【赵渝强老师】阿里云大数据ACP认证之阿里大数据产品体系

阿里大数据产品体系是基于阿里云飞天平台上的数据处理服务。主要分为阿里云大数据基础产品和阿里云数加平台,其产品架构图如下所示:
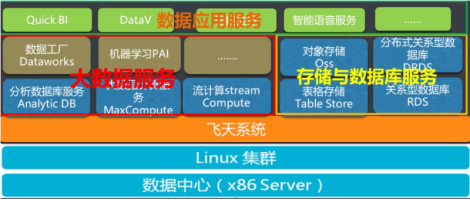
一、阿里云大数据基础产品
1、云数据库——RDS(ApsaraDB for RDS的简称)
- 稳定可靠、可弹性伸缩的在线数据库服务
- 即开即用,DMS可视化界面
- 兼容MySQL,SQL server,PG等关系型数据库
- 提供数据库在线扩容,备份回滚,性能监控及分析等功能
- 只读实例和临时实例
优势:
- 双机热备——秒级切换,服务可用性达99.5%
- 安全防护——防DDOS攻击,SQL注入警告,数据多重备份
- 简单易用——一键式数据迁移,可视化管理操作
2、分布式关系型数据库——DRDS(Distributed Relational Database Service)
- 基于RDS的分布式数据存储和检索产品
- 水平拆分可平滑扩展
- 解决用户单RDS无法支撑业务的苦难
- 降低用户使用分布式数据库的难度
优势:
- 简单易用——兼容MySQL(交互协议、SQL)
- 稳定可靠——共享阿里组件
- 分布式——水平拆分,容量达到单节点百倍
- 可扩展——增减节点对应用几乎无影响,高效数据迁移
3、表格存储——TS(Table Store)
- 构建在阿里云飞天分布式系统上的NoSQL数据存储服务
- 海量结构化数据的存储和实时访问
- 弹性资源预留
- 实时监控显示
优势:
- 稳定——自动故障检测和恢复,系统可用性99.9%
- 安全——用户级别的数据隔离、访问控制和权限管理,数据冗余备份
- 大规模——单表到百TB级数据存储
- 高性能——毫秒级别单行读写延迟,十万级别QPS
4、分析型数据库——ADB(Analytic DB)
- 海量数据实时高并发在线分析云计算平台
- 自由的计算和查询能力
- 高可用性和高安全性
- 全面兼容MySQL协议
优势:
- 高度的计算自由——通过SQL进行灵活的多维分析、数据透视、数据筛选等
- 急速的响应时间——毫秒级的千亿级数据透视,毫秒级的大表关联计算
- 简单的使用方式——标准SQL,支持标准MySQL协议,内置多种云平台数据的输入输出
- 丰富的特点功能——高性能自动索引,海量数据的急速导出等
5、大数据计算服务——MaxCompute
- 针对TP/BP级数据、实时性要求不高的分布式处理能力
- 大数据运算能力
- 开箱即用
- 数据安全
优势:
- 分布式——分布式集群架构,可灵活扩展
- 安全性——自动存储容错机制,所有计算都在沙箱进行
- 易用性——全面支持基于SQL的数据处理,提供标准API,高并发高吞吐量的数据上传下载
- 管理与授权——多用户管理协同分析数据,多种方式对用户权限管理,灵活的数据访问控制决策
6、数据集成(Data Integration)
数据集成是阿里集团对外提供的稳定高效、弹性伸缩的数据同步平台,为阿里云大数据计算引擎提供的离线(批量)数据进出通道。
优势:
- 多:支持数据源种类多,多样数据通道,齐全的数据传输方式,丰富的数据处理插件;
- 快:高效的调用方式,强劲的传输速度,强大的吞吐力;
- 好:健壮的传输通道,智能的错误检测,自动的传输恢复;
- 省:开箱即用,动态分配,弹性伸展,按需申请,按量付费;
7、对象存储(Object Storage Service,简称OSS)
- 提供海量、安全、低成本、高可靠的云存储服务;
- 即开即用,无限大空间的存储集群;
- 通过API/SDK接口或OSS迁移工具方便将海量数据移入或移除;
- 存储对象操作具有原子性,强一致性;
优势:
- 可靠:服务可用性99.99%,数据持久性99.999999999%(9个9),多重备份,规模自动扩展;
- 安全:用户级别的资源隔离,异地容灾,企业级多层安全防护,多种授权机制;
- 低成本:多线GBP骨干网络,无带宽限制,上行流量免费;
- 多种类数据处理能力:图片处理、音视频转码、内容加速分发、鉴黄服务,归档服务等。
二、阿里云数加平台
阿里云数据产品均集成在数加平台,阿里云公共云数加平台的定位:一站式数据平台(集成包括从基础数据分析应用到大数据开发、调度、运维,到机器学习等);提供三层服务(底层计算、数据平台分析工具、应用层服务)行业解决方案。
1、DataWorks(原Data IDE)
数据工场DataWorks(原大数据开发套件Data IDE)是基于MaxCompute作为计算和存储引擎的用于工作流可视化开发和托管调度运维的海量数据离线加工分析平台。
优势:
- 专业:阿里多年DW/BI经验沉淀,全链路解决方案,高效率低成本;
- 功能强大:集成式组件服务,多种异构数据源支持,多人协同代码开发,完善的版本管理,分钟、小时级调度、拖拽式数据分析与可视化算法建模;
- 大数据处理能力:完美融合Max Compute,支持十万级任务的有序运行及管理。
2、Quick BI
提供海量数据实时在线分析服务,支持拖拽式操作,提供了丰富的可视化效果,可以轻松自如地完成数据分析,业务数据探查,报表制作等工作。
优势:
- 门槛低:拖拽操作,简单易用;
- 功能强:多样的解决方案,丰富的展现手段;
- 大数据处理能力:数据分析,数据处理能力强大
3、机器学习PAI
- 基于MaxCompute、GPU集群,支持MR、MPI、SQL、BSP、SPARK等计算类型;
- 内置阿里、蚂蚁多年沉淀的分布式算法,支持百亿级数据量训练;
- WEB界面,通过拖、拉、拽等方式即可完成复杂数据挖掘流程;
优势:
- 提供从数据预处理到模型评估的一站式平台服务,显著降低大数据算法建模门槛;
- 支持自定义算法和组件,灵活开放的个性化设置,极大地提高了建模效率;
- 提供丰富的分布式算法,提高模型精度,助力海量数据中挖掘出业务价值。
【赵渝强老师】阿里云大数据ACP认证之阿里大数据产品体系的更多相关文章
- 大数据实时处理-基于Spark的大数据实时处理及应用技术培训
随着互联网.移动互联网和物联网的发展,我们已经切实地迎来了一个大数据 的时代.大数据是指无法在一定时间内用常规软件工具对其内容进行抓取.管理和处理的数据集合,对大数据的分析已经成为一个非常重要且紧迫的 ...
- BL老师的建议,数学不好的,大数据一票否决--后赋从java转大数据
__________________________ 作者:我是蛋蛋链接:https://www.zhihu.com/question/59593387/answer/167235075来源:知乎著作 ...
- MySQL随机获取数据的方法,支持大数据量
最近做项目,需要做一个从mysql数据库中随机取几条数据出来. 总所周知,order by rand 会死人的..因为本人对大数据量方面的只是了解的很少,无解,去找百度老师..搜索结果千篇一律.特发到 ...
- [Hadoop 周边] Hadoop和大数据:60款顶级大数据开源工具(2015-10-27)【转】
说到处理大数据的工具,普通的开源解决方案(尤其是Apache Hadoop)堪称中流砥柱.弗雷斯特调研公司的分析师Mike Gualtieri最近预测,在接下来几年,“100%的大公司”会采用Hado ...
- Hadoop和大数据:60款顶级大数据开源工具
一.Hadoop相关工具 1. Hadoop Apache的Hadoop项目已几乎与大数据划上了等号.它不断壮大起来,已成为一个完整的生态系统,众多开源工具面向高度扩展的分布式计算. 支持的操作系统: ...
- 【转载】Hadoop和大数据:60款顶级大数据开源工具
一.Hadoop相关工具 1. Hadoop Apache的Hadoop项目已几乎与大数据划上了等号.它不断壮大起来,已成为一个完整的生态系统,众多开源工具面向高度扩展的分布式计算. 支持的操作系统: ...
- Druid:一个用于大数据实时处理的开源分布式系统——大数据实时查询和分析的高容错、高性能开源分布式系统
转自:http://www.36dsj.com/archives/28590 Druid 是一个用于大数据实时查询和分析的高容错.高性能开源分布式系统,旨在快速处理大规模的数据,并能够实现快速查询和分 ...
- Data - 【转】数据统计、数据挖掘、大数据、OLAP的区别
原文链接 数据分析 数据分析是一个大的概念,理论上任何对数据进行计算.处理从而得出一些有意义的结论的过程,都叫数据分析. 从数据本身的复杂程度.以及对数据进行处理的复杂度和深度来看,可以把数据分析分为 ...
- C#将dataGridView中显示的数据导出到Excel(大数据量超有用版)
开发中非常多情况下须要将dataGridView控件中显示的数据结果以Excel或者Word的形式导出来,本例就来实现这个功能. 因为从数据库中查找出某些数据列可能不是必需显示出来,在dataGrid ...
- 【MySQL】随机获取数据的方法,支持大数据量
在mysql中带了随机取数据的函数,在mysql中我们会有rand()函数,很多朋友都会直接使用,如果几百条数据肯定没事,如果几万或百万时你会发现,直接使用是错误的.下面我来介绍随机取数据一些优化方法 ...
随机推荐
- GraphRAG介绍
GraphRAG GraphRAG 是一种基于图的检索增强方法,由微软开发并开源.它通过结合LLM和图机器学习的技术,从非结构化的文本中提取结构化的数据,构建知识图谱,以支持问答.摘要等多种应用场景. ...
- git 提交备注规范
git 提交规范commit message = subject + :+ 空格 + message 主体 例如:feat:增加用户注册功能 常见的 subject 种类以及含义如下: feat: 新 ...
- web3 产品介绍 MyEtherWallet 方便和智能合约交互的钱包
MyEtherWallet(简称MEW)是一款流行的去中心化以太坊钱包,它允许用户在安全且简单的界面中管理自己的以太坊资产.在本文中,我们将介绍MyEtherWallet的主要特点.功能以及如何使用它 ...
- 【爬虫】Java爬取省市县行政区域统计数据
前言 网上看了好几个Python爬虫来爬取省市县行政区域统计 官网除了省市县以外,还有区,街道,居委村委层级 https://zhuanlan.zhihu.com/p/512852193 所以自己用J ...
- 【Java】三元运算符 类型提升 问题
代码片段: @Test public void test() { Object o = true ? new Integer(1) : new Double(2); System.out.printl ...
- 【Java】MultiThread 多线程 Re01
学习参考: https://www.bilibili.com/video/BV1ut411T7Yg 一.线程创建的四种方式: 1.集成线程类 /** * 使用匿名内部类实现子线程类,重写Run方法 * ...
- 【Java】Map 映射接口 概述
Map 映射接口 概述 Map是一个双列数据,存储K-V类型的数据 JDK1.2 - HashMap 是目前Map的主要实现类 JDK1.2 线程不安全的,效率高,可存储null的key和value ...
- 【DataBase】MySQL 02 MySQL的配置详细
参考至视频:P8 - P11部分 https://www.bilibili.com/video/BV1xW411u7ax 配置文件的介绍 最基本的只需要这三项就行了,演示的其他配置在新版都不支持了貌似 ...
- 【PostgreSQL】01 环境搭建
[PostgreSQL数据库安装] 数据库本体就没下本机了,直接挂服务器的Docker上面跑 docker pull postgres:9.4 创建容器并运行: docker run --name p ...
- Git安装与windows终端配置Git-bash
Git概述 简介 Git是一个分布式版本控制工具,通常用来对软件开发过程中的源代码文件进行管理.通过Git仓库存储和管理这些文件,Git仓库分为两种: 本地仓库:开发人员自己电脑上的Git仓库 远程仓 ...