这波操作看麻了!十亿行数据,从71s到1.7s的优化之路。
你好呀,我是歪歪。
春节期间关注到了一个关于 Java 方面的比赛,很有意思。由于是开源的,我把项目拉下来试图学(白)习(嫖)别人的做题思路,在这期间一度让我产生了一个自我怀疑:
他们写的 Java 和我会的 Java 是同一个 Java 吗?
不能让我一个人怀疑,所以这篇文章我打算带你盘一下这个比赛,并且试图让你也产生怀疑。
赛题
在 2024 年 1 月 1 日,一个叫做 Gunnar Morling 的帅哥,发了这样一篇文章:
https://www.morling.dev/blog/one-billion-row-challenge/

文章的标题叫做《The One Billion Row Challenge》,十亿行挑战,简称就是 1BRC,挑战的时间是一月份整个月。
赛题的内容非常简单,你只需要看懂这个文件就行了:

文件的每一行记录的是一个气象站的温度值。气象站和温度分号分隔,温度值只会保留一位小数。
参赛者只需要解析这个文件,然后并计算出每个气象站的最小、最大和平均温度。按照字典序的格式输出就行了:

出题人还配了一个简图:
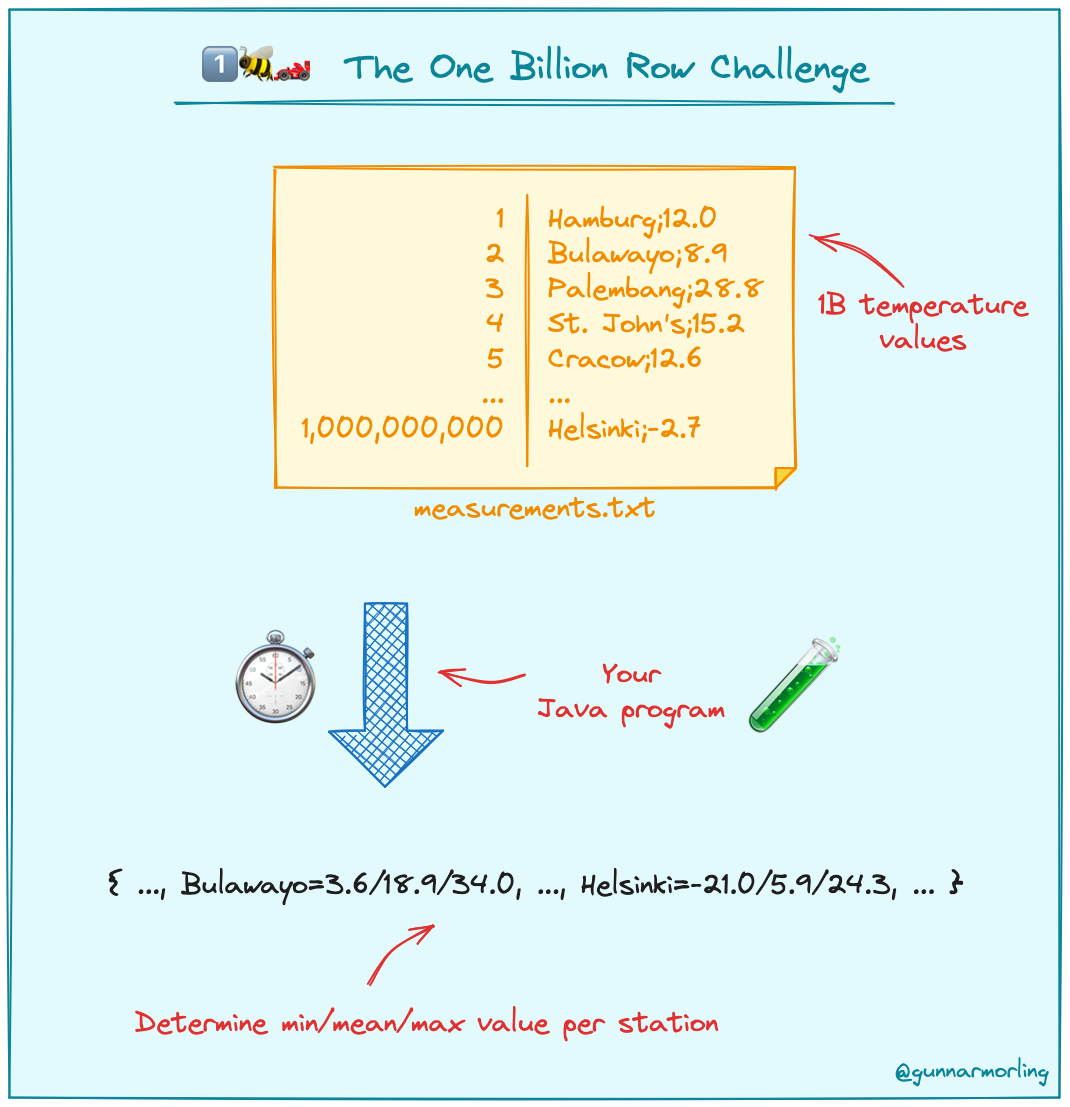
需求非常明确、简单,对不对?
为了让你彻底明白,我再给你举一个具体的例子。
假设文件中的内容是这样的:
chengdu;12.0
guangzhou;7.2;
chengdu;6.3
beijing;-3.6;
chengdu;23.0
shanghai;9.8;
chengdu;24.3
beijing;17.8;
那么 chengdu (成都)的最低气温是 6.3,最高气温是 24.3,平均气温是(12.0+6.3+23.0+24.3)/4=16.4,就是这么朴实无华的计算方式。
最终结果输出的时候,再注意一下字典序就行。
这有啥好挑战的呢?
难点在于出题人给出的这个文件有 10 亿行数据。
在我的垃圾电脑上,光是跑出题人提供的数据生成的脚本,就跑了 20 分钟:
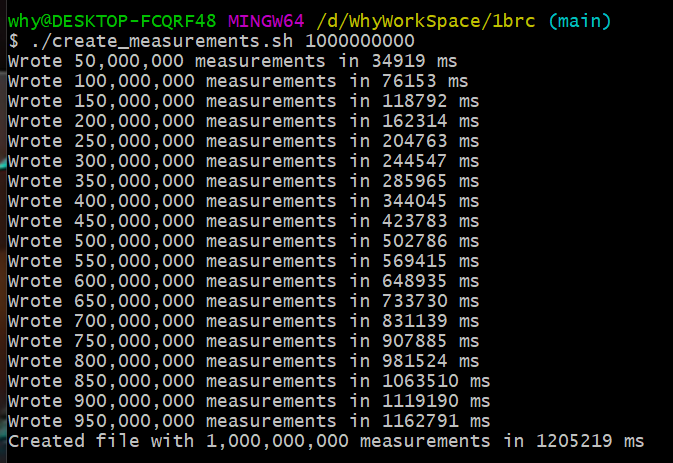
跑出来之后文件大小都有接近 13G,记事本打都打不开:
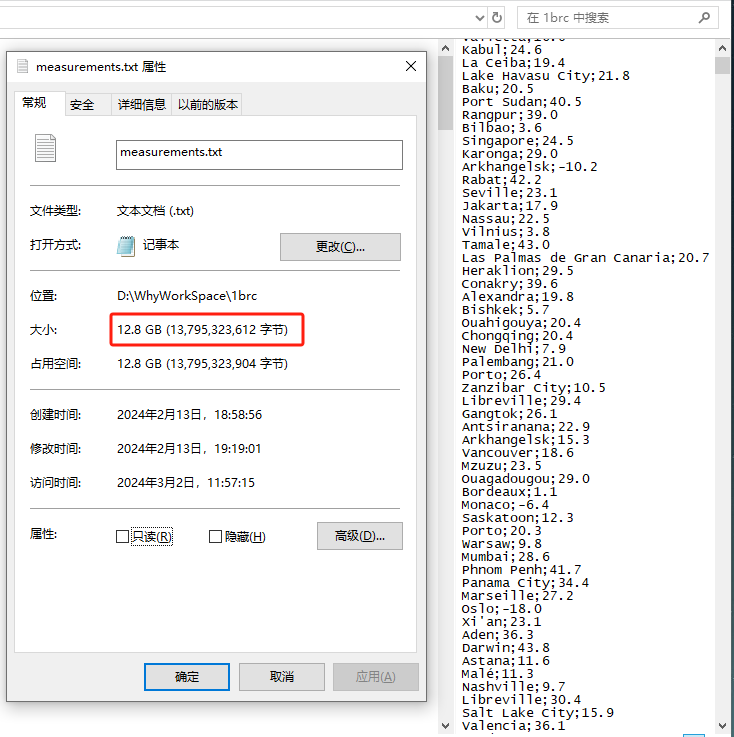
所以挑战点就在于“十亿行”数据。
具体的一些规则描述和细节补充,都在 github 上放好了:
https://github.com/gunnarmorling/1brc
针对这个挑战,出题人还提供了一个基线版本:
https://github.com/gunnarmorling/1brc/blob/main/src/main/java/dev/morling/onebrc/CalculateAverage_baseline.java
首先封装了一个 MeasurementAggregator 对象,里面放的就是要记录的最小温度、最大温度、总温度和总数。
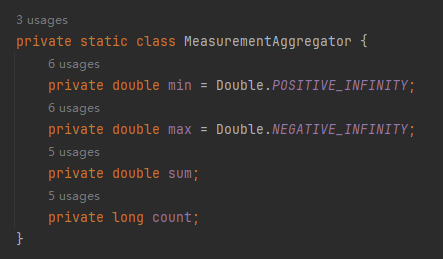
整个核心代码就二三十行,使用了流式编程:
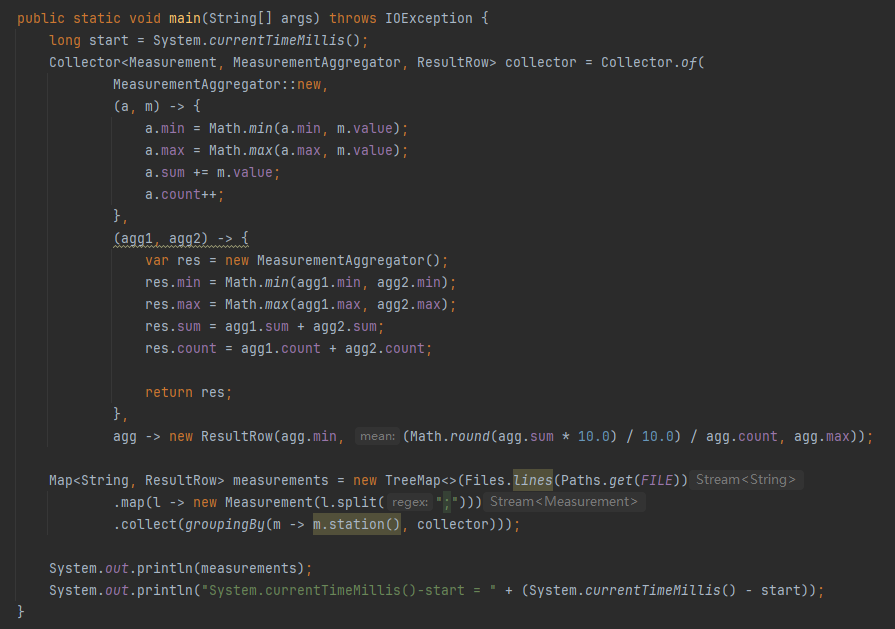
首先是一行行的读取文本,接着每一行都按照分号进行拆分,取出对应的气象站和温度值。
然后按照气象站维度进行 groupingBy 聚合,并且计算最大值、最小值和平均值。
在计算平均值的时候,为了避免浮点计算,还特意将温度乘 10,转换为 int 类型。
最后用 TreeMap 按字典序输出各个气象站的温度数据。
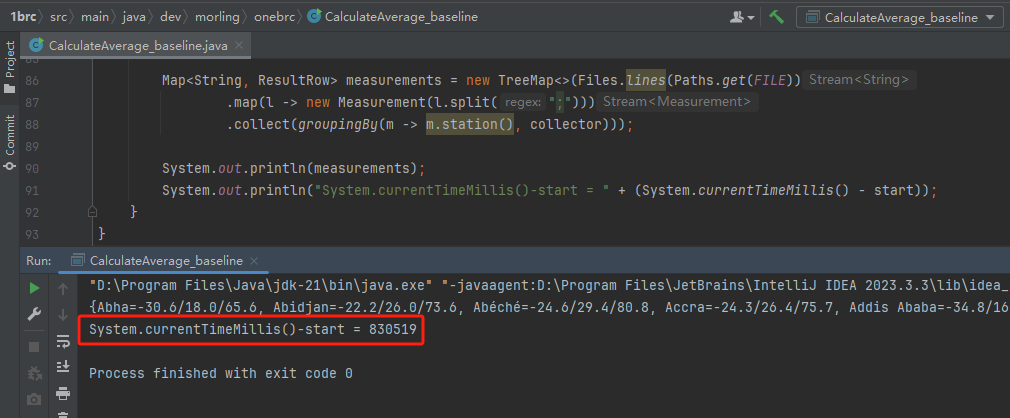
这个基线版本官方的数据是在跑分环境下,2 分钟内可以运行完毕。
而在我的电脑上跑了接近 14 分钟:
很正常,毕竟人家的测评环境配置都是很高的:
Results are determined by running the program on a Hetzner AX161 dedicated server (32 core AMD EPYC 7502P (Zen2), 128 GB RAM).
参加挑战的各路大神,最终拿出的 TOP 10 成绩是这样的:
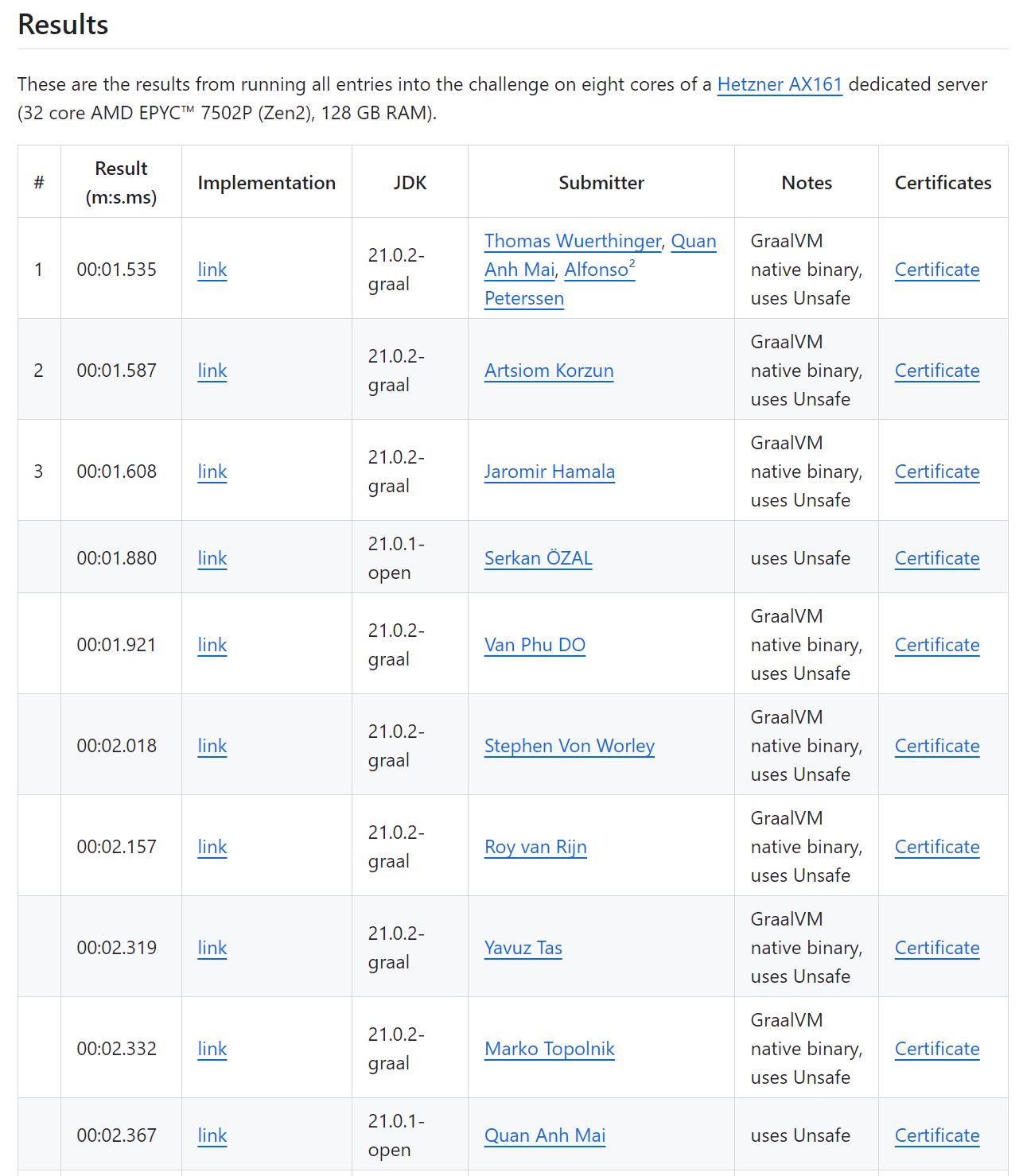
当时看到这个成绩的瞬间,我人都是麻的,第一个疑问是:我靠,13G 的文件啊?1.5s 内完成了读取、解析、计算的过程?这不可能啊,光是读取 13G 大小的文件,也需要一点时间吧?

但是需要注意的是,歪师傅有这个想法是走入了一个小误区,就是我以为这 13G 的文件一次性加载不完成,怎么快速的从硬盘把文件读取到内存中也是一个考点。
后来发现是我多虑了,人家直接就说了,不用考虑这一点,跑分成绩运行的时候,文件直接就在内存中:

所以,最终的成绩中不包含读取文件的时间。
但是也很牛逼了啊,毕竟有十亿条数据。
第一名
我尝试着看了一下第一名的代码:
https://github.com/gunnarmorling/1brc/blob/main/src/main/java/dev/morling/onebrc/CalculateAverage_thomaswue.java
过于硬核,实在是看不懂。我只能通过作者写的一点注释、方法名称、代码提交记录去尝试理解他的代码。
在他的代码开头的部分,有这样的一段描述:

这是他的破题思路,结合了这些信息之后再去看代码,稍微好一点,但是我发现他里面还是有非常多的微操、太多针对性的优化导致代码可读性较差,虽然他的代码加上注释一共也才 400 多行,然而我看还是看不懂。
我随便截个代码片段吧:

问 GPT 这个哥们,他也是能说个大概出来:

所以我放弃了理解第一名的代码,开始去看第二名,发现也是非常的晦涩难懂,再到第三名...
最后,我产生了文章开始时的疑问:他们写的 Java 和我会的 Java 是同一个 Java 吗?
但是有一说一,虽然我看不懂他们的某些操作,但是会发现他们整体的思路都几乎是一致。
虽然我没有看懂第一名的代码,但是我还是专门列出了这一个小节,给你指个路,有兴趣你可以去看看。
另外,获得第一名的老哥,其实是一个巨佬:
是 GraalVM 项目的负责人之一:

巨人肩膀
在官方的 github 项目的最后,有这样的一个部分:
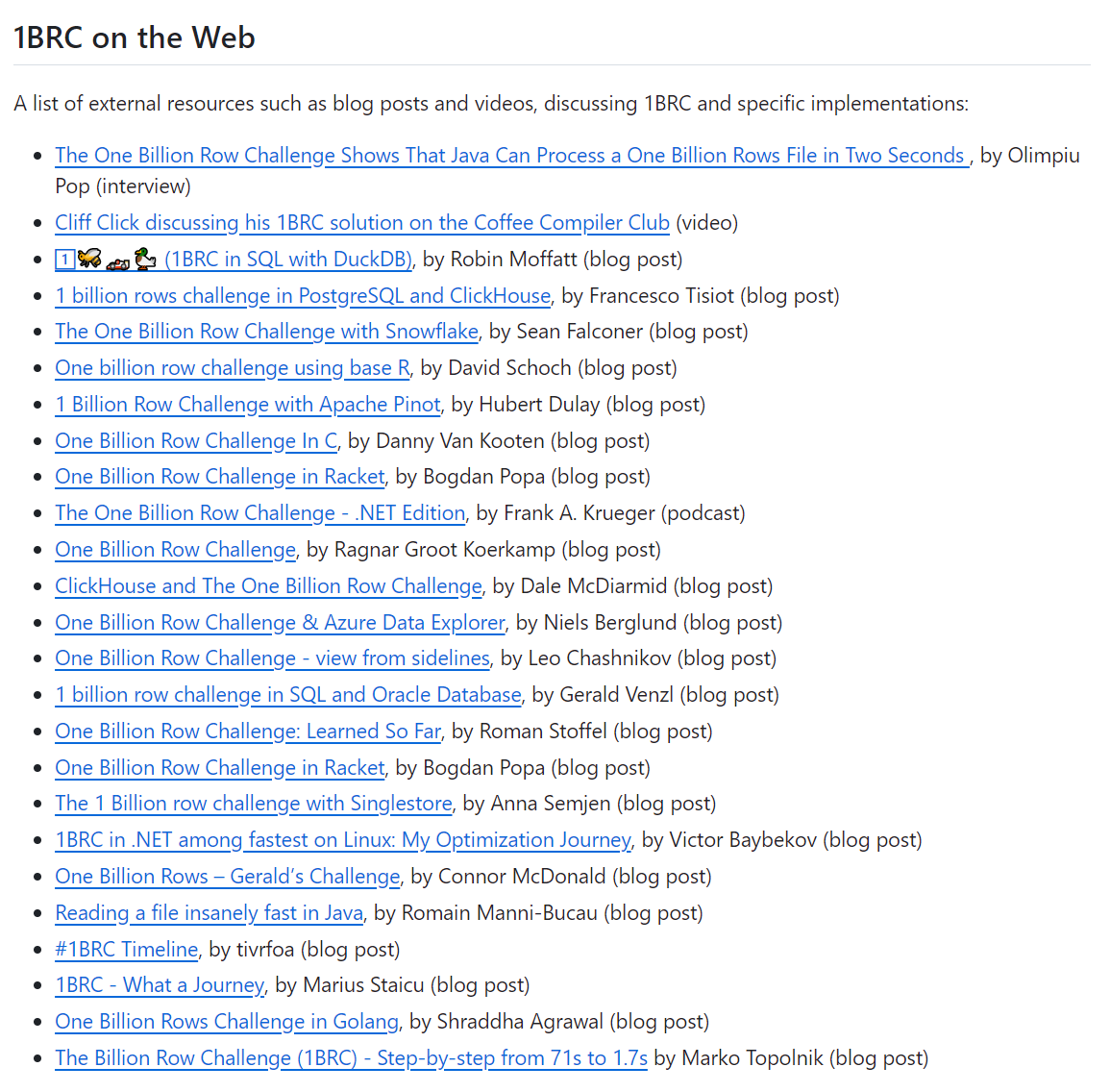
其中最后一篇文章,是一个叫做 Marko Topolnik 的老哥写的。
我看了一下,这个哥们的官方成绩是 2.332 秒,榜单第九名:

但是按照他自己的描述,在比赛结束后他还继续优化了代码,最终可以跑到 1.7s,排名第四。
在他的文章中详细的描述了他的挑战过程和思路。
我就站在巨人的肩膀上,带大家看看这位大佬从 71s 到 1.7s 的破题之道:
https://questdb.io/blog/billion-row-challenge-step-by-step/
最常规的代码
首先,他给了一个常规实现的代码,和基线版本的代码大同小异,只不过是使用了并行流来处理:
https://github.com/mtopolnik/billion-row-challenge/blob/main/src/Blog1.java
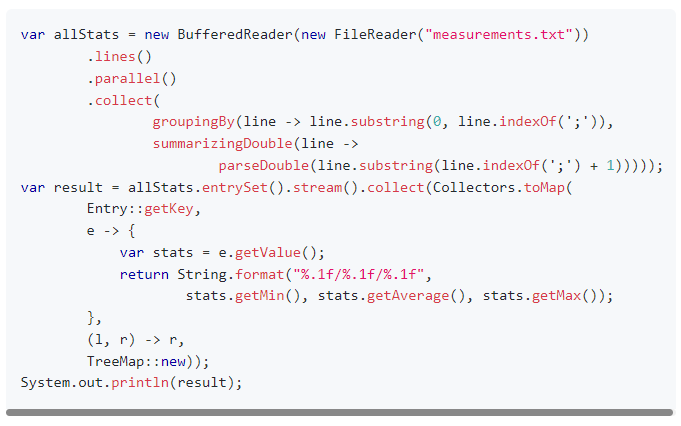
平时看到流式编程我是有点头疼的,需要稍微的反应一下,但是在看了前三名的最终代码后再看这个代码,我觉得很亲切。
根据作者的描述,这段代码:
使用并行 Java 流,将所有 CPU 核心都用起来了。 也不会陷入任何已知的性能陷阱,比如 Java 正则表达式
在一台装有 OpenJDK 21.0.2 的 Hetzner CCX33 机器上,跑完需要的时间为 71 秒。
第 0 版优化:换个好的 JVM
叫做第 0 版优化的原因是作者对于代码其实啥也没动,只是换了一个 JVM:

默认使用 GraalVM 之后,最常规的代码,运行时间从 71s 到了 66s,相当于白捡了 5s,我问就你香不香。
同时作者还提到一句话:
When we get deeper into optimizing and bring down the runtime to 2-3 seconds, eliminating the JVM startup provides another 150-200ms in relief. That becomes a big deal.
当我们把程序优化到运行时间只需要 2-3 秒的时候,使用 GraalVM,会消除 JVM 的启动时间,从而提供额外的 150-200ms 的提升。
到那个时候,这个就变得非常重要了。
数据指标很重要
在正式进入优化之前,作者先介绍了他使用到的三个非常重要的工具:

关于工具我就不过多介绍了,这里单独提一嘴主要是想表达一个贯穿整个优化过程的中心思想:数据指标很重要。
你只有收集到了当前程序足够多的运行指标,才能对你进行下一步优化时提供直观的、优化方向上的指导。
工欲善其事必先利其器,就是这个道理。
第一版优化:并行 I/O 搞起来
通过查看当前代码对应的火焰图:
https://questdb.io/html/blog/profile-blog1

通过火焰图以及观察 GC 情况,作者发现当前耗时的地方注意是这三个地方:

BufferedReader 将每行文本输出为字符串 处理每一行的字符串 垃圾收集 (GC):使用 VisualGC 可以看到,差不多每秒要 GC 10 次甚至更多。
可以发现 BufferedReader 占用了大量的性能,因为当前读取文件还是一行行读取的嘛,性能很差。
于是大多数人意识到的第一件事就是采用并行化 I/O。
所以,我们需要把待处理的文件分块。分多少块呢?
有多少个线程就分成多少个块,每个线程各自处理一个块,这样性能就上去了。
文件分块读取,大家自然而然的就想到了 mmap 相关的方法。
mmap 可以用 ByteBuffer API 来搞事情,但是使用的索引是 int 类型,所以可映射的大小有 2GB 的限制。
前面说了,在这个挑战中,光是文件大小就有 13G,所以 2GB 是捉襟见肘的。
但是在 JDK 21 中,支持一个叫做 MemorySegment 的东西,也可以干 mmap 一样的事情,但是它的索引使用的是 long,相当于没有内存限制了。
除了使用 MemorySegment 外,还有一些细节的处理,比如找到正确的分割文件的位置、启动线程、等待线程处理完成等等。
处理这些细节会导致这一版的代码从最初的 17 行增加到了 120 行。
这是优化后的代码地址:
https://github.com/mtopolnik/billion-row-challenge/blob/main/src/Blog2.java
在这个赛题下,我们肯定是需要再循环中进行数据的解析和处理的,所以循环就是非常重要的一个点。
我们可以关注一下代码中的循环部分,这里面有一个小细节:
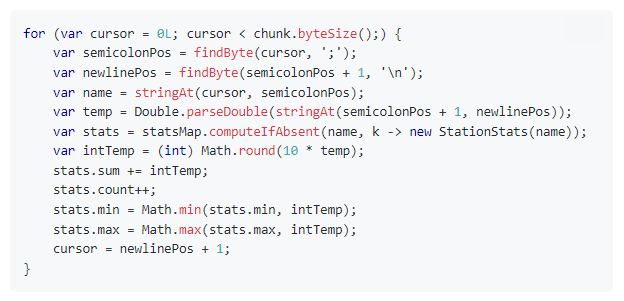
这个循环是每个线程在按块读取文件大小,里面用到了 findByte 方法和 stringAt 方法。
在第一个版本中,我们是用的 BufferedReader 把一行内容以字符串的形式读进来,然后按照分号分隔,并生成城市和温度两个字符串。
这个过程就涉及到三个字符串了。
但是这个哥们的思路是啥?
自定义一个 findByte 方法,先找到分号的位置,然后把下标返回回去。
再用自定义的 stringAt 方法,结合前面找到的下标,直接解析出“城市和温度”这两个字符串,减少了整行读取的内存消耗。
相当于少了十亿个字符串,在字符串处理和 GC 方面取得了不错的表现。
这一波操作下来,处理时间直接从 66s 下降到了 17s:

然后再看火焰图:
https://questdb.io/html/blog/profile-blog2-variant1

可以发现 GC 的时间几乎消失了。
CPU 现在大部分时间都花在自定义的 stringAt 上。还有相当多的时间花在 Map.computeIfAbsent 方法 、Double.parseDouble 方法和 findByte 方法
其中 Double.parseDouble 方法是解析温度用的。
作者打算先把这个地方给攻下来。
第二版优化:优化温度解析方法
在这版优化中,作者直接将温度解析为整数。
首先,目前的做法是,首先分配一个字符串,然后对其调用 parseDouble() 方法,最后转换为整数以进行高效的存储和计算。
但是,其实我们应该直接创建整数出来,没必要走字符串绕一圈。
同时我们知道,温度的取值范围是 [-99.9,99.9],所以针对这个范围,我们搞个自定义方法就行了:
private int parseTemperature(long semicolonPos) {
long off = semicolonPos + 1;
int sign = 1;
byte b = chunk.get(JAVA_BYTE, off++);
if (b == '-') {
sign = -1;
b = chunk.get(JAVA_BYTE, off++);
}
int temp = b - '0';
b = chunk.get(JAVA_BYTE, off++);
if (b != '.') {
temp = 10 * temp + b - '0';
// we found two integer digits. The next char is definitely '.', skip it:
off++;
}
b = chunk.get(JAVA_BYTE, off);
temp = 10 * temp + b - '0';
return sign * temp;
}
这波操作下来,处理时间又减少了 6s,来到了 11s:

再看对应火焰图:
https://questdb.io/html/blog/profile-blog2-variant2

温度解析部分的耗时占比从 21.43% 降低到 6%,说明是一次正确的优化。
接下来,可以再搞一搞 stringAt 方法了。
第三版优化:自定义哈希表
首先,要优化 stringAt 方法,我们得知道它是干啥的。
我们看一眼代码:
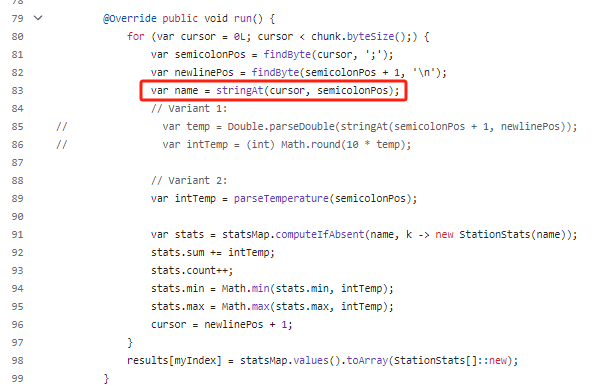
在经历了上一波优化之后,stringAt 目前在代码中的唯一作用就是为了获取气象站的名称。
而获取到这个名称的唯一目的是看看当前的 HashMap 中有没有这个气象站的数据,如果没有就新建一个 StationStats 对象,如果有就把之前的 StationStats 对象拿出来进行数据维护。
此外,在赛题中还有这样的一个信息,虽然有十亿行数据,但是只有 413 个气象站:

既然 key 的大小是可控的,那基于这个条件,作者想了一个什么样的骚操作呢?
他直接不用 HashMap 了,自定义了一个哈希表,长这样的:
https://github.com/mtopolnik/billion-row-challenge/blob/main/src/Blog3.java
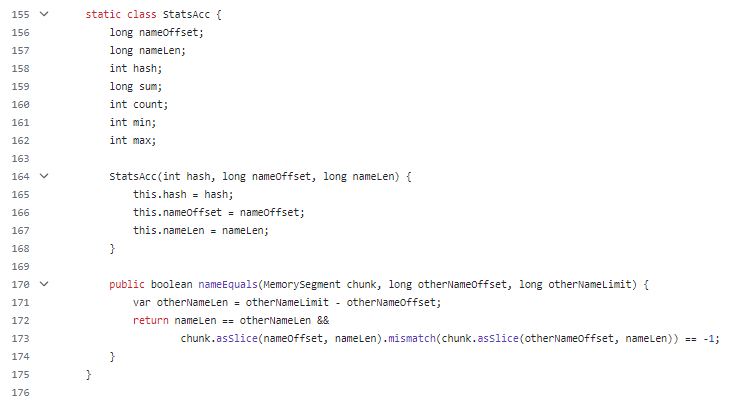
主要看一下代码中的 findAcc 方法,你就能明白它是干啥的了:
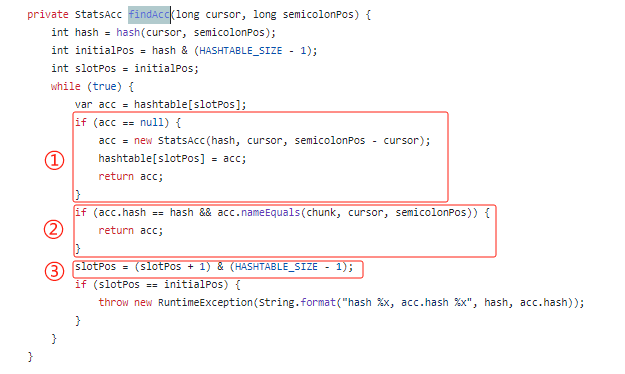
通过 hash 方法计算出指定字符串,即气象站名称的 hash 值之后,从自定义的 hashtable 中取出该位置的数据。
首先标号为 ① 的地方,如果没有取到数据,则说明没有这个气象站的数据,新建一个放好,返回就完事。
如果取到了数据,来到标号为 ② 的地方,看看取到的数据和当前要放的数据对应的气象站名称是不是一样的。
如果是则说明已经有了,取出来,然后返回。
如果不是,说明啥情况?
说明 hash 冲突了,来到标号为 ③ 的地方进行下标加一的动作。
然后再次进行循环。
来,你告诉我,这是什么手法?
这不就是开放寻址来解决 hash 冲突吗?
所以 findAcc 方法,就可以替代 computeIfAbsent 方法。
通过自定义的 StatsAcc 哈希表来代替原生的 HashMap。
而且前面说了,key 的大小是可控的,如果自定义 hash 表的初始化大小控制的合适,那么整个 hash 冲突的情况也不会非常严重。
这一波组合拳下来,运行时间来到了 6.6s,火焰图变成了这样:
https://questdb.io/html/blog/profile-blog3

大量的时间花在了前面分析的 findAcc 方法上。
同时作者提到了这样一句话:

同样的代码,如果放到 OpenJDK 上跑需要运行 9.6s,比 GraalVM 慢了 3.3s。
我滴个乖乖,这就是一个 45% 的性能提升啊。
第四版优化:使用 Unsafe 和 SWAR
在这一版优化开始之前,作者先写了这样一段话:

大概意思就是说,到目前为止,我们用到的都是常规且有效的解决方案,并且是 Java 标准、安全的用法。
即使止步于此也能学到很多优化技巧,可以在实际的项目中进行使用。
如果你继续往下探索,那么:
Readability and maintainability also take a big hit, while providing diminishing returns in performance. But, a challenge is a challenge, and the contestants pressed on without looking back!
可读性和可维护性也会受到重创,同时性能的收益会递减。但是,挑战就是挑战,参赛者们继续努力,没有回头!
简单来说,作者的意思就是打个预防针:接下来就要开始上强度了。
所以,在这个版本中,作者应用一些排名靠前的选上都在用的方案:
使用 sun.misc.Unsafe 而不是 MemorySegment,来避免边界检查 避免重新读取相同的输入字节:重复使用加载的值进行哈希和分号搜索 每次处理 8 个字节的数据,使用 SWAR 技术找到分号分隔符。 使用 merykitty 老哥提供的牛逼的 SWAR(SIMD Within A Register)代码解析温度。
这是这一版的代码:
https://github.com/mtopolnik/billion-row-challenge/blob/main/src/Blog4.java
比如其中关于循环处理数据的部分,看起来就很之前很不一样了:
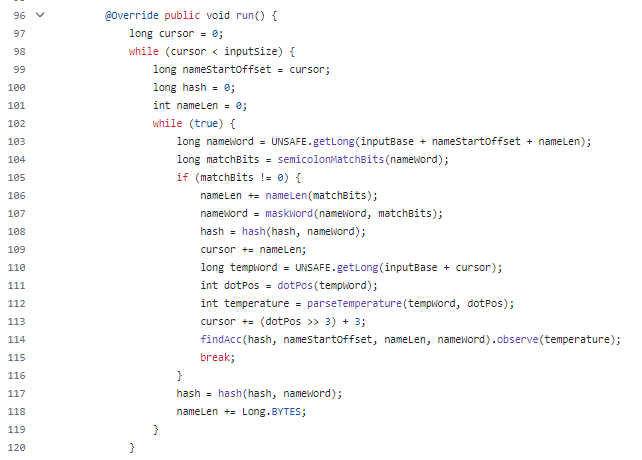
然后你再看里面 semicolonMatchBits、nameLen、maskWord、dotPos、parseTemperature 这些方法的调用,直接就是一个懵逼的状态,看着头都大了:

但是你仔细看,你会发现这几个方法是作者从其他人那边学来的:
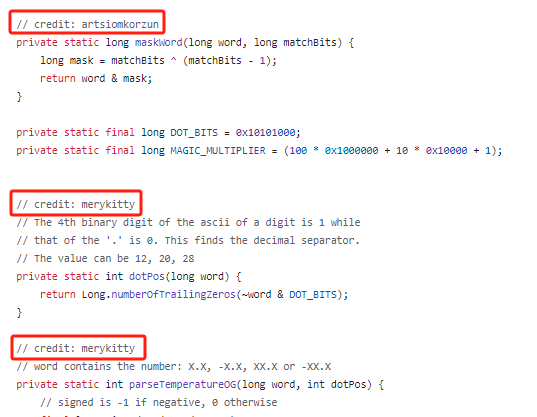
比如这个叫做 merykitty 的老哥,提供了解析温度的代码,虽然作者加入了大量的注释说明,但是我也只是大概就看懂了不到三层吧。
这里面大量的使用了位运算的技巧,同时你仔细看:几乎没有 if 判断的存在。这是重点,用直接的位运算替换了分支指令,从而减少了分支预测错误的成本。
此外,还有很多我第一次见、叫不上名字的奇技淫巧。
通过这一波“我看不懂,但是我大受震撼”的操作搞下来,时间降低到了 2.4s:

第五版优化:统计学用起来
现在,我们的火焰图变成了这样:
https://questdb.io/html/blog/profile-blog4

耗时主要还是在于 findAcc 方法:

而 findAcc 方法的耗时在于 nameEquals 方法,判断当前气象站名称是否出现过:

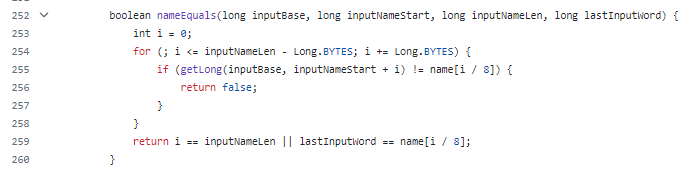
但是这个方法里面有个 if 判断,以字节为单位比较两个字符串的内容,每次比较 8 个字节。
首先,它通过循环逐步比较两个字符串中的对应字节。在每次迭代中,它使用 getLong 方法从输入字符串中获取一个 64 位的长整型值,并与另一个字符串中的相应位置进行比较。如果发现不相等的字节,则返回 false,表示两个字符串不相等。
如果循环结束后没有发现不相等的字节,它会继续检查是否已经比较了输入字符串的所有字节,或者最后一个输入字符串的字节与相应位置的字符串字节相等,那么表示两个字符串相等,则返回 true。
那么问题就来了?
如果气象站名称长度全都是小于 8 个字节,会出现啥情况?
假设有这样的一个前提条件,是不是我们就不用在 for 循环中进行 if 判断了,直接一把就比较完成了?
很可惜,没有这样一个提前条件。
但是,如果在数据集中,气象站名称长度绝大部分都小于 8 个字节那是不是就可以单独处理一下?
那到底数据分布是怎么样的呢?
这个问题问题出去的一瞬间,统计学啪的一下就站出来了:这个老子在行,我算算。
所以,作者写了一个程序来统计分析数据集中气象站名称的长度:
https://github.com/mtopolnik/billion-row-challenge/blob/main/src/Statistics.java
基于程序运行结果,最终的结论如下:

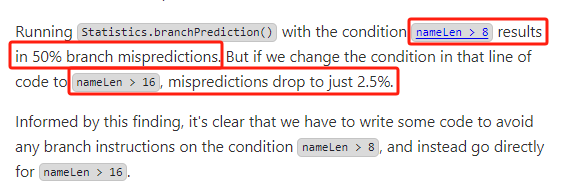
通过分析作者发现,赛题的数据集中气象站名称长度几乎均匀分布在 8 字节以上和 8 字节以下。
运行 Statistics.branchPrediction 方法,当条件是 nameLen > 8 时导致了 50% 的分支预测失败。
也就是说,十亿数据中有一半的数据,都是小于 8 字节的,都是不用特意进行 if 判断的。
但如果将条件更改为 nameLen > 16,那么预测失败率将降至 2.5%。
根据这一发现,很明显,如果要进一步优化代码,就需要编写一些特定的代码来避免在 nameLen > 8 上使用任何 if 判断,直接使用 nameLen > 16 就行。
这是这一版的最终代码,可读性越来越差了:
https://github.com/mtopolnik/billion-row-challenge/blob/main/src/Blog5.java
但是最终的成绩是 1.8s:

哦,对了,如果你对于分支预测技术不太清楚,那你可能看得比较懵。
但是分支预测,在性能挑战中,特别是最后大家比分都咬的非常紧的情况下,每次都是屡立奇功,战功赫赫,属于高手间过招杀手锏级别的优化手段。
继续优化
再后面作者还有这两个部分。
消除启动/清理成本:

使用更小的文件分块和工作窃取机制:

这后面就完全是基于这个赛题进行定制化的优化,可移植性不强了,作者就没有进行详细描述,再加上一个我也是没怎么看明白,就不展开讲了。
反正这两个组合拳下来,又搞了 0.1s 的时间下来,最终的成绩为 1.7s:
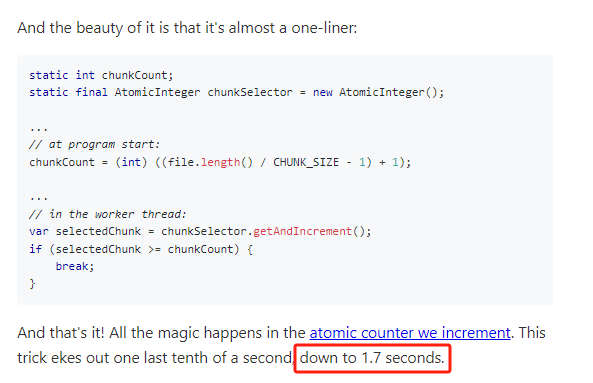
我实在是学不动了,有兴趣的同学可以自己去看看原文的对应部分。

写在后面
其实关于这篇文章,我原想法是看懂前三名的代码,然后对代码进行解析、对比,找到他们思路的共同点和差异点,但是后来他们的代码确实我看不懂,所以我放弃了这个想法。
但是我知道,只要我愿意花时间、有足够的时间,我肯定可以慢慢地把他们的这几百行代码啃透,但是我也只是想了想而已,很快就放弃了这个思路。
我想如果是大学的时候,我看到这个比赛,我会觉得,真牛逼,我得好好研究一下。
然而现在不一样了,参加工作了,看到了这个比赛,我还是会觉得,真牛逼,但是对我写业务代码帮助不大,就不深究了,浅尝辄止。
大学的时候学习是靠自己无穷的精力和对于掌握新知识的乐趣撑着,现在学习主要靠一时冲动。
但是我还是强烈建议感兴趣的朋友,按照我问中提到的地址,自己去研究一波别人提交的代码。
也许你也会产生一样的疑问:他们写的 Java 和我会的 Java 是同一个 Java 吗?
我的答案是:不是的,他们写的 Java 是自己热爱的 Java,我们写的 Java 只是挣钱的 Java。
没有高低贵贱之分,但是能让你不经意间,从业务代码的深海中抬头看一眼,看到自己熟悉的领域中,更广阔的世界。
这波操作看麻了!十亿行数据,从71s到1.7s的优化之路。的更多相关文章
- sql索引从入门到精通(十亿行数据测试报告)
原文:sql索引从入门到精通(十亿行数据测试报告) 导读部分 --------------------------------------------------------------------- ...
- Google将数十亿行代码储存在单一的源码库
过去16年,Google使用一个中心化源码控制系统去管理一个日益庞大的单一共享源码库.它的代码库包含了约10亿个文件(有重复文件和分支)和 3500万行注解,86TB数据,900万唯一源文件中含有大约 ...
- C++中文件的读取操作,如何读取多行数据,如何一个一个的读取数据
练习8.1:编写函数.接受一个istream&参数,返回值类型也是istream&.此函数必须从给定流中读取数据,直至遇到文件结束标识时停止. #include <iostrea ...
- 厉害了,ES 如何做到几十亿数据检索 3 秒返回!
一.前言 数据平台已迭代三个版本,从头开始遇到很多常见的难题,终于有片段时间整理一些已完善的文档,在此分享以供所需朋友的 实现参考,少走些弯路,在此篇幅中偏重于ES的优化,关于HBase,Hadoop ...
- 两年内从零到每月十亿 PV 的发展来谈 Pinterest 的架构设计(转)
原文:Scaling Pinterest - From 0 To 10s Of Billions Of Page Views A Month In Two Years 译文:两年内从零到每月十亿 PV ...
- 大数据计算:如何仅用1.5KB内存为十亿对象计数
大数据计算:如何仅用1.5KB内存为十亿对象计数 Big Data Counting: How To Count A Billion Distinct Objects Using Only 1.5K ...
- 每天4亿行SQLite订单大数据测试(源码)
SQLite单表4亿订单,大数据测试 SQLite作为嵌入式数据库的翘楚,广受欢迎!新生命团队自2010年以来,投入大量精力对SQLite进行学习研究,成功应用于各系统非致命数据场合. SQLite极 ...
- 2018.2.12 PHP 如何读取一亿行的大文件
PHP 如何读取一亿行的大文件 我们可能在很多场景下需要用 PHP 读取大文件,之后进行处理,如果你没有相关的经验可以看下,希望能给你带来一些启发. 模拟场景 我们有一个 1亿 行,大小大概为 3G ...
- 个人永久性免费-Excel催化剂功能第100波-透视多行数据为多列数据结构
在数据处理过程中,大量的非预期格式结构需要作转换,有大家熟知的多维转一维(准确来说应该是交叉表结构的数据转二维表标准数据表结构),也同样有一些需要透视操作的数据源,此篇同样提供更便捷的方法实现此类数据 ...
- opencv安装实录附十几行C++实现的一个人脸识别demo
前言: 之前写过一篇在nano上使用opencv,nano上默认是安装了opencv的库,除了nano,我们自己电脑上也想使用opencv做一些平时图像处理验证. 本来也是看一些资料安装好的,觉得也没 ...
随机推荐
- Redis极简教程
简介 Redis 是用C语言开发完全开源免费的,遵守BSD协议的,一个高性能的,key-value型的,NOSQL数据库. 特点 可以将内存中的数据持久化到硬盘中,重启的时候可以从硬盘中再次加载 拥有 ...
- 【0基础学爬虫】爬虫基础之自动化工具 Selenium 的使用
大数据时代,各行各业对数据采集的需求日益增多,网络爬虫的运用也更为广泛,越来越多的人开始学习网络爬虫这项技术,K哥爬虫此前已经推出不少爬虫进阶.逆向相关文章,为实现从易到难全方位覆盖,特设[0基础学爬 ...
- 2023年第七届蓝帽杯初赛wp
取证检材容器密码:Hpp^V@FQ6bdWYKMjX=gUPG#hHxw!j@M9 案情介绍 2021年5月,公安机关侦破了一起投资理财诈骗类案件,受害人陈昊民向公安机关报案称其在微信上认识一名昵称为 ...
- easyUI 多表头设置
- TienChin 渠道管理-渠道页面完善
最后附上渠道管理的数据 install SQL 语句: INSERT INTO TienChin.tienchin_channel (channel_id, channel_name, status, ...
- TienChin 运行 RuoYi-Vue3
在前几篇文章当中,之前使用的是 Vue2,在某一天发现若依提供了 Vue3 的版本,所以这篇文章主要是运行起来,Vue2,迟早要被替代,所以这里采用最先进的 Vue3. 仓库地址:https://gi ...
- 小白学k8s(11)-k8s中Secret理解
理解Secret 什么是Secret Secret的类型 Opaque Secret Opaque Secret的使用 将Secret挂载到Volume中 挂载的Secret会被自动更新 将Secre ...
- 【一】tensorflow【cpu/gpu、cuda、cudnn】全网最详细安装、常用python镜像源、tensorflow 深度学习强化学习教学
相关文章: [一]tensorflow安装.常用python镜像源.tensorflow 深度学习强化学习教学 [二]tensorflow调试报错.tensorflow 深度学习强化学习教学 [三]t ...
- 【STL源码剖析】list::sort真的好用吗?Centos7-Linux环境g++Release下vector数组排序和list排序效率测试【超详细的注释和解释】
说在前面的话 在使用C++的标准模板库的一些容器时,我们难免会遇到给序列排序的问题. 在学习list的时候,我们可能会了解到,algorithm::sort其实不是万能的. 当我们要给list排序的时 ...
- 5 款轻松上手的开源项目「GitHub 热点速览」
大家都忙一年了,所以今天来点轻松的吧!就是那种拿来直接用.免费看的开源项目. 开源真是一个充满惊喜的宝库,很多开源软件比收费软件还好用,比如这款开箱即用的电视直播软件:my-tv,它免费.无广告.启动 ...