NDPQ(NDP+PQ),定义分布式数据库新方向
摘要:云服务提供商构建新的云原生关系数据库系统,专门为云基础架构设计,通常采用将计算和存储分离到独立扩展的分布式层的设计。
本文分享自华为云社区《性能提升100倍!GaussDB(for MySQL)近数据处理(NDP)解锁查询新姿势》,作者: GaussDB 数据库。
业务增长对数据库吞吐量和响应能力提出新挑战
随着企业和政府机构将其应用程序迁移到云端,对基于云的数据库即服务(DBaaS)产品的需求也在迅速增长。传统上的DBaaS产品,是云服务提供商基于现有的数据库软件本身,将常规数据库部署在云端虚拟机上,使用的是本地或者云存储。这种方法易于实施,但是未能提供足够的性能和可扩展性,而且由于需要复制数据,存储成本也很高。
为了应对这些挑战,云服务提供商开始构建新的云原生关系数据库系统,专门为云基础架构设计,通常采用将计算和存储分离到独立扩展的分布式层的设计。这种方法具有多种优势,包括数据库存储的自动扩展、按使用付费功能、跨多个AZ部署的高可靠性以及故障快速切换和恢复。这些云原生设计还有助于减少只读副本的数据更新时延,并提高硬件共享和可扩展性。华为云数据库GaussDB(for MySQL),正是具备上述优势的一款云原生分布式数据库。
由于计算和存储节点通过网络通信,网络带宽和延迟往往成为瓶颈。为了克服这一挑战,GaussDB(for MySQL)通过从数据库节点中去除写页面的操作并将检查点操作向下推送到存储节点,以优化与写入相关的网络流量。GaussDB(for MySQL)数据库节点向存储节点发送REDO日志,而不是数据页。因为REDO日志(记录对数据页的修改)通常比修改的数据页小得多, 所以这种方法减少了网络流量。存储节点(也称为页面存储)能够根据REDO日志构建数据库页面,并可以响应数据库节点的请求,将页面返回到数据库节点。
在传统数据库中,SQL执行引擎从存储中获取数据,并执行包括投影、谓词计算和聚合在内的步骤。对于经常涉及大型表扫描的分析查询,SQL执行引擎必须从存储中读取大量数据页。当存储节点与计算分离,通过网络通讯时,大表扫描会转化为增加的网络流量。一个典型的例子是对一个非常大的表进行计数查询,查询对象表的所有页面必须从页面存储池(Page stores)发送到要计数的数据库节点,之后,数据库节点将丢弃这些页面中的大部分,因为缓冲区池不能装载这么多数据页,这是对网络带宽资源的浪费。华为云创新的NDP(Near Data Processing,近数据处理,简称NDP)方案解决了这一问题。
GaussDB(for MySQL)近数据处理(NDP)详解
NDP的设计思路是避免在分布式系统中移动数据,并让数据处理在其所存储的地方进行。在云原生数据库中,存储节点通常由大量性能强大的服务器组成,这些存储节点上的CPU资源经常利用率较低,这就为近数据处理(NDP)提供了一个绝佳的机会。
GaussDB(for MySQL)的NDP功能将选定的SQL操作下推到页面存储中,页面存储过滤掉不必要的数据,只将匹配的数据子集返回给数据库节点进一步处理。例如,要处理计数查询,页数据存储可以计数行,并将计数而不是实际数据页返回到数据库节点。这样就避免了大量的网络流量,使用此技术也提升了查询响应时间。
GaussDB(for MySQL)可以将三种SQL操作推送到页面存储:列投影、谓词计算和聚合。
- 列投影:页面存储通过仅保留查询所需的列并丢弃其余列,从而减少行的长度。
- 谓词计算:页数据存储仅保留满足谓词的行,并丢弃不满足谓词的行。
- 聚合:页面根据查询中聚合函数的要求,将多行聚合到单行中,并丢弃原始行。
这三种SQL操作可以以任何组合出现在NDP中。例如,NDP操作可能仅包含列投影,也可能包含所有三个SQL操作。让我们看看一个示例SQL查询:
sele ctsum(salary)
from worker
where age< 40 and
join_date>= date ‘2010-01-01’ and
join_date< date ‘2010-01-01’ + interval ‘1’ year
对于“worker”表中的每一行,页面存储计算谓词“age < 40 and join_date >= date‘2010-01-01’ and join_date < date ‘2010-01-01’ + interval ‘1’ year”。如果行不满足谓词,则将立即丢弃。如果该行满足谓词,则将其聚合到sum(salary)值中,并丢弃原始行。如果页数据存储无法聚合行(由于某些内部处理要求),它仍然可以从行投影三列(salary, age, and join_date),并生成更窄的行。此后,原始行将被丢弃。最后,将一个显著减少的数据集返回到数据库节点。
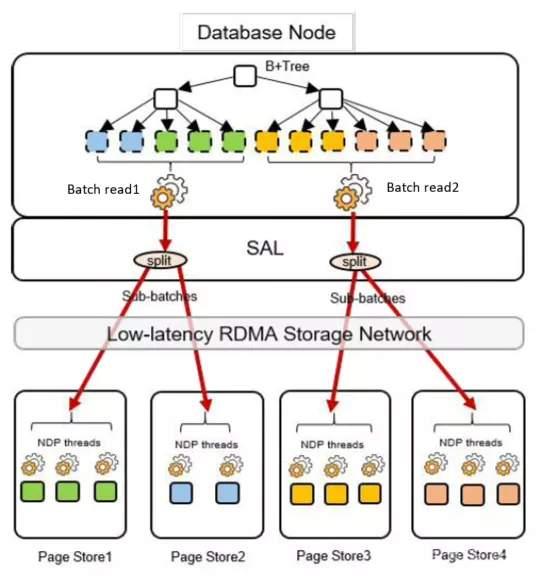
GaussDB (for MySQL)的 NDP特性架构如下图所示。数据库节点向页面存储发送NDP请求(请注意,通常有多个页面存储服务于每个数据库节点),为了降低IOPS(每秒IO数),将多个页面分组为一个NDP请求(批量页面读取请求),页面存储中的NDP运算符可以执行上述三种SQL操作,并将较小的数据集返回到数据库节点。数据库节点可以是主节点,也可以是只读副本节点,两者都支持NDP。

NDP中的批处理读取和并行处理
在云原生数据库系统中,即使数据库节点和页面存储通过高速RDMA网络连接,但与传统数据库中的本地存储相比,延迟仍然很高,通过降低网络IOPS和并行执行多个IO可以减少延迟带来的负面影响。在NDP功能中,我们实现了“批处理读取”的概念。这个想法是在B+树叶数据节点中向前看,并将相邻的叶数据节点分组到一个批处理请求中,而这些B+树叶数据节点是正在进行近数据处理的查询所需要的。批量读取是降低IOPS的一个绝佳方法。如果我们在每个请求中发送一个页面,那么IO的数量将等于页面的数量。如果我们将1000个页面分组到一个请求中,IO的数量将减少1000倍。
下图阐述了批处理读取的工作原理。数据库节点发送批量请求,SAL(存储抽象层)标识页面所在的页面存储,并将批处理读取拆分为多个子读取:每个页面存储一个子读取。然后,子读取将并行发送到页面存储。使用这种方法,可以同时使用多个页面存储来服务NDP请求。
页面存储接收包含多个页面的NDP请求,而这些页面之间没有依赖关系,因此可以使用NDP以任何顺序处理。这样既提供了灵活性,又使页面存储能够将页面分配给多个线程并行处理。
GaussDB(for MySQL)使用增强的SQL优化器自动判定NDP是否可能对特定查询有利。如果有利,它将自动启用NDP,SQL优化器查看扫描大小等因素,以及SQL运算如果推送到页面存储,是否可以显著降低数据集大小。一般来说,NDP并不有利于小扫描,例如,当可以用索引减少要扫描的数据量时。
同时,NDP也有自己的资源诉求。在数据库节点中,NDP主要占用内存资源,因为它需要内存来保存NDP页面。在GaussDB(for MySQL)数据库节点中,NDP页面与常规页面共享相同的内存池(又名缓冲区池),没有专门为NDP保留的内存。这种方法的优点是,当系统中没有NDP时,整个缓冲池可用于常规处理。但是页面内存一旦被NDP操作占用,在NDP操作完成之前,不能被其他查询使用。这就是为什么必须控制分配的NDP页数,以避免常规页被剥夺内存。
NDPQ(NDP+PQ),释放查询极致性能,定义分布式数据库新方向
并行查询(PQ)是商业关系型数据库系统的事实标准,为分析工作负载提供高性能支持。PQ通常采用“leader-worker”设计,要处理的表被划分为非重叠的数据块,并把这些数据块分配给多个worker处理。每个worker都会产生中间结果,leader会累积这些结果并做进一步处理,以产生最终结果。PQ在数据库节点中提供并行性,利用多个CPU并发处理查询。华为云GaussDB(for MySQL)具备PQ特性,而且NDP和PQ可以协同工作,进一步提高查询性能。可以为PQ worker启用NDP。PQ worker执行的一些SQL操作可以推送到页面存储区,通过将NDP和PQ结合,我们在GaussDB系统的数据库节点、多个页面存储之间和一个页面存储内部这三层激活了并行处理的魔力,进一步提高查询性能。
如何启用NDP?
GaussDB(for MySQL)会自动判断NDP是否有助于查询,并为查询启用NDP。用户需要做的就是打开系统变量“ndp_mode”。ndp_mode可以为整个数据库打开,也可以仅为当前会话打开。要为整个数据库打开ndp_mode,请在“set”命令中添加“global”关键字,如下所示:
set[global] ndp_mode = on
您可以使用“explain”查询以了解是否为查询启用了NDP。例如,以下是树格式的TPC-H查询14的解释输出。为LINEITEM表扫描启用了NDP,投影和谓词计算都会推送到数据页面存储区。此外,还为LINEITEM表扫描启用了PQ。

下面是另一个例子,在LINEITEM表上的计数查询,我们将此查询命名为Q002。谓词计算和聚合都会推送到页面存储区,PQ也已启用。

下面我们通过在100GB的TPC-H数据库上运行多个查询,展示NDP和PQ如何提升查询效率。
测试环境:
- 上海-1区域的华为云GuassDB (for MySQL)
- CPU:16个,内存:64GB,缓冲池大小:20GB
- 将join_buffer_size 和 sort_buffer_size增加到1MB,因为这两个缓冲区对于哈希连接和排序的性能很重要
- PQ并发度设置为16
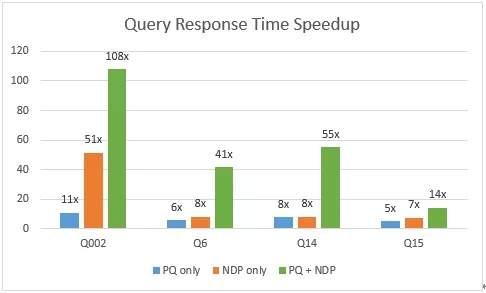
下图的y轴显示查询响应时间加速因子。加速因子定义:如果原始查询时间为100秒,而启用PQ后,查询时间变为50秒,则加速因子应为2。
从下面的测试结果可以看出, NDP+PQ将Q002加速了100多倍。
NDP将数据库节点和存储节点解耦,这一特性将成为未来云原生数据库系统的一个标准。大型扫描在OLAP工作负载中很常见,NDP将大大提升此类操作的效率。
综上所述,NDP可以:
- 减少网络带宽的使用量
- 降低网络IOPS
- 同时使用多个页数据存储来实现NDP并行处理
- 提高需要大表扫描的SQL查询的性能
- 降低数据库节点的CPU使用率,使数据库节点能够支持更多的OLTP工作负载

NDPQ(NDP+PQ),定义分布式数据库新方向的更多相关文章
- 全球分布式数据库:Google Spanner(论文翻译)
本文由厦门大学计算机系教师林子雨翻译,翻译质量很高,本人只对极少数翻译得不太恰当的地方进行了修改. [摘要]:Spanner 是谷歌公司研发的.可扩展的.多版本.全球分布式.同步复制数据库.它是第一个 ...
- 对话DDM:分布式数据库中间件全解析
进入云计算时代,传统的数据库在性能和容量等方面已无法满足企业的要求,随着数据量的不断骤增,易于扩展.拆分的数据库解决方案对于企业的云化转型更是显得尤为重要.为使企业应用上云更简单,分布式数据库中间件D ...
- 分布式数据库的四分结构设计 BCDE
首先,对关系型数据库的表进行四种分类定义: Basis 根基,Content 内容, Description 说明, Extension 扩展. Basis:Baisis 表是唯一的,为了实现标准而得 ...
- 分布式数据库中的Paxos 算法
分布式数据库中的Paxos 算法 http://baike.baidu.com/link?url=ChmfvtXRZQl7X1VmRU6ypsmZ4b4MbQX1pelw_VenRLnFpq7rMvY ...
- 【Java EE 学习 30】【闪回】【导入导出】【管理用户安全】【分布式数据库】【数据字典】【方案】
一.闪回 1.可能的误操作 (1)错误的删除了记录 (2)错误的删除了表 (3)查询历史记录 (4)撤销已经提交了的事务. 2.对应着以上四种类型的误操作,有四种闪回类型 (1)闪回表:将表回退到过去 ...
- 云时代的分布式数据库:阿里分布式数据库服务DRDS
发表于2015-07-15 21:47| 10943次阅读| 来源<程序员>杂志| 27 条评论| 作者王晶昱 <程序员>杂志数据库DRDS分布式沈询 摘要:伴随着系统性能.成 ...
- Cobar分布式数据库的应用与实践
最新文章:看我如何快速学习.Net(高可用数据采集平台).高并发数据采集的架构应用(Redis的应用) 问题点: 随着项目的增长,数据和数据表也成倍的增长,普通的单点数据库已经无法满足日常的增长的需要 ...
- 分布式数据库中间件–(2) Cobar与client握手身份验证
Cobar启动完毕,监听特定端口.整个认证的流程图: NIOAcceptor类继承自Thread类,该类的对象会以线程的方式执行,进行连接的监听. NIOAcceptor启动的初始化步骤例如以下: 1 ...
- 在分布式数据库中CAP原理CAP+BASE
本篇博文的内容均来源于网络,本人只是整理,仅供学习! 一.关系型数据库 关系型数据库遵循ACID规则 事务在英文中是transaction,和现实世界中的交易很类似,它有如下四个特性: 1.A (At ...
- 利用C#实现分布式数据库查询
随着传统的数据库.计算机网络和数字通信技术的飞速发展,以数据分布存储和分布处理为主要特征的分布式数据库系统的研究和开发越来越受到人们的关注.但由于其开发较为复杂,在一定程度上制约了它的发展.基于此,本 ...
随机推荐
- CF1610B [Kalindrome Array]
Problem 题目简述 给你一个数列 \(a\),有这两种情况,这个数列是「可爱的」. 它本身就是回文的. 定义变量 \(x\),满足:序列 \(a\) 中所有值等于 \(x\) 的元素删除之后,它 ...
- C++11 列表初始化都做了什么?
类的成员变量的初始化细节 首先,来看两个问题: 类的构造函数中,成员变量的列表初始化是如何实现的? 为什么列表初始化效率上优于在构造函数中为成员变量赋值? (后文中,将 "在构造函数中为成员 ...
- go 中如何实现定时任务
定时任务简介 定时任务是指按照预定的时间间隔或特定时间点自动执行的计划任务或操作.这些任务通常用于自动化重复性的工作,以减轻人工操作的负担,提高效率.在计算机编程和应用程序开发中,定时任务是一种常见的 ...
- 【教程】cpp转python Nanobind 实践 加速轻量版 pythonbind11
主要是尝试一下把c++这边的函数封装打包给python用,选择nanobind的原因是:1. 优化速度快,2. 生成二进制包小,不过pythonbind11是更为广泛知道的,nanobind也是pyt ...
- Shell必备三剑客
Top 目录 Sed--三剑客之一 基本格式 选项及含义 命令flags标记及功能 支持正则表达式, 扩展正则表达式 高级命令 命令格式 注意: 命令示例 字符串替换----'s' 行内容替换--'c ...
- 浮点类型(double与float及其它们的输入输出)
<1>浮点类型 (1)两种类型 double 字长64位(8个字节),有效数字15,范围大概为2.2* 10^-308 ~ 1.79*10^308,0,nan; float字长32位(4个 ...
- Web前端工程的装机必备软件
前言 最近作者的电脑 C 盘变红了,这让我很难受(有点小强迫症),所以准备重新安装下系统,顺便把 C 盘扩大点. 注意: 操作系统是 windows 11 23H2. 所有的命令行都是使用 Windo ...
- SpringCore完整学习教程7,入门级别
本章可以说是完结,下一章可能讲kotlin+springboot 本章从第九章开始: 9. Creating Your Own Auto-configuration 如果您在开发共享库的公司工作,或者 ...
- 使用IDEA2022.3创建web工程~
为什么突然记录这么一篇博客呢? 以前都是用2019IDEA的,突然换成了IDEA2022懵逼了,所以记录一下~ 具体步骤 1.创建一个新的Project 2.注意选择BuildSystem 3.在当前 ...
- VMware安装虚拟机详细步骤
在VMware中安装CentOS7 01.目录 CentOS7的下载 CentOS7的配置 CentOS7的安装 CentOS7的网络配置 自动获取IP 固定获取IP 02.安装前提 准备工作: 提前 ...