pytorch不像TensorFlow那样有专用的文件存储格式真的是不足吗?pytorch该如何处理大量小文件的读取呢?
偶然发现前文:
【转载】 PyTorch下训练数据小文件转大文件读写(附有各种存储格式对比)
在谈论pytorch的文件读取问题,因为以前是搞TensorFlow的,后来由于编写效率和生态环境问题转为了pytorch,但是同时也发现pytorch不像TensorFlow那样有专用的文件存储格式,因为官方给出的宣传是专用存储格式可以很好提高文件读取性能,那么这样说来pytorch在训练数据集的文件读取上一定不如TensorFlow使用专用格式了???
带着这个疑问搞了些研究,最后得到了意料之外的答案。
==================================================================
背景介绍:
测试的数据集选择为ImageNet2012的数据集。
数据集大小:(压缩状态)

数据集大小:(解压状态)
实验硬件:
A电脑:i7-8600 CPU 16G内存
B电脑:intel 自强gold 双路CPU 500G内存
==========================================
使用官方代码进行读取测试:


import argparse
import multiprocessing
from math import ceil
import torch
from torch.utils import data
from torchvision import datasets, transforms class FiniteRandomSampler(data.Sampler):
def __init__(self, data_source, num_samples):
super().__init__(data_source)
self.data_source = data_source
self.num_samples = num_samples def __iter__(self):
return iter(torch.randperm(len(self.data_source)).tolist()[: self.num_samples]) def __len__(self):
return self.num_samples class RunningAverage:
def __init__(self, num_channels=3, **meta):
self.num_channels = num_channels
self.avg = torch.zeros(num_channels, **meta) self.num_samples = 0 def update(self, vals):
batch_size, num_channels = vals.size() if num_channels != self.num_channels:
raise RuntimeError updated_num_samples = self.num_samples + batch_size
correction_factor = self.num_samples / updated_num_samples updated_avg = self.avg * correction_factor
updated_avg += torch.sum(vals, dim=0) / updated_num_samples self.avg = updated_avg
self.num_samples = updated_num_samples def tolist(self):
return self.avg.detach().cpu().tolist() def __str__(self):
return "[" + ", ".join([f"{val:.3f}" for val in self.tolist()]) + "]" def make_reproducible(seed):
torch.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False def main(args): transform = transforms.Compose(
[transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor()]
)
dataset = datasets.ImageNet(args.root, split="train", transform=transform) loader = data.DataLoader(
dataset,
shuffle=True,
num_workers=args.num_workers,
batch_size=args.batch_size,
) num_batches = ceil(len(dataset) / args.batch_size) with torch.no_grad():
for batch, (images, _) in enumerate(loader, 1): #if not args.quiet and batch % args.print_freq == 0:
if batch%100==0:
print(
(
f"[{batch:6d}/{num_batches}] "
)
) def parse_input():
parser = argparse.ArgumentParser(
description="Calculation of ImageNet z-score parameters"
)
parser.add_argument("root", help="path to ImageNet dataset root directory")
parser.add_argument(
"--num-samples",
metavar="N",
type=int,
default=None,
help="Number of images used in the calculation. Defaults to the complete dataset.",
)
parser.add_argument(
"--num-workers",
metavar="N",
type=int,
default=None,
help="Number of workers for the image loading. Defaults to the number of CPUs.",
)
parser.add_argument(
"--batch-size",
metavar="N",
type=int,
default=None,
help="Number of images processed in parallel. Defaults to the number of workers",
)
parser.add_argument(
"--device",
metavar="DEV",
type=str,
default=None,
help="Device to use for processing. Defaults to CUDA if available.",
)
parser.add_argument(
"--seed",
metavar="S",
type=int,
default=None,
help="If given, runs the calculation in deterministic mode with manual seed S.",
)
parser.add_argument(
"--print_freq",
metavar="F",
type=int,
default=50,
help="Frequency with which the intermediate results are printed. Defaults to 50.",
)
parser.add_argument(
"--quiet",
action="store_true",
help="If given, only the final results is printed",
) args = parser.parse_args() if args.num_workers is None:
args.num_workers = multiprocessing.cpu_count() if args.batch_size is None:
args.batch_size = args.num_workers if args.device is None:
device = "cuda" if torch.cuda.is_available() else "cpu"
args.device = torch.device(device) return args if __name__ == "__main__":
args = parse_input()
main(args)
保存为y.py
命令:
python y.py .
其中 . 指 ILSVRC2012_img_train.tar 所在目录。
===========================
B服务器首次执行:


B服务器非首次执行:
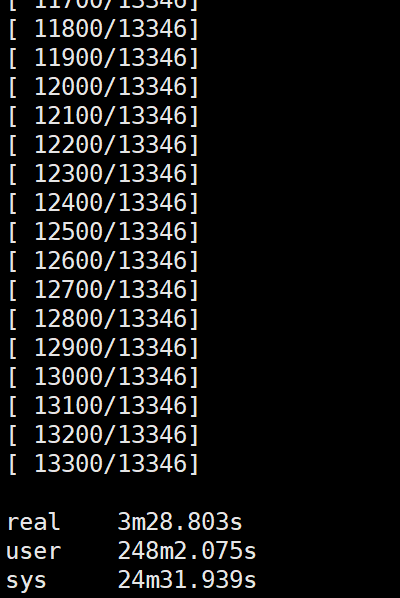
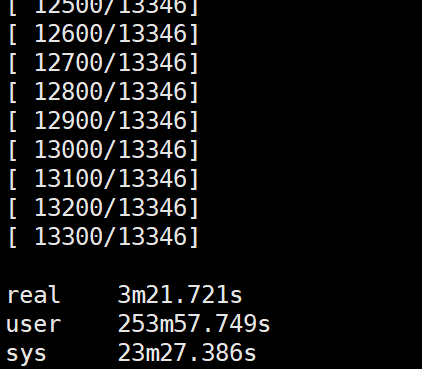

由于B服务器内存很大,足够将所有数据全部存入到内存中,首次执行是将所有图片从硬盘读到内存中,其中应用程序内存空间不对这些图片进行保存,而系统内核对这些图片进行缓存,首次执行后所有图片数据全部保存在内核的缓存数据中,所以非首次执行可以极大的加快读取速度,因为此时的数据不是从硬盘中读取而是从内存的缓存空间中读取。
===================================
使用A电脑首次执行:
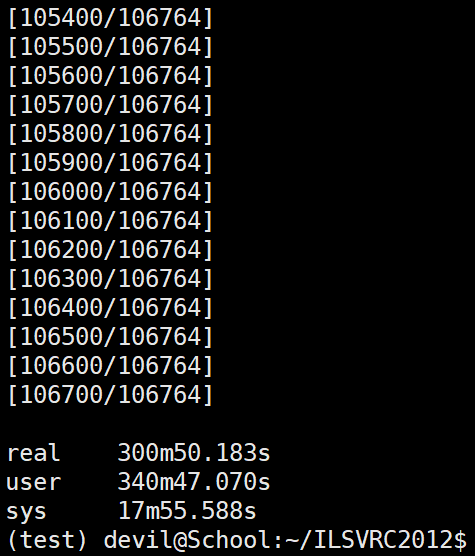
使用A电脑非首次执行:
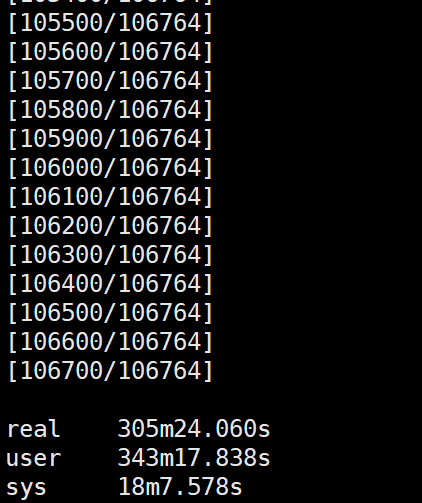
可以看到A电脑不论是不是首次执行需要的时间都大致相同,且时间较长。
原因:
A电脑内存空间较小,所以图片无法全部装入到内存的缓存空间中,所以执行图片读取操作时会频繁的进行页面置换,换句话说A电脑执行读取操作基本上可以认为是每次读取都是从硬盘空间导入的,而且A电脑仅有的内存空间也会被缓存消耗掉,但是消耗的内存中的缓存并不能满足图片读取的需求,从而导致图片读取引起内存缺页,从硬盘中读取图片,而内存中仅有的空间还被缓存暂具,从而加重系统的竞争。
=================================================================
那么大内存的电脑除了首次读取图片需要从硬盘加载其他都是直接从内存读取,这样的话其实是否使用专用的数据文件格式并不会有太大的性能影响。那么对于内存的电脑来说是不是专用的数据文件格式会提高性能呢?
为此,编写下面代码,实现小图片的大文件整合,将小图片写入二进制文件中:
from PIL import Image
import numpy as np from typing import Any, Callable, cast, Dict, List, Optional, Tuple
import os
import pickle IMG_EXTENSIONS = ('.jpg', '.jpeg', '.png', '.ppm', '.bmp', '.pgm', '.tif', '.tiff', '.webp') def has_file_allowed_extension(filename: str, extensions: Tuple[str, ...]) -> bool:
"""Checks if a file is an allowed extension. Args:
filename (string): path to a file
extensions (tuple of strings): extensions to consider (lowercase) Returns:
bool: True if the filename ends with one of given extensions
"""
return filename.lower().endswith(extensions) def is_image_file(filename: str) -> bool:
"""Checks if a file is an allowed image extension. Args:
filename (string): path to a file Returns:
bool: True if the filename ends with a known image extension
"""
return has_file_allowed_extension(filename, IMG_EXTENSIONS) def find_classes(directory: str) -> Tuple[List[str], Dict[str, int]]:
"""Finds the class folders in a dataset. See :class:`DatasetFolder` for details.
"""
classes = sorted(entry.name for entry in os.scandir(directory) if entry.is_dir())
if not classes:
raise FileNotFoundError(f"Couldn't find any class folder in {directory}.") class_to_idx = {cls_name: i for i, cls_name in enumerate(classes)}
return classes, class_to_idx def get_path_classIdx(directory, class_to_idx):
instances = []
available_classes = set()
for target_class in sorted(class_to_idx.keys()):
class_index = class_to_idx[target_class]
target_dir = os.path.join(directory, target_class)
if not os.path.isdir(target_dir):
continue
for root, _, fnames in sorted(os.walk(target_dir, followlinks=True)):
for fname in sorted(fnames):
if is_image_file(fname):
path = os.path.join(root, fname)
item = path, class_index
instances.append(item) if target_class not in available_classes:
available_classes.add(target_class) empty_classes = set(class_to_idx.keys()) - available_classes
if empty_classes:
msg = f"Found no valid file for the classes {', '.join(sorted(empty_classes))}. "
raise FileNotFoundError(msg) return instances def pil_loader(path: str) -> Image.Image:
# open path as file to avoid ResourceWarning (https://github.com/python-pillow/Pillow/issues/835)
with open(path, 'rb') as f:
img = Image.open(f)
return img.convert('RGB') def png_loader(path: str):
# open path as file to avoid ResourceWarning (https://github.com/python-pillow/Pillow/issues/835)
with open(path, 'rb') as f:
return f.read() ########################################################### directory = "/home/devil/ILSVRC2012/train"
data_file_path = "/media/devil/数据/data.dat"
target_file_path = "/media/devil/数据/target.dat" def train_data_pickle(instances, data_file, target_file):
# instances = instances[:10000]
loc = 0
infos = [] L = len(instances)
for i, (path, target_idx) in enumerate(instances, 1):
img = np.array(pil_loader(path))
# print(img.dtype, img.shape, target_idx)
a, b, c = img.shape
data_file.write(img.flatten())
infos.append((a,b,c,loc,target_idx)) loc += a*b*c if i%1000 == 0:
print("{} / {}".format(i, L)) pickle.dump(infos, target_file) def train_data_pickle_png(instances, data_file, target_file):
loc = 0
infos = [] L = len(instances)
for i, (path, target_idx) in enumerate(instances, 1):
img = png_loader(path)
# img = np.array(pil_loader(path))
# print(img.dtype, img.shape, target_idx)
# a, b, c = img.shape
# data_file.write(img.flatten())
# infos.append((a,b,c,loc,target_idx))
img_size = data_file.write(img)
infos.append((loc, img_size, target_idx)) loc += img_size if i%1000 == 0:
print("{} / {}".format(i, L)) pickle.dump(infos, target_file) def main():
classes, class_to_idx = find_classes(directory) if not class_to_idx:
raise ValueError("'class_to_index' must have at least one entry to collect any samples.") instances = get_path_classIdx(directory, class_to_idx) data_file = open(data_file_path, 'wb')
target_file = open(target_file_path, 'wb') # train_data_pickle(instances, data_file, target_file)
train_data_pickle_png(instances, data_file, target_file) data_file.close()
target_file.close() if __name__ == "__main__":
main()
验证写入的二进制文件是否正常,读取的数据与小文件中读取的数据是否相同:
from PIL import Image
import numpy as np from typing import Any, Callable, cast, Dict, List, Optional, Tuple
import os
import pickle
from io import BytesIO ########################################################### directory = "/home/devil/ILSVRC2012/train"
data_file_path = "/media/devil/数据/data.dat"
target_file_path = "/media/devil/数据/target.dat"
root = "/home/devil/ILSVRC2012" def main():
data_file = open(data_file_path, 'rb')
target_file = open(target_file_path, 'rb')
infos = pickle.load(target_file) def get_img_target(indexId):
a,b,c,loc,target_idx = infos[indexId]
data_file.seek(loc)
img = np.frombuffer(data_file.read(a*b*c), np.uint8).reshape(a,b,c)
return img, target_idx def get_png_target(indexId):
loc, png_size, target_idx = infos[indexId]
data_file.seek(loc)
img = data_file.read(png_size) return img, target_idx from torchvision import datasets
dataset = datasets.ImageNet(root, split="train")
false_count_img = 0
false_count_target = 0
for i in range(len(dataset)):
true_img, true_target = dataset[i]
true_img = np.array(true_img)
true_target = int(true_target) # false_img, false_target = get_img_target(i)
false_img, false_target = get_png_target(i)
false_img = Image.open(BytesIO(false_img))
# false_img = np.asarray(false_img, np.uint8) if not np.all(true_img==false_img):
false_count_img += 1
if not (true_target==false_target):
false_count_target += 1 if i%9999 == 1:
print("{} / {}".format(i, len(dataset)), false_count_img, false_count_target) if __name__ == "__main__":
main()
数据的读取测试代码:
为图方便直接修改库代码:
修改文件:
~anaconda3/envs/test/lib/python3.7/site-packages/torchvision/datasets/folder.py
修改后的整体文件代码:
from .vision import VisionDataset from PIL import Image
from io import BytesIO
import pickle
import numpy as np
import cv2 import os
import os.path
from typing import Any, Callable, cast, Dict, List, Optional, Tuple def has_file_allowed_extension(filename: str, extensions: Tuple[str, ...]) -> bool:
"""Checks if a file is an allowed extension. Args:
filename (string): path to a file
extensions (tuple of strings): extensions to consider (lowercase) Returns:
bool: True if the filename ends with one of given extensions
"""
return filename.lower().endswith(extensions) def is_image_file(filename: str) -> bool:
"""Checks if a file is an allowed image extension. Args:
filename (string): path to a file Returns:
bool: True if the filename ends with a known image extension
"""
return has_file_allowed_extension(filename, IMG_EXTENSIONS) def find_classes(directory: str) -> Tuple[List[str], Dict[str, int]]:
"""Finds the class folders in a dataset. See :class:`DatasetFolder` for details.
"""
classes = sorted(entry.name for entry in os.scandir(directory) if entry.is_dir())
if not classes:
raise FileNotFoundError(f"Couldn't find any class folder in {directory}.") class_to_idx = {cls_name: i for i, cls_name in enumerate(classes)}
return classes, class_to_idx def make_dataset(
directory: str,
class_to_idx: Optional[Dict[str, int]] = None,
extensions: Optional[Tuple[str, ...]] = None,
is_valid_file: Optional[Callable[[str], bool]] = None,
) -> List[Tuple[str, int]]:
"""Generates a list of samples of a form (path_to_sample, class). See :class:`DatasetFolder` for details. Note: The class_to_idx parameter is here optional and will use the logic of the ``find_classes`` function
by default.
"""
directory = os.path.expanduser(directory) if class_to_idx is None:
_, class_to_idx = find_classes(directory)
elif not class_to_idx:
raise ValueError("'class_to_index' must have at least one entry to collect any samples.") both_none = extensions is None and is_valid_file is None
both_something = extensions is not None and is_valid_file is not None
if both_none or both_something:
raise ValueError("Both extensions and is_valid_file cannot be None or not None at the same time") if extensions is not None: def is_valid_file(x: str) -> bool:
return has_file_allowed_extension(x, cast(Tuple[str, ...], extensions)) is_valid_file = cast(Callable[[str], bool], is_valid_file) instances = []
available_classes = set()
for target_class in sorted(class_to_idx.keys()):
class_index = class_to_idx[target_class]
target_dir = os.path.join(directory, target_class)
if not os.path.isdir(target_dir):
continue
for root, _, fnames in sorted(os.walk(target_dir, followlinks=True)):
for fname in sorted(fnames):
if is_valid_file(fname):
path = os.path.join(root, fname)
item = path, class_index
instances.append(item) if target_class not in available_classes:
available_classes.add(target_class) empty_classes = set(class_to_idx.keys()) - available_classes
if empty_classes:
msg = f"Found no valid file for the classes {', '.join(sorted(empty_classes))}. "
if extensions is not None:
msg += f"Supported extensions are: {', '.join(extensions)}"
raise FileNotFoundError(msg) return instances class DatasetFolder(VisionDataset):
"""A generic data loader. This default directory structure can be customized by overriding the
:meth:`find_classes` method. Args:
root (string): Root directory path.
loader (callable): A function to load a sample given its path.
extensions (tuple[string]): A list of allowed extensions.
both extensions and is_valid_file should not be passed.
transform (callable, optional): A function/transform that takes in
a sample and returns a transformed version.
E.g, ``transforms.RandomCrop`` for images.
target_transform (callable, optional): A function/transform that takes
in the target and transforms it.
is_valid_file (callable, optional): A function that takes path of a file
and check if the file is a valid file (used to check of corrupt files)
both extensions and is_valid_file should not be passed. Attributes:
classes (list): List of the class names sorted alphabetically.
class_to_idx (dict): Dict with items (class_name, class_index).
samples (list): List of (sample path, class_index) tuples
targets (list): The class_index value for each image in the dataset
""" def __init__(
self,
root: str,
loader: Callable[[str], Any],
extensions: Optional[Tuple[str, ...]] = None,
transform: Optional[Callable] = None,
target_transform: Optional[Callable] = None,
is_valid_file: Optional[Callable[[str], bool]] = None,
) -> None:
super(DatasetFolder, self).__init__(root, transform=transform,
target_transform=target_transform)
classes, class_to_idx = self.find_classes(self.root)
samples = self.make_dataset(self.root, class_to_idx, extensions, is_valid_file) self.loader = loader
self.extensions = extensions self.classes = classes
self.class_to_idx = class_to_idx
self.samples = samples
self.targets = [s[1] for s in samples] self.data_file_path = "/media/devil/数据/data.dat"
self.target_file_path = "/media/devil/数据/target.dat"
# self.data_file = open(self.data_file_path, 'rb')
self.target_file = open(self.target_file_path, 'rb')
self.infos = pickle.load(self.target_file) @staticmethod
def make_dataset(
directory: str,
class_to_idx: Dict[str, int],
extensions: Optional[Tuple[str, ...]] = None,
is_valid_file: Optional[Callable[[str], bool]] = None,
) -> List[Tuple[str, int]]:
"""Generates a list of samples of a form (path_to_sample, class). This can be overridden to e.g. read files from a compressed zip file instead of from the disk. Args:
directory (str): root dataset directory, corresponding to ``self.root``.
class_to_idx (Dict[str, int]): Dictionary mapping class name to class index.
extensions (optional): A list of allowed extensions.
Either extensions or is_valid_file should be passed. Defaults to None.
is_valid_file (optional): A function that takes path of a file
and checks if the file is a valid file
(used to check of corrupt files) both extensions and
is_valid_file should not be passed. Defaults to None. Raises:
ValueError: In case ``class_to_idx`` is empty.
ValueError: In case ``extensions`` and ``is_valid_file`` are None or both are not None.
FileNotFoundError: In case no valid file was found for any class. Returns:
List[Tuple[str, int]]: samples of a form (path_to_sample, class)
"""
if class_to_idx is None:
# prevent potential bug since make_dataset() would use the class_to_idx logic of the
# find_classes() function, instead of using that of the find_classes() method, which
# is potentially overridden and thus could have a different logic.
raise ValueError(
"The class_to_idx parameter cannot be None."
)
return make_dataset(directory, class_to_idx, extensions=extensions, is_valid_file=is_valid_file) def find_classes(self, directory: str) -> Tuple[List[str], Dict[str, int]]:
"""Find the class folders in a dataset structured as follows:: directory/
├── class_x
│ ├── xxx.ext
│ ├── xxy.ext
│ └── ...
│ └── xxz.ext
└── class_y
├── 123.ext
├── nsdf3.ext
└── ...
└── asd932_.ext This method can be overridden to only consider
a subset of classes, or to adapt to a different dataset directory structure. Args:
directory(str): Root directory path, corresponding to ``self.root`` Raises:
FileNotFoundError: If ``dir`` has no class folders. Returns:
(Tuple[List[str], Dict[str, int]]): List of all classes and dictionary mapping each class to an index.
"""
return find_classes(directory) def __getitem__(self, index: int) -> Tuple[Any, Any]:
"""
Args:
index (int): Index Returns:
tuple: (sample, target) where target is class_index of the target class.
"""
# path, target = self.samples[index] loc, png_size, target_idx = self.infos[index]
# print(loc, png_size, target_idx) data_file = open(self.data_file_path, 'rb')
data_file.seek(loc)
img = data_file.read(png_size)
data_file.close() # print(img)
# img = np.asarray(Image.open(BytesIO(img)), np.uint8)
img = Image.open(BytesIO(img)).convert('RGB')
# f_array_bytes = np.frombuffer(img, np.uint8)
# img = cv2.cvtColor(cv2.imdecode(f_array_bytes, cv2.IMREAD_COLOR), cv2.COLOR_BGR2RGB) if self.transform is not None:
img = self.transform(img)
if self.target_transform is not None:
target_idx = self.target_transform(target_idx) return img, target_idx """
sample = self.loader(path)
if self.transform is not None:
sample = self.transform(sample)
if self.target_transform is not None:
target = self.target_transform(target) return sample, target
""" def __len__(self) -> int:
# return len(self.samples)
return len(self.infos) IMG_EXTENSIONS = ('.jpg', '.jpeg', '.png', '.ppm', '.bmp', '.pgm', '.tif', '.tiff', '.webp') def pil_loader(path: str) -> Image.Image:
# open path as file to avoid ResourceWarning (https://github.com/python-pillow/Pillow/issues/835)
with open(path, 'rb') as f:
img = Image.open(f)
return img.convert('RGB') # TODO: specify the return type
def accimage_loader(path: str) -> Any:
import accimage
try:
return accimage.Image(path)
except IOError:
# Potentially a decoding problem, fall back to PIL.Image
return pil_loader(path) def default_loader(path: str) -> Any:
from torchvision import get_image_backend
if get_image_backend() == 'accimage':
return accimage_loader(path)
else:
return pil_loader(path) class ImageFolder(DatasetFolder):
"""A generic data loader where the images are arranged in this way by default: :: root/dog/xxx.png
root/dog/xxy.png
root/dog/[...]/xxz.png root/cat/123.png
root/cat/nsdf3.png
root/cat/[...]/asd932_.png This class inherits from :class:`~torchvision.datasets.DatasetFolder` so
the same methods can be overridden to customize the dataset. Args:
root (string): Root directory path.
transform (callable, optional): A function/transform that takes in an PIL image
and returns a transformed version. E.g, ``transforms.RandomCrop``
target_transform (callable, optional): A function/transform that takes in the
target and transforms it.
loader (callable, optional): A function to load an image given its path.
is_valid_file (callable, optional): A function that takes path of an Image file
and check if the file is a valid file (used to check of corrupt files) Attributes:
classes (list): List of the class names sorted alphabetically.
class_to_idx (dict): Dict with items (class_name, class_index).
imgs (list): List of (image path, class_index) tuples
""" def __init__(
self,
root: str,
transform: Optional[Callable] = None,
target_transform: Optional[Callable] = None,
loader: Callable[[str], Any] = default_loader,
is_valid_file: Optional[Callable[[str], bool]] = None,
):
super(ImageFolder, self).__init__(root, loader, IMG_EXTENSIONS if is_valid_file is None else None,
transform=transform,
target_transform=target_transform,
is_valid_file=is_valid_file)
self.imgs = self.samples
数据读取代码与之前相同:
import argparse
import multiprocessing
from math import ceil
import torch
from torch.utils import data
from torchvision import datasets, transforms class FiniteRandomSampler(data.Sampler):
def __init__(self, data_source, num_samples):
super().__init__(data_source)
self.data_source = data_source
self.num_samples = num_samples def __iter__(self):
return iter(torch.randperm(len(self.data_source)).tolist()[: self.num_samples]) def __len__(self):
return self.num_samples class RunningAverage:
def __init__(self, num_channels=3, **meta):
self.num_channels = num_channels
self.avg = torch.zeros(num_channels, **meta) self.num_samples = 0 def update(self, vals):
batch_size, num_channels = vals.size() if num_channels != self.num_channels:
raise RuntimeError updated_num_samples = self.num_samples + batch_size
correction_factor = self.num_samples / updated_num_samples updated_avg = self.avg * correction_factor
updated_avg += torch.sum(vals, dim=0) / updated_num_samples self.avg = updated_avg
self.num_samples = updated_num_samples def tolist(self):
return self.avg.detach().cpu().tolist() def __str__(self):
return "[" + ", ".join([f"{val:.3f}" for val in self.tolist()]) + "]" def make_reproducible(seed):
torch.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False def main(args): transform = transforms.Compose(
[transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor()]
)
dataset = datasets.ImageNet(args.root, split="train", transform=transform) loader = data.DataLoader(
dataset,
shuffle=True,
num_workers=args.num_workers,
batch_size=args.batch_size,
) num_batches = ceil(len(dataset) / args.batch_size) with torch.no_grad():
for batch, (images, _) in enumerate(loader, 1): #if not args.quiet and batch % args.print_freq == 0:
if batch%100==0:
print(
(
f"[{batch:6d}/{num_batches}] "
)
) def parse_input():
parser = argparse.ArgumentParser(
description="Calculation of ImageNet z-score parameters"
)
parser.add_argument("root", help="path to ImageNet dataset root directory")
parser.add_argument(
"--num-samples",
metavar="N",
type=int,
default=None,
help="Number of images used in the calculation. Defaults to the complete dataset.",
)
parser.add_argument(
"--num-workers",
metavar="N",
type=int,
default=None,
help="Number of workers for the image loading. Defaults to the number of CPUs.",
)
parser.add_argument(
"--batch-size",
metavar="N",
type=int,
default=None,
help="Number of images processed in parallel. Defaults to the number of workers",
)
parser.add_argument(
"--device",
metavar="DEV",
type=str,
default=None,
help="Device to use for processing. Defaults to CUDA if available.",
)
parser.add_argument(
"--seed",
metavar="S",
type=int,
default=None,
help="If given, runs the calculation in deterministic mode with manual seed S.",
)
parser.add_argument(
"--print_freq",
metavar="F",
type=int,
default=50,
help="Frequency with which the intermediate results are printed. Defaults to 50.",
)
parser.add_argument(
"--quiet",
action="store_true",
help="If given, only the final results is printed",
) args = parser.parse_args() if args.num_workers is None:
args.num_workers = multiprocessing.cpu_count() if args.batch_size is None:
args.batch_size = args.num_workers if args.device is None:
device = "cuda" if torch.cuda.is_available() else "cpu"
args.device = torch.device(device) return args if __name__ == "__main__":
args = parse_input()
main(args)
执行: python y.py +数据文件目录
执行性能:大约5小时

由于时间原因没有全部跑完,不过可以知道其运行时间不会好于从小文件中读取的性能。
=========================================================
总结:
在文件读取操作中,大文件性能和小文件性能只有在首次读取时候会有性能区别,如果电脑内存主机足够大的话首次从大文件读取数据要比小文件中读取性能要好一些,不过这也只是在首次读取过程中,而且应该不会有太明显差别,因为即使是大数据我们读取的时候也是随机读取(shuffle模式)。如果主机内存不够的话需要频繁的读取硬盘的话首次读取和非首次读取性能基本一致。
总的来说,在训练神经网络模型时影响文件读取速度并不是文件的存储格式,大文件和小文件并不会明显的提高读取性能,基本上可以认为是一致的,即使是大内存主机首次读取时也不会有显著差距。而真正影响训练集数据的读取速度的真正的关键因素其实是内存大小。
个人分析专用数据文件格式最大的好处是节省硬盘空间,如文中图片显示压缩数据包大约为147.9G左右大小,解压后占294.9G左右大小,而使用专用数据文件格式(单个大文件),占硬盘空间不会比压缩数据包差别太多,个人计算后发现其大小反而有了略微下降:
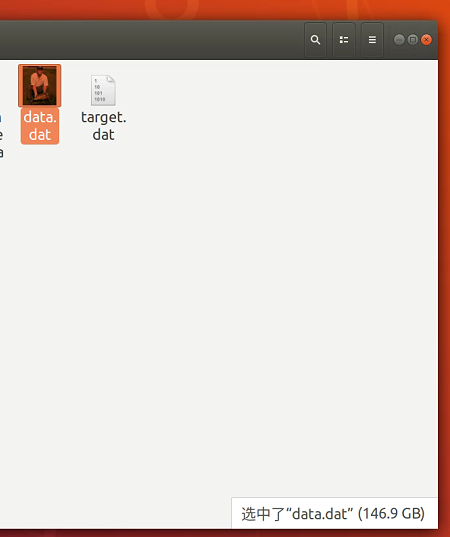
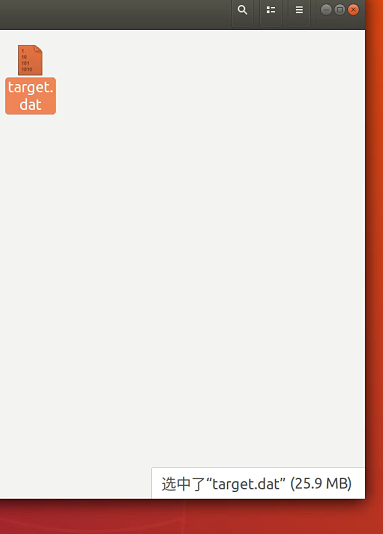
后话:
有时候不能只听宣传,真实的上手搞一搞就知道到底哪个是对的了。
pytorch没有专用数据文件格式除了占硬盘空间外一点也不影响读取性能,综合考虑pytorch不使用专用数据文件格式完全OK 。官方给出的小文件读取方式完全OK 。
------------------------------------------------------------------------
补充:
A电脑在读取大文件的实验中最后性能:
可以看到在A电脑中最后的大文件读取性能不如小文件的读取性能,个人推测原因是同样内存中无法进行缓存的情况下大文件的打开更加的耗费时间,同样频繁的打开文件小文件更加有优势,在A电脑中内存空间太小导致磁盘寻址的读取性能并不会对实验最后结果有太大影响,主要因素还是电脑无法有效缓存数据。
----------------------------------------------------------------------------
pytorch不像TensorFlow那样有专用的文件存储格式真的是不足吗?pytorch该如何处理大量小文件的读取呢?的更多相关文章
- Google的TensorFlow,微软CNTK, Amazon 的MxNet,Facebook 的Caffe2, PyTorch,国内百度的PaddlePaddle
深度学习框架竞争很激烈,而且看上去都是业界巨头在玩. 老师木:是的.一个深度学习框架一旦像Hadoop那样成为事实工业标准,就占据了人工智能各种关键应用的入口,对各类垂直应用,基于私有部署的技术服务, ...
- 如何用Tensorflow训练模型成pb文件和和如何加载已经训练好的模型文件
这篇薄荷主要是讲了如何用tensorflow去训练好一个模型,然后生成相应的pb文件.最后会将如何重新加载这个pb文件. 首先先放出PO主的github: https://github.com/ppp ...
- Ubuntu 16.04上源码编译和安装pytorch教程,并编写C++ Demo CMakeLists.txt | tutorial to compile and use pytorch on ubuntu 16.04
本文首发于个人博客https://kezunlin.me/post/54e7a3d8/,欢迎阅读最新内容! tutorial to compile and use pytorch on ubuntu ...
- 【PyTorch】PyTorch使用LMDB数据库加速文件读取
PyTorch使用LMDB数据库加速文件读取 原始文档:https://www.yuque.com/lart/ugkv9f/hbnym1 对于数据库的了解较少,文章中大部分的介绍主要来自于各种博客和L ...
- Google 云计算中的 GFS 体系结构
google 公司的很多业务具有数据量巨大的特点,为此,google 公司研发了云计算技术.google 云计 算结构中的 google 文件系统是其云计算技术中的三大法宝之一.本文主要介 ...
- oracle 学习
一.数据库语言部分1. SQL语言:关系数据库的标准语言2. PL/SQL:过程化语言Procedural Language3. SQL*Plus:简单的报表,操作系统接口 4. Oracle 8.0 ...
- [大牛翻译系列]Hadoop(17)MapReduce 文件处理:小文件
5.1 小文件 大数据这个概念似乎意味着处理GB级乃至更大的文件.实际上大数据可以是大量的小文件.比如说,日志文件通常增长到MB级时就会存档.这一节中将介绍在HDFS中有效地处理小文件的技术. 技术2 ...
- 如何将位图格式图片文件(.bmp)生成geotiff格式图片?
一.位图格式信息 位图BITMAPINFOHEADER 与BITMAPFILEHEADER: 先来看BITMAPINFOHEADER,只写几个主要的 biSize包含的是这个结构体的大小(包括颜色表) ...
- 网络基础tcp/ip协议五
传输层的作用: ip层提供点到点的链接. 传输层提供端到端的链接. 传输层的协议: TCP: 传输控制协议可靠的,面向链接的协议,传输效率低. UDP: 用户数据报协议,不可靠,无连接的服务,传输效率 ...
- Hadoop就业面试题
----------------------------------------------------------------------------- [申明:资料来源于互联网] 本文链接:htt ...
随机推荐
- ChatGPT应用与实践初探
近期,长江商学院EMBA38期&甄知科技开展了题为"ChatGPT应用与实践初探"的线下沙龙活动,由上海甄知科技创始合伙人兼CTO张礼军主讲,主要给大家解密最近很火的Cha ...
- 从 Modbus 到 Web 数据可视化之 WebSocket 实时消息
前言 工业物联网是一个范围很大的概念,本文从数据可视化的角度介绍了一个最小化的工业物联网平台,从 Modbus 数据采集到前端数据可视化呈现的基本实现思路.这里面主要涉及基于 Modbus 通讯规约的 ...
- js-对象创建
哥被逼得要当全栈工程师,今天练习了下各种对象的创建方式.代码较多参考了https://www.cnblogs.com/ImmortalWang/p/10517091.html 为了方便测试,整合了一个 ...
- VSCode因网络问题导致下载更新/扩展出错
VSCode因网络问题导致下载更新/扩展出错 可尝试方法: 问题0: VSCode出现网络问题排查方法? 法1: 启动时加上选项 --log-net-log=netlog.json ...
- 设备树DTS 学习:学习总结(应用篇)
设备树DTS 学习:学习总结(应用篇) 背景 经过前几章的学习,我们可以说是掌握了设备树的基础用法,现在作为总结回顾. 1.设备树DTS 学习:有关概念 介绍了什么是设备树,设备树的作用,如何编译设备 ...
- 全志T113-i+玄铁HiFi4开发板硬件说明书(2)
前 言 本文档主要介绍开发板硬件接口资源以及设计注意事项等内容,测试板卡为全志T113-i+玄铁HiFi4开发板,由于篇幅问题,本篇文章共分为上下两集,点击账户可查看更多内容详情,开发问题欢迎留言,感 ...
- Hadoop集群管理之fsimage和edits工作机制
客户端对hdfs进行写文件时会首先被记录在edits文件中. edits修改时元数据也会更新. 每次hdfs更新时edits先更新后客户端才会看到最新信息. fsimage:是namenode中关于元 ...
- PHP转Go系列 | ThinkPHP与Gin框架之API接口签名设计实践
大家好,我是码农先森. 回想起以前用模版渲染数据的岁月,那时都没有 API 接口开发的概念.PHP 服务端和前端 HTML.CSS.JS 代码混合式开发,也不分前端.后端程序员,大家都是全干工程师.随 ...
- PS工具的基本使用
常见的图片格式: 切片工具的使用 1.用切片选中图片 2.导出切片 3.切片悬着工具 可以选择指定 切片框 删除. 点击图层 切图 清除切片 基于参考线的切片 切图插件Cutterman
- 【PHP】关于fastadmin框架中使用with进行连表查询时setEagerlyType字段的理解
前言 FastAdmin是我第一个接触的后台管理系统框架.FastAdmin是一款开源且免费商用的后台开发框架,它基于ThinkPHP和Bootstrap两大主流技术构建的极速后台开发框架,它有着非常 ...