Spark部署
Spark的部署让人有点儿困惑,有些需要注意的事项,本来我已经装成功了YARN模式的,但是发现了一些问题,出现错误看日志信息,完全看不懂那个错误信息,所以才打算翻译Standalone的部署的文章。第一部分,我先说一下YARN模式的部署方法。第二部分才是Standalone的方式。
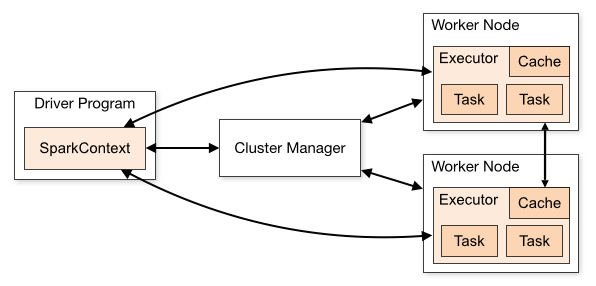
我们首先看一下Spark的结构图,和hadoop的差不多。
1、YARN模式
采用yarn模式的话,其实就是把spark作为一个客户端提交作业给YARN,实际运行程序的是YARN,就不需要部署多个节点,部署一个节点就可以了。
把从官网下载的压缩包在linux下解压之后,进入它的根目录,没有安装git的,先执行yum install git安装git
1)运行这个命令: SPARK_HADOOP_VERSION=2.2.0 SPARK_YARN=true ./sbt/sbt assembly
就等着吧,它会下载很多jar包啥的,这个过程可能会卡死,卡死的就退出之后,重新执行上面的命令。
2)编辑conf目录下的spark-env.sh(原来的是.template结尾的,删掉.template),添加上HADOOP_CONF_DIR参数
HADOOP_CONF_DIR=/etc/hadoop/conf
3)运行一下demo看看,能出结果 Pi is roughly 3.13794
SPARK_JAR=./assembly/target/scala-/spark-assembly_2.9.3-0.8.1-incubating-hadoop2.2.0.jar \
./spark-class org.apache.spark.deploy.yarn.Client \
--jar examples/target/scala-/spark-examples-assembly--incubating.jar \
--class org.apache.spark.examples.SparkPi \
--args yarn-standalone \
--num-workers \
--master-memory 1g \
--worker-memory 1g \
--worker-cores
2、Standalone模式
下面我们就讲一下怎么部署Standalone,参考页面是http://spark.incubator.apache.org/docs/latest/spark-standalone.html。
这里我们要一个干净的环境,刚解压出来的,运行之前的命令的时候不能再用了,会报错的。
1)打开make-distribution.sh,修改SPARK_HADOOP_VERSION=2.2.0,然后执行./make-distribution.sh, 然后会生成一个dist目录,这个目录就是我们要部署的内容。官方推荐是先把master跑起来,再部署别的节点,大家看看bin目录下面的脚本,和hadoop的差不多的,按照官方文档的推荐的安装方式有点儿麻烦。下面我们先说简单的方法,再说官方的方式。
我们打开dist目录下conf目录的,如果没有slaves文件,添加一个,按照hadoop的那种配置方式,把slave的主机名写进去,然后把dist目录部署到各台机器上,回到master上面,进入第三题、目录的sbin目录下,有个start-all.sh,执行它就可以了。
下面是官方文档推荐的方式,先启动master,执行。
./bin/start-master.sh
2)部署dist的目录到各个节点,然后通过这个命令来连接master节点
./spark-class org.apache.spark.deploy.worker.Worker spark://IP:PORT
3)然后在主节点查看一下http://localhost:8080 ,查看一下子节点是否在这里,如果在,就说明连接成功了。
4) 部署成功之后,想要在上面部署程序的话,在执行./spark-shell的时候,要加上MASTER这个参数。
MASTER=spark://IP:PORT ./spark-shell
3、High Availability
Spark采用Standalone模式的话,Spark本身是一个master/slaves的模式,这样就会存在单点问题,Spark采用的是zookeeper作为它的active-standby切换的工具,设置也很简单。一个完整的切换需要1-2分钟的时间,这个时候新提交的作业会受到影响,之前提交到作业不会受到影响。
在spark-env.sh添加以下设置:
//设置下面三项JVM参数,具体的设置方式在下面//spark.deploy.recoveryMode=ZOOKEEPER//spark.deploy.zookeeper.url=192.168.1.100:2181,192.168.1.101:2181// /spark是默认的,可以不写//spark.deploy.zookeeper.dir=/spark export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop.Master:2181,hadoop.SlaveT1:2181,hadoop.SlaveT2:2181"
这里就有一个问题了,集群里面有多个master,我们连接的时候,连接谁?用过hbase的都知道是先连接的zookeeper,但是Spark采用的是另外的一种方式,如果我们有多个master的话,实例化SparkContext的话,使用spark://host1:port1,host2:port2这样的地址,这样它会同时注册两个,一个失效了,还有另外一个。
如果不愿意配置高可用的话,只是想失败的时候,再恢复一下,重新启动的话,那就使用FILESYSTEM的使用,指定一个目录,把当前的各个节点的状态写入到文件系统。
spark.deploy.recoveryMode=FILESYSTEMspark.deploy.recoveryDirectory=/usr/lib/spark/dataDir
当 stop-master.sh来杀掉master之后,状态没有及时更新,再次启动的时候,会增加一分钟的启动时间来等待原来的连接超时。
recoveryDirectory最好是能够使用一个nfs,这样一个master失败之后,就可以启动另外一个master了。
Spark部署的更多相关文章
- Spark部署三种方式介绍:YARN模式、Standalone模式、HA模式
参考自:Spark部署三种方式介绍:YARN模式.Standalone模式.HA模式http://www.aboutyun.com/forum.php?mod=viewthread&tid=7 ...
- 基于Docker搭建大数据集群(四)Spark部署
主要内容 spark部署 前提 zookeeper正常使用 JAVA_HOME环境变量 HADOOP_HOME环境变量 安装包 微云下载 | tar包目录下 Spark2.4.4 一.环境准备 上传到 ...
- 大数据系列之并行计算引擎Spark部署及应用
相关博文: 大数据系列之并行计算引擎Spark介绍 之前介绍过关于Spark的程序运行模式有三种: 1.Local模式: 2.standalone(独立模式) 3.Yarn/mesos模式 本文将介绍 ...
- Spark部署及应用
在飞速发展的云计算大数据时代,Spark是继Hadoop之后,成为替代Hadoop的下一代云计算大数据核心技术,目前Spark已经构建了自己的整个大数据处理生态系统,如流处理.图技术.机器学习.NoS ...
- 再谈spark部署搭建和企业级项目接轨的入门经验(博主推荐)
进入我这篇博客的博友们,相信你们具备有一定的spark学习基础和实践了. 先给大家来梳理下.spark的运行模式和常用的standalone.yarn部署.这里不多赘述,自行点击去扩展. 1.Spar ...
- Spark 部署即提交模式意义解析
Spark 的官方从 Cluster Mode Overview 中,官方向我们介绍了 cluster 模式的部署方式. Spark 作为独立进程在集群上运行,他们通过 SparkContext 进行 ...
- 入门大数据---Spark部署模式与作业提交
一.作业提交 1.1 spark-submit Spark 所有模式均使用 spark-submit 命令提交作业,其格式如下: ./bin/spark-submit \ --class <ma ...
- spark 部署问题
spark的web UI 端口设置:spark-env.sh 中设置SPARK_MASTER_WEBUI_PORT 为自己想设置的端口号. 其他worker 的web UI 端口默认:8081 mas ...
- [Spark] - Spark部署安装
环境:centos6.0 虚拟机 搭建单机版本的spark 前提条件:搭建好hadoop环境 1. 下载scala进行安装 只需要设置环境变量SCALA_HOME和PATH即可 export SCAL ...
随机推荐
- [转]greenplum(postgresql)之数据字典
greenplum是基于postgresql开发的分布式数据库,里面大部分的数据字典是一样的.我们在维护gp的时候对gp的数据字典比较熟悉,特此分享给大家.在这里不会详细介绍每个字典的内容,只会介绍常 ...
- 安装 Vbundle 的笔记
Vbundle 挺好用的,能够很方便管理Vim的一些插件.虽然Vbundle的安装方法看的很简单,但是它的配置却让我弄了很久,现在记录如下,方便后面安装时再出现相同的问题: 我按照这里的官方提示的安装 ...
- 电子证据 利用Kali进行wifi钓鱼实战详细教程
电子证据 利用Kali进行wifi钓鱼实战详细教程 一. Kali系统安装和必要软件安装: 1.Kali最新版可以来我这儿拿外置驱动和光盘装,目测用U盘装最新版有些问题,比较麻烦. 2.Kali更新源 ...
- MySql(五):MySQL数据库安全管理
一.前言 对于任何一个企业来说,其数据库系统中所保存数据的安全性无疑是非常重要的,尤其是公司的有些商业数据,可能数据就是公司的根本. 失去了数据,可能就失去了一切 本章将针对mysql的安全相关内容进 ...
- 对于android浏览器的一些看法
首先我先声明我不是一个浏览器开发者,只是近段时间看了一些关于浏览器的东西,才有一些看法. 在几年前开发手机的web 页面,都经常因为JS插件不兼容android WebView内核,导致开发浪费大量时 ...
- PHP use关键字概述
PHP中的use关键字的用法. 很多开源系统如osCommerce框架中,都会在其源码中找到use这个关键字,如osCommerce框架中就在index.php文件中出现了这段源码:use osCom ...
- Mac OSX 快捷键&命令行
一.Mac OSX 快捷键 ctrl+shift 快速放大dock的图标会暂时放大,而如果你开启了dock放大Command+Op ...
- Gartner 2018新技术成熟度曲线
https://blog.csdn.net/BtB5e6Nsu1g511Eg5XEg/article/details/82047719 近日,Gartner发布了2018年新技术成熟度曲线,首次将生物 ...
- ASP.NET Core2.0 环境下MVC模式的支付宝PC网站支付接口-沙箱环境开发测试
1.新建.NET Core web项目 2.Controllers-Models-Views 分三个大部分 3.下载安装最新sdk 官方的SDK以及Demo都还是.NET Framework的,根据官 ...
- 每日英语:Marriage makes our children richer — Here's why
Young people from less-privileged homes are more likely to graduate from college and earn more if ra ...