactional.Id的值,timeout则是事务的超时时间。由于我们未引入事务而只是配置幂等producer,故transcationalId为null,而timeout则设置成了Int.MAX,即Sender线程将一直阻塞直到broker端发送PID返回。一旦接收到broker端返回的response,Sender线程就会更新该producer的PID字段。有兴趣的读者可以参考源码:Sender.maybeWaitForProducerId,如下图所示:
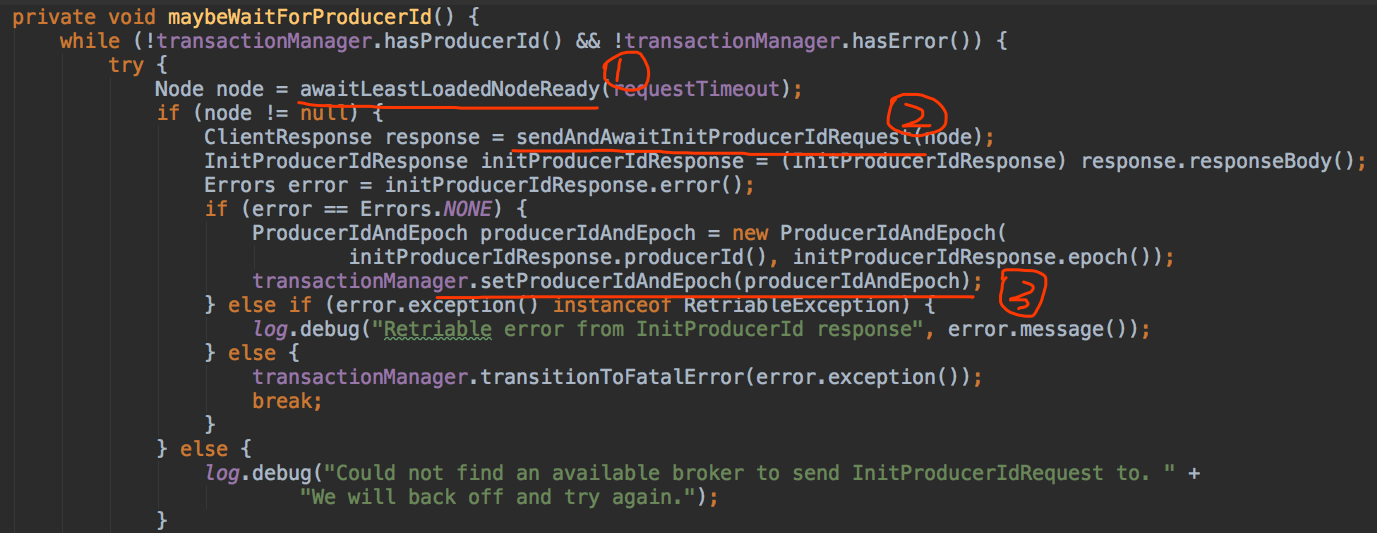
(下面我就不贴源码了,但会给出对应的源码文件,有兴趣的直接看吧~~)
上图中, 第一步是随机寻找一个负载最低的broker,即当前未完成请求数最少的broker。由此可见,InitProducerIdRequest和MetadataRequest一样,都可由任意的broker完成处理。至于为什么我们稍后讨论,现在先来讨论下broker端是如何确定PID的。其实说起来很简单,Kafka在Zookeeper中新引入了一个节点:/latest_producer_id_block,broker启动时提前预分配一段PID,当前是0~999,即提前分配出1000个PID来,如下图所示:
[zk: localhost:2181(CONNECTED) 2] get /latest_producer_id_block
{"version":1,"broker":0,"block_start":"0","block_end":"999"}
一旦PID超过了999,则目前会按照1000的步长重新分配,到时候就应该是这个样子:
{"version":1, "broker":0,"block_start":"1000","block_end":"1999"}
除了上面的信息,broker在内存中还保存了下一个待分配的PID。这样,当broker端接收到InitProducerIdRequest请求后,它会比较下一个PID是否在当前预分配的PID范围:若是则直接返回;否则再次预分配下一批的PID。现在我们来讨论下为什么这个请求所有broker都能响应——原因就在于集群中所有broker启动时都会启动一个叫TransactionCoordinator的组件,该组件能够执行预分配PID块和分配PID的工作,而所有broker都使用/latest_producer_id_block节点来保存PID块,因此任意一个broker都能响应这个请求。
上图中的第二步就是发送InitProducerIdRequest的方法,注意当前是同步等待返回结果,即Sender线程会无限阻塞直到broker端返回response(当然依然会受制于request.timeout.ms参数的影响)。当拿到response后,Sender线程就会更新该producer的PID字段,如图中第三步所示。
确定了PID之后,Sender线程会调用RecordAccumulator.drain()提取当前可发送的消息,在该方法中会将PID,Seq number等信息封装进消息batch中,具体代码参见:RecordAccumulator.java#drain()。一旦获取到消息batch后,Sender线程开始构建ProduceRequest请求然后发送给broker端。至此producer端的工作就算告一段落了。
下面我们看下broker端是如何响应PRODUCE请求。实际上,broker最重要的事情就是要区别某个PID的同一个消息batch是否重复发送了。因此在消息被写入到leader底层日志之前必须要先做一次判断,即PRODUCE请求中的消息batch是否已然被处理过,判断的逻辑就在:ProducerStateManager.scala中的ProducerAppendInfo#validateAppend方法中。如果请求中包含的消息batch与最近一次成功写入的batch相同(即PID相同,batch起始seq number和batch结束seq number都相同),那么该方法便抛出DuplicateSequenceNumberException,然后由上层方法捕获到该异常封装进ProduceResponse返回。如果batch不相同,则允许此次写入,并在写入完成后更新这些producer信息。
值得一提的是在0.11.0.0版本中DuplicateSequenceNumberException继承自RetriableException类,即表示Kafka认为它是一个可重试的异常。这其实是个问题,因为抛出该异常已经表明broker不需要处理这次写入,即使重试broker依然会拒绝,因此在1.0.0版本中该类已经不再继承自RetriableException,顺便还改了个名字:DuplicateSequenceException。
以上就是关于幂等producer的一些讨论。从上面的分析中我们可以看到幂等producer的设计思想主要是基于用空间保存状态并利用状态来去重的思想。了解了这一点,你会发现幂等producer的设计以及代码改动实际上非常容易理解。
最后再说一点:以上所说的幂等producer一直强调的是“精确处理一次”的语义,实际上幂等producer还有“不乱序”的强语义保证,只不过在0.11版本中这种不乱序主要是通过设置enable.idempotence=true时强行将max.in.flight.requests.per.connection设置成1来实现的。这种实现虽然保证了消息不乱序,但也在某种程度上降低了producer的TPS。据我所知,这个问题将在1.0.0版本中已然得到解决。在后续的Kafka 1.0.0版本中即使启用了幂等producer也能维持max.in.flight.requests.per.connection > 1,具体的算法我还没有看,不过总之是个好消息。至于表现如何就让我们拭目以待吧~~
关于Kafka幂等producer的讨论的更多相关文章
- Kafka设计解析(二十一)关于Kafka幂等producer的讨论
转载自 huxihx,原文链接 关于Kafka幂等producer的讨论 众所周知,Kafka 0.11.0.0版本正式支持精确一次处理语义(exactly once semantics,下称EOS) ...
- Kafka 幂等生产者和事务生产者特性(讨论基于 kafka-python | confluent-kafka 客户端)
Kafka 提供了一个消息交付可靠性保障以及精确处理一次语义的实现.通常来说消息队列都提供多种消息语义保证 最多一次 (at most once): 消息可能会丢失,但绝不会被重复发送. 至少一次 ( ...
- kafka 幂等生产者及事务(kafka0.11之后版本新特性)
1. 幂等性设计1.1 引入目的生产者重复生产消息.生产者进行retry会产生重试时,会重复产生消息.有了幂等性之后,在进行retry重试时,只会生成一个消息. 1.2 幂等性实现1.2.1 PID ...
- apache kafka系列之Producer处理逻辑
最近研究producer的负载均衡策略,,,,我在librdkafka里边用代码实现了partition 值的轮询方法,,,但是在现场验证时,他的负载均衡不起作用,,,所以来找找原因: 下文是一篇描 ...
- Kafka 0.8 Producer处理逻辑
Kafka Producer产生数据发送给Kafka Server,具体的分发逻辑及负载均衡逻辑,全部由producer维护. 1.Kafka Producer默认调用逻辑 1.1 默认Partiti ...
- Kafka 0.8 Producer (0.9以前版本适用)
Kafka旧版本producer由scala编写,0.9以后已经废除,但是很多公司还在使用0.9以前的版本,所以总结如下: 要注意包Producer是 kafka.javaapi.producer.P ...
- 关于Kafka区分请求处理优先级的讨论
所有的讨论都是基于KIP-291展开的.抱歉,这又是一篇没有图的文字. 目前Kafka broker对所有发过来的请求都是一视同仁的,不会区别对待.不管是用于生产消费的PRODUCE和FETCH请求, ...
- Kafka 之 async producer (2) kafka.producer.async.DefaultEventHandler
上次留下来的问题 如果消息是发给很多不同的topic的, async producer如何在按batch发送的同时区分topic的 它是如何用key来做partition的? 是如何实现对消息成批量的 ...
- Kafka 之 async producer (1)
问题 很多条消息是怎么打包在一起的? 如果消息是发给很多不同的topic的, async producer如何在按batch发送的同时区分topic的 它是如何用key来做partition的? 是如 ...
随机推荐
- 小米3移动版 分区 调整/合并教程(16GB/64GB)
(必读)版权声明:米3移动版TWRP Recovery为XueferH适配,分区脚本以及双数据置换脚本的知识产权,智力成果权归XueferH所有. 注:此教程仅适用于Xiaomi MI 3-移动版(1 ...
- String直接赋值和使用new的区别
String str1 = "ABC"; String str2 = new String("ABC"); String str1 = “ABC”;可能创建一个 ...
- SAP 产品条码WMS结合 以及ABAP script的集成 BarCode
条码和RFID打印解决方案 1, 热转印条码标签打印 热转打印技术的原理是通过加温和加压将色带上的固体油墨熔化转印到介质上完成打印的.通过选择热转印色带与标签材料匹配,热转印打印方式可以产生耐高温 ...
- SQL Server 连接远程服务器
最近要用到sqlserver,将本地的数据更新到远端的sqlserver时,希望能够查看远端sqlserver数据变化. 下载Microsoft SQL Server Management Studi ...
- Linux下硬链接与软链接
linux下的链接文件,尤其是软链接使用非常的频繁: 链分为硬链接(hard link)与软链接(symbolic link) 两种:关键在于inode: 硬链接: 当系统需要读取一个文件时,就会去读 ...
- 第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装
第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装 当前环境python3.5 ,windows10系统 Linux系统安装 在线安装,会自动安装scrapy模块以及相关依赖模块 pip ...
- Ubuntu 14.04 安装 DevStack与遇到的的问题记录
本文总结Ubuntu 14.04下部署DevStack的过程以及一些可能遇到的问题. 一.安装 以下的操作最好在普通用户下进行,至少在git clone devstack的时候使用普通用户,这样可以避 ...
- Java条形码插件
项目中需要用条形码插件,基于Java平台的 需要比较简单,根据一个12位的数字生成一个条形码图片即可 之前一直用Google的Zxing,因为功能强大,调用简单,网上也有很多资料 后来发现,Zxing ...
- java 项目 存入mysql后 变问号 MySql 5.6 (X64) 解压版 1067错误与编码问题的解决方案
[参考]MySQL 5.7.19 忘记密码 重置密码 my.ini示例 服务启动后停止 环境 Java环境JDK1.8 安装好了 mysql-5.6.38-winx64 idea2016(64) ...
- node,npm的安装
1. 在node的官网下载 2.安装node 3. 4.进入项目根目录,安装依赖:```npm install 如:npm install -g cnpm --registry=https://reg ...