HDFS文件系统的JAVA-API操作(一)
使用java.net.URL访问HDFS文件系统
HDFS的API使用说明:
1.如果要访问HDFS,HDFS客户端必须有一份HDFS的配置文件
也就是hdfs-site.xml,从而读取Namenode的信息。
2.每个应用程序也必须拥有访问Hadoop程序的jar文件
3.操作HDFS,也就是HDFS的读和写,最常用的类FileSystem
实例1:使用java.net.URL访问HDFS文件系统
/**
* 操作:显示HDFS文件夹中的文件内容
* 1.使用java.net.URL对象打开数据流
* 2.使用静态代码块使得java程序识别Hadoop的HDFS url
*/
操作代码如下:
package TestHdfs;
import java.io.InputStream;
import java.net.URL;
import org.apache.hadoop.fs.FsUrlStreamHandlerFactory;
import org.apache.hadoop.io.IOUtils;
/**
* @author SimonsZhao
* HDFS的API使用
* 1.如果要访问HDFS,HDFS客户端必须有一份HDFS的配置文件
* 也就是hdfs-site.xml,从而读取Namenode的信息。
* 2.每个应用程序也必须拥有访问Hadoop程序的jar文件
* 3.操作HDFS,也就是HDFS的读和写,最常用的类FileSystem
* 操作:显示HDFS文件夹中的文件内容
* 1.使用java.net.URL对象打开数据流
* 2.使用静态代码块使得java程序识别Hadoop的HDFS url
*/
public class MyCat {
static{
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
}
public static void main(String[] args) {
InputStream input=null;
try {
input = new URL(args[0]).openStream();
IOUtils.copyBytes(input,System.out,4096,false);
} catch (Exception e) {
System.err.println("Error");
}finally{
IOUtils.closeStream(input);
}
}
}
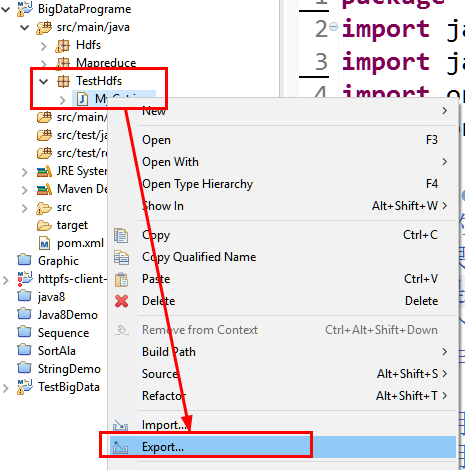
0.打包程序并长传到Linux中
a.通过export导出文件jar包
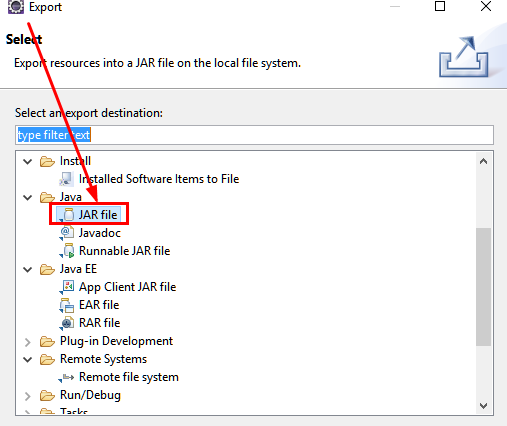
b.选择jar包存放路径
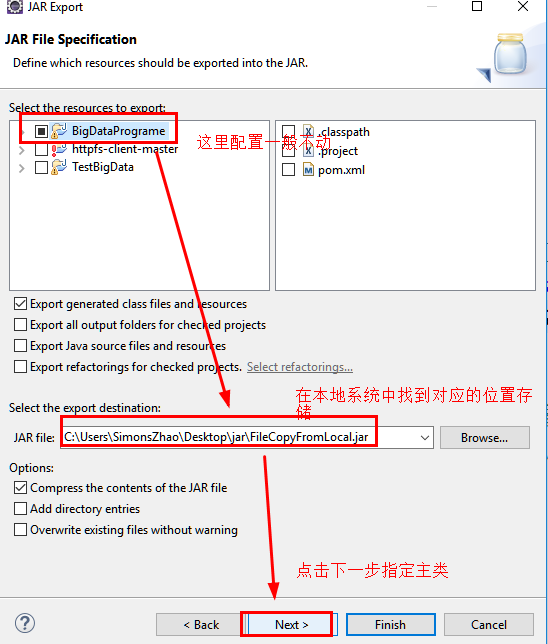
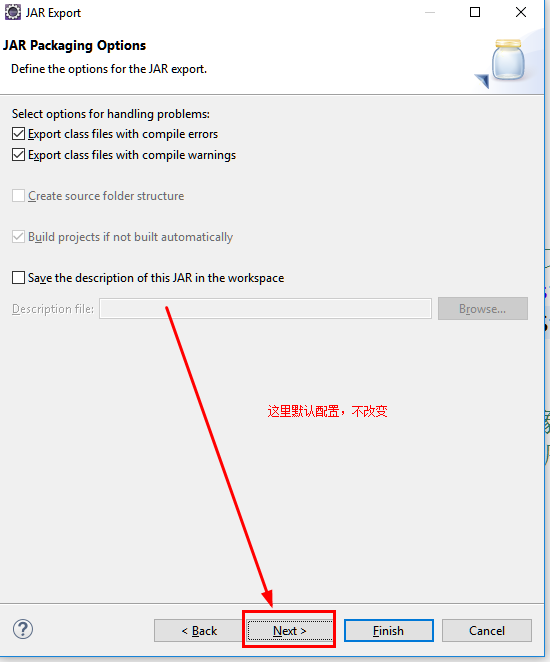
c.指定主类
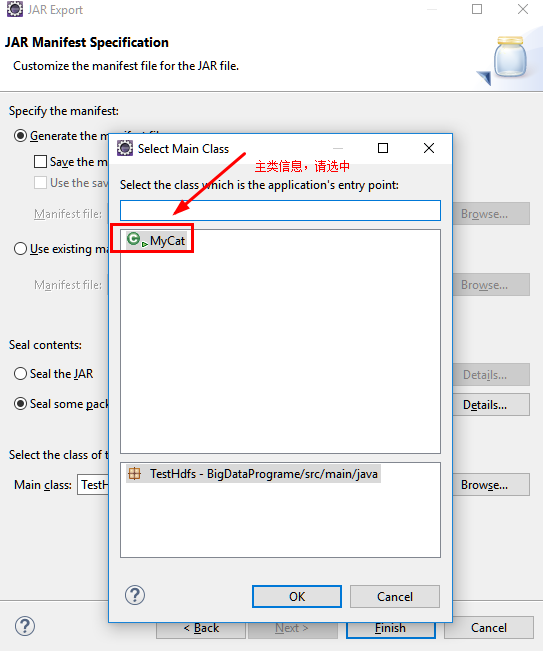
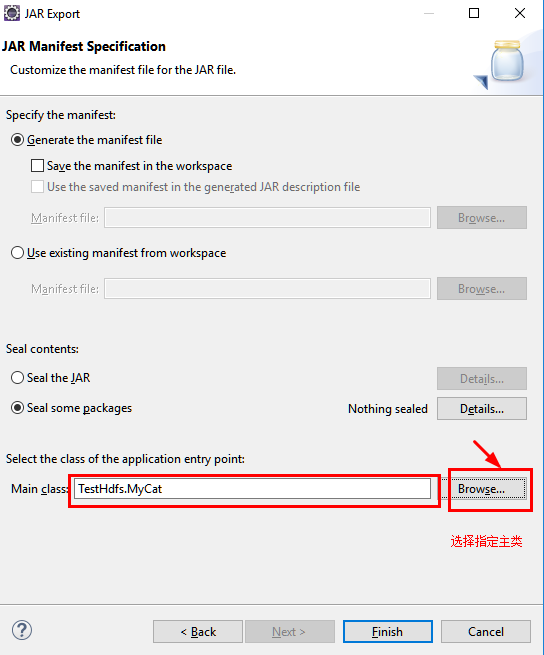
d.通过SecureCRT上传jar包至Linux中的指定文件夹下。

1.在指定文件夹下创建示例文件demo
[root@neusoft-master filecontent]# vi demo

2.上传文件至HDFS的data目录,data目录需要首先创建。
[root@neusoft-master filecontent]# hadoop dfs -put demo /data/

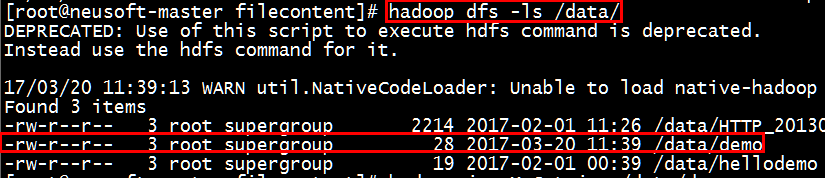
3.查看是否上传成功
[root@neusoft-master filecontent]# hadoop dfs -ls /data/
4.将已经打包好的jar文件上传至linux并切换到相应文件夹运行hadoop命令执行
从结果可以看出能够显示出来demo文件的内容
[root@neusoft-master filecontent]# hadoop jar MyCat.jar hdfs://neusoft-master:9000/data/demo

实例2:使用FileSystem访问HDFS文件系统
/**
*操作:将本地文件系统的文件通过java-API写入到HDFS文件
*/
1.本地文件系统和HDFS中应该首先创建指定的目录
linux中创建文件命令:mkdir test
HDFS中创建文件夹命令:hadoop dfs -mkdir /data/
String source="/usr/local/filecontent/demo";//linux中的文件路徑,demo存在一定数据,这里存储了一行英语句子,如welcome to.....
String destination="hdfs://neusoft-master:9000/data/test";//HDFS的路徑
2.程序源代码
package TestHdfs; import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils; /**
* @author SimonsZhao
*将本地文件系统的文件通过java-API写入到HDFS文件
*/
public class FileCopyFromLocal {
public static void main(String[] args) throws Exception {
String source="/usr/local/filecontent/demo";//linux中的文件路徑,demo存在一定数据
String destination="hdfs://neusoft-master:9000/data/test";//HDFS的路徑
InputStream in = new BufferedInputStream(new FileInputStream(source));
//HDFS读写的配置文件
Configuration conf = new Configuration();
//调用Filesystem的create方法返回的是FSDataOutputStream对象
//该对象不允许在文件中定位,因为HDFS只允许一个已打开的文件顺序写入或追加
FileSystem fs = FileSystem.get(URI.create(destination),conf);
OutputStream out = fs.create(new Path(destination));
IOUtils.copyBytes(in, out, 4096, true);
}
}
3.程序打包并传至linux文件系统中
请参考实例1的打包过程
4.程序运行及结果分析
a.查看指定jar包是否成功上传,在linux中使用ls或ll命令
b.执行jar命令
[root@neusoft-master filecontent]# hadoop jar FileSystemDemoCat.jar

c.结果显示welcome to....说明操作正确
实例3:创建HDFS目录
* 创建HDFS目录
* 实例:HDFS创建test2目录
1.明确在HDFS文件系统中创建目录的具体地址,在程序中通过args[0]参数提供用户输入,如
hdfs://neusoft-master:9000/data/test2
2.程序源代码
package TestHdfs;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
/**
* @author SimonsZhao
* 创建HDFS目录
* 实例:HDFS创建test2目录
* hadoop jar CreateDir.jar hdfs://neusoft-master:9000/data/test2
*/
public class CreateDirction {
public static void main(String[] args) {
//HDFS路径:hdfs://neusoft-master:9000/data/test2
String uri=args[0];//从键盘输入路径参数
Configuration conf = new Configuration();
try {
FileSystem fs = FileSystem.get(new URI(uri),conf);
Path dfs = new Path(uri);
fs.mkdirs(dfs);
} catch (Exception e) {
e.printStackTrace();
}finally{
System.out.println("SUCESS");
}
}
}
3.将jar包上传到Linux
请参考第一个程序的导出jar包的过程。
4.程序运行及结果分析
[root@neusoft-master filecontent]# hadoop jar CreateDir.jar hdfs://neusoft-master:9000/data/test2

实例4:删除HDFS目录
package TestHdfs;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
/**
* @author SimonsZhao
* 删除HDFS上面的文件
*/
public class DeleteFile {
public static void main(String[] args) {
String uri="hdfs://neusoft-master:9000/data/test2";
Configuration conf = new Configuration();
try {
FileSystem fs =FileSystem.get(new URI(uri), conf);
Path f = new Path(uri);
//递归删除文件夹下所有文件
boolean isDelete= fs.delete(f, true);
//递归删除文件夹下所有文件
//boolean isDelete= fs.delete(f, false);
String str=isDelete?"Sucess":"Error";
System.out.println("删除"+str);
} catch (Exception e) {
System.out.println("删除出错~");
}
}
}
3.将jar包上传到Linux
请参考第一个程序的导出jar包的过程。
4.程序运行及结果分析
执行程序之后,通过hadoop dfs -ls / 查看是否成功删除HDFS上面的文件
实例5:查看文件或目录是否存在
package TestHdfs;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
/**
* @author SimonsZhao
* 查看文件是否存在
*/
public class CheckFileIsExists {
public static void main(String[] args) {
//String uri="hdfs://neusoft-master:9000/data/test2/";//指定目录
String uri="hdfs://neusoft-master:9000/data/test2/hello";//指定文件
Configuration conf = new Configuration();
try {
FileSystem fs = FileSystem.get(new URI(uri), conf);
Path path = new Path(uri);
boolean isExists=fs.exists(path);
String str=isExists?"Exists":"Not Exists";
System.out.println("指定文件或目录"+str);
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.将jar包上传到Linux
请参考第一个程序的导出jar包的过程。
4.程序运行及结果分析
如果在linux中存在该文件的话,则显示如下:
“指定文件或目录Exists”
实例6:列出目录下的文件或目录名称
package TestHdfs;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
/**
* @author SimonsZhao
* 列出目录下的文件或目录名称
*/
public class ListFiles {
public static void main(String[] args) {
String uri="hdfs://neusoft-master:9000/data";
Configuration conf = new Configuration();
try {
FileSystem fs=FileSystem.get(new URI(uri), conf);
Path path = new Path(uri);
FileStatus status[] = fs.listStatus(path);
for (int i = 0; i < status.length; i++) {
System.out.println(status[i].getPath().toString());
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.将jar包上传到Linux
请参考第一个程序的导出jar包的过程。
4.程序运行及结果分析

实例7:查看文件存储位置
package TestHdfs;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path; /**
* @author SimonsZhao
* 文件存储的位置
*/
public class LoactionFile {
public static void main(String[] args) {
String uri="hdfs://neusoft-master:9000/data/demo";//hello为文件
Configuration conf = new Configuration();
try {
FileSystem fs=FileSystem.get(new URI(uri), conf);
Path path = new Path(uri);
FileStatus fileStatus = fs.getFileStatus(path);
BlockLocation blkLocation[]=
fs.getFileBlockLocations
(fileStatus, 0, fileStatus.getLen());
for (int i = 0; i < blkLocation.length; i++) {
String[] hosts=blkLocation[i].getHosts();
System.out.println("block_"+i+"_Location:"+hosts[0]);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.将jar包上传到Linux
请参考第一个程序的导出jar包的过程。
4.程序运行及结果分析
由于采用伪分布的环境block块存储均为1,因此这里仅显示1个block块的host主机名
显示:block_0_Location:neusoft-master
实例8:将本地文件写入到HDFS中
package TestHdfs;
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils; /**
* @author SimonsZhao
*将本地文件系统的文件通过java-API写入到HDFS文件
*/
public class FileCopyFromLocal {
public static void main(String[] args) throws Exception {
String source="/usr/local/filecontent/demo";//linux中的文件路徑,demo存在一定数据
String destination="hdfs://neusoft-master:9000/data/test";//HDFS的路徑
InputStream in = new BufferedInputStream(new FileInputStream(source));
//HDFS读写的配置文件
Configuration conf = new Configuration();
//调用Filesystem的create方法返回的是FSDataOutputStream对象
//该对象不允许在文件中定位,因为HDFS只允许一个已打开的文件顺序写入或追加
FileSystem fs = FileSystem.get(URI.create(destination),conf);
OutputStream out = fs.create(new Path(destination));
IOUtils.copyBytes(in, out, 4096, true);
}
}
3.将jar包上传到Linux
请参考第一个程序的导出jar包的过程。
4.程序运行及结果分析
将本地的demo文件写入HDFS的data目录下的test文件
HDFS文件系统的JAVA-API操作(一)的更多相关文章
- HDFS 05 - HDFS 常用的 Java API 操作
目录 0 - 配置 Hadoop 环境(Windows系统) 1 - 导入 Maven 依赖 2 - 常用类介绍 3 - 常见 API 操作 3.1 获取文件系统(重要) 3.2 创建目录.写入文件 ...
- HDFS基础和java api操作
1. 概括 适合一次写入多次查询情况,不支持并发写情况 通过hadoop shell 上传的文件存放在DataNode的block中,通过linux shell只能看见block,看不见文件(HDFS ...
- 使用Java API操作HDFS文件系统
使用Junit封装HFDS import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org ...
- Hadoop之HDFS(三)HDFS的JAVA API操作
HDFS的JAVA API操作 HDFS 在生产应用中主要是客户端的开发,其核心步骤是从 HDFS 提供的 api中构造一个 HDFS 的访问客户端对象,然后通过该客户端对象操作(增删改查)HDFS ...
- 大数据(5) - HDFS中的常用API操作
一.安装java 二.IntelliJ IDEA(2018)安装和破解与初期配置 参考链接 1.进入官网下载IntelliJ IDEA https://www.jetbrains.com/idea/d ...
- hive-通过Java API操作
通过Java API操作hive,算是测试hive第三种对外接口 测试hive 服务启动 package org.admln.hive; import java.sql.SQLException; i ...
- hadoop2-HBase的Java API操作
Hbase提供了丰富的Java API,以及线程池操作,下面我用线程池来展示一下使用Java API操作Hbase. 项目结构如下: 我使用的Hbase的版本是 hbase-0.98.9-hadoop ...
- Kafka系列三 java API操作
使用java API操作kafka 1.pom.xml <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xs ...
- MongoDB Java API操作很全的整理
MongoDB 是一个基于分布式文件存储的数据库.由 C++ 语言编写,一般生产上建议以共享分片的形式来部署. 但是MongoDB官方也提供了其它语言的客户端操作API.如下图所示: 提供了C.C++ ...
- zookeeper的java api操作
zookeeper的java api操作 创建会话: Zookeeper(String connectString,int sessionTimeout,Watcher watcher) Zookee ...
随机推荐
- IOS私有API的使用(转)
最近在做企业级程序,需要搞设备的udid等信息,但是ios7把udid私有化了,不公开使用.所以研究了一下ios的私有api. 调查了一下文章,发现这方面的文章不多,国内更是不全,高手们都懒得写基 ...
- 1、一、Introduction(入门): 0、Introduction to Android(引进到Android)
一.Introduction(入门) 0.Introduction to Android(引进到Android) Android provides a rich application framewo ...
- C# 多线程 Parallel.ForEach 和 ForEach 效率问题研究及理解
from:https://blog.csdn.net/li315171406/article/details/78450534 最近要做一个大数据dataTable循环操作,开始发现 运用foreac ...
- MvvmLight学习篇—— Mvvm Light Toolkit for wpf/silverlight系列(导航)
系列一:看的迷迷糊糊的 一.Mvvm Light Toolkit for wpf/silverlight系列之准备工作 二.Mvvm Light Toolkit for wpf/silverlight ...
- python BeautifulSoup库用法总结
1. Beautiful Soup 简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.pyt ...
- 【Android】录音暂停和继续
https://www.2cto.com/kf/201410/347839.html http://blog.csdn.net/wanli_smile/article/details/7715030 ...
- 计算直线与WGS84椭球的交点
/************************************************************************/ /*线段与WGS84椭球求交 x^2/a^2+y^ ...
- thinkphp3.2 实现上一篇和下一篇
现在在做一个能够在内容页点击上一篇可以看到上一篇,点击下一篇可以看到下一篇. 首先http://www.mmkb.com/zhendao/index/news_show?code=98 现在code= ...
- 【laravel5.6】 laravel 接口 接管 自定义异常类
1 app\exceptions 目录下 新建 Apiexception.php <?php namespace App\Exceptions; /*** * API 自定义异常类 */ us ...
- java基础---->git的使用(一)
这里面记录一下git的使用,只是平时工作中遇到的一些问题的解决方案,不会涉及到git的一些基础概念及说明.人的天性便是这般凉薄,只要拿更好的来换,一定舍得. Git的一些使用 一.在码云建立好仓库之后 ...