Falcon 登陆 Hugging Face 生态
引言
Falcon 是由位于阿布扎比的 技术创新研究院 (Technology Innovation Institute,TII) 创建的一系列的新语言模型,其基于 Apache 2.0 许可发布。 值得注意的是,Falcon-40B 是首个“真正开放”的模型,其能力可与当前许多闭源模型相媲美。这对从业者、爱好者和行业来说都是个好消息,因为“真开源”使大家可以毫无顾忌地基于它们探索百花齐放的应用。
本文,我们将深入探讨 Falcon 模型: 首先探讨它们的独特之处,然后 展示如何基于 Hugging Face 生态提供的工具轻松构建基于 Falcon 模型的多种应用 (如推理、量化、微调等) 。
目录
Falcon 模型
Falcon 家族有两个基础模型: Falcon-40B 及其小兄弟 Falcon-7B。 40B 参数模型目前在 Open LLM 排行榜 中名列前茅,而 7B 模型在同等参数量的模型中表现最佳。
运行 Falcon-40B 需要约 90GB 的 GPU 显存 —— 虽然还是挺多的,但比 LLaMA-65B 少了不少,况且 Falcon-40B 的性能还优于 LLaMA-65B。而 Falcon-7B 只需要约 15GB 显存,即使在消费类硬件上也可以进行推理和微调。 (我们将在后文讨论如何使用量化技术在便宜的 GPU 上使用 Falcon-40B!)
TII 还提供了经过指令微调的模型: Falcon-7B-Instruct 以及 Falcon-40B-Instruct。这两个实验性的模型变体经由指令和对话数据微调而得,因此更适合当前流行的助理式任务。 如果你只是想把 Falcon 模型快速用起来,这两个模型是最佳选择。 当然你也可以基于社区构建的大量数据集微调一个自己的模型 —— 后文会给出微调步骤!
Falcon-7B 和 Falcon-40B 分别基于 1.5 万亿和 1 万亿词元数据训练而得,其架构在设计时就充分考虑了推理优化。 Falcon 模型质量较高的关键在于训练数据,其 80% 以上的训练数据来自于 RefinedWeb —— 一个新的基于 CommonCrawl 的网络数据集。 TII 选择不去收集分散的精选数据,而是专注于扩展并提高 Web 数据的质量,通过大量的去重和严格过滤使所得语料库与其他精选的语料库质量相当。 在训练 Falcon 模型时,虽然仍然包含了一些精选数据 (例如来自 Reddit 的对话数据),但与 GPT-3 或 PaLM 等最先进的 LLM 相比,精选数据的使用量要少得多。你知道最妙的是什么吗? TII 公布了从 RefinedWeb 中提取出的含有 6000 亿词元的数据集,以供社区在自己的 LLM 中使用!
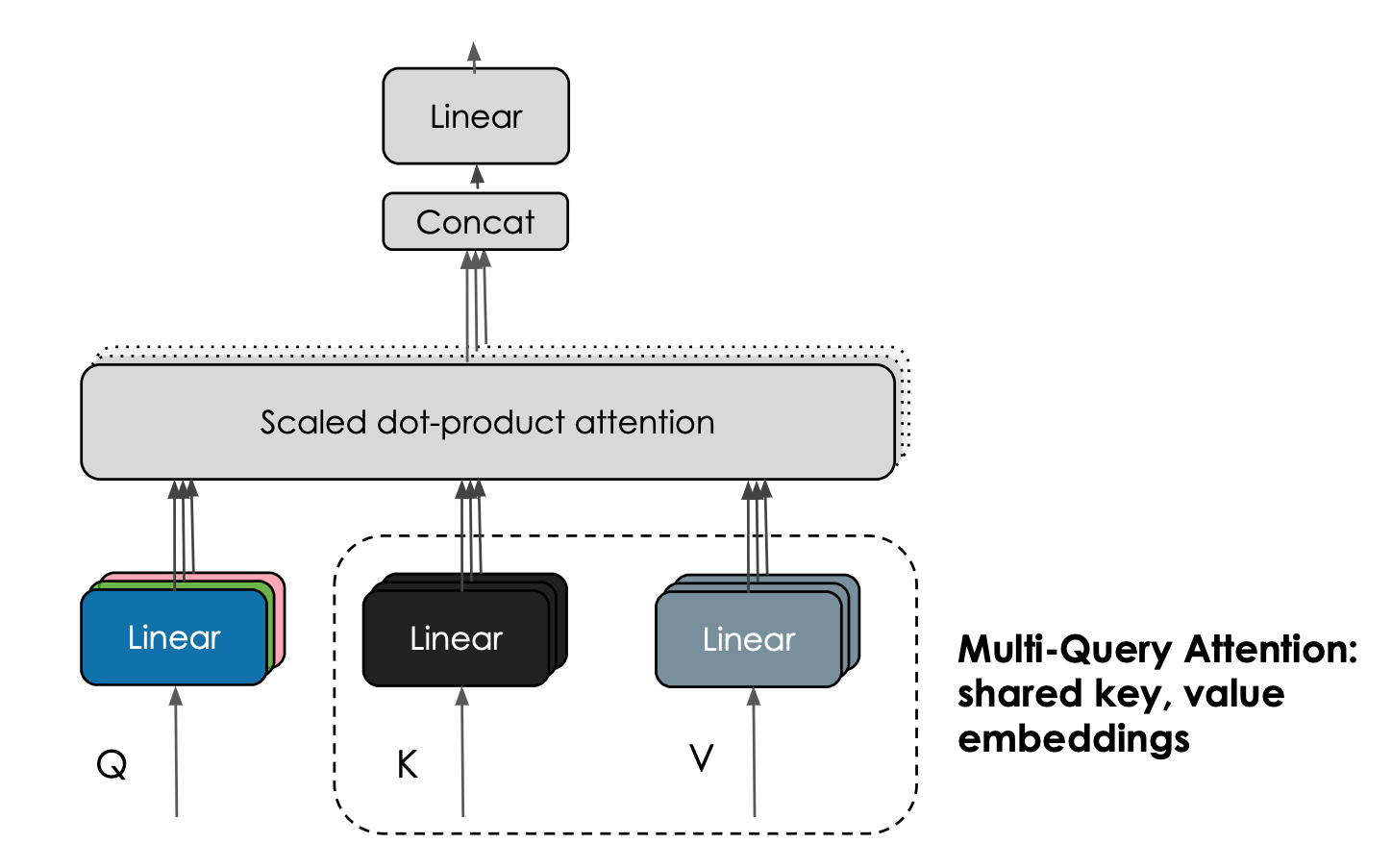
Falcon 模型的另一个有趣的特性是其使用了 多查询注意力 (multiquery attention)。原始多头 (head) 注意力方案每个头都分别有一个查询 (query) 、键 (key) 以及值 (value),而多查询注意力方案改为在所有头上共享同一个键和值。
 |
|---|
| 多查询注意力机制在注意力头之间共享同一个键嵌入和值嵌入。图片由 Harm de Vries 提供。 |
这个技巧对预训练影响不大,但它极大地 提高了推理的可扩展性: 事实上, 该技巧大大减少了自回归解码期间 K,V 缓存的内存占用,将其减少了 10-100 倍 (具体数值取决于模型架构的配置),这大大降低了模型推理的内存开销。而内存开销的减少为解锁新的优化带来了可能,如省下来的内存可以用来存储历史对话,从而使得有状态推理成为可能。
| 模型 | 许可 | 能否商用? | 预训练词元数 | 预训练算力 [PF-天] | 排行榜得分 | K,V 缓存大小 (上下文长度为 2048) |
|---|---|---|---|---|---|---|
| StableLM-Alpha-7B | CC-BY-SA-4.0 | 1,500B | 700 | 38.3* | 800MB | |
| LLaMA-7B | LLaMA license | 1,000B | 500 | 47.6 | 1,100MB | |
| MPT-7B | Apache 2.0 | 1,000B | 500 | 48.6 | 1,100MB | |
| Falcon-7B | Apache 2.0 | 1,500B | 700 | 48.8 | 20MB | |
| LLaMA-33B | LLaMA license | 1,500B | 3200 | 56.9 | 3,300MB | |
| LLaMA-65B | LLaMA license | 1,500B | 6300 | 58.3 | 5,400MB | |
| Falcon-40B | Apache 2.0 | 1,000B | 2800 | 60.4 | 240MB |
- 上表中得分均为经过微调的模型的得分
演示
通过 这个 Space 或下面的应用,你可以很轻松地试用一下大的 Falcon 模型 (400 亿参数!):
请点击 阅读原文 查看交互式示例。
上面的应用使用了 Hugging Face 的 Text Generation Inference 技术,它是一个可扩展的、快速高效的文本生成服务,使用了 Rust、Python 以及 gRPC 等技术。HuggingChat 也使用了相同的技术。
我们还构建了一个 Core ML 版本的 falcon-7b-instruct 模型,你可以通过以下方式将其运行至 M1 MacBook Pro:
请点击 阅读原文 观看视频。
该视频展示了一个轻量级应用程序,该应用程序利用一个 Swift 库完成了包括加载模型、分词、准备输入数据、生成文本以及解码在内的很多繁重的操作。我们正在快马加鞭构建这个库,这样开发人员就能基于它将强大的 LLM 集成到各种应用程序中,而无需重新发明轮子。目前它还有点粗糙,但我们迫不及待地想让它早点面世。同时,你也可以下载 Core ML 的权重文件 自己探索!
推理
在使用熟悉的 transformers API 在你自己的硬件上运行 Falcon 模型时,你需要注意几个以下细节:
- 现有的模型是用
bfloat16数据类型训练的,因此建议你也使用相同的数据类型来推理。使用bfloat16需要你安装最新版本的 CUDA,而且bfloat16在最新的卡 (如 A100) 上效果最好。你也可以尝试使用float16进行推理,但请记住,目前我们分享的模型效果数据都是基于bfloat16的。 - 你需要允许远程代码执行。这是因为
transformers尚未集成 Falcon 模型架构,所以,我们需要使用模型作者在其代码库中提供的代码来运行。以falcon-7b-instruct为例,如果你允许远程执行,我们将使用下列文件里的代码来运行模型: configuration_RW.py,modelling_RW.py。
综上,你可以参考如下代码来使用 transformers 的 pipeline API 加载 falcon-7b-instruct 模型:
from transformers import AutoTokenizer
import transformers
import torch
model = "tiiuae/falcon-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
然后,再用如下代码生成文本:
sequences = pipeline(
"Write a poem about Valencia.",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
最后,你可能会得到如下输出:
Valencia, city of the sun
The city that glitters like a star
A city of a thousand colors
Where the night is illuminated by stars
Valencia, the city of my heart
Where the past is kept in a golden chest
对 Falcon 40B 进行推理
因为 40B 模型尺寸比较大,所以要把它运行起来还是挺有挑战性的,单个显存为 80GB 的 A100 都放不下它。如果用 8 比特模型的话,需要大约 45GB 的空间,此时 A6000 (48GB) 能放下但 40GB 的 A100 还是放不下。相应的推理代码如下:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "tiiuae/falcon-40b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
load_in_8bit=True,
device_map="auto",
)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
需要注意的是,INT8 混合精度推理使用的浮点精度是 torch.float16 而不是 torch.bfloat16,因此请务必详尽地对结果进行测试。
如果你有多张 GPU 卡并安装了 accelerate,你还可以用 device_map="auto" 将模型的各层自动分布到多张卡上运行。如有必要,甚至可以将某些层卸载到 CPU,但这会影响推理速度。
在最新版本的 bitsandbytes、transformers 以及 accelerate 中我们还支持了 4 比特加载。此时,40B 模型仅需约 27GB 的显存就能运行。虽然这个需求还是比 3090 或 4090 这些卡所能提供的显存大,但已经足以在显存为 30GB 或 40GB 的卡上运行了。
Text Generation Inference
Text Generation Inference 是 Hugging Face 开发的一个可用于生产的推理容器。有了它,用户可以轻松部署大语言模型。
其主要特点有:
- 对输入进行流式 batch 组装 (batching)
- 流式生成词,主要基于 SSE 协议 (Server-Sent Events,SSE)
- 推理时支持多 GPU 张量并行 (Tensor Parallelism ),推理速度更快
- transformers 模型代码由定制 CUDA 核函数深度优化
- 基于 Prometheus 和 Open Telemetry 的产品级日志记录、监控和跟踪机制
从 v0.8.2 起,Text Generation Inference 原生支持 Falcon 7b 和 40b 模型,而无需依赖 transformers 的 “信任远程代码 (trust remote code)” 功能。因此,Text Generation Inference 可以支持密闭部署及安全审计。此外,我们在 Falcon 模型的实现中加入了定制 CUDA 核函数优化,这可显著降低推理的端到端延迟。
 |
|---|
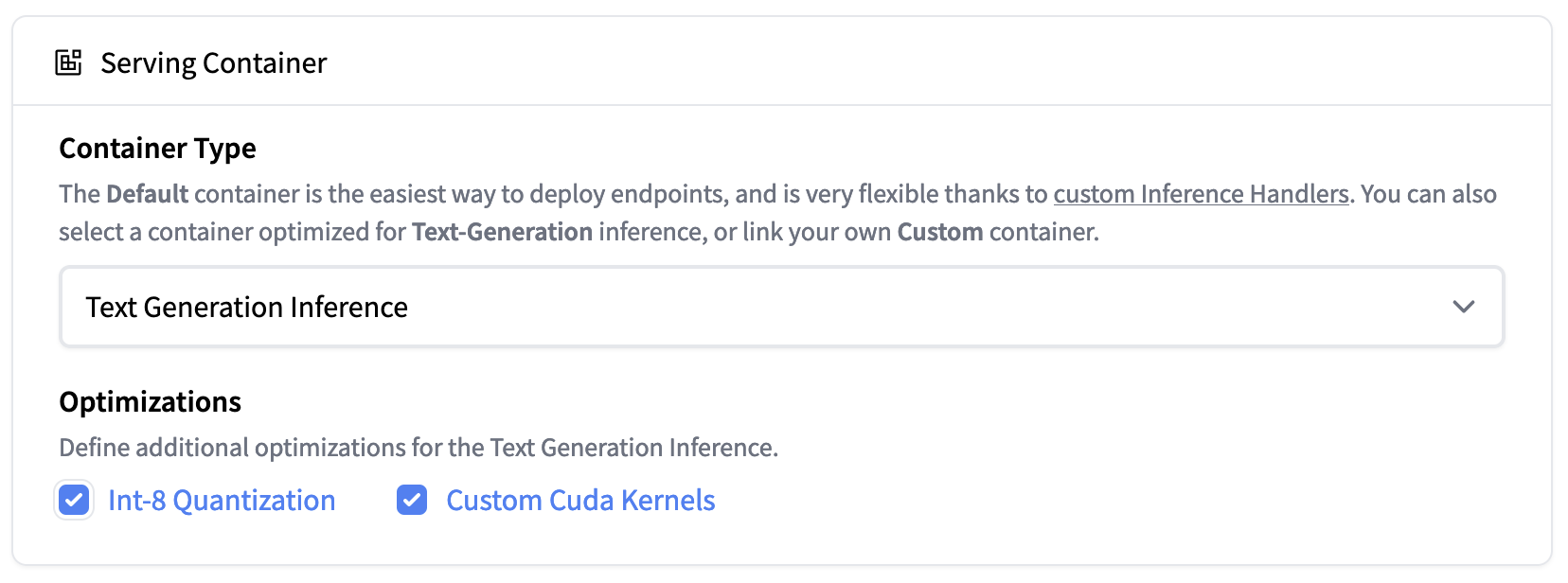
Hugging Face Inference Endpoint 现已支持 Text Generation Inference。你可以在单张 A100 上轻松部署 falcon-40b-instruct 的 Int8 量化模型。 |
Text Generation Inference 现已集成至 Hugging Face 的 Inference Endpoint。想要部署 Falcon 模型,可至 模型页面 并点击 Deploy -> Inference Endpoints 按钮。
如需部署 7B 模型,建议选择 “GPU [medium] - 1x Nvidia A10G”。
如需部署 40B 模型,你需要在 “GPU [xlarge] - 1x Nvidia A100” 上部署且需要开启量化功能,路径如下:
Advanced configuration -> Serving Container -> Int-8 Quantization
注意: 在此过程中,如果你需要升级配额,可直接发电子邮件至 api-enterprise@huggingface.co 申请。
评估
那么 Falcon 模型究竟效果如何? Falcon 的作者们马上将会发布一个深入的评估数据。这里,我们仅在我们的 Open LLM 排行榜 上对 Falcon 基础模型和指令模型进行一个初步评估。 Open LLM 排行榜主要衡量 LLM 的推理能力及其回答以下几个领域的问题的能力:
- AI2 推理挑战 (ARC): 小学程度有关科学的选择题。
- HellaSwag: 围绕日常事件的常识性问题。
- MMLU: 57 个科目 (包含职业科目及学术科目) 的选择题。
- TruthfulQA: 测试模型从一组错误陈述中找出事实性陈述的能力。
结果显示,40B 基础模型和指令模型都非常强,目前在 Open LLM 排行榜 上分列第一和第二!
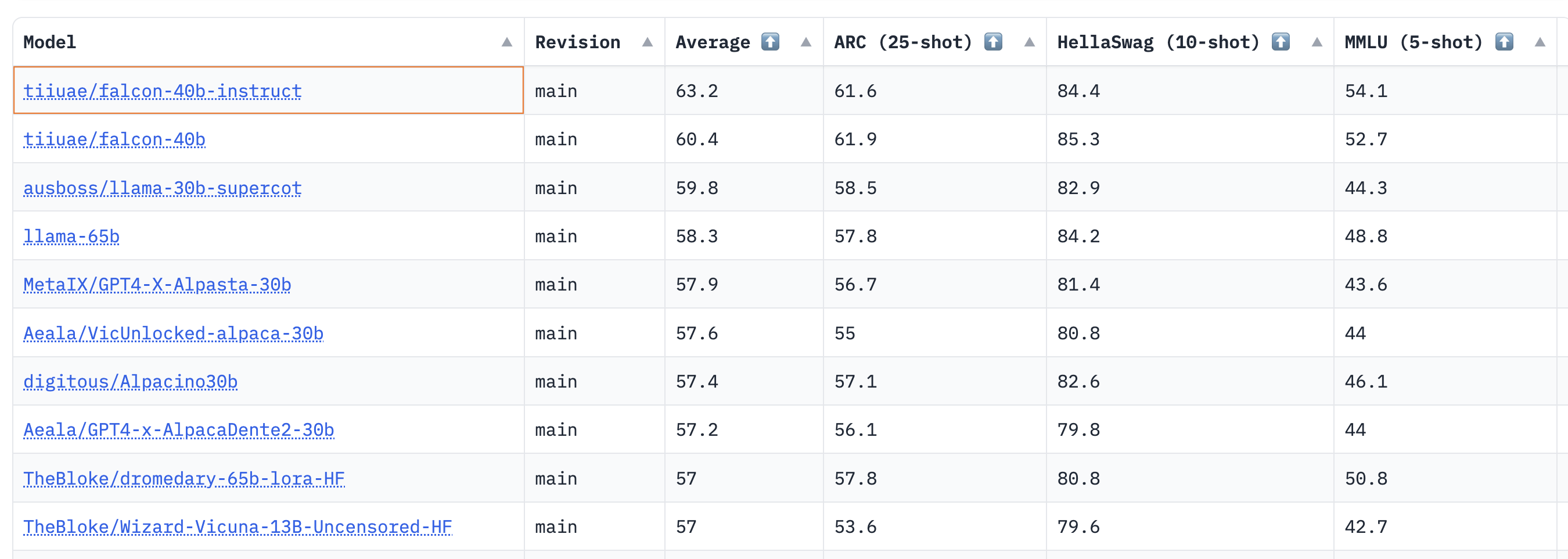
正如 Thomas Wolf 所述,我们惊喜地发现,目前预训练 40B 模型所用的计算量大约只有 LLaMa 65B 所用计算量的一半 (Falcon 40B 用了 2800 petaflop- 天,而 LLaMa 65B 用了 6300 petaflop- 天),这表明该模型甚至尚未完全预训练至 LLM 的“最佳”极限。
对 7B 模型而言,我们发现其基础模型表现优于 llama-7b,并超过了 MosaicML 的 mpt-7b,成为当前该规模上最好的预训练 LLM。下面摘录了排行榜中一些热门模型的排名情况,以供比较:
| 模型 | 类型 | 排行榜平均得分 |
|---|---|---|
| tiiuae/falcon-40b-instruct | instruct | 63.2 |
| tiiuae/falcon-40b | base | 60.4 |
| llama-65b | base | 58.3 |
| TheBloke/dromedary-65b-lora-HF | instruct | 57 |
| stable-vicuna-13b | rlhf | 52.4 |
| llama-13b | base | 51.8 |
| TheBloke/wizardLM-7B-HF | instruct | 50.1 |
| tiiuae/falcon-7b | base | 48.8 |
| mosaicml/mpt-7b | base | 48.6 |
| tiiuae/falcon-7b-instruct | instruct | 48.4 |
| llama-7b | base | 47.6 |
尽管 Open LLM 排行榜 不能衡量聊天能力 (这方面目前主要还是依赖人类评估),但截至目前 Falcon 模型表现出的这些初步效果依然非常鼓舞人心!
现在让我们来看看如何微调一个你自己的 Falcon 模型 —— 或许你微调出来的某一个模型最终会登上榜首。
用 PEFT 微调
训练 10B+ 大小的模型在技术和计算上都颇具挑战。在本节中,我们将了解如何使用 Hugging Face 生态中软件工具在简单的硬件上高效地微调超大模型,并展示如何在单张英伟达 T4 卡 (16GB - Google Colab) 上微调 falcon-7b。
我们以在 Guanaco 数据集 上微调 Falcon 为例。Guanaco 数据集是 Open Assistant 数据集 的一个高质量子集,其中包含大约 1 万个对话。通过 PEFT 库,我们可以使用最新的 QLoRA 方法用 4 比特来表示模型,并冻结它,再在其上加一个适配子模型 (adapter),并微调该适配子模型。你可以 从这篇博文中 了解有关 4 比特量化模型的更多信息。
因为在使用低阶适配器 (Low Rank Adapters,LoRA) 时只有一小部分模型权重是可训练的,所以可训练参数的数量和训得模型的尺寸都会显著减小。如下图所示,最终的训练产物 (trained artifact) 与原始的 7B 模型 (数据类型为 bfloat16 时占 15GB 存储空间) 相比,只占 65MB 存储空间。
 |
|---|
| 与大约 15GB 的原始模型(半精度)相比,最终的训练产物只需存储 65MB 的权重 |
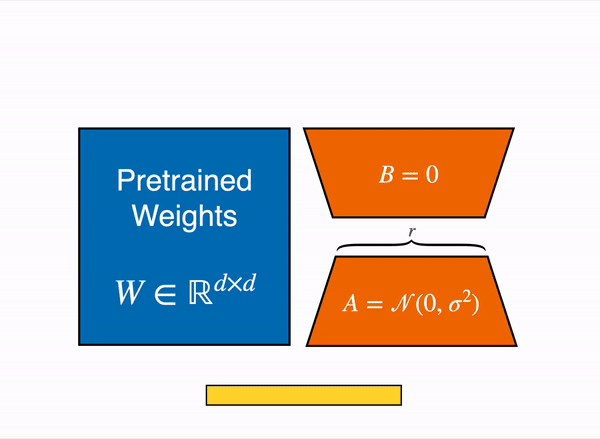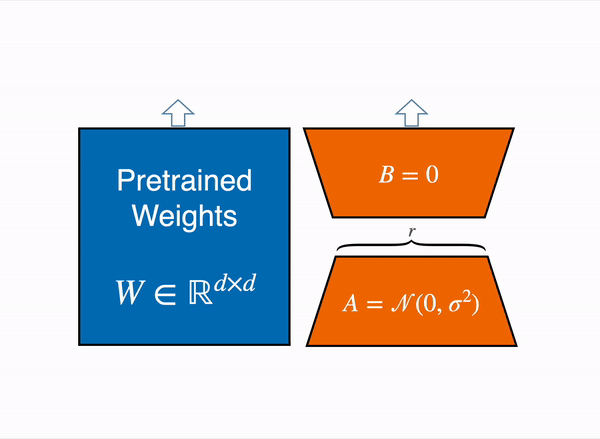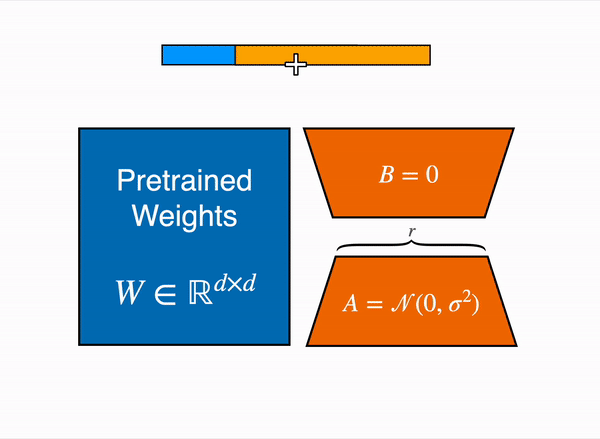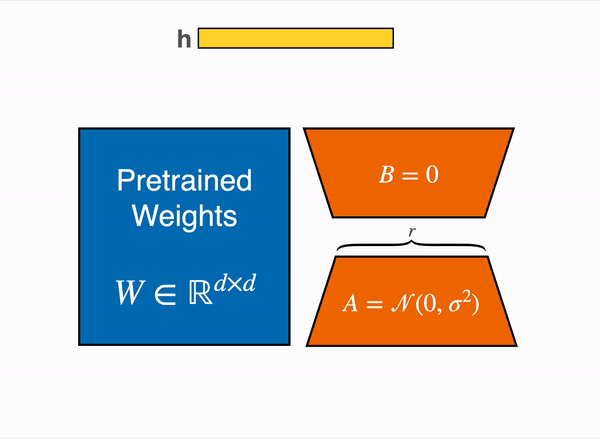
更具体地说,在选定需要微调的模块 (即注意力模块的查询映射层和键映射层) 之后,我们在每个目标模块旁边添加两个小的可训练线性层 (如下图所示) 作为适配子模型。然后,将适配子模型输出的隐含状态与原始模型的隐含状态相加以获得最终隐含状态。
 |
|---|
| 用由权重矩阵 A 和 B 组成的低秩适配器(右)的输出激活来增强原始(冻结)预训练模型(左)的输出激活。 |
一旦训练完成,无须保存整个模型,因为基础模型一直处于冻结状态。此外,原始模型可以表示为任意数据类型 (int8、fp4、fp16 等),只要在与适配器的输出隐含状态相加前,将其输出隐含状态的数据类型转换成与适配器相同的数据类型即可 —— bitsandbytes 的模块 ( Linear8bitLt 和 Linear4bit ) 就是这么做的, Linear8bitLt 和 Linear4bit 这两个模块的输出数据类型与原未量化模型的输出数据类型相同。
我们在 Guanaco 数据集上微调了 Falcon 模型的两个变体 (7B 和 40B)。其中,7B 模型是在单 NVIDIA-T4 16GB 上微调的,而 40B 模型是在单 NVIDIA A100 80GB 上微调的。在微调时,我们使用了 4 比特量化的基础模型以及 QLoRA 方法,并使用了 来自 TRL 库的最新的 SFTTrainer。
此处 提供了使用 PEFT 重现我们实验的完整脚本。但是如果你想快速运行 SFTTrainer (而无需 PEFT) 的话,只需下面几行代码即可:
from datasets import load_dataset
from trl import SFTTrainer
from transformers import AutoTokenizer, AutoModelForCausalLM
dataset = load_dataset("imdb", split="train")
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, trust_remote_code=True)
trainer = SFTTrainer(
model,
tokenizer=tokenizer
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=512,
)
trainer.train()
你还可以查看 原始 QLoRA 代码库,以了解有关如何评估训练模型的更多详细信息。
关于微调的资源
- 使用 4 比特量化和 PEFT 在 Guanaco 数据集上微调 Falcon-7B 的 Colab notebook
- 训练代码
- 40B 模型的 LoRA 模型 (日志)
- 7B 模型的 LoRA 模型 (日志)
总结
Falcon 是最新的、令人兴奋的、可商用的大语言模型。在本文中,我们展示了 Falcon 模型的功能、如何在你自己的环境中运行 Falcon 模型以及在 Hugging Face 生态中如何轻松地用自有数据微调它们。我们期待看到社区如何使用 Falcon 模型!
英文原文: https://hf.co/blog/falcon
原文作者:Leandro von Werra,Younes Belkada,Sourab Mangrulkar,Lewis Tunstall,Olivier Dehaene,Pedro Cuenca,Philipp Schmid
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
排版/审校: zhongdongy (阿东)
Falcon 登陆 Hugging Face 生态的更多相关文章
- AI 影评家:用 Hugging Face 模型打造一个电影评分机器人
本文为社区成员 Jun Chen 为 百姓 AI 和 Hugging Face 联合举办的黑客松所撰写的教程文档,欢迎你阅读今天的第二条推送了解和参加本次黑客松活动.文内含有较多链接,我们不再一一贴出 ...
- SphereEx 登陆 ApacheCon Asia|依托 ShardingSphere 可插拔架构体系打造数据应用完整生态
2021 年 8 月 8 日,ApacheCon 首次亚洲大会于线上正式闭幕.作为久负盛名的开源盛宴,本届 ApacheCon Asia 受到了海内外众多开源领域人士的关注. 作为 Apache 软件 ...
- 互联网云生态下DDOS安全产品的一些考虑和测试方法(一)
DDOS攻击简介 安全的三要素——“保密性”.“完整性”和“可用性”中,DOS(Denial of Service拒绝服务攻击)所针对的目标是服务的“可用性”.这种攻击方式利用目标系统的网络服务功能缺 ...
- angularjs框架及其生态环境 --待续
angular的MVVM框架结构: 1. app, 2.routes, config, 3.module, 4.Controller, $scope,controller参数,事件 ...
- centos安装 Falcon+
1:环境 准备 : 安装 go环境 :下载 - Golang中国 参照 :http://www.cnblogs.com/Amos-Turing/p/8494250.html 安装 mysql 安装 r ...
- 浅谈API网关(API Gateway)如何承载API经济生态链
序言 API经济生态链已经在全球范围覆盖, 绝大多数企业都已经走在数字化转型的道路上,API成为企业连接业务的核心载体, 并产生巨大的盈利空间.快速增长的API规模以及调用量,使得企业IT在架构上.模 ...
- PS4游戏将登陆PC:一曲属于主机的悲歌
曾经,红白机.PS游戏机等成为一代人难以磨灭的记忆.而随后的索尼PS3.微软Xbox 360.任天堂Wii U等,也称霸了次时代主机时代,成为家庭娱乐的中心.但面对着依托于PC和智能移动终端 ...
- 分布式计算框架-Spark(spark环境搭建、生态环境、运行架构)
Spark涉及的几个概念:RDD:Resilient Distributed Dataset(弹性分布数据集).DAG:Direct Acyclic Graph(有向无环图).SparkContext ...
- HDD深圳站:全生命周期赋能开发者,华为引领应用生态升级
12月14日,由华为开发者联盟主办的HDD(HUAWEI Developer Day)于深圳举行.此次HDD主论坛,围绕打造应用全生命周期服务,介绍了华为在创新孵化.开发测试.应用分发和运营增长阶段的 ...
- 获明略科技B+轮战略投资,思迈特软件Smartbi用强产品思维推动BI生态完善
今天,商业智能BI和大数据分析产品提供商思迈特软件(Smartbi)宣布完成亿级B+轮战略融资,本轮投资方为领先的全球企业级数据分析和组织智能服务平台提供商--明略科技. 此前,思迈特软件曾先后获得来 ...
随机推荐
- sealos踩坑记录
前言 记录下我安装sealos的踩坑历程,全网基本没有什么类似的可靠资料,也许是因为太小众了吧,希望能帮助到搜索到此文的人. sealos是什么 Sealos 是以 kubernetes 为内核的云操 ...
- EF Core从TPH迁移到TPT
Intro EF Core支持多种方式处理具有继承关系的表,现在支持TPH.TPC(EF Core 7).TPT,具体的实现方式可以参考官方文档和这篇文章. 大致总结一下不同的方式的区别: TPH:所 ...
- Java设计模式 —— 外观模式
13 外观模式 13.1 外观模式概述 Facade Pattern: 为子系统的接口提供一组统一的入口.外观模式定义了一个高层接口,这个接口使得子系统的更加容易使用. 在外观模式中,一个子系统的外部 ...
- Anaconda 安装 PyTorch 和 DGL
安装 PyTorch Anaconda 是 PyTorch 官方推荐的包管理工具,它会帮助安装所有的依赖项.当使用 conda 安装的时候,可能会出现下载过慢的问题,需要更换清华源来代替默认的cond ...
- day117:MoFang:宠物栏的功能实现&宠物道具的使用
目录 1.宠物栏的功能实现 2.宠物道具的使用 1.宠物栏的功能实现 1. 宠物的显示 2. 宠物的使用 3. 宠物的饱食度 4. 宠物的开锁 1.服务端提供显示宠物的api接口 orchard/so ...
- OctConv:八度卷积复现
摘要:不同于传统的卷积,八度卷积主要针对图像的高频信号与低频信号. 本文分享自华为云社区<OctConv:八度卷积复现>,作者:李长安 . 论文解读 八度卷积于2019年在论文<Dr ...
- The first week match's mistake
比赛中的补题中的一些错误 P8506 标题计数(https://www.luogu.com.cn/problem/P8506) 第一眼下去,嗯..贪了,只读到一个'#'后边跟一个空格就+1,结果wa几 ...
- day01-项目介绍&功能实现
项目介绍&功能实现 1.项目介绍&环境搭建 一个以社交平台为核心的轻电商项目,功能如下: 短信登录.商户查询缓存.优惠券秒杀.达人探店.好友关注.附近的商户.用户签到.UV统计 1.1 ...
- Function-advanced
函数进阶 1. 函数防抖 在频率触发的情况下 只有等待一定的时间才会触发 执行一次代码 特点 执行之前先清除之前的即将执行操作 保证只有最后一次生效 优化高频执行JS代码操作 提高性能 防抖代码实现 ...
- FLV文件分析
很久没看,做下关于FLV文件格式知识点回顾! 一.简单介绍 FLV(Flash Video)是Adobe公司推出的一种媒体封装格式.一个FLV文件,每个Tag类型都属于一个流.也就是说一 ...