INFINI Labs 产品更新 | Gateway 支持基于 Kafka 的复制能力,发布 Helm Charts 部署方式

INFINI Labs 产品又更新啦~。本次更新概要如下:Easysearch 新增了索引字段相关统计 API,优化了 source_reuse 提升压缩效率;Gateway 新增诸多新特性,如:支持基于 Kafka 的复制能力,添加可插拔的分布式锁实现,新增 CPU 资源限制等功能;Console 本次主要优化了数据迁移功能,迁移任务详情页新增了若干指标图和日志查看等功能。
欢迎大家下载使用和反馈。
INFINI Helm Charts v0.1.0
INFINI Helm Charts 是一组 Kubernetes 部署包管理工具。基于 Helm Charts,我们将 INFINI Labs 旗下相关产品预先配置好程序资源包,大大简化了部署流程。Github 仓库地址:https://github.com/infinilabs/helm-charts。
Helm Charts 本次更新如下:
Features
- 添加 Console Chart
- 添加 Easysearch Chart,支持单节点以及多节点(节点角色可配置)部署
部署视频演示:
博客文章:
INFINI Easysearch v1.6.0
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。
Easysearch 本次更新如下:
Features
- 新增 _field_usage_stats API,统计索引每个字段的访问次数
- 新增 _disk_usage API,可以分析指定索引每个字段的磁盘占用大小
- 增加 flattened 类型,将 JSON 对象作为字符串处理,可以减少嵌套 JSON 型的文档的大小
Improvements
- source_reuse 增加对 _source 中数字类型的值进行复用压缩,可进一步降低 _source 磁盘占用
- 改进 source_reuse 筛选字段的逻辑
INFINI Gateway v1.18.0
INFINI Gateway 是一个面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway 可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
Gateway 本次更新如下:
Breaking changes
- 彻底移除了 request_body_truncate 和 response_body_truncate 过滤器
Features
- 支持基于 Kafka 的复制能力
- 在请求上下文中添加 _util.generate_uuid
- 在请求上下文中添加 _util.increment_id.BUCKET_NAME
- 在 Pipeline 配置中添加 singleton,防止多个 Pipeline 同时运行
- 添加可插拔的分布式锁实现
- 添加通用应用程序的 preference 配置
- 泛化队列抽象,重构磁盘队列,完善 Kafka 实现
- 添加 merge_to_bulk 处理器, 废弃 indexing_merge 处理器
- 添加 flow_replay 处理器,废弃 flow_runner 处理器
- 为复制场景添加 replication_correlation
- 添加 hash_mod 过滤器
- 在 bulk_response_process 过滤器中添加新参数
- 添加 request_reshuffle 过滤器
- 添加资源限制,允许设置最大 CPU 数或绑定亲和性
- 支持模板中的嵌套变量
- 添加 rewrite_to_bulk 过滤器
Bug fix
- 修复了 Pipeline 中重试延迟未生效的问题
- 修复了模板中不支持数字的问题
- 修复了队列选择器通过标签的问题,如果指定了多个标签,它们都应该一起匹配
Improvements
- 将所有模块名称转换为小写
- 在启动期间预取 Elasticsearch 元数据
- 添加应用程序范围的关闭信号
- 重构队列 API,支持 Kafka 管理
- 在 Badger 模块中添加 enabled
- 允许使用优先级注册模块/插件
- 统一队列的使用和初始化
- 优化 bulk_reshuffle 过滤器的性能,添加响应头 X-Bulk-Reshuffled
- 支持在 queue 过滤器中使用变量,允许输出最后生成的消息偏移量
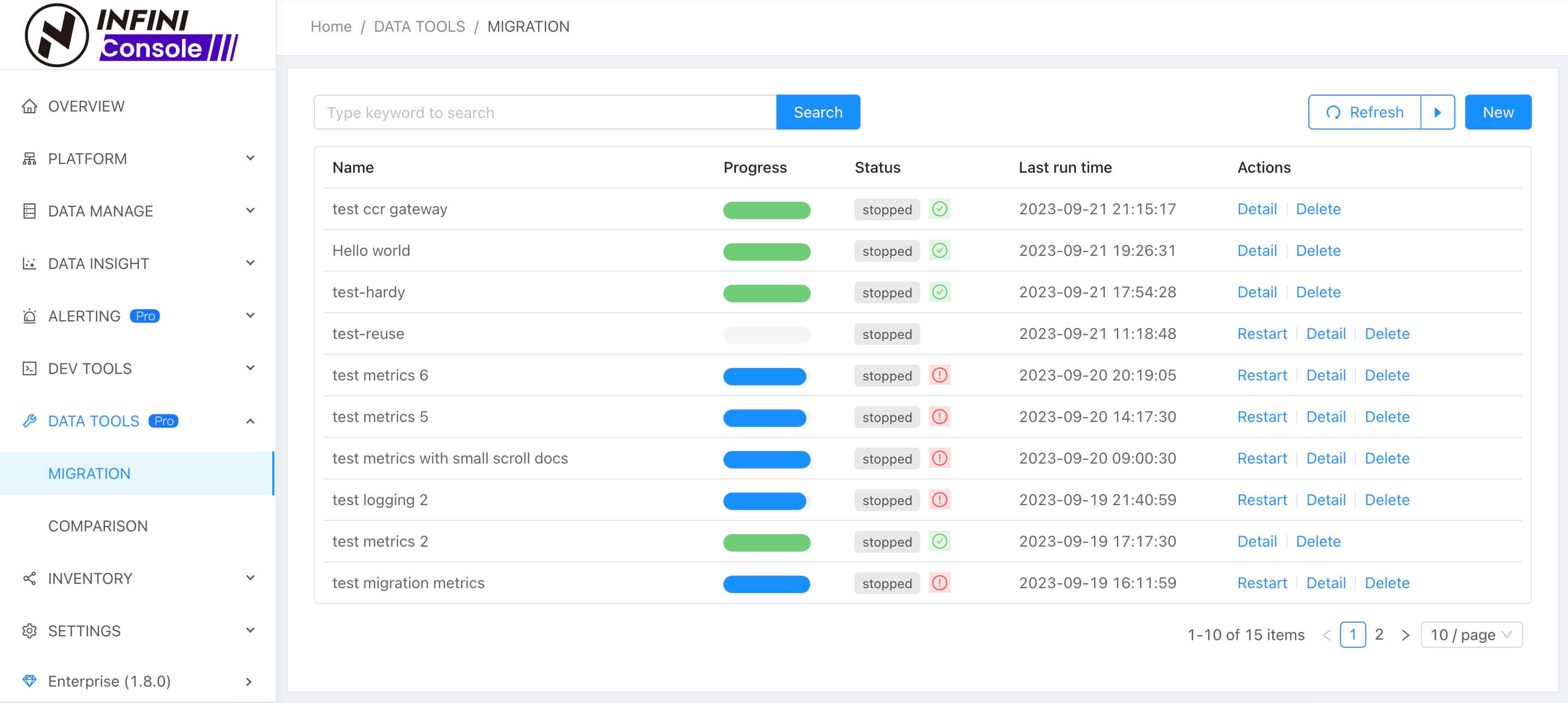
INFINI Console v1.8.0
INFINI Console 是一款非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管, 企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 在线体验: http://demo.infini.cloud (用户名/密码:readonly/readonly)。
Console 本次更新如下:
Features
- 数据迁移任务支持自定义名称和添加标签
- 数据迁移任务详情页新增若干指标
- 数据迁移任务详情页新增查看日志
Improvements
- 数据迁移 UI 优化
- 优化监控报表、数据看板、数据探索的时间控件 UI

期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
- INFINI Gateway: https://github.com/infinilabs/gateway/issues
- INFINI Console: https://github.com/infinilabs/console/issues
- 下载地址: https://www.infinilabs.com/download
您还可以通过邮件联系我们:hello@infini.ltd
或者拨打我们的热线电话:(+86) 400-139-9200
欢迎加入 Discord 聊天室:https://discord.com/invite/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。

关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
INFINI Labs 产品更新 | Gateway 支持基于 Kafka 的复制能力,发布 Helm Charts 部署方式的更多相关文章
- Confluent Platform 3.0支持使用Kafka Streams实现实时的数据处理(最新版已经是3.1了,支持kafka0.10了)
来自 Confluent 的 Confluent Platform 3.0 消息系统支持使用 Kafka Streams 实现实时的数据处理,这家公司也是在背后支撑 Apache Kafka 消息框架 ...
- 基于Kafka Connect框架DataPipeline在实时数据集成上做了哪些提升?
在不断满足当前企业客户数据集成需求的同时,DataPipeline也基于Kafka Connect 框架做了很多非常重要的提升. 1. 系统架构层面. DataPipeline引入DataPipeli ...
- DataPipeline丨瓜子二手车基于Kafka的结构化数据流
文 |彭超 瓜子大数据架构师 交流微信 | datapipeline2018 一.为什么选择Kafka 为什么选Kafka?鉴于庞大的数据量,需要将其做成分布式,这时需要将Q里面的数据分到许多机器 ...
- 打造实时数据集成平台——DataPipeline基于Kafka Connect的应用实践
导读:传统ETL方案让企业难以承受数据集成之重,基于Kafka Connect构建的新型实时数据集成平台被寄予厚望. 在4月21日的Kafka Beijing Meetup第四场活动上,DataPip ...
- TOP100summit:【分享实录-Microsoft】基于Kafka与Spark的实时大数据质量监控平台
本篇文章内容来自2016年TOP100summit Microsoft资深产品经理邢国冬的案例分享.编辑:Cynthia 邢国冬(Tony Xing):Microsoft资深产品经理.负责微软应用与服 ...
- 基于Kafka消息驱动最终一致事务(一)
基本可用软状态最终一致事务 本用例分两个数据库分别是用户库和交易库,不使用分布式事务,使用基于消息驱动实现基本可用软状态最终一致事务(BASE).现在说明下事务逻辑演化步骤,尊从CAP原则,即分布式系 ...
- 深入浅出理解基于 Kafka 和 ZooKeeper 的分布式消息队列
消息队列中间件是分布式系统中重要的组件,主要解决应用耦合,异步消息,流量削锋等问题.实现高性能,高可用,可伸缩和最终一致性架构,是大型分布式系统不可缺少的中间件. 本场 Chat 主要内容: Kafk ...
- Knative 实战:基于 Kafka 实现消息推送
作者 | 元毅 阿里云智能事业群高级开发工程师 导读:当前在 Knative 中已经提供了对 Kafka 事件源的支持,那么如何基于 Kafka 实现消息推送呢?本文作者将以阿里云 Kafka 产品为 ...
- 基于Kafka的实时计算引擎如何选择?Flink or Spark?
1.前言 目前实时计算的业务场景越来越多,实时计算引擎技术及生态也越来越成熟.以Flink和Spark为首的实时计算引擎,成为实时计算场景的重点考虑对象.那么,今天就来聊一聊基于Kafka的实时计算引 ...
- 基于Kafka的实时计算引擎如何选择?(转载)
1.前言 目前实时计算的业务场景越来越多,实时计算引擎技术及生态也越来越成熟.以Flink和Spark为首的实时计算引擎,成为实时计算场景的重点考虑对象.那么,今天就来聊一聊基于Kafka的实时计算引 ...
随机推荐
- 【笔记】Oracle列转行unpivot&行转列 PIVOT
unpivot 说明:将表中多个列缩减为一个聚合列(多列转多行) 语法:unpivot(新列名 for 聚合列名 in (对应的列名1-列名n )) 写到了一个力扣的题,发现这个unpivot函数还没 ...
- 【笔记】go语言--函数式编程
[笔记]go语言--函数式编程 简单来说,go语言的函数式编程体现的是一个闭包的情况 函数式编程 VS 函数指针 函数是一等公民:参数,变量,返回值都可以是函数 高阶函数 函数->闭包 &quo ...
- 加入自定义块对fashion_mnist数据集进行softmax分类
在之前,我们实现了使用torch自带的层对fashion_mnist数据集进行分类.这次,我们加入一个自己实现的block,实现一个四层的多层感知机进行softmax分类,作为对"自定义块& ...
- 性能透明提升 50%!SMC + ERDMA 云上超大规模高性能网络协议栈
简介: 新的协议栈是不是重新发明轮子?一个协议栈能否解决所有问题?适配所有场景? 编者按:当前内核网络协议栈有什么问题?新的协议栈是不是重新发明轮子?一个协议栈能否解决所有问题?适配所有场景?本文整理 ...
- Serverless 在阿里云函数计算中的实践
简介: 近日,阿里云 aPaaS&Serverless 前端技术专家袁坤在 CSDN 云原生 meetup 长沙站分享了 Serverless 在阿里云函数计算 FC 的实践. 作者:CSDN ...
- dotnet OpenXML 读取 PPT 形状边框定义在 Style 的颜色画刷
本文来和大家聊聊在 PPT 形状使用了 Style 样式的颜色画刷读取方法 在开始之前,期望大家已了解如何在 dotnet 应用里面读取 PPT 文件,如果还不了解读取方法,请参阅 C# dotnet ...
- STM32 USART串口通信
一.介绍 通用同步异步收发器(USART)提供了一种灵活的方法与使用工业标准NRZ异步串行数据格式的外部设备之间进行全双工数据交换.USART利用分数波特率发生器提供宽范围的波特率选择.它支持同步单向 ...
- 最强AI直播换脸软件,DeepFaceLive下载介绍
DeepFaceLive是一款专注于直播实时换脸的AI软件,使用经过长时间训练的人脸模型替换摄像头中的人脸,能够产生接近电影质量的面部合成效果,提供高保真的视觉体验,在新版本中也支持了图片换脸(视频换 ...
- C语言程序设计-笔记2-分支结构
C语言程序设计-笔记2-分支结构 例3-1 简单的猜数游戏.输入你所猜的整数(假定1-100),与计算机产生的被猜数比较,若相等,显示猜中:若不等,显示与被猜数的大小关系. /*简单的猜数游戏*/ ...
- 一个可以输出当前移动设备机型(安卓,ios)系统版本的html页面
<!doctype html> <html lang="en"> <head> <meta charset="UTF-8&quo ...