ELK日志分析系统-Logstack
ELK日志分析系统
作者:Danbo 2016-*-*
本文是学习笔记,参考ELK Stack中文指南,链接:https://www.gitbook.com/book/chenryn/kibana-guide-cn/details
ELK Stack 是 Elasticsearch、Logstash、Kibana 三个开源软件的组合。在实时数据检索和分析场合,三者通常是配合共用,而且又都先后归于 Elastic.co 公司名下,故有此简称。
ELK Stack 在最近两年迅速崛起,成为机器数据分析,或者说实时日志处理领域,开源界的第一选择。和传统的日志处理方案相比,ELK Stack 具有如下几个优点:
- 处理方式灵活。Elasticsearch 是实时全文索引,不需要像 storm 那样预先编程才能使用;
- 配置简易上手。Elasticsearch 全部采用 JSON 接口,Logstash 是 Ruby DSL 设计,都是目前业界最通用的配置语法设计;
- 检索性能高效。虽然每次查询都是实时计算,但是优秀的设计和实现基本可以达到全天数据查询的秒级响应;
- 集群线性扩展。不管是 Elasticsearch 集群还是 Logstash 集群都是可以线性扩展的;
- 前端操作炫丽。Kibana 界面上,只需要点击鼠标,就可以完成搜索、聚合功能,生成炫丽的仪表板。
Logstack
推荐安装方式:采用Elasticsearch官方仓库来直接安装Logstash
rpm --import http://packages.elasticsearch.org/GPG-KEY-elasticsearch
cat > /etc/yum.repos.d/logstash.repo <<EOF
[logstash-1.5]
name=logstash repository for 1.5.x packages
baseurl=http://packages.elasticsearch.org/logstash/1.5/centos
gpgcheck=
gpgkey=http://packages.elasticsearch.org/GPG-KEY-elasticsearch
enabled=
EOF
yum clean all
yum install logstash
不过我是直接官网下载logstash-1.5.4.tar.gz安装包,然后直接tar -zxvf logstash-1.5.4.tar.gz; mv logstash-1.5.4 /usr/local; ln -s logstash-1.5.4 logstash。支持安装完毕。
测试运行结果如下:
[root@centos-linux logstash]# bin/logstash -e 'input {stdin{}}output{stdout{codec=>rubydebug}}'
Hello World
Logstash startup completed
{
"message" => "Hello World",
"@version" => "1",
"@timestamp" => "2016-03-03T03:17:37.694Z",
"host" => "centos-linux.shared"
}
Logstash就像管道一样,输入类似cat,处理类似过滤awk、uniq,最后输出类似并保存类似tee。
top--》H查看进程时发现,logstash给每个线程都取了一个名字,输入的叫xx,输出的叫|xx。数据在线程之间以事件的形式流传。logstash会给事件添加一些额外的信息。最重要的是@timestamp,用来标记时间的发生时间。
语法
logstash设计了自己的DSL(Domain Specific Language,区域特定语言)
包括:区域,注释,数据类型(布尔值,字符串,数值,数组,哈希),条件判断,字段引用等。
区段(section)
logstash用{}来定义区域。区域内可以包括插件区域定义,可以在一个区域内定义多个插件。插件区域内则可以定义键值对(类似字典)设置
数据类型
Logstash支持少量的数据值类型
bool
debug => true
string
host => "hostname"
number
port => 514
array
match => ["datetime", "UNIX", "ISO8601"]
hash
options => {
key1 => "value1"
key2 => "value2"
}
如果是logstash版本低于1.2.0,哈希的语法跟数组是一样的,就像下面这样:
match => ["field1", "pattern1", "field2", "pattern2"]
字段引用(field reference)
字段是Logstash::Event 对象的属性。对象就像一个哈希一样,所以你可以想象字段就像一个键值对。
在Logstash配置中使用字段的值,只需要把字段的名字写在[]里就行了,这就叫字段引用。对于嵌套字段(多维哈希表),每层的字段名都写在[]里就可以了。比如可以从geoip里获取longitude值:[geoip][location][0]。
logstash 还支持变量内插,在字符串里使用字段引用的方法是这样:
"the longitude is %{[geoip][location][-1]}"
条件判断(condition)
命令行参数
Logstash提供了一个shell脚本叫logstash 方便快速运行,
-e 执行。
--config或者-f 表示文件。
真实运用中,我们会写很长的配置,甚至超过shell所能支持的1024个字符长度。所以我们必把配置固定化到文件里,然后通过bin/logstash -f agent.conf这样的形式来运行。
此外,logstash还提供一个方便我们规划和书写配置的小功能。你可以直接用bin/logstash -f /etc/logstash.d/来运行。logstash会自动读取/etc/logstash.d/目录下所有*.conf的文本文件,然后在自己内存里拼接成一个完整的大配置文件,再去执行。
--configtest 或-t表示测试。
用来测试logstash读取到的配置文件语法是否能正常解析。
--log 或-l表示日志
logstash默认输出日志到标准错误。生产环境可以通过bin/logstash -l logs/logstash.log 来统一存储日志。
--filterworks 或 -w 表示工作线程
logstash会运行多个线程。你可以用bin/logstash -w 5这样的方式强制logstash为过滤插件运行5个线程。
--pluginpath 或 -P
可以写自己的插件,然后利用bin/logstash --pluginpath /path/to/own/plugins加载他们。不过高版本的logstash已经取消该功能了。
--verbose
输出一定的调试日志
--debug
输出更多的调试日志
Plugin的安装
从logstash 1.5.0版本开始,logstash将所有的插件都独立拆分为gem包,这样,每个插件都可以独立更新,不用等待logstash自身做整体更新的时候才能使用。
plugin用法说明
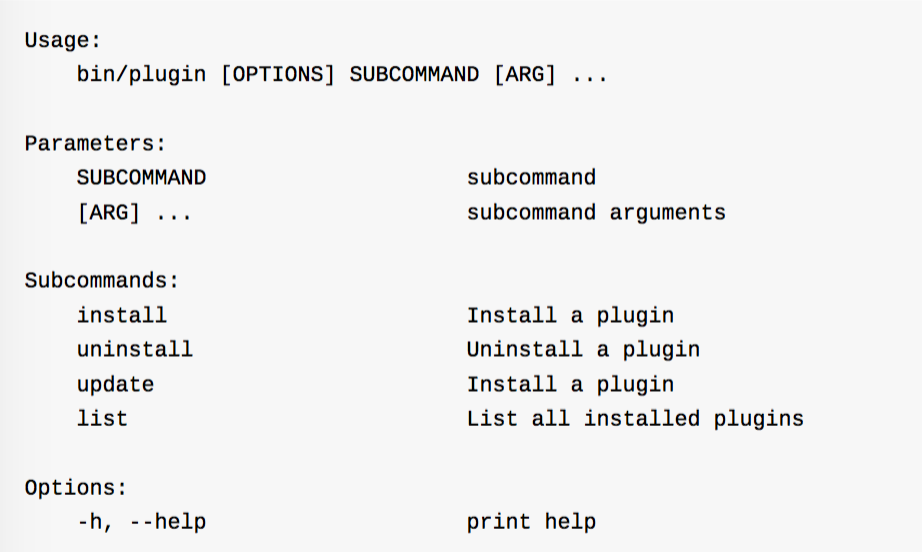
示例,通过bin/plugin list 查看本机现在有多少插件可用。(其实就在vendor/bundle/ruby/1.9/gems 目录下)
通过bin/plugin install logstash-ouput-webhdfs 就可以了;
同样仅升级的话可以使用:bin/plugin update logstash-input-tcp
本地插件安装
bin/plugin 不单可以通过rubygems平台安装插件,还可以读取本地路径的gem文件。
例如:bin/plugin install /path/to/logstash-filter-crash.gem
长期运行
1.最基础的nohup方式
nohup command 2>$1 &
2.screen方式
3.推荐daemontools方式
daemontools是一个软件的,包括但不限于python实现的supervisord,perl实现的ubic,ruby实现的god等。
?????这个没懂
输入插件
注意:logstash配置一定要有一个input和一个output。如果没有写明input,默认就会使用input/stdin,同理,没有写明的output就是output/stdout。
collectd简述
collectd是一个守护进程,用来收集系统性能和提供各种存储方式来存储不同值的机制。它会在系统运行和存储信息时周期的统计系统的相关统计信息。利用这些信息有助于查找当前系统性能瓶颈和预测系统未来的部署能力。
详细参见配置手册。
读取文件(File)
Logstash使用一个名叫FileWatch的Ruby Gem库来监听文件变化。会记录一个叫.sincedb的数据库文件来跟踪被监听的日志文件的当前读取位置。
sincedb文件中记录了每个被监听的文件的inode, major number, minor number 和 pos
配置文件:
[root@centos-linux conf]# cat input.conf
input {
file {
path => ["/var/log/*.log", "/var/message"]
type => "system"
start_position => "beginning"
}
}
解释
有一些有用的配置项:
·discover_interval
logstash每隔多久去检查一次被监听的path下是否有新文件。默认值是15s。
·exclude
不想被监听的文件可以排除出去。
·sincedb_path
如果你不想用默认的$HOME/.sincedb,可以通过这个配置定义sincedb文件到其他位置。
·sincedb_write_interval
logstash每隔多久写一次sincedb文件,默认是15s。
·stat_interval
logstash每隔多久检查一次被监听文件状态(是否更新),默认是1s。
·start_position
logstash从什么位置开始读取文件数据,默认是结束位置,也就是说logstash进程会以类似tail -f的形式运行。如果你是要导入原有数据,可以把这个参数改成"beginning",logstash进程就从头开始读取,优点类似cat,然后读到最后一行再以tail -f形式读取。
此时我们运行input.conf文件: bin/logstash -f /conf/input.conf
[root@centos-linux logstash]# cat conf/input.conf
input {
file {
path => ["/var/log/*.log", "/var/message"]
type => "system"
start_position => "beginning"
sincedb_path => "/uestc/log/sincedb"
}
}
运行结果如下:
[root@centos-linux log]# cat sincedb
正如上面写的,从左到右以此为:inode, major number, minor number, pos
注意:
1.FileWatch只支持文件的绝对路径,而且会不自动递归目录。所以有需要的话,用数字方式写明具体哪些文件。
2.LogStash::Inputs::File 只是在进程运行的注册阶段初始化一个FileWatch对象。它不支持那样动态的写法,如:path => "/path/to/%{+yyyy/MM/dd/hh}.log"这样的写法,为了达到相同的目的你可以写:path => "/path/to/**/*.log",用**来缩写表示递归全部子目录。
3. start_position 仅在该文件从从未被监听的时候起作用。如果sincedb文件中已经由这个文件的inode记录了,那么logstash依然会从记录过的pos开始读取数据。所以重复测试的时候需要删除sincedb文件,不过有另一巧妙的解决办法那就是在conf文件中将sincedb_path定义为/dev/null,则每次启动自动从头开会读。
4.不过windows没有inode的概念,因此在windows下很不靠谱。
读取Syslog数据
当你想从设备上收集系统日志的时候,syslog应该会是你的第一选择。
这个实验没有做成功。
读取网络数据(TCP)
未来你可能会用Redis服务器或者其他的消息队列系统来作为logstash broker的角色。不过logstash其实也有自己的TCP/UDP插件,不过在生产环境下Logstash本身只能在sizedqueue中缓存20个事件。
目前来看,logstash::input::TCP 最常见的用法就是配合nc命令导入久数据。
******
编码插件(Codec)
Codec来自Coder/Decoder两个单词的首字母缩写。
其实logstash最初只支持纯文本形式输入,然后过滤处理它,现在可以处理不同的类型的数据,这全是因为有了codec设置。logstash不只只有一个input | filter | output 的数据流,而是一个input| decode| filter | encode | output 的数据流 codec就是用来decode、encode事件的。
采用JSON编码
在早期的版本中,有一种降低logstash过滤器的CPU负载消耗的做法盛行于社区:直接输入预定义好的JSON数据,这样就可以省略嗲filter/grok配置。
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,其特点是易于人阅读和编写,同时也易于机器解析和生成(一般用于提高网络传输速率)。
合并多行数据(Multiline)
有时候,应用程序调试日志会包含非常丰富的内容,为一个事件打印出很多行内容,这种日志通常都很难通过命令解析的方式做分析。
配置实例:
input {
stdin {
codec => multiline {
pattern => "^\["
negate => true
what => "previous"
}
}
}
此时在logstash输入以下几行信息:

此时你会发现logstash输出下面这样的返回:

此时你会发现输出的事件中都没有最后的“the end”字符串。这是因为你最后输入的回车符\n 并不匹匹配^\[开头”[“,logstash还得等到下一个数据直到匹配成功后才会输出这个事件。
NetFlow
******
过滤器插件(Filter)
1.时间处理(Date)
之前我们提到过,filters/date插件可以用来转换你的日志记录中的时间字符串,变成Logstash::Timestamp 对象,然后转存到@timestamp字段里。
注意:因为在稍后的outputs/elasticsearch中常用的%{+YYYY.MM.dd} 这种写法必须读取@timestamp数据,所以一定不要直接删掉这个字段保留自己的字段,而是应该用filters/date转换后删除自己的字段!
2.Grok正则捕获
Grok是Logstash最重要的插件。你可以在Grok里预定义好命名正则表达式,在稍后(grok参数或者其他正则表达式里)引用它。
配置文件:
input {stdin{}}
filter {
grok {
match => {
"message" => "\s+(?<request_time>\d+(?:\.\d+)?)\s+"
}
}
}
output {stdout{}}
然后运行logstash进程,然后输入"begin 123.456 end",你会看到类似下面的输出:

不过数据类型好像不太对,request_time 应该是数值而不是字符串。
3.Grok正则捕获
Grok支持把预定义的grok表达式写入到文件中。
其用法我们看下面这个示例:
USERNAME [a-zA-Z0-._-]+
USER %{USERNAME}
第一行,用普通的正则表达式来定义一个grok表达式;第二行,通过打印赋值格式,用前面定义好的grok表达式来定义另一个grok表达式。
grok表达式的打印复制格式的完整语法是下面这样:
%{PATTERN_NAME:capture_name:data_type}
data_type 目前只支持两个值:int 和 float。
我们将配置修改成下面这样:
input { stdin {} }
filter {
grok {
match => {
"message" => "%{WORD} %{NUMBER:request_time:float} %{WORD}"
}
}
}
output { stdout {} }
重新运行进程然后可以得到如下结果:

此时request_time 变成数值类型了。
4.最佳实践
实际运用中,我们需要处理各种各样的日志文件,如果都是在配置文件里各自写一行自己的表达式,太麻烦,我们建议是把所有的grok表达式统一写入到一个地方。然后用filter/grok的patterns_dir 选项来指明。
如果你吧“message”里所有的信息都grok到不同的字段了,数据实质上就相当于是重复存储了两份。所以可以用remove_field参数来删除掉message字段,或者用overwirte 参数来重写默认的message字段,只保留最重要的部分。
重写参数:
filter {
grok {
patterns_dir => "/path/to/your/own/patterns"
match => {
"message" => "%{SYSLOGBASE} %{DATA:message}"
}
overwirte => ["message"]
}
}
哎哎......有没有讲解的视频啊~,求视频!
**********
ELK日志分析系统-Logstack的更多相关文章
- ELK日志分析系统简单部署
1.传统日志分析系统: 日志主要包括系统日志.应用程序日志和安全日志.系统运维和开发人员可以通过日志了解服务器软硬件信息.检查配置过程中的错误及错误发生的原因.经常分析日志可以了解服务器的负荷,性能安 ...
- Rsyslog+ELK日志分析系统
转自:https://www.cnblogs.com/itworks/p/7272740.html Rsyslog+ELK日志分析系统搭建总结1.0(测试环境) 因为工作需求,最近在搭建日志分析系统, ...
- 十分钟搭建和使用ELK日志分析系统
前言 为满足研发可视化查看测试环境日志的目的,准备采用EK+filebeat实现日志可视化(ElasticSearch+Kibana+Filebeat).题目为“十分钟搭建和使用ELK日志分析系统”听 ...
- elk 日志分析系统Logstash+ElasticSearch+Kibana4
elk 日志分析系统 Logstash+ElasticSearch+Kibana4 logstash 管理日志和事件的工具 ElasticSearch 搜索 Kibana4 功能强大的数据显示clie ...
- 《ElasticSearch6.x实战教程》之实战ELK日志分析系统、多数据源同步
第十章-实战:ELK日志分析系统 ElasticSearch.Logstash.Kibana简称ELK系统,主要用于日志的收集与分析. 一个完整的大型分布式系统,会有很多与业务不相关的系统,其中日志系 ...
- Docker笔记(十):使用Docker来搭建一套ELK日志分析系统
一段时间没关注ELK(elasticsearch —— 搜索引擎,可用于存储.索引日志, logstash —— 可用于日志传输.转换,kibana —— WebUI,将日志可视化),发现最新版已到7 ...
- ELK 日志分析系统的部署
一.ELK简介 ElasticSearch介绍Elasticsearch是一个基于Lucene的搜索服务器. 它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口. Elasti ...
- Rsyslog+ELK日志分析系统搭建总结1.0(测试环境)
因为工作需求,最近在搭建日志分析系统,这里主要搭建的是系统日志分析系统,即rsyslog+elk. 因为目前仍为测试环境,这里说一下搭建的基础架构,后期上生产线再来更新最后的架构图,大佬们如果有什么见 ...
- ELK日志分析系统搭建
之前一段时间由于版本迭代任务紧,组内代码质量不尽如人意.接二连三的被测试提醒后台错误之后, 我们决定搭建一个后台日志分析系统, 经过几个方案比较后,选择的相对更简单的ELK方案. ELK 是Elast ...
随机推荐
- KingdeeK3-修改单据邮件发送的自定义字段
只需要执行类似下面语句即可: update ICTemplateentry set FVisForBillType = 63,flookupcls=6 where fid ='P01' and fhe ...
- window.location网页URL信息
window.location属性 描述 hash 设置或获取 href 属性中在井号“#”后面的分段. host 设置或获取 location 或 URL 的 hostname 和 port 号码. ...
- LeetCode :: Sum Root to Leaf Numbers [tree、dfs]
Given a binary tree containing digits from 0-9 only, each root-to-leaf path could represent a number ...
- mfs客户端挂载
1.安装fuse yum install fuse fuse-devel 2.加载fuse模块 modprobe fuse 3.创建mfs用户 useradd mfs -s /sbin/nologin ...
- 2d-Lidar 点云多直线拟合算法
具体步骤: EM+GMM(高斯模糊模型) 点云分割聚类算法的实现. 基于RANSAC单帧lidar数据直线拟合算法实现. 多帧lidar数据实时直线优化算法实现. 算法实现逻辑: Struct lin ...
- linux安全组配置
万网的是这样子配置的:
- Junit内部解密之四: Junit单元测试最佳实践
我们做使用Junit工具来做单页测试或接口测试时,需要注意一些问题,包括我们的编码规范,test规范,以及编写测试代码的策略,以下个人的总结. 1.为还没有实现的测试代码抛出一个异常.这就避免了该测试 ...
- NPOI 添加下拉列表
需求 给指定列添加下拉列表.如下图: 思路 NPOI的文档网站不能访问了,这里参考的POI文档. 加下拉列表有两种方式,一种直接写字符串,例如 new String[]{"10", ...
- 你不知道的Google Search
0.导读 这篇文章讲了这三个事儿: 如何訪问Google?----------什么?不是直接输入地址么? Google的地址是什么? ------ 你在逗我?难道不是www.google.com? G ...
- C#趣味程序---理財高手
问题:如果银行存款分五种 利率:0.63% 一年 月 利率:0.66% 二年 月 利率:0.69% 三年 月 利率:0.75% 五年 月 利率:0.84% 八年 月 如今 ...