Spark Streaming之六:Transformations 普通的转换操作
与RDD类似,DStream也提供了自己的一系列操作方法,这些操作可以分成四类:
- Transformations 普通的转换操作
- Window Operations 窗口转换操作
- Join Operations 合并操作
- Output Operations 输出操作
2.2.3.1 普通的转换操作
普通的转换操作如下表所示:
|
转换 |
描述 |
|
map(func) |
源 DStream的每个元素通过函数func返回一个新的DStream。 |
|
flatMap(func) |
类似与map操作,不同的是每个输入元素可以被映射出0或者更多的输出元素。 |
|
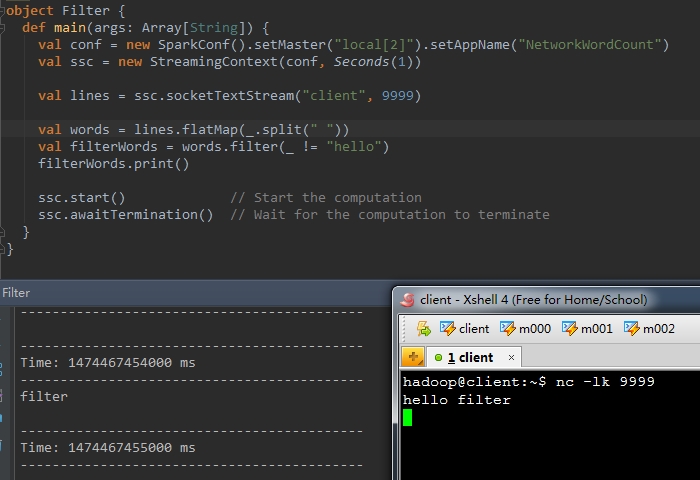
filter(func) |
在源DSTREAM上选择Func函数返回仅为true的元素,最终返回一个新的DSTREAM 。 |
|
repartition(numPartitions) |
通过输入的参数numPartitions的值来改变DStream的分区大小。 |
|
union(otherStream) |
返回一个包含源DStream与其他 DStream的元素合并后的新DSTREAM。 |
|
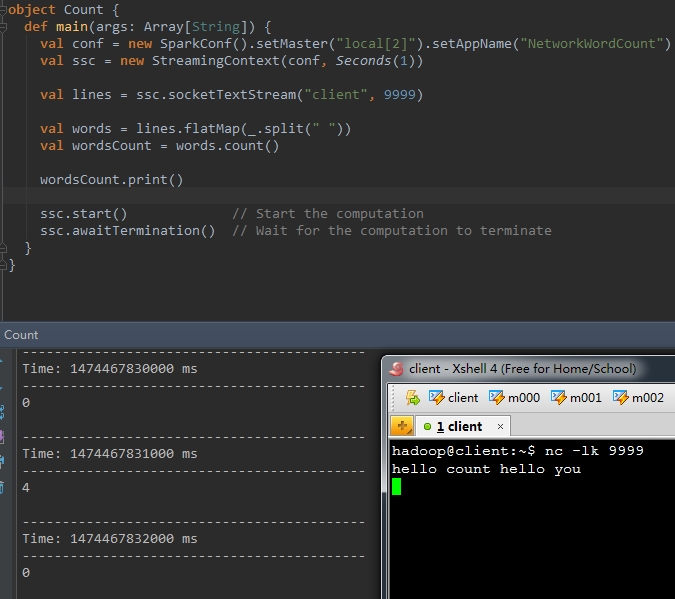
count() |
对源DStream内部的所含有的RDD的元素数量进行计数,返回一个内部的RDD只包含一个元素的DStreaam。 |
|
reduce(func) |
使用函数func(有两个参数并返回一个结果)将源DStream 中每个RDD的元素进行聚 合操作,返回一个内部所包含的RDD只有一个元素的新DStream。 |
|
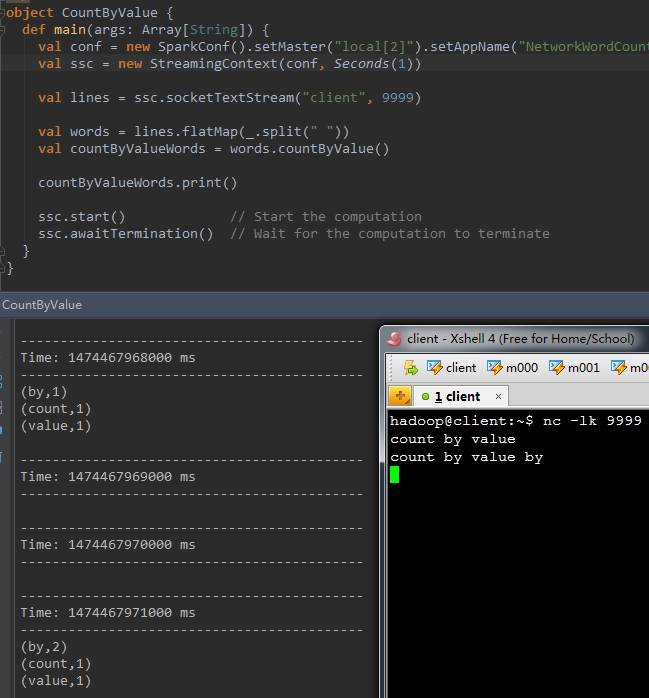
countByValue() |
计算DStream中每个RDD内的元素出现的频次并返回新的DStream[(K,Long)],其中K是RDD中元素的类型,Long是元素出现的频次。 |
|
reduceByKey(func, [numTasks]) |
当一个类型为(K,V)键值对的DStream被调用的时候,返回类型为类型为(K,V)键值对的新 DStream,其中每个键的值V都是使用聚合函数func汇总。注意:默认情况下,使用 Spark的默认并行度提交任务(本地模式下并行度为2,集群模式下位8),可以通过配置numTasks设置不同的并行任务数。 |
|
join(otherStream, [numTasks]) |
当被调用类型分别为(K,V)和(K,W)键值对的2个DStream 时,返回类型为(K,(V,W))键值对的一个新DSTREAM。 |
|
cogroup(otherStream, [numTasks]) |
当被调用的两个DStream分别含有(K, V) 和(K, W)键值对时,返回一个(K, Seq[V], Seq[W])类型的新的DStream。 |
|
transform(func) |
通过对源DStream的每RDD应用RDD-to-RDD函数返回一个新的DStream,这可以用来在DStream做任意RDD操作。 |
|
updateStateByKey(func) |
返回一个新状态的DStream,其中每个键的状态是根据键的前一个状态和键的新值应用给定函数func后的更新。这个方法可以被用来维持每个键的任何状态数据。 |
在上面列出的这些操作中,transform()方法和updateStateByKey()方法值得我们深入的探讨一下:
l transform(func)操作
该transform操作(转换操作)连同其其类似的 transformWith操作允许DStream 上应用任意RDD-to-RDD函数。它可以被应用于未在 DStream API 中暴露任何的RDD操作。例如,在每批次的数据流与另一数据集的连接功能不直接暴露在DStream API 中,但可以轻松地使用transform操作来做到这一点,这使得DStream的功能非常强大。例如,你可以通过连接预先计算的垃圾邮件信息的输入数据流(可能也有Spark生成的),然后基于此做实时数据清理的筛选,如下面官方提供的伪代码所示。事实上,也可以在transform方法中使用机器学习和图形计算的算法。
示例:
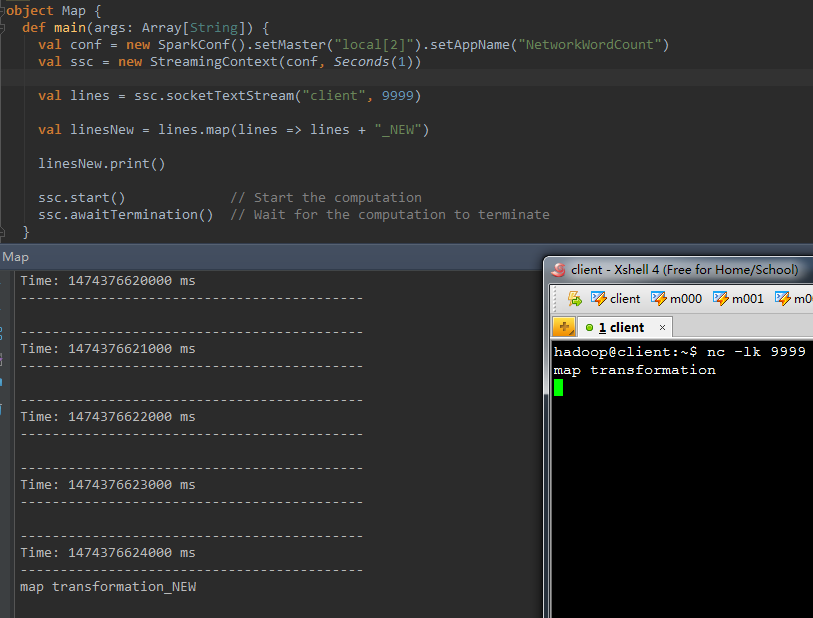
1、map(func)
val b = a.map(func)
val linesNew = lines.map(lines => lines + "_NEW" )
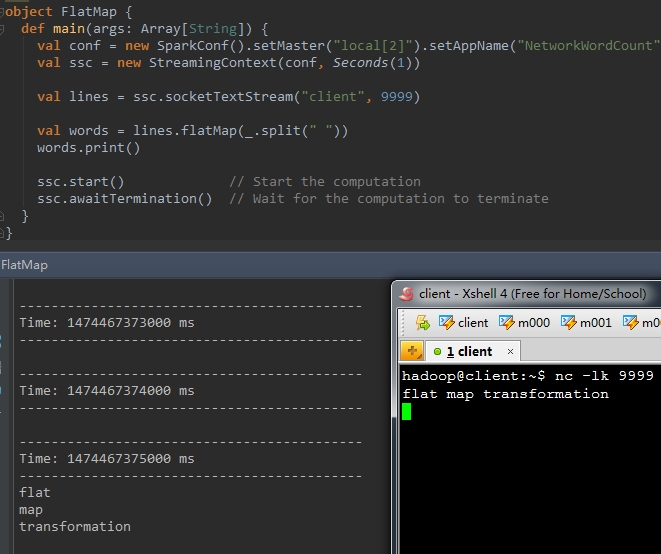
2、flatMap(func)
val b = a.flatMap(func)
val words = lines.flatMap(_.split( " " ))
val b = a.filter(func)

val wordsOne = words.map(_ + "_one" )
val wordsTwo = words.map(_ + "_two" )
val unionWords = wordsOne.union(wordsTwo) wordsOne.print()
wordsTwo.print()
unionWords.print()

val wordsCount = words.count()
val reduceWords = words.reduce(_ + "-" + _)
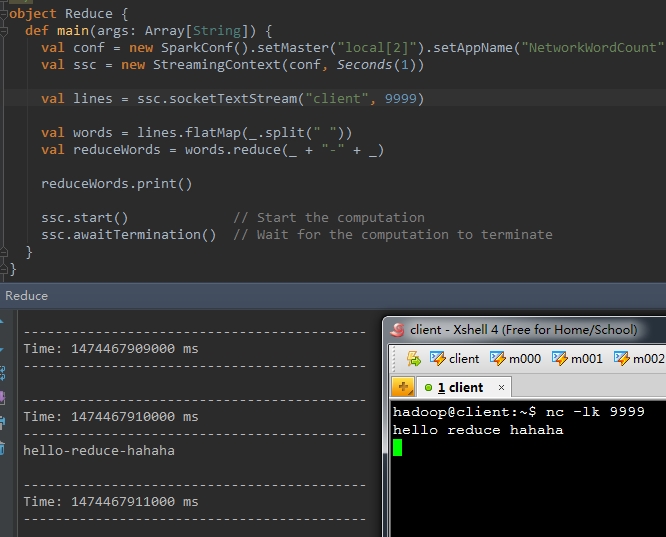
val countByValueWords = words.countByValue()
val pairs = words.map(word => (word , 1))
val wordCounts = pairs.reduceByKey(_ + _)

val wordsOne = words.map(word => (word , word + "_one" ))
val wordsTwo = words.map(word => (word , word + "_two" ))
val joinWords = wordsOne.join(wordsTwo)


l updateStateByKey操作
该 updateStateByKey 操作可以让你保持任意状态,同时不断有新的信息进行更新。要使用此功能,必须进行两个步骤 :
(1) 定义状态 - 状态可以是任意的数据类型。
(2) 定义状态更新函数 - 用一个函数指定如何使用先前的状态和从输入流中获取的新值 更新状态。
让我们用一个例子来说明,假设你要进行文本数据流中单词计数。在这里,正在运行的计数是状态而且它是一个整数。我们定义了更新功能如下:

此函数应用于含有键值对的DStream中(如前面的示例中,在DStream中含有(word,1)键值对)。它会针对里面的每个元素(如wordCount中的word)调用一下更新函数,newValues是最新的值,runningCount是之前的值。

Spark Streaming之六:Transformations 普通的转换操作的更多相关文章
- Spark Streaming之一:整体介绍
提到Spark Streaming,我们不得不说一下BDAS(Berkeley Data Analytics Stack),这个伯克利大学提出的关于数据分析的软件栈.从它的视角来看,目前的大数据处理可 ...
- 初步了解Spark生态系统及Spark Streaming
一. 场景 ◆ Spark[4]: Scope: a MapReduce-like cluster computing framework designed for low-laten ...
- spark第六篇:Spark Streaming Programming Guide
预览 Spark Streaming是Spark核心API的扩展,支持高扩展,高吞吐量,实时数据流的容错流处理.数据可以从Kafka,Flume或TCP socket等许多来源获取,并且可以使用复杂的 ...
- Spark Streaming的编程模型
Spark Streaming的编程和Spark的编程如出一辙,对于编程的理解也非常类似.对于Spark来说,编程就是对于RDD的操作:而对于Spark Streaming来说,就是对DStream的 ...
- Spark Streaming:大规模流式数据处理的新贵(转)
原文链接:Spark Streaming:大规模流式数据处理的新贵 摘要:Spark Streaming是大规模流式数据处理的新贵,将流式计算分解成一系列短小的批处理作业.本文阐释了Spark Str ...
- Spark Streaming:大规模流式数据处理的新贵
转自:http://www.csdn.net/article/2014-01-28/2818282-Spark-Streaming-big-data 提到Spark Streaming,我们不得不说一 ...
- Spark Streaming之五:Window窗体相关操作
SparkStreaming之window滑动窗口应用,Spark Streaming提供了滑动窗口操作的支持,从而让我们可以对一个滑动窗口内的数据执行计算操作.每次掉落在窗口内的RDD的数据,会被聚 ...
- spark系列-8、Spark Streaming
参考链接:http://spark.apache.org/docs/latest/streaming-programming-guide.html 一.Spark Streaming 介绍 Spark ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
随机推荐
- Javascript对数组的操作--转载
在jquery中处理JSON数组的情况中遍历用到的比较多,但是用添加移除这些好像不是太多. 今天试过json[i].remove(),json.remove(i)之后都不行,看网页的DOM对象中好像J ...
- sqlite增删改查 SimpleCursorAdapter 事务
<?xml version="1.0" encoding="utf-8"?> <RelativeLayout xmlns:android=&q ...
- SAP初始账号
方法1:有其中某Client的登录帐号1. 用已有帐号登录某个Client2. 运行Tcode SE303. 单击“tips and tricks“按钮4. 在Performance Tips an ...
- Web Service概念辨析
Web Service包含两个概念. 其一是Web Service标准体系,由SOAP.WSDL.UDDI三要素组成,是平台和语言无关的.在这个概念里和WCF做比较是错误的,因为前者是行业标准,后者是 ...
- Java多线程系列 JUC线程池05 线程池原理解析(四)
转载 http://www.cnblogs.com/skywang12345/p/3544116.html https://blog.csdn.net/programmer_at/article/d ...
- python字符串格式和编码与解码问题
%c 转换成字符(ASCII码值,长度为一的字符串) %r 有线使用repr()函数进行字符串转换 %s 有线使用str()函数进行字符串转换 %d or %i 转换成有符号十进制数 %u 转换成无符 ...
- P4240 毒瘤之神的考验
题目 P4240 毒瘤之神的考验 神仙题\(emmm\) 前置 首先有一个很神奇的性质: \(\varphi(ij)=\dfrac{\varphi(i)\varphi(j)gcd(i,j)}{\var ...
- hid_info函数分析
昨天博文<linux下无线鼠标驱动执行流程>中有一行输出信息很让我迷惑,如下所示: [ :1D57: Mouse [HID Wireless Mouse HID Wireless Mous ...
- China sets economic reform priorities for 2015
BEIJING -- China's State Council, the cabinet, on Monday unveiled this year's priorities for economi ...
- cocos2d-x 3.9 android studio项目命令行打包
进入创建的项目的 proj.android-studio目录 cocos run/compile -p android --android-studio 这样就可以打包了