在mac下使用python抓取数据
2015已经过去,这是2016的第一篇博文!
祝大家新年快乐!
但是我还有好多期末考试!
还没开始复习,唉,一把辛酸泪!
最近看了一遍彦祖的文章叫做
iOS程序员如何使用Python写网路爬虫
所以自己也想小试牛刀.于是便开始动手写,但初次接触,还是遇见了很多不懂的东西,于是爬文一个一个解决了,最终抓取了自己想要的东西
彦祖的这篇文章里Python代码格式有错,但是解释是没错的!所以我待会儿贴出我能正确运行的代码
彦祖的文章里说可以直接用类似于cocoapods的Python库管理工具pip进行安装我们解析网页所需要用的第三方库BeautifulSoup!
Mac确实是自带了Python.但是并没有安装pip,所以需要我们手动进行安装!
有人说可以使用命令:easy_install pip进行安装,但是我并没有安装成功!百思不得其解
于是爬文寻找其他方法:http://stackoverflow.com/questions/17271319/installing-pip-on-mac-os-x
原来是需要我的超级管理员权限...
至此,安装Pip成功
- 第二步:安装BeautifulSoup!
用彦祖的命令去运行,结果报错!提示我安装失败!(又忘了截图..)
没办法,就尝试手动安装BeautifulSoup,结果还是不行
后来我想是不是还是因为没有管理员权限的原因
于是尝试加上过后,就安装成功了
好了,开始写代码吧,但是我一个新人连该用什么来写Python代码都不知道!
又搜!(好低级的问题)=====>用记事本就行(真方便)(保存为.py文件后,是用的xcode打开的)
于是敲了如下代码:
#!/usr/bin/python
#-*- coding: utf-8 -*-
#encoding=utf-8 import urllib2
import urllib
import os
from BeautifulSoup import BeautifulSoup
def getAllImageLink():
html = urllib2.urlopen('http://www.dbmeinv.com').read()
soup = BeautifulSoup(html) liResult = soup.findAll('li',attrs={"class":"span3"}) for li in liResult:
imageEntityArray = li.findAll('img')
for image in imageEntityArray:
link = image.get('src')
imageName = image.get('title')
filesavepath = '/Users/WayneLiu_Mac/Desktop/meizi/%s.png' % imageName
urllib.urlretrieve(link,filesavepath)
print filesavepath if __name__ == '__main__':
getAllImageLink()
获得了如下数据(彦祖好邪恶....):
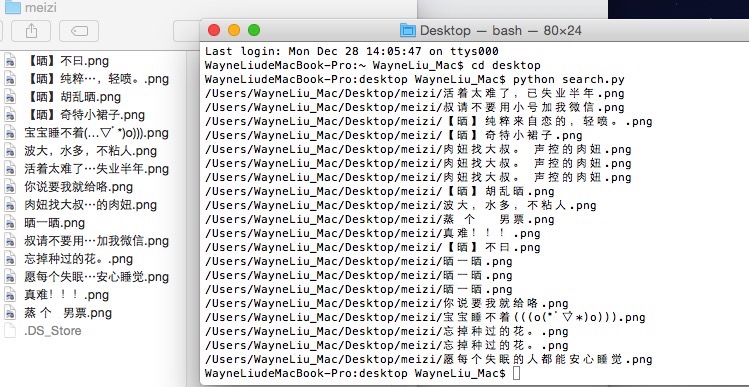
其实python真的很强大的,短短数几十行代码就可以实现这些功能!
闲来无事,又完善了一下代码,用以获得所有妹子的照片...
#!/usr/bin/python
#-*- coding: utf-8 -*-
#encoding=utf-8 import urllib2
import urllib
import os
import socket
from BeautifulSoup import BeautifulSoup def getAllImageLink():
xiayiye = True
page = '/?pager_offset=12'
while(1):
html = urllib2.urlopen('http://www.dbmeinv.com%s' % page).read()
soup = BeautifulSoup(html) liResult = soup.findAll('li',attrs={"class":"span3"})
nextResult = soup.findAll('li',attrs={"class":"next next_page"}) for li in liResult:
imageEntityArray = li.findAll('img')
nameResult = li.findAll('span',attrs={"class":"starcount"})
for name in nameResult:
nameTitle = name.get('topic-image-id') for image in imageEntityArray:
link = image.get('src')
filesavepath = '/Users/WayneLiu_Mac/Desktop/meizi2/%s.jpg' % nameTitle
socket.setdefaulttimeout(30)
urllib.urlretrieve(link,filesavepath)
print filesavepath for nextPage in nextResult:
aEntityArray = nextPage.findAll('a')
for a in aEntityArray:
nextTitle = a.get('title')
print nextTitle
page = a.get('href')
print page
if nextTitle.encode('utf-8') != "下一页":
xiayiye = False
print xiayiye
if xiayiye == False:
break if __name__ == '__main__':
getAllImageLink()
呵呵哒...

在mac下使用python抓取数据的更多相关文章
- python抓取数据,python使用socks代理抓取数据
在python中,正常的抓取数据直接使用urllib2 这个模块: import urllib2 url = 'http://fanyi.baidu.com/' stream = urllib2.ur ...
- python抓取数据构建词云
1.词云图 词云图,也叫文字云,是对文本中出现频率较高的"关键词"予以视觉化的展现,词云图过滤掉大量的低频低质的文本信息,使得浏览者只要一眼扫过文本就可领略文本的主旨. 先看几个词 ...
- python抓取数据 常见反爬虫 情况
1.报文头信息: User-Agent Accept-Language 防盗链 上referer 随机生成不同的User-Agent构造报头 2.加抓取等待时间 每抓取一页都让它随机休息几秒,加入此 ...
- MAC下使用Charles抓取安卓模拟器数据
一.安装Charles,这个不多记录 二.Charles数据乱码问题(参照这篇文章 http://blog.csdn.net/huanghanqian/article/details/52973651 ...
- python 抓取数据,pandas进行数据分析并可视化展示
感觉要总结总结了,希望这次能写个系列文章分享分享心得,和大神们交流交流,提升提升. 因为半桶子水的水平,一直在想写什么,为什么写,怎么写. 直到现在找到了一种好的办法: 1.写什么 自己手上掌握的,工 ...
- python 抓取数据 存入 excel
import requestsimport datetimefrom random import choicefrom time import timefrom openpyxl import loa ...
- 使用python抓取数据之菜鸟爬虫1
''' Created on 2018-5-27 @author: yaoshuangqi ''' #本代码获取百度乐彩网站上的信息,只获取最近100期的双色球 import urllib.reque ...
- Python 抓取数据存储到Mysql中
# -*- coding: utf-8 -*- import os,sys import requests import bs4 import pymysql#import MySQLdb #连接MY ...
- Python 抓取数据存储到Redis中
redis是一个key-value存储结构.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合).zset(sorted set ...
随机推荐
- tp5分页注意,分页生成的ul class是pagination,有些模板可能将pagination定义为display:none
今天在调用分页时总是无法显示,查看网页源代码是正常的,后来发现是在css文件里将pagination定义为display:none,所以无法显示
- springMvc json 参数
以前,一直以为在SpringMVC环境中,@RequestBody接收的是一个Json对象,一直在调试代码都没有成功,后来发现,其实 @RequestBody接收的是一个Json对象的字符串,而不是一 ...
- ssl加密
握手前使用非对称加密, 握手后使用对称加密 前期握手就是用来协商对称加密算法的
- 07.Spring Bean 加载 - BeanDefinitionReader
基本概念 BeanDefinitionReader ,该接口的作用就是加载 Bean. 在 Spring 中,Bean 一般来说都在配置文件中定义.而在配置的路径由在 web.xml 中定义.所以加载 ...
- LeetCode 137 Single Number II 数组中除了一个数外,其他的数都出现了三次,找出这个只出现一次的数
Given an array of integers, every element appears three times except for one, which appears exactly ...
- gogs迁移
windows->linux 之前gogs放在windows server2016中,需要迁移至linux docker中. 首先拉取gogs镜像 docker pull gogs/gogs 然 ...
- Java微信公众平台开发(十)--微信用户信息的获取
前面的文章有讲到微信的一系列开发文章,包括token获取.菜单创建等,在这一篇将讲述在微信公众平台开发中如何获取微信用户的信息,在上一篇我们有说道微信用户和微信公众账号之间的联系可以通过Openid关 ...
- 利用PyQt GUI显示图片、实时播放视频
---作者吴疆,未经允许,严禁转载,违权必究--- ---欢迎指正,需要源码和文件可站内私信联系--- -----------点击此处链接至博客园原文----------- 功能说明:PyQt界面程序 ...
- 精心收集的SSH框架的面试题汇总
Hibernate工作原理及为什么要用? 原理: 1. 读取并解析配置文件 2. 读取并解析映射信息,创建SessionFactory 3. 打开Sesssion 4. 创建事务Transation ...
- POI 博客总结.....
主键类: HSSFRow row1= sheet.createRow(1); row.createCell(0).setCellValue("学生编号"); row.createC ...