kubernetes CNI(Container Network Inferface)
为什么需要 CNI
在 kubernetes 中,pod 的网络是使用 network namespace 隔离的,但是我们有时又需要互相访问网络,这就需要一个网络插件来实现 pod 之间的网络通信。CNI 就是为了解决这个问题而诞生的。CNI 是 container network interface 的缩写,它是一个规范,定义了容器运行时如何配置网络。CNI 插件是实现了 CNI 规范的二进制文件,它可以被容器运行时调用,来配置容器的网络。
Docker 网络
基础
计算机五层网络如下:

如果我们想把 pod 中的网络对外,首先想到的就是七层代理,比如nginx,但是我们并不知道 pod 里的网络一定是 http,甚至他可能不是tcp。所以我们像做一些网络操作,就不能在五层做了,只能在二三四层做。
Docker 实验
当我们在物理机上启动 docker daemon 不需要启动任何容器的时候,使用 ip a 命令查看网卡,发现多了一个 docker0
4: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:9b:65:e1:01 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
docker0 是一个 linux Bridge 设备,这个可以理解成一个虚拟的交换机,用来做二层网络的转发。当我们启动一个容器的时候,docker 会为这个容器创建一个 veth pair 设备,一个端口挂载在容器的 network namespace 中,另一个端口挂载在 docker0 上。这样容器就可以和 docker0 上的其他容器通信了。
docker run -d --rm -it ubuntu:22.04 sleep 3000
在物理机上查看 ip a
8: veth6bc75d9@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether d6:87:ca:5c:54:51 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::d487:caff:fe5c:5451/64 scope link
valid_lft forever preferred_lft forever
docker 容器里面 ip a
7: eth0@if8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
再启动一个 docker
docker run --name test -d --rm -it ubuntu:22.04 sleep 3000
# ip a
9: eth0@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:03 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.3/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
这样两个容器就可以通过 docker0 通信了。
root@b19a3dc4b32d:/# ping 172.17.0.2
PING 172.17.0.2 (172.17.0.2) 56(84) bytes of data.
64 bytes from 172.17.0.2: icmp_seq=1 ttl=64 time=0.055 ms
通信方式

CNI 网络
当两个 pod 在同一 node 上的时候,我们可以使用像上述 docker 的 bridge 的方式通信是没问题的。但是 kubernetes 是这个多节点的集群,当 pod 在不同的 node 上的时候,直接通信肯定不行了,这时候我们需要一些办法来解决这个问题。
UDP 封包
当 pod 在不同节点上的时候,两个 pod 不可以直接通信,那最简单的方式就是通过 udp 封包,把整个网络包使用 udp 封包起来,然后第二个节点再解包,然后发给网桥。
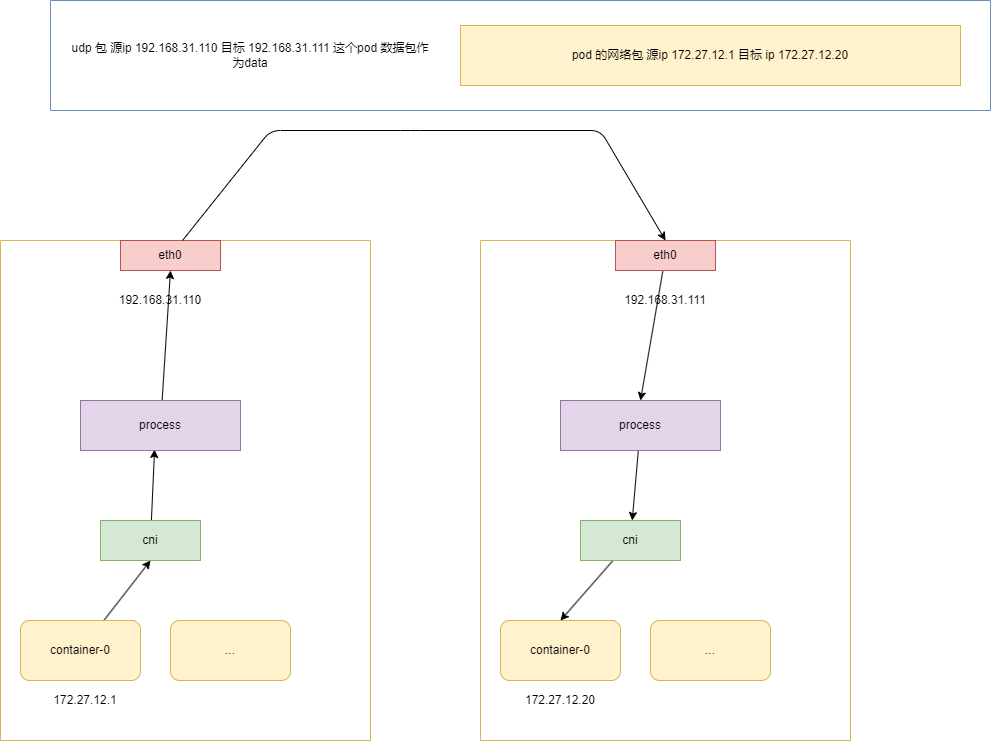
整个过程就是 node1 上的 pod 把网络包封装,然后由于 process 再封装发给 node2,node2 再解包,然后发给 pod2。
process 是 cni 实现的进程,很多 cni 都实现 udp 封包的方式,比如 flannel,cailco 等。
至于我们怎么知道目标 ip (pod 的 ip) 是在哪台主机上,这个就有很多中方式了,比如把每台机器发配 ip 分配不同的网段,甚至于把这些对应关系写到 etcd 中。
VXLAN
上述的 udp 封包方式,是可以满足基本需求但是。cni 创建的 process 进程是一个用户态的进程,每个包要在 node1 上从内核态 copy 到用户态,然后再封包,再 copy 到内核态,再发给 node2,再从内核态 copy 到用户态,再解包,再 copy 到内核态,再发给 pod2。这样的方式效率很低。所以我们使用一种更加高效的方式,就是 vxlan。
VXLAN 是什么?
VXLAN(Virtual Extensible LAN)是一种网络虚拟化技术,用于解决大规模云计算环境中的网络隔离、扩展性和灵活性问题。VXLAN 允许网络工程师在现有的网络架构上创建一个逻辑网络层,这可以使得数据中心的网络设计变得更加灵活和可扩展。
为什么性能会高?
VXLAN 是在内核态实现的,原理和 udp 封包一样,只不过是在内核态实现的,数据包不会在内核态和用户态之间 copy,所以效率会高很多。
ip 路由
就算是 vxlan,也是需要封包和解包的,这样的方式效率还是不够高,所以我们可以使用 ip 路由的方式。
ip 路由故名思意,就是使用路由表来实现 pod 之间的通信。这样的方式效率最高,但是配置比较复杂,需要配置路由表。
而且路由表跳转是二层网络实现的,所以又要要求所有 node 在同一个二层网络中。
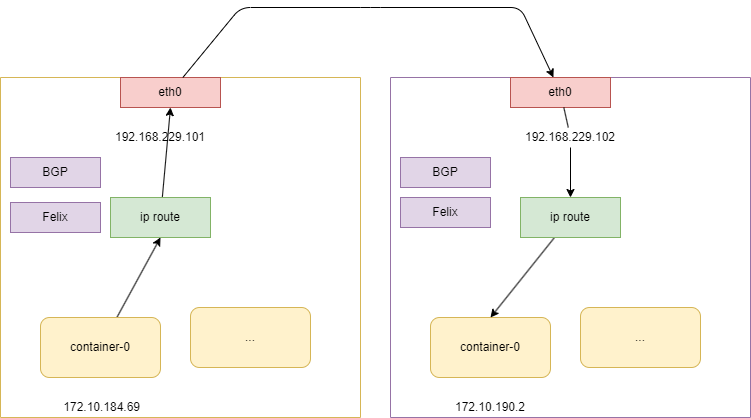
查看 node1 上的 container 的是设备
ip a
2: eth0@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 66:5e:d8:8d:86:ba brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.10.184.69/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::645e:d8ff:fe8d:86ba/64 scope link
valid_lft forever preferred_lft forever
这个和主机上是对应的是一个 veth pair 设备,一个端口挂载在容器的 network namespace 中,一边挂载在主机上。
# 主机
ip a
10: calia78b8700057@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netns cni-0da431c8-dd8b-ca68-55e6-40b04acf78d6
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever
当 pod 中的数据包来到主机 查看 node1 上的路由表 会命中一下这条路由 这条的意思是跳到192.168.229.102节点使用 ens33 设备
ip r
172.10.190.0/26 via 192.168.229.102 dev ens33 proto bird
当 数据包来到 node2 上的时候 我们看下 node2 的路由表
ip r
172.10.190.2 dev calie28ee63d6b0 scope link
ip a
7: calie28ee63d6b0@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netns cni-dd892c92-1826-f648-2b8c-d22618311ca9
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever
这个设备是 veth pair 设备,对应的容器内的
ip a
2: eth0@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether fa:a6:2f:97:58:28 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.10.190.2/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::f8a6:2fff:fe97:5828/64 scope link
valid_lft forever preferred_lft forever
这样node2上的 172.10.190.2 pod 就可以收到数据包了。
路由跳转
路由跳转是怎么实现的?
路由跳转是通过路由表来实现的,它作用在二层上,所以当跳转的时候,直接修改数据包的目标 mac 地址(如果知道的话是使用 ARP 协议获得)。
所以当我们访问百度的时候,获得百度的ip的时候,数据包会经过很多路由器,每个路由器都会修改数据包的目标 mac 地址,这样数据包就可以到达百度的服务器了。
Felix
那么主机上的路由表是怎么来的呢?
这个就是 cni 的实现了,cni 会调用 felix 这个进程,felix 会根据 cni 的配置来配置路由表。
BGP
那么 node1 怎么知道对应的 pod ip 在哪个 node 上呢?
这个就是 BGP 协议了,BGP 是一个路由协议,用来告诉 node1 对应的 pod ip 在哪个 node 上。
这个协议很重,之前都是用到互联网上,比如我们刚才距离的百度的时候,经过那么多路由器,每个路由器怎么知道要跳到哪,他们之间就是通过 BGP 协议来告诉对方自己的路由表,再经过一系列的学习优化。
ip in ip
刚才也说过了,ip 路由是最高效的,是因为它作用在二层网络上,这就需要保证所有的 node 在同一个二层网络上。但是有时候我们的 node 不在同一个二层网络上,这时候我们可以使用 ip in ip。
简单来说就是如果 node 之间在一个二层网络上,那么就直接使用 ip 路由,如果不在,那么就使用 ip in ip,把数据包封装起来,然后再发给对应的 node。
kubernetes CNI(Container Network Inferface)的更多相关文章
- docker的网络-Container network interface(CNI)与Container network model(CNM)
Overview 目前围绕着docker的网络,目前有两种比较主流的声音,docker主导的Container network model(CNM)和社区主导的Container network in ...
- [转帖]Kubernetes CNI网络最强对比:Flannel、Calico、Canal和Weave
Kubernetes CNI网络最强对比:Flannel.Calico.Canal和Weave https://blog.csdn.net/RancherLabs/article/details/88 ...
- 彻底理解kubernetes CNI
kubernetes各版本离线安装包 CNI接口很简单,特别一些新手一定要克服恐惧心里,和我一探究竟,本文结合原理与实践,认真读下来一定会对原理理解非常透彻. 环境介绍 我们安装kubernetes时 ...
- Kubernetes CNI网络插件
CNI 容器网络接口,就是在网络解决方案由网络插件提供,这些插件配置容器网络则通过CNI定义的接口来完成,也就是CNI定义的是容器运行环境与网络插件之间的接口规范.这个接口只关心容器的网络连接,在创建 ...
- Docker container network configuration
http://xmodulo.com/networking-between-docker-containers.html How to set up networking between Docker ...
- Kubernetes init container
目录 简介 配置 init container与应用容器的区别 简介 在很多应用场景中,应用在启动之前都需要进行如下初始化操作: 等待其他关联组件正确运行(例如数据库或某个后台服务) 基于环境变量或配 ...
- 《两地书》--Kubernetes(K8s)基础知识(docker容器技术)
大家都知道历史上有段佳话叫“司马相如和卓文君”.“皑如山上雪,皎若云间月”.卓文君这么美,却也抵不过多情女儿薄情郎. 司马相如因一首<子虚赋>得汉武帝赏识,飞黄腾达之后便要与卓文君“故来相 ...
- Kubernetes(K8s)基础知识(docker容器技术)
今天谈谈K8s基础知识关键词: 一个目标:容器操作:两地三中心:四层服务发现:五种Pod共享资源:六个CNI常用插件:七层负载均衡:八种隔离维度:九个网络模型原则:十类IP地址:百级产品线:千级物理机 ...
- Kubernetes & Docker 容器网络终极之战(十四)
目录 一.单主机 Docker 网络通信 1.1.host 模式 1.2 Bridge 模式 1.3 Container 模式 1.4.None 模式 二.跨主机 Docker 网络通信分类 2.1 ...
- Kubernetes 技能图谱skill-map
# Kubernetes 技能图谱 ## Container basics (容器技术基础)* Kernel* Cgroups* Userspace runtime* Image* Registry ...
随机推荐
- 新增、修改校验逻辑使用-Validation-的group分组校验完成-2022新项目
一.业务场景 一般在项目开发中少不了新增.修改操作,这两个操作中传递的参数中也仅仅只有一个参数是不一致的,新增操作时没有ID, 修改时有ID,其校验逻辑也只有这一个ID校验的差别.最开始自己在写代码时 ...
- PowerShell alias - cmd中设置别名 快捷的执行命令
Step. 1: 发现需求 最近学nest.js发现,都是用命令创建工程文件,然后教程里面都是用的快捷命令 比如 pd = pnpm run dev pb = pnpm run build 但是我这里 ...
- day11-2-内置Tomcat的配置和切换
SpringBoot内置Tomcat的配置和切换 1.基本介绍 SpringBoot支持的webServer:Tomcat,Jetty,Undertow 因为在spring-boot-starter- ...
- PyQt5 Ubuntu 16.04/14.04 环境配置
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文作为本人csdn blog的主站的备份.(Bl ...
- 记录--npm, npx, cnpm, yarn, pnpm梭哈
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 依赖管理解决了在软件开发过程中管理和协调各种依赖项的问题,简化了开发流程,提高了项目的可靠性.可维护性和可重复性.它们帮助开发人员更高效地 ...
- KingabseES 构造常量数据表的方式 union, values, array
背景 通用报表系统中,如果过滤条件是多选数据项,需要动态构造虚拟数据表,这里也会成为查询性能的痛点. 构造方式与执行计划 构造1000行数据的虚拟表. SQL UNION 组合多个查询的结果,需要解析 ...
- AndroidStudio配置 | 菜鸟教程
https://www.runoob.com/android/android-studio-install.html
- 为什么js项目中金额强烈推荐使用分而不是元
相信我们都已经知道在js中浮点数据精度的问题了 看下面的例子 0.1 + 0.2 0.30000000000000004 如何解决呢? 在前后端交互过程中统一使用分为单位进行通讯,在最后的表示层处理为 ...
- C#/.NET/.NET Core优秀项目和框架2024年3月简报
前言 公众号每月定期推广和分享的C#/.NET/.NET Core优秀项目和框架(每周至少会推荐两个优秀的项目和框架当然节假日除外),公众号推文中有项目和框架的介绍.功能特点.使用方式以及部分功能截图 ...
- Vue入门笔记三(Vuex)
<Vue.js项目实战> Vuex 集中式的状态管理 Vuex从Flux(由Facebook开发)的概念中获取得灵感.Flux又一系列指导原则构成,阐明了如何使用集中式store来实现组件 ...