# 再次推荐github 6.7k star开源IM项目OpenIM性能测试及消息可靠性测试报告
本报告主要分为两部分,性能测试和消息可靠性测试。前者主要关注吞吐,延时,同时在线用户等,即通常所说的性能指标。后者主要模拟真实环境(比如离线,在线,弱网)消息通道的可靠性。
先说结论,对于容量和性能:
性能及容量总结
服务器资源: 8核16G内存, 6个机械磁盘,每个磁盘100G, 用于mongo分片,10MB带宽。
容量:用户容量10万以上,消息条数10亿条。
性能评估:同时在线用户10万,每秒钟发送消息900条,消息延时1秒(从发送者发出消息到接收到消息)
可靠性总结
启动sdk,模拟50个用户在线、离线情况,消息可靠性100%。
发送10万消息,有3条失败,其他消息都能被对方精确收到,并成功落地本地db。对于失败的3条消息,接收方确实没有收到,系统消息是一致的。
项目介绍
OpenIM是由前微信技术专家打造的开源的即时通讯组件。Open-IM包括IM服务端和客户端SDK,是一套整体的解决方案,代码开源,一切可控,
github地址:https://github.com/OpenIMSDK/Open-IM-Server
开发者中心: https://doc.rentsoft.cn/#/

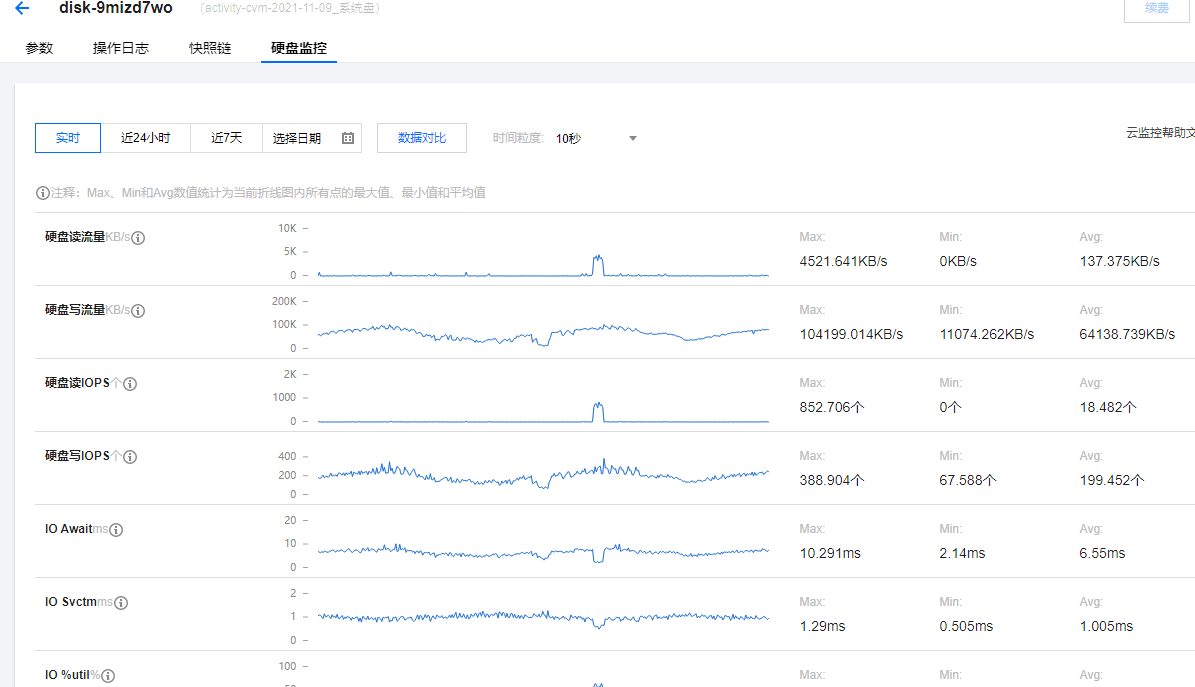
在单机的情况下,模拟线上用户发消息流程,在线用户量和消息量达到一定量级后,系统CPU、内存、磁盘占用、以及消息时延情况。以确定用户群体达到一定量级后,对服务器资源的预先评估。本次测试并不极限测试,一是因为生产环境本来都会有用户量和消息量的限制,二是因为OpenIM的消息模型,消息发送首先都会通过websocket入库kafka,理论上发送消息的写入性能是两者的组合,而消息发送的真正瓶颈实际在mongodb的随机读写。
测试过程
服务器资源: 腾讯云主机(香港)1台:linux Ubuntu 18.04.4系统,4核8G内存,单块机械硬盘。5Mb带宽。
测试条件:去掉消息入库mysql(因mysql仅用于管理后台,不影响线上用户服务)。日志级别调整为4或更低。kafka设置2个分区,msg_transfer 2个。
测试流程:1个客户端(成都,window pc,4核16G内存)启动1万个协程,模拟用户与服务器建立websocket长连接,间隔时间为随机50-100秒之间。两个客户端共模拟2万用户同时在线,发送消息,观察消息流转各个模块的处理能力,共计2500万条消息,观察系统内存、磁盘资源使用情况。
测试结论和分析
| 关注指标 | 测试结果 |
| ---------------- | ------------------------------------------------------------ |
| 同时在线人数 | 20000个 |
| 网关接收消息速度 | 150条/s(因为瓶颈不在此,故意控制发送速度,以确保kafka能被快速消费入mongodb) |
| mongodb处理写入 | 300条/s (收件箱模型,导致消息一拆为二) |
| CPU使用率 | 约50% |
| 内存使用率 | 约4G(mongo内存限制2G,由于每个文档存储5k条消息,实际实际索引量很小。 redis只存了用户seq映射关系,基本不占内存) |
| 发送消息响应时长 | 平均70毫秒 |
| 发送过程时延 | 平约1秒 |
| 磁盘空间 | mongo中5000万条消息占用10G磁盘,由于一拆为二的缘故,mongo的50000万条消息,实际为2500万条消息。
|
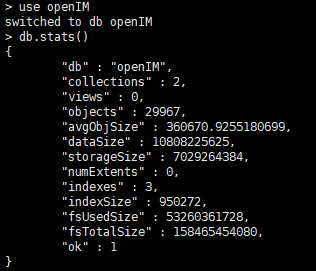
mongodb数据情况
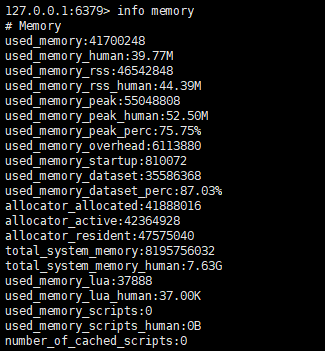
redis数据情况
磁盘状态
资源占用分析
(1)redis内存消耗极小,一个用户一条数据(包括token和seq),和用户量成正比,3万用户占用几十M内存。
(2)mongodb如果去掉cache,内存消耗极小,每个document存放5000条消息,与用户量和消息量成正比,3万用户,2500万消息,索引才950K(更好的方式查看mongo消耗cache之外的内存)
(3)2500万消息,磁盘空间占用10G。
(4)每秒钟150条消息,cpu整体占用50%,即2核。
性能分析
(1)性能瓶颈在mongodb写入操作,1条消息,需要按照发送者和接收者拆分2次,mongodb写入2次,未来可以针对mongodb读写进一步优化。
(2)对于cpu消耗较大的模块,未来做一次整体优化。
(3)性能很平稳,不会随着数据量增加而降低。机械磁盘iops 达到200基本达到了设备的极限
单机性能预估
服务器资源: 8核16G内存, 6个磁盘,每个磁盘100G, 用于mongo分片,10MB带宽。
性能评估:同时在线用户10万,每秒钟发送消息900条,消息延时1秒(从发送者发出消息到接收到消息)
| 模块 | 性能情况 | 说明 |
| -------------------- | ---------------------------------------- | -------------------------------------------------------- |
| msg_gateway | 部署多个 | ,同时在线5万*2=10万 |
| mongodb | 6分片,每个磁盘对应一个分片 | 1800条/每秒消息入库 |
| CPU使用率 | 约100% | 需要优化模块 减少cpu消耗 |
| 内存使用率 | 小于8G(mongo内存限制2G) | 如果内存富余可以增加mongodb的cache大小 |
| 发送消息响应时长 | 平均70ms | |
| 发送过程时延 | 平约1s | 从发送者到接收者 |
| 10亿条消息,磁盘空间 | 占用40*100G磁盘,每个磁盘大概占用70G空间 | 对于群聊属于扩散写,磁盘消耗较大。整体要考虑磁盘空间富余 |
未来工作优化
(1)mongo集群部署,支持上亿用户同时在线,千亿级消息;
(2)简化集群部署;
(3)数据备份、恢复工具;
以上主要对服务端性能做了一个大致测试,但一套完整的IM解决方案,不仅仅是服务端的工作。实际上,客户端重要性毋庸置疑,具体包括如何利用seq和服务端同步消息,如果保证消息收发的时序,如何回调客户端(会话改变、新增,新消息),消息落地本地db,seq同步,消息推拉如何结合以确保消息收发可靠性。
消息可达率(可靠性)测试
相比于性能测试,实际上,消息的可达性(可靠性)更为重要。所以,我们在做性能测试的同时,也要对消息的可达性(可靠性)进行测试,如果不能保证消息收发的正确性,再高的性能也是徒劳。本文重点总结关于OpenIM对于消息可达性测试的方案、过程以及结果。先说结论,OpenIM消息可达率100%,大家可以放心使用在生产环境中。seq对齐和同步机制,保证了OpenIM的消息可达性是业界领先的。
消息可达性(可靠性)的定义
IM消息系统的可靠性,通常就是指消息投递的可靠性,即我们经常听到的“消息必达”,通常用消息的不丢失和不重复两个技术指标来表示。确保消息被发送后,能被接收者收到。由于网络环境的复杂性,以及用户在线的不确定性,消息的可靠性(不丢失、不重复)无疑是IM系统的核心指标,也是IM系统实现中的难点之一。总体来说,IM系统的消息“可靠性”,通常就是指聊天消息投递的可靠性(准确的说,这个“消息”是广义的,因为还存用户看不见的各种指令和通知,包括但不限于进群退群通知、好友添加通知等,为了方便描述,统称“消息”)。
从消息发送者和接收者用户行为来讲,消息“可靠性”应该分为以下几种情况:
(1)发送失败,对于这种情况IM系统必须要感知到,明确反馈发送方。如果此消息没有发送成功,发送方可以选择重试或者稍后再试。
(2)发送成功,如果接收方处在“在线”状态,应该立即收到此消息。如果接收方处在“离线”状态不能收到消息,一旦上线则立刻收到消息。
(3)消息不能重复,用数学术语表示:“有且仅有这条消息”,如果重复了,可能表达的意思就变了。 总之,一个商用 IM系统,必须包含消息“可靠性”逻辑,才能谈基本可用,这是IM系统最基本也是最核心的逻辑。
模拟场景&测试方案
互联网真实场景复杂,但客户端大体可以分为两种情况:(1)发送消息时,接收方在线,能收到消息;(2)发送消息时接收方不在线,登录后能收到离线消息。我们用测试程序模拟互联网客户端各种场景,按照登录、发送消息、接收消息的情况,把测试客户端分为以下2种类型:
(1)启动测试时离线,随机sleep 0-60 秒后登录,发送消息,且接收消息
(2)启动测试时离线,随机sleep 0-60 秒后登录,不发送消息,只接收消息
test.ReliabilityTest(oneClientSendMsgNum, intervalSleepMs, imIP, randSleepMaxSecond, testClientNum)
在实际测试中共计50个客户端,约25个(50%概率)客户端不发送只接收消息,约25个(50%概率)客户端发送且接收消息 。
发送模式:每个客户端随机选择其他客户端作为消息接收者;
测试预期: 每一条发送成功的MsgID,都能在接收的消息列表中找到,同样,每一条接收到的MsgID,都能在发送成功的消息列表中找到。
具体做法:(1)消息发送成功后,通过OnSuccess回调,记录MsgID; 收到新消息后回调OnRecvNewMessage,记录MsgID;(2)周期性对比两个消息列表,确认是否完全一致;
测试结果
| 发送消息客户端 | 接收消息客户端 | 预设发送消息总量 | 发送成功条数 | 发送失败条数 | 接收消息条数 | |
| -------------- | -------------- | ---------------- | ------------ | ------------ | ------------ | ---- |
| 25个 | 50个 | 100000条 | 99997 | 3 | 99997 | |
发送数据100000条,其中失败3条,9999997条成功,接收方成功接收9999997条消息(接收方成功接收到消息,写入本地db,并能触发消息回调)
每一条发送成功的消息,对方都能准确接收到,无论接收方在消息发送时的登录状态是在线还是离线。
每一条发送失败的消息,对方都不会收到。
测试程序
main/main.go
intervalSleepMs := 1
randSleepMaxSecond := 30
imIP := "127.0.0.1" //OpenIM ip
oneClientSendMsgNum := 4000 //每个客户端发送的消息条数
testClientNum := 50 //同时启动压测客户端数量
func main() {
reliabilityTest()
}
注意事项:
(1)控制压力,因为sdk需要写本地db,客户端会成为压力瓶颈。
(2)压测客户端日志会影响测试性能。
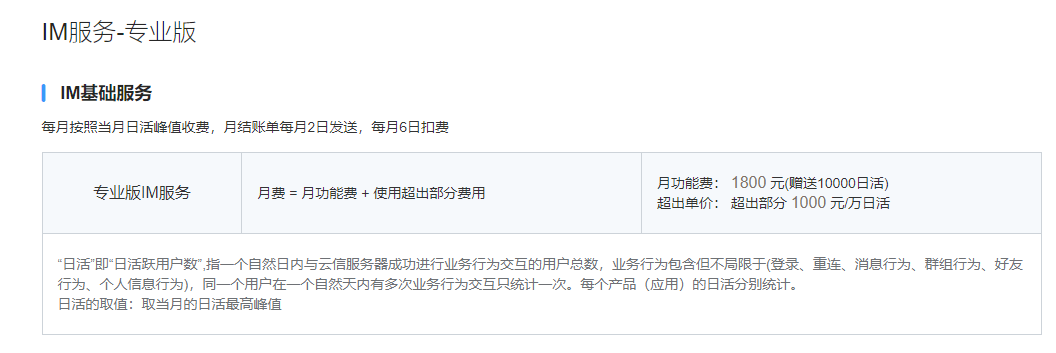
成本对比
此表格是某IM云平台的价格,如果按照10万月活,存储三年消息来算,大概每年需要支付15万。而采用OpenIM只需要采购云主机,每年成本约0.8万。

# 再次推荐github 6.7k star开源IM项目OpenIM性能测试及消息可靠性测试报告的更多相关文章
- 推荐GitHub上10 个开源深度学习框架
推荐GitHub上10 个开源深度学习框架 日前,Google 开源了 TensorFlow(GitHub),此举在深度学习领域影响巨大,因为 Google 在人工智能领域的研发成绩斐然,有着雄厚 ...
- 28款GitHub最流行的开源机器学习项目,推荐GitHub上10 个开源深度学习框架
20 个顶尖的 Python 机器学习开源项目 机器学习 2015-06-08 22:44:30 发布 您的评价: 0.0 收藏 1收藏 我们在Github上的贡献者和提交者之中检查了用Python语 ...
- 在github上查找star最多的项目
如何在github上查找star最多的项目 在search中输入stars:>1 就可以查找所有有star的项目,然后右上角根据自己的需要筛选 当我输入stars:>10000的时候,就会 ...
- 我的开源之路:耗时 6 个月发布线程池框架,GitHub 1.7k Star!
文章首发在公众号(龙台的技术笔记),之后同步到掘金和个人网站:xiaomage.info Hippo4J 线程池框架经过 6 个多月的版本迭代,2022 年春节当天成功发行了 1.0.0 RELEAS ...
- 28款GitHub最流行的开源机器学习项目
现在机器学习逐渐成为行业热门,经过二十几年的发展,机器学习目前也有了十分广泛的应用,如:数据挖掘.计算机视觉.自然语言处理.生物特征识别.搜索引擎.医学诊断.DNA序列测序.语音和手写识别.战略游戏和 ...
- 第一次玩github,第一个开源小项目——xxoo
引言 由于最近的工作写代码比较少,这让LZ产生了一丝危机感.于是便想找一个办法可以没事自己写写代码,自然而然就想到了github.接下来便是一阵捣鼓的过程,其实整个过程很快,主要过程就是注册一个账号, ...
- 强烈推荐 GitHub 上值得前端学习的开源实战项目
强烈推荐 GitHub 上值得前端学习的开源实战项目. Vue.js vue-element-admin 是一个后台前端解决方案,它基于和 element-ui 实现 基于 iView 的 Vue 2 ...
- 袋鼠云研发手记 | 数栈·开源:Github上400+Star的硬核分布式同步工具FlinkX
作为一家创新驱动的科技公司,袋鼠云每年研发投入达数千万,公司80%员工都是技术人员,袋鼠云产品家族包括企业级一站式数据中台PaaS数栈.交互式数据可视化大屏开发平台Easy[V]等产品也在迅速迭代.在 ...
- 一大波开发者福利来了,一份微软官方Github上发布的开源项目清单等你签收
目录 微软Github开源项目入口 微软开源项目受欢迎程度排名 Visual Studio Code TypeScript RxJS .NET Core 基础类库 CNTK Microsoft cal ...
- 推荐4个Flutter重磅开源项目
早上好,骚年,我是小 G,我的公众号「菜鸟翻身」会推荐 GitHub 上有用的项目,一分钟 get 一个优秀的开源项目,挖掘开源的价值,欢迎关注我. 近年来,随着移动智能设备的快速普及,移动多端统一开 ...
随机推荐
- PPT 客户提案PPT应该怎么样改
PPT 客户提案PPT应该怎么样改
- kubeadm init port is in use
前一次 init 时,master ip 写错了,导致init 失败,修改IP后再次执行时,报 kubeadm init 失败,port is in use Last login: Thu Oct 1 ...
- Intellij IDEA 关闭阿里编码规约“请不要使用行尾注释”提醒
Settings -> Inspections -> 注释 取消 "方法内部单行注释 xxxx " 里面的勾,[设完后重启]如下图
- 收到一封CTO来信,邀约面试机器学习工程师
大家好,我是北海 很少登陆 Gmail,前天收验证码登了一下,发现居然收到一封某初创公司CTO的来信. 我在Github上看到了您的资料觉得很有意思,请问您是否考虑我们公司的全职工作机会呢?可供考虑的 ...
- Leaflet 使用图片作为地图
Leaflet 使用图片作为地图 关键代码: L.CRS.Simple.transformation = new L.Transformation(1, 0, 1, 0); // 坐标原点切换为左上角 ...
- 3D编程模式:开篇
大家好~现在开始新的系列文章:3D编程模式系列 本系列会介绍从我的实际开发经验中抽象提炼出来的编程模式,大家可直接应用它们到3D引擎开发.编辑器开发等领域中 相关资料: 课程录像回放 代码和课程ppt ...
- svg组件封装
svg图标优点 文件体积小,能够被大量的压缩 图片可无限放大而不失真(矢量图的基本特征) 在视网膜显示屏上效果极佳 能够实现互动和滤镜效果 svg图标使用 1.安装相应的npm包: yarn add ...
- 30 秒使用 Sealos 搭建个人密码管理器 Vaultwarden
我与 LastPass 的曲折恋情 超过 8 年网龄的我,注册过很多网站帐号,每个网站的密码我都用不同的复杂密码.一开始我全靠脑力记忆这些密码,后来渐渐觉得记起来很困难,就记录在笔记本上.但是随着时间 ...
- php开发之文件下载的实现
前言 php是网络安全学习里必不可少的一环,简单理解php的开发环节能更好的帮助我们去学习php以及其他语言的web漏洞原理 正文 在正常的开发中,文件下载的功能是必不可少,比如我们在论坛看到好看图片 ...
- shell脚本(4)-格式化输入
一.read命令 1.概念: 默认接受键盘的输入,回车符代表输入结束 2.read命令选项 -p:打印信息 -t:限定时间 -s:不回显 -n:输入字符个数 3.举例说明 (1)模拟登录 [root@ ...