ML(5):KNN算法
K近邻算法,即K-Nearest Neighbor algorithm,简称KNN算法,可以简单的理解为由那离自己最近的K个点来投票决定待分类数据归为哪一类。这个算法是机器学习里面一个比较经典的算法, 总体来说KNN算法是相对比较容易理解的算法。其中的K表示最接近自己的K个数据样本。KNN算法和K-Means算法不同的是,K-Means算法用来聚类,用来判断哪些东西是一个比较相近的类型,而KNN算法是用来做归类的,也就是说,有一个样本空间里的样本分成几个类型,然后,给定一个待分类的数据,通过计算接近自己最近的K个样本来判断这个待分类数据属于哪个分类。
目录:
- 算法概述
- 工作原理
- K值的选择
- 归一化处理
- knn R示例
- 推测车型代码
算法概述

- 如上图所示,有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的圆所标示的数据则是待分类的数据。也就是说,现在,我们不知道中间那个绿色的数据是从属于哪一类(蓝色小正方形or红色小三角形),我们就要解决这个问题:给这个绿色的圆分类
从上图中,你还能看到:如果K=3,绿色圆点的最近的3个邻居是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
- 如果K=5,绿色圆点的最近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类
- 于此我们看到,当无法判定当前待分类点是从属于已知分类中的哪一类时,我们可以依据统计学的理论看它所处的位置特征,衡量它周围邻居的权重,而把它归为(或分配)到权重更大的那一类。这就是K近邻算法的核心思想
工作原理
- 我们知道样本集中每一个数据与所属分类的对应关系,输入没有标签的新数据后,将新数据与训练集的数据对应特征进行比较,找出“距离”最近的k数据,选择这k个数据中出现最多的分类作为新数据的分类。
- 算法描述
- 计算已知数据集中的点与当前点的距离
- 按距离递增次序排序
- 选取与当前数据点距离最近的K个点
- 确定前K个点所在类别出现的频率
- 返回频率最高的类别作为当前类别的预测
- 距离计算方法有"euclidean"(欧氏距离),”minkowski”(明科夫斯基距离), "maximum"(切比雪夫距离), "manhattan"(绝对值距离),"canberra"(兰式距离), 或 "minkowski"(马氏距离)等
- knn算法中判断两条记录的相似度的采用的是欧式距离
- 算法缺点:
- k值需要预先设定,而不能自适应
- 样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数
K值的选择
- 除了如何定义邻居的问题之外,还有一个选择多少个邻居,即K值定义为多大的问题。不要小看了这个K值选择问题,因为它对K近邻算法的结果会产生重大影响。
- 如果选择较小的K值,就相当于用较小的领域中的训练实例进行预测,“学习”近似误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是“学习”的估计误差会增大,换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
- 如果选择较大的K值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误,且K值的增大就意味着整体的模型变得简单。
- 在实际应用中,K值一般取一个比较小的数值,例如采用交叉验证法(简单来说,就是一部分样本做训练集,一部分做测试集)来选择最优的K值。
- 一般来说,k的取值最好是数据集的条数开方,并且最好取奇数,下面示例中iris是150条数据,所以这里k值选13。
归一化处理
- 数据标准化(归一化)处理是数据挖掘的一项基础工作,不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。以下是两种常用的归一化方法:
- min-max标准化(Min-Max Normalization):也称为离差标准化,是对原始数据的线性变换,使结果值映射到[0 - 1]之间。转换函数如下:

- 其中max为样本数据的最大值,min为样本数据的最小值。这种方法有个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
- Z-score标准化方法: 这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,转化函数为:

- 其中
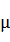 为所有样本数据的均值,
为所有样本数据的均值,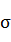 为所有样本数据的标准差。
为所有样本数据的标准差。
R示例
- R实现时,可选择class包,也可选择kknn包进行计算
- 以iris为例示例代码如下:
#---------------------R:KNN算法--------------------------------
head(iris)
a<-iris[-5] #将标记种类的列去掉
head(a)
a<-scale(a) #z-score标准化
str(a)
head(a) train<-a[c(1:25,50:75,100:125),] #训练集
head(train)
test<-a[c(26:49,76:99,126:150),] #测试集 #接下来需要把训练集和测试集的种类标记保存下来
train_lab <-iris[c(1:25,50:75,100:125),5]
test_lab <-iris[c(26:49,76:99,126:150),5] #KNN分类例子中在R中使用到的包有“class包”,“gmodels包”
#install.packages("class")
library(class)
#接下来就可以调用knn函数进行模型的建立了
## 数据框,K个近邻投票,欧氏距离
pre_result<-knn(train=train,test=test,cl=train_lab,k=13)
table(pre_result,test_lab) #---------------------R:KKNN 包-------------------------------- #install.packages("kknn")
library(kknn)
data("iris")
dim(iris)
m <-(dim(iris))[1]
ind <- sample(2, m, replace=TRUE, prob=c(0.7, 0.3))
iris.train <- iris[ind==1,]
iris.test <- iris[ind==2,] #调用kknn 之前首先定义公式
#myformula :Species ~ Sepal.Length + Sepal.Width + Petal.Length + Petal.Width
iris.kknn<-kknn(Species~.,iris.train,iris.test,distance=1,kernel="triangular")
summary(iris.kknn) # 获取fitted.values
fit <- fitted(iris.kknn) # 建立表格检验判类准确性
table(fit,iris.test$Species) # 绘画散点图,k-nearest neighbor用红色高亮显示
pcol <- as.character(as.numeric(iris.test$Species)) pairs(iris.test[1:4], pch = pcol, col = c("green3", "red")[(iris.test$Species != fit)+1])
推测车型代码
- 完整代码如下:
setwd("E:\\RML")
cars <- read.csv("bus01.csv",header=TRUE,stringsAsFactors=TRUE) #
library(kknn)
m <-(dim(cars))[1]
ind <- sample(2, m, replace=TRUE, prob=c(0.7, 0.3))
car.train <- cars[ind==1,]
car.test <- cars[ind==2,] #调用kknn 之前首先定义公式
myformula <- Type ~ V + A + SOC + MinV + MaxV + MaxT + MinT
car.kknn<-kknn(myformula,car.train,car.test,distance=1,kernel="triangular") # 获取car.values
fit <- fitted(car.kknn) # 建立表格检验判类准确性
table(fit,car.test$Type,dnn = c("predict","actual")) # 绘画散点图,k-nearest neighbor用红色高亮显示
pcol <- as.character(as.numeric(car.test$Type))
pairs(car.test[-8], pch = pcol, col = c("green3", "red")[(car.test$Type != fit)+1])
- 结果如下:

- 图形分布

ML(5):KNN算法的更多相关文章
- ML一:python的KNN算法
(1):list的排序算法: 参考链接:http://blog.csdn.net/horin153/article/details/7076321 示例: DisListSorted = sorted ...
- 学习OpenCV——KNN算法
转自:http://blog.csdn.net/lyflower/article/details/1728642 文本分类中KNN算法,该方法的思路非常简单直观:如果一个样本在特征空间中的k个最相似( ...
- OpenCV实现KNN算法
原文 OpenCV实现KNN算法 K Nearest Neighbors 这个算法首先贮藏所有的训练样本,然后通过分析(包括选举,计算加权和等方式)一个新样本周围K个最近邻以给出该样本的相应值.这种方 ...
- KNN算法简单应用
这里是写给小白看的,大牛路过勿喷. 1 KNN算法简介 KNN(K-Nearest Neighbor)工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集 ...
- JavaScript机器学习之KNN算法
译者按: 机器学习原来很简单啊,不妨动手试试! 原文: Machine Learning with JavaScript : Part 2 译者: Fundebug 为了保证可读性,本文采用意译而非直 ...
- [Python]基于K-Nearest Neighbors[K-NN]算法的鸢尾花分类问题解决方案
看了原理,总觉得需要用具体问题实现一下机器学习算法的模型,才算学习深刻.而写此博文的目的是,网上关于K-NN解决此问题的博文很多,但大都是调用Python高级库实现,尤其不利于初级学习者本人对模型的理 ...
- py4CV例子1猫狗大战和Knn算法
1.什么是猫狗大战: 数据集来源于Kaggle(一个为开发商和数据科学家提供举办机器学习竞赛.托管数据库.编写和分享代码的平台),原数据集有12500只猫和12500只狗,分为训练.测试两个部分. 2 ...
- KNN算法的R语言实现
近邻分类 简言之,就是将未标记的案例归类为与它们最近相似的.带有标记的案例所在的类. 应用领域: 1.计算机视觉:包含字符和面部识别等 2.推荐系统:推荐受众喜欢电影.美食和娱乐等 3.基因工程:识别 ...
- 【StatLearn】统计学习中knn算法的实验(1)
Problem: Develop a k-NN classifier with Euclidean distance and simple voting Perform 5-fold cross va ...
随机推荐
- 文件属性,获取,设置文件属性chown stat函数
转载:http://c.biancheng.net/cpp/html/326.html man 2 stat查看手册 int stat(const char *path, struct stat *b ...
- 遍历HashMap的方法(四)
Map map = new HashMap(); for (Iterator iter = map.entrySet().iterator(); iter.hasNext();) { Map.Entr ...
- Xshell5 Xftp安装图解
1Xshell5 Xftp_5安装图解 2.1Xshell5安装 2.2Xftp安装
- window8服务器
安装PHP集成环境:XAMPP cmd下查看端口号: 如果直接输入netstat -nao 报不是内部指令的处理方法: c:\WINDOWS\system32\netstat -nao 就可以了. w ...
- cas AuthenticationFilter
AuthenticationFilter *** 这个类的作用:判断是否已经登录,如果没有登录则根据配置的信息来决定将跳转到什么地方 *** casServerLoginUrl:定义cas 服务器的登 ...
- 关于Arch Linux efibootmgr 命令行参数问题
相关链接: https://wiki.archlinux.org/index.php/EFISTUB 今天安装Arch Linux 在 efibootmgr创建启动项时,总是提示 UUID=xxxx ...
- Linux内核分析-使用gdb跟踪调试内核从start_kernel到init进程启动
姓名:江军 ID:fuchen1994 实验日期:2016.3.13 实验指导 使用实验楼的虚拟机打开shell cd LinuxKernel/ qemu -kernel linux-3.18.6/a ...
- 关于 lerp();
value lerp(value s, value a, value b ); 该函数返回的值为:a + s * (b - a) ,是一个处于 [a, b] 之间的值. 当s=0, 该函数返回a :当 ...
- Quartz表结构说明
一.表信息解析: 1.1. qrtz_blob_triggers : 以Blob 类型存储的触发器. 1.2. qrtz_calendars:存放日历信息, quartz可配置一个日历来指定一个时间范 ...
- Swift网络封装库Moya中文手册之RxSwift
RxSwift Maya提供了一个可选的MoyaProvider 子类 - RxMoyaProvider.在网络请求完成时,我们不再使用 request() 函数的回调闭包,而是使用 Observab ...