kafka 工作流程及文件存储机制

1、kafka的数据存储
文件存储格式: .log 和 .index
Kafka 中消息是以 topic 进行分类的, 生产者生产消息,消费者消费消息,都是面向 topic的。
topic 是逻辑上的概念,而 partition 是物理上的概念,每个 partition 对应于一个 log 文件,该 log 文件中存储的就是 producer 生产的数据。
Producer 生产的数据会被不断追加到该log 文件末端,且每条数据都有自己的 offset。 消费者组中的每个消费者, 都会实时记录自己消费到了哪个 offset,以便出错恢复时,从上次的位置继续消费。
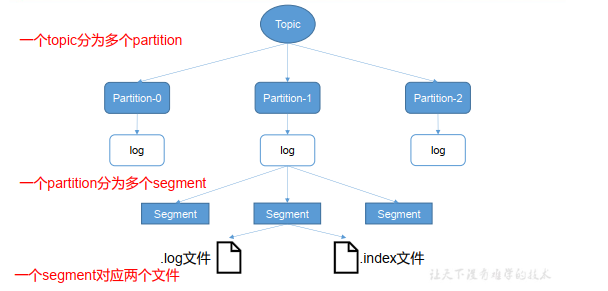
如图:由于生产者生产的消息会不断追加到 log 文件末尾, 为防止 log 文件过大导致数据定位效率低下, Kafka 采取了分片和索引机制,将每个 partition 分为多个 segment。
每个 segment对应两个文件——“.index”文件和“.log”文件。 这些文件位于一个文件夹下, 该文件夹的命名规则为: topic 名称+分区序号。例如, first 这个 topic 有三个分区,则其对应的文件夹为 first-0,first-1,first-2。


“.index”文件存储大量的索引信息,“.log”文件存储大量的数据,索引文件中的元数据指向对应数据文件中 message 的物理偏移地址。
文件根据大小拆分成多个分片,.index存储offset、数据位置; .log存储数据;通过index的offet和数据位置 找到在log中数据
比如:要查找绝对offset为7的Message:
- 首先是用2分查找肯定它是在哪一个LogSegment中,自然是在第1个Segment中。
- 打开这个Segment的index文件,也是用2分查找找到offset小于或等于指定offset的索引条目中最大的那个offset。自然offset为6的那个索引是我们要找的,通过索引文件我们知道offset为6的Message在数据文件中的位置为9807。
- 打开数据文件,从位置为9807的那个地方开始顺序扫描直到找到offset为7的那条Message。
这套机制是建立在offset是有序的。索引文件被映照到内存中,所以查找的速度还是很快的。
1句话,Kafka的Message存储采取了分区(partition),分段(LogSegment)和稀疏索引这几个手段来到达了高效性。
kafka 工作流程及文件存储机制的更多相关文章
- Kafka架构深入:Kafka 工作流程及文件存储机制
kafka工作流程: 每个分区都有一个offset消费偏移量,kafka并不能保证全局有序性. Kafka 中消息是以 topic 进行分类的,生产者生产消息,消费者消费消息,都是面向 topic 的 ...
- 深入了解Kafka【二】工作流程及文件存储机制
1.Kafka工作流程 Kafka中的消息以Topic进行分类,生产者与消费者都是面向Topic处理数据. Topic是逻辑上的概念,而Partition是物理上的概念,每个Partition分为多个 ...
- Kafka与RocketMq文件存储机制对比
一个商业化消息队列的性能好坏,其文件存储机制设计是衡量一个消息队列服务技术水平和最关键指标之一. 开头问题 kafka文件结构和rocketMQ文件结构是什么样子?特点是什么? 一.目录结构 Kafk ...
- kafka知识体系-kafka设计和原理分析-kafka文件存储机制
kafka文件存储机制 topic中partition存储分布 假设实验环境中Kafka集群只有一个broker,xxx/message-folder为数据文件存储根目录,在Kafka broker中 ...
- Kafka文件存储机制及partition和offset
转载自: https://yq.aliyun.com/ziliao/65771 参考: Kafka集群partition replication默认自动分配分析 如何为kafka选择合适的p ...
- Kafka文件存储机制及offset存取
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
- Kafka文件存储机制那些事
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
- Kafka 文件存储机制那些事 - 美团技术团队
出处:https://tech.meituan.com/2015/01/13/kafka-fs-design-theory.html 自己总结: Kafka 文件存储机制_结构图:https://ww ...
- kafka学习之-文件存储机制
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
- 转】 Kafka文件存储机制那些事
原博文出自于:http://tech.meituan.com/kafka-fs-design-theory.html 感谢! Kafka是什么 Kafka是最初由Linkedin公司开发,是一个 ...
随机推荐
- 爬虫逆向基础,认识 SM1-SM9、ZUC 国密算法
关注微信公众号:K哥爬虫,QQ交流群:808574309,持续分享爬虫进阶.JS/安卓逆向等技术干货! [01x00] 简介 国密即国家密码局认定的国产加密算法,爬虫工程师在做 JS 逆向的时候,会遇 ...
- 安装Visual Studio的详细流程
本文介绍Visual Studio 2022软件Community(社区版)的下载.安装.运行与使用方法. 首先需要提一句,本文介绍的是Visual Studio 2022软件的下载:而其它版 ...
- svn忽略某个目录后update出现fetching
忽略某个子目录 在svn udpate一个大目录时忽略特定的子目录,主要是子目录下内容已经单独拉取过,并且这个大目录对于程序来说,可以是只读的. 操作方法:选中要忽略的目录,右键 svn - Unve ...
- 【踩坑记录】SpringBoot跨域配置不生效
问题复现: 明明在拦截器里配置了跨域,就是不生效,使用PostMan等后端调试工具调试,均正常,Response中有Access-Control-Allow-Origin: *,这个Header,但是 ...
- 知识蒸馏相关技术【模型蒸馏、数据蒸馏】以ERNIE-Tiny为例
1.任务简介 基于ERNIE预训练模型效果上达到业界领先,但是由于模型比较大,预测性能可能无法满足上线需求. 直接使用ERNIE-Tiny系列轻量模型fine-tune,效果可能不够理想.如果采用数据 ...
- 21.6 Python 构建ARP中间人数据包
ARP中间人攻击(ARP spoofing)是一种利用本地网络的ARP协议漏洞进行欺骗的攻击方式,攻击者会向目标主机发送虚假ARP响应包,使得目标主机的ARP缓存中的IP地址和MAC地址映射关系被篡改 ...
- [XXL-JOB] 分布式调度XXL-JOB快速上手
1.概述 1.1什么是任务调度 我们可以思考一下下面业务场景的解决方案: 某电商平台需要每天上午10点,下午3点,晚上8点发放一批优惠券 某银行系统需要在信用卡到期还款日的前三天进行短信提醒 某财务系 ...
- 创建framework静态库和.a静态库
在APP项目中使用的静态库有两种,一是.a静态库,另一种是framework静态库.下面分布介绍这2中静态库的创建过程,以及通过脚本工具做自动化打包的2种方式. Framework静态库生成 如果 ...
- 一篇学会软硬链接|快捷方式|操作系统|centos7
前言 那么这里博主先安利一些干货满满的专栏了! 首先是博主的高质量博客的汇总,这个专栏里面的博客,都是博主最最用心写的一部分,干货满满,希望对大家有帮助. 高质量博客汇总https://blog.cs ...
- 【内存操作】C语言内存函数介绍以及部分模拟实现【初学者保姆级福利】超详细的解释和注释
C语言 内存函数的使用以及部分模拟实现 求个赞求个赞求个赞求个赞 谢谢 先赞后看好习惯 打字不容易,这都是很用心做的,希望得到支持你 大家的点赞和支持对于我来说是一种非常重要的动力 看完之后别忘记关注 ...