快递单信息抽取【二】基于ERNIE1.0至ErnieGram + CRF预训练模型
相关文章:
1.快递单中抽取关键信息【一】----基于BiGRU+CR+预训练的词向量优化
2.快递单信息抽取【二】基于ERNIE1.0至ErnieGram + CRF预训练模型
3.快递单信息抽取【三】–五条标注数据提高准确率,仅需五条标注样本,快速完成快递单信息任务
1)PaddleNLP通用信息抽取技术UIE【一】产业应用实例:信息抽取{实体关系抽取、中文分词、精准实体标。情感分析等}、文本纠错、问答系统、闲聊机器人、定制训练
2)PaddleNLP–UIE(二)–小样本快速提升性能(含doccona标注)
!强烈推荐:数据标注平台doccano----简介、安装、使用、踩坑记录
本项目链接:
https://aistudio.baidu.com/aistudio/projectdetail/4157455?contributionType=1
1.ERNIE 1.0 完成快递单信息抽取
命名实体识别是NLP中一项非常基础的任务,是信息提取、问答系统、句法分析、机器翻译等众多NLP任务的重要基础工具。命名实体识别的准确度,决定了下游任务的效果,是NLP中的一个基础问题。在NER任务提供了两种解决方案,一类LSTM/GRU + CRF,通过RNN类的模型来抽取底层文本的信息,而CRF(条件随机场)模型来学习底层Token之间的联系;另外一类是通过预训练模型,例如ERNIE,BERT模型,直接来预测Token的标签信息。
本项目将演示如何使用PaddleNLP语义预训练模型ERNIE完成从快递单中抽取姓名、电话、省、市、区、详细地址等内容,形成结构化信息。辅助物流行业从业者进行有效信息的提取,从而降低客户填单的成本。
在2017年之前,工业界和学术界对文本处理依赖于序列模型Recurrent Neural Network (RNN).
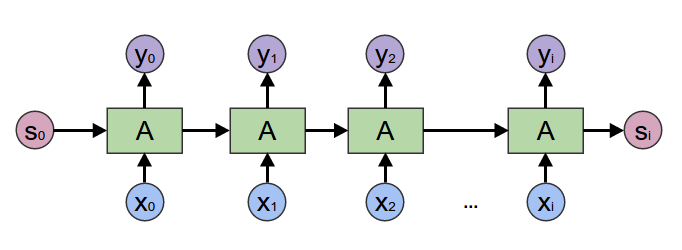
图1:RNN示意图
基于BiGRU+CRF的快递单信息抽取项目介绍了如何使用序列模型完成快递单信息抽取任务。
近年来随着深度学习的发展,模型参数的数量飞速增长。为了训练这些参数,需要更大的数据集来避免过拟合。然而,对于大部分NLP任务来说,构建大规模的标注数据集非常困难(成本过高),特别是对于句法和语义相关的任务。相比之下,大规模的未标注语料库的构建则相对容易。为了利用这些数据,我们可以先从其中学习到一个好的表示,再将这些表示应用到其他任务中。最近的研究表明,基于大规模未标注语料库的预训练模型(Pretrained Models, PTM) 在NLP任务上取得了很好的表现。
近年来,大量的研究表明基于大型语料库的预训练模型(Pretrained Models, PTM)可以学习通用的语言表示,有利于下游NLP任务,同时能够避免从零开始训练模型。随着计算能力的不断提高,深度模型的出现(即 Transformer)和训练技巧的增强使得 PTM 不断发展,由浅变深。
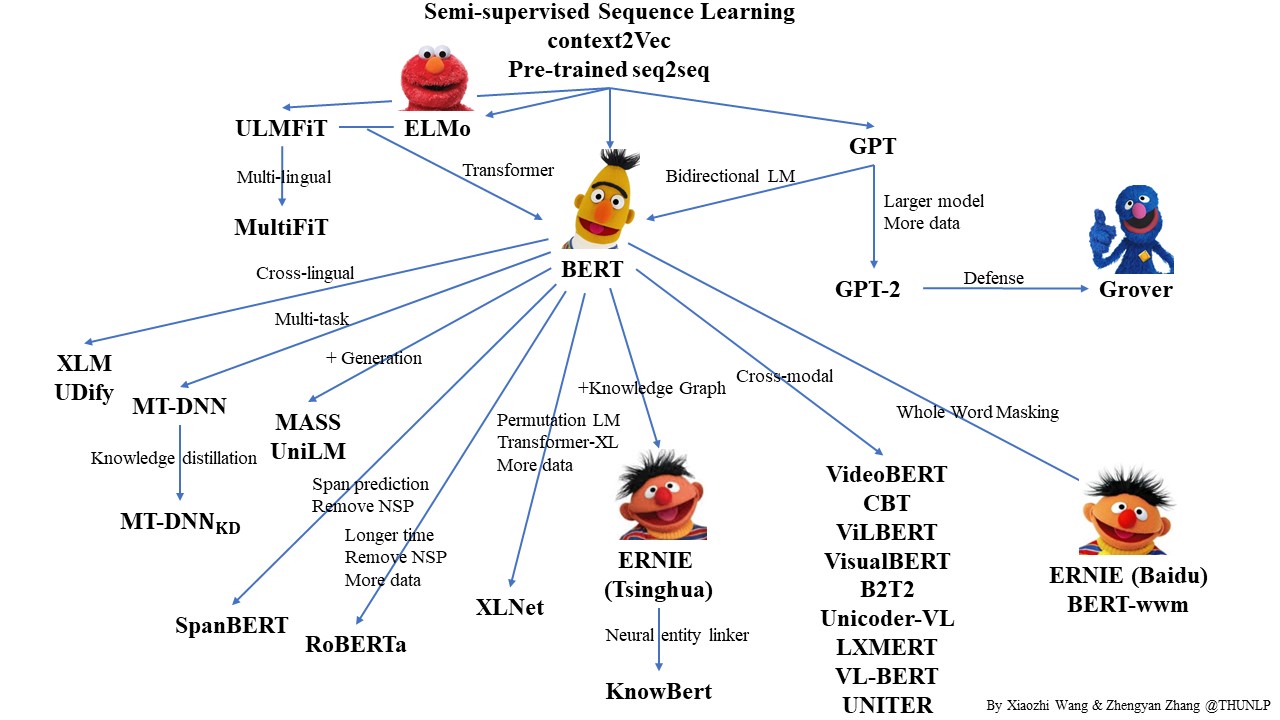
图2:预训练模型一览,图片来源于:https://github.com/thunlp/PLMpapers
本示例展示了以ERNIE(Enhanced Representation through Knowledge Integration)为代表的预训练模型如何Finetune完成序列标注任务。
!pip install --upgrade paddlenlp
# 下载并解压数据集
from paddle.utils.download import get_path_from_url
URL = "https://paddlenlp.bj.bcebos.com/paddlenlp/datasets/waybill.tar.gz"
get_path_from_url(URL, "./")
# 查看预测的数据
!head -n 5 data/test.txt
from functools import partial
import paddle
from paddlenlp.datasets import MapDataset
from paddlenlp.data import Stack, Tuple, Pad
from paddlenlp.transformers import ErnieTokenizer, ErnieForTokenClassification
from paddlenlp.metrics import ChunkEvaluator
from utils import convert_example, evaluate, predict, load_dict
1.1加载自定义数据集
推荐使用MapDataset()自定义数据集。
def load_dataset(datafiles):
def read(data_path):
with open(data_path, 'r', encoding='utf-8') as fp:
next(fp) # Skip header
for line in fp.readlines():
words, labels = line.strip('\n').split('\t')
words = words.split('\002')
labels = labels.split('\002')
yield words, labels
if isinstance(datafiles, str):
return MapDataset(list(read(datafiles)))
elif isinstance(datafiles, list) or isinstance(datafiles, tuple):
return [MapDataset(list(read(datafile))) for datafile in datafiles]
# Create dataset, tokenizer and dataloader.
train_ds, dev_ds, test_ds = load_dataset(datafiles=(
'./data/train.txt', './data/dev.txt', './data/test.txt'))
for i in range(5):
print(train_ds[i])
(['1', '6', '6', '2', '0', '2', '0', '0', '0', '7', '7', '宣', '荣', '嗣', '甘', '肃', '省', '白', '银', '市', '会', '宁', '县', '河', '畔', '镇', '十', '字', '街', '金', '海', '超', '市', '西', '行', '5', '0', '米'], ['T-B', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'P-B', 'P-I', 'P-I', 'A1-B', 'A1-I', 'A1-I', 'A2-B', 'A2-I', 'A2-I', 'A3-B', 'A3-I', 'A3-I', 'A4-B', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I'])
(['1', '3', '5', '5', '2', '6', '6', '4', '3', '0', '7', '姜', '骏', '炜', '云', '南', '省', '德', '宏', '傣', '族', '景', '颇', '族', '自', '治', '州', '盈', '江', '县', '平', '原', '镇', '蜜', '回', '路', '下', '段'], ['T-B', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'P-B', 'P-I', 'P-I', 'A1-B', 'A1-I', 'A1-I', 'A2-B', 'A2-I', 'A2-I', 'A2-I', 'A2-I', 'A2-I', 'A2-I', 'A2-I', 'A2-I', 'A2-I', 'A3-B', 'A3-I', 'A3-I', 'A4-B', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I'])
(['内', '蒙', '古', '自', '治', '区', '赤', '峰', '市', '阿', '鲁', '科', '尔', '沁', '旗', '汉', '林', '西', '街', '路', '南', '1', '3', '7', '0', '1', '0', '8', '5', '3', '9', '0', '那', '峥'], ['A1-B', 'A1-I', 'A1-I', 'A1-I', 'A1-I', 'A1-I', 'A2-B', 'A2-I', 'A2-I', 'A3-B', 'A3-I', 'A3-I', 'A3-I', 'A3-I', 'A3-I', 'A4-B', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'T-B', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'P-B', 'P-I'])
(['广', '东', '省', '梅', '州', '市', '大', '埔', '县', '茶', '阳', '镇', '胜', '利', '路', '1', '3', '6', '0', '1', '3', '2', '8', '1', '7', '3', '张', '铱'], ['A1-B', 'A1-I', 'A1-I', 'A2-B', 'A2-I', 'A2-I', 'A3-B', 'A3-I', 'A3-I', 'A4-B', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'T-B', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'P-B', 'P-I'])
(['新', '疆', '维', '吾', '尔', '自', '治', '区', '阿', '克', '苏', '地', '区', '阿', '克', '苏', '市', '步', '行', '街', '1', '0', '号', '1', '5', '8', '1', '0', '7', '8', '9', '3', '7', '8', '慕', '东', '霖'], ['A1-B', 'A1-I', 'A1-I', 'A1-I', 'A1-I', 'A1-I', 'A1-I', 'A1-I', 'A2-B', 'A2-I', 'A2-I', 'A2-I', 'A2-I', 'A3-B', 'A3-I', 'A3-I', 'A3-I', 'A4-B', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'T-B', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'P-B', 'P-I', 'P-I'])
每条数据包含一句文本和这个文本中每个汉字以及数字对应的label标签。
之后,还需要对输入句子进行数据处理,如切词,映射词表id等。
1.2数据处理
预训练模型ERNIE对中文数据的处理是以字为单位。PaddleNLP对于各种预训练模型已经内置了相应的tokenizer。指定想要使用的模型名字即可加载对应的tokenizer。
tokenizer作用为将原始输入文本转化成模型model可以接受的输入数据形式。
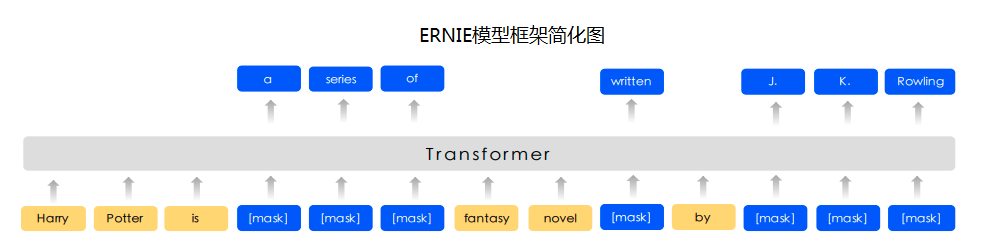
图3:ERNIE模型示意图
label_vocab = load_dict('./data/tag.dic')
tokenizer = ErnieTokenizer.from_pretrained('ernie-1.0')
trans_func = partial(convert_example, tokenizer=tokenizer, label_vocab=label_vocab)
train_ds.map(trans_func)
dev_ds.map(trans_func)
test_ds.map(trans_func)
print (train_ds[0])
([1, 208, 515, 515, 249, 540, 249, 540, 540, 540, 589, 589, 803, 838, 2914, 1222, 1734, 244, 368, 797, 99, 32, 863, 308, 457, 2778, 484, 167, 436, 930, 192, 233, 634, 99, 213, 40, 317, 540, 256, 2], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 40, [12, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 0, 1, 1, 4, 5, 5, 6, 7, 7, 8, 9, 9, 10, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 12])
1.3数据读入
使用paddle.io.DataLoader接口多线程异步加载数据。
ignore_label = -1
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids
Stack(), # seq_len
Pad(axis=0, pad_val=ignore_label) # labels
): fn(samples)
train_loader = paddle.io.DataLoader(
dataset=train_ds,
batch_size=36,
return_list=True,
collate_fn=batchify_fn)
dev_loader = paddle.io.DataLoader(
dataset=dev_ds,
batch_size=36,
return_list=True,
collate_fn=batchify_fn)
test_loader = paddle.io.DataLoader(
dataset=test_ds,
batch_size=36,
return_list=True,
collate_fn=batchify_fn)
1.4PaddleNLP一键加载预训练模型
快递单信息抽取本质是一个序列标注任务,PaddleNLP对于各种预训练模型已经内置了对于下游任务文本分类Fine-tune网络。以下教程以ERNIE为预训练模型完成序列标注任务。
paddlenlp.transformers.ErnieForTokenClassification()一行代码即可加载预训练模型ERNIE用于序列标注任务的fine-tune网络。其在ERNIE模型后拼接上一个全连接网络进行分类。
paddlenlp.transformers.ErnieForTokenClassification.from_pretrained()方法只需指定想要使用的模型名称和文本分类的类别数即可完成定义模型网络。
# Define the model netword and its loss
model = ErnieForTokenClassification.from_pretrained("ernie-1.0", num_classes=len(label_vocab))
PaddleNLP不仅支持ERNIE预训练模型,还支持BERT、RoBERTa、Electra等预训练模型。
下表汇总了目前PaddleNLP支持的各类预训练模型。您可以使用PaddleNLP提供的模型,完成文本分类、序列标注、问答等任务。同时我们提供了众多预训练模型的参数权重供用户使用,其中包含了二十多种中文语言模型的预训练权重。中文的预训练模型有bert-base-chinese, bert-wwm-chinese, bert-wwm-ext-chinese, ernie-1.0, ernie-tiny, gpt2-base-cn, roberta-wwm-ext, roberta-wwm-ext-large, rbt3, rbtl3, chinese-electra-base, chinese-electra-small, chinese-xlnet-base, chinese-xlnet-mid, chinese-xlnet-large, unified_transformer-12L-cn, unified_transformer-12L-cn-luge等。
更多预训练模型参考:PaddleNLP Transformer API。
更多预训练模型fine-tune下游任务使用方法,请参考:examples。
1.5设置Fine-Tune优化策略,模型配置
适用于ERNIE/BERT这类Transformer模型的迁移优化学习率策略为warmup的动态学习率。
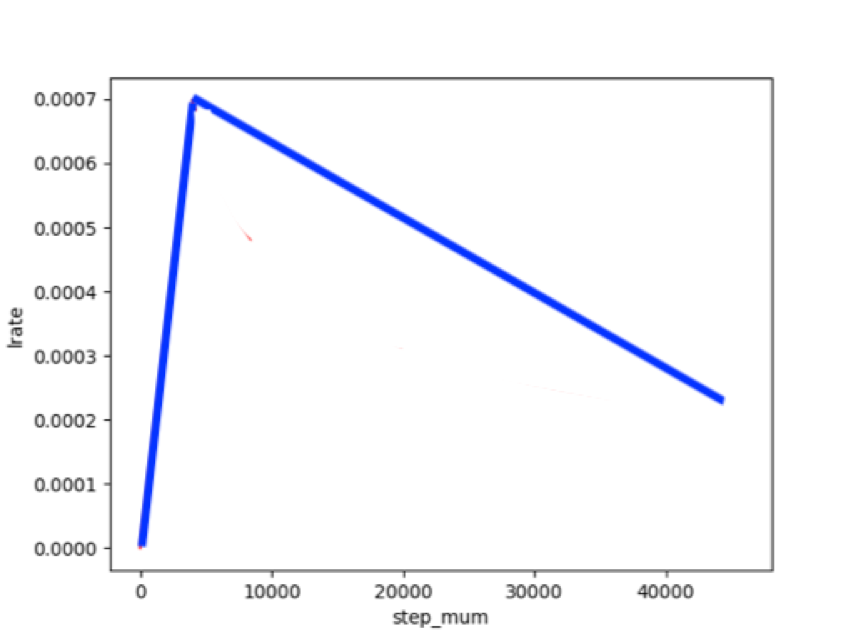
图4:动态学习率示意图
metric = ChunkEvaluator(label_list=label_vocab.keys(), suffix=True)
loss_fn = paddle.nn.loss.CrossEntropyLoss(ignore_index=ignore_label)
optimizer = paddle.optimizer.AdamW(learning_rate=2e-5, parameters=model.parameters())
1.6模型训练与评估
模型训练的过程通常有以下步骤:
- 从dataloader中取出一个batch data
- 将batch data喂给model,做前向计算
- 将前向计算结果传给损失函数,计算loss。将前向计算结果传给评价方法,计算评价指标。
- loss反向回传,更新梯度。重复以上步骤。
每训练一个epoch时,程序将会评估一次,评估当前模型训练的效果。
step = 0
for epoch in range(10):
for idx, (input_ids, token_type_ids, length, labels) in enumerate(train_loader):
logits = model(input_ids, token_type_ids)
loss = paddle.mean(loss_fn(logits, labels))
loss.backward()
optimizer.step()
optimizer.clear_grad()
step += 1
print("epoch:%d - step:%d - loss: %f" % (epoch, step, loss))
evaluate(model, metric, dev_loader)
paddle.save(model.state_dict(),
'./ernie_result/model_%d.pdparams' % step)
# model.save_pretrained('./checkpoint')
# tokenizer.save_pretrained('./checkpoint')
结果:
epoch:9 - step:435 - loss: 0.001102
epoch:9 - step:436 - loss: 0.001224
epoch:9 - step:437 - loss: 0.002693
epoch:9 - step:438 - loss: 0.022898
epoch:9 - step:439 - loss: 0.001355
epoch:9 - step:440 - loss: 0.001069
epoch:9 - step:441 - loss: 0.001204
epoch:9 - step:442 - loss: 0.001223
epoch:9 - step:443 - loss: 0.007524
epoch:9 - step:444 - loss: 0.001363
epoch:9 - step:445 - loss: 0.004732
epoch:9 - step:446 - loss: 0.001559
epoch:9 - step:447 - loss: 0.002389
epoch:9 - step:448 - loss: 0.002210
epoch:9 - step:449 - loss: 0.005183
epoch:9 - step:450 - loss: 0.001259
eval precision: 0.994958 - recall: 0.995795 - f1: 0.995376
1.7模型预测
训练保存好的模型,即可用于预测。如以下示例代码自定义预测数据,调用predict()函数即可一键预测。
preds = predict(model, test_loader, test_ds, label_vocab)
file_path = "ernie_results.txt"
with open(file_path, "w", encoding="utf8") as fout:
fout.write("\n".join(preds))
# Print some examples
print(
"The results have been saved in the file: %s, some examples are shown below: "
% file_path)
print("\n".join(preds[:10]))
The results have been saved in the file: ernie_results.txt, some examples are shown below:
('黑龙江省', 'A1')('双鸭山市', 'A2')('尖山区', 'A3')('八马路与东平行路交叉口北40米', 'A4')('韦业涛', 'P')('18600009172', 'T')
('广西壮族自治区', 'A1')('桂林市', 'A2')('雁山区', 'A3')('雁山镇西龙村老年活动中心', 'A4')('17610348888', 'T')('羊卓卫', 'P')
('15652864561', 'T')('河南省', 'A1')('开封市', 'A2')('顺河回族区', 'A3')('顺河区公园路32号', 'A4')('赵本山', 'P')
('河北省', 'A1')('唐山市', 'A2')('玉田县', 'A3')('无终大街159号', 'A4')('18614253058', 'T')('尚汉生', 'P')
('台湾', 'A1')('台中市', 'A2')('北区', 'A3')('北区锦新街18号', 'A4')('18511226708', 'T')('蓟丽', 'P')
('廖梓琪', 'P')('18514743222', 'T')('湖北省', 'A1')('宜昌市', 'A2')('长阳土家族自治县', 'A3')('贺家坪镇贺家坪村一组临河1号', 'A4')
('江苏省', 'A1')('南通市', 'A2')('海门市', 'A3')('孝威村孝威路88号', 'A4')('18611840623', 'T')('计星仪', 'P')
('17601674746', 'T')('赵春丽', 'P')('内蒙古自治区', 'A1')('乌兰察布市', 'A2')('凉城县', 'A3')('新建街', 'A4')
('云南省', 'A1')('临沧市', 'A2')('耿马傣族佤族自治县', 'A3')('鑫源路法院对面', 'A4')('许贞爱', 'P')('18510566685', 'T')
('四川省', 'A1')('成都市', 'A2')('双流区', 'A3')('东升镇北仓路196号', 'A4')('耿丕岭', 'P')('18513466161', 'T')
2.0 快递单信息抽取[三]:Ernie 1.0至ErnieGram + CRF改进算法
代码和链接以及项目都在下面链接,fork一下可以直接跑:
项目连接:Ernie 1.0至ErnieGram + CRF改进算法

GRU + CRF
Eval begin...
step 1/6 - loss: 0.0000e+00 - precision: 0.9896 - recall: 0.9948 - f1: 0.9922 - 121ms/step
step 2/6 - loss: 0.0000e+00 - precision: 0.9896 - recall: 0.9948 - f1: 0.9922 - 125ms/step
step 3/6 - loss: 20.9767 - precision: 0.9861 - recall: 0.9895 - f1: 0.9878 - 123ms/step
step 4/6 - loss: 0.0000e+00 - precision: 0.9805 - recall: 0.9869 - f1: 0.9837 - 123ms/step
step 5/6 - loss: 0.0000e+00 - precision: 0.9782 - recall: 0.9843 - f1: 0.9812 - 122ms/step
step 6/6 - loss: 0.0000e+00 - precision: 0.9740 - recall: 0.9791 - f1: 0.9765 - 123ms/step
Eval samples: 192
Ernie
'''
epoch:8 - step:72 - loss: 0.038532
eval precision: 0.974124 - recall: 0.981497 - f1: 0.977796
epoch:9 - step:73 - loss: 0.031000
epoch:9 - step:74 - loss: 0.033214
epoch:9 - step:75 - loss: 0.034606
epoch:9 - step:76 - loss: 0.038763
epoch:9 - step:77 - loss: 0.033273
epoch:9 - step:78 - loss: 0.031058
epoch:9 - step:79 - loss: 0.028151
epoch:9 - step:80 - loss: 0.030707
eval precision: 0.976608 - recall: 0.983179 - f1: 0.979883
ErnieGram
'''
epoch:8 - step:72 - loss: 0.030066
eval precision: 0.990764 - recall: 0.992431 - f1: 0.991597
epoch:9 - step:73 - loss: 0.023607
epoch:9 - step:74 - loss: 0.023326
epoch:9 - step:75 - loss: 0.022730
epoch:9 - step:76 - loss: 0.033801
epoch:9 - step:77 - loss: 0.026398
epoch:9 - step:78 - loss: 0.026028
epoch:9 - step:79 - loss: 0.021799
epoch:9 - step:80 - loss: 0.025259
eval precision: 0.990764 - recall: 0.992431 - f1: 0.991597
ERNIE + CRF
'''
[EVAL] Precision: 0.975793 - Recall: 0.983179 - F1: 0.979472
[TRAIN] Epoch:9 - Step:73 - Loss: 0.111980
[TRAIN] Epoch:9 - Step:74 - Loss: 0.152896
[TRAIN] Epoch:9 - Step:75 - Loss: 0.274099
[TRAIN] Epoch:9 - Step:76 - Loss: 0.294602
[TRAIN] Epoch:9 - Step:77 - Loss: 0.231813
[TRAIN] Epoch:9 - Step:78 - Loss: 0.225045
[TRAIN] Epoch:9 - Step:79 - Loss: 0.180734
[TRAIN] Epoch:9 - Step:80 - Loss: 0.171899
[EVAL] Precision: 0.975000 - Recall: 0.984020 - F1: 0.979489
ErnieGram + CRF
'''
[EVAL] Precision: 0.992437 - Recall: 0.993272 - F1: 0.992854
[TRAIN] Epoch:9 - Step:73 - Loss: 0.100207
[TRAIN] Epoch:9 - Step:74 - Loss: 0.189141
[TRAIN] Epoch:9 - Step:75 - Loss: 0.051093
[TRAIN] Epoch:9 - Step:76 - Loss: 0.230366
[TRAIN] Epoch:9 - Step:77 - Loss: 0.271885
[TRAIN] Epoch:9 - Step:78 - Loss: 0.342371
[TRAIN] Epoch:9 - Step:79 - Loss: 0.050146
[TRAIN] Epoch:9 - Step:80 - Loss: 0.257951
[EVAL] Precision: 0.990764 - Recall: 0.992431 - F1: 0.991597
结论:CRF在ERNIE上体现作用不大,主要是在传统处理nlp语言上有显著作用,可以避免标注偏置问题。
快递单信息抽取【二】基于ERNIE1.0至ErnieGram + CRF预训练模型的更多相关文章
- django-表单之获取表单信息(二)
urls.py from django.urls import path from . import views urlpatterns = [ path('',views.index,name=&q ...
- Linux c使用gumbo库解析页面表单信息(二)
一.如何在程序当中使用gumbo? 要想在代码中使用gumbo,仅仅包含gumbo头文件是不够的,必须在编译程序的时候加上-lgumbo选项,编译程序才会链接到gumbo库上面. 这是我编译gumbo ...
- ML2021 | (腾讯)PatrickStar:通过基于块的内存管理实现预训练模型的并行训练
前言 目前比较常见的并行训练是数据并行,这是基于模型能够在一个GPU上存储的前提,而当这个前提无法满足时,则需要将模型放在多个GPU上.现有的一些模型并行方案仍存在许多问题,本文提出了一种名为 ...
- NLP知识图谱项目合集(信息抽取、文本分类、图神经网络、性能优化等)
NLP知识图谱项目合集(信息抽取.文本分类.图神经网络.性能优化等) 这段时间完成了很多大大小小的小项目,现在做一个整体归纳方便学习和收藏,有利于持续学习. 1. 信息抽取项目合集 1.PaddleN ...
- 基于ERNIELayout&pdfplumber-UIE的多方案学术论文信息抽取
本项目链接:https://aistudio.baidu.com/aistudio/projectdetail/5196032?contributionType=1 基于ERNIELayout& ...
- 基于Label studio实现UIE信息抽取智能标注方案,提升标注效率!
基于Label studio实现UIE信息抽取智能标注方案,提升标注效率! 项目链接见文末 人工标注的缺点主要有以下几点: 产能低:人工标注需要大量的人力物力投入,且标注速度慢,产能低,无法满足大规模 ...
- 中文预训练模型ERNIE2.0模型下载及安装
2019年7月,百度ERNIE再升级,发布持续学习的语义理解框架ERNIE 2.0,及基于此框架的ERNIE 2.0预训练模型, 它利用百度海量数据和飞桨(PaddlePaddle)多机多卡高效训练优 ...
- [信息抽取]基于ERNIE3.0的多对多信息抽取算法:属性关系抽取
[信息抽取]基于ERNIE3.0的多对多信息抽取算法:属性关系抽取 实体关系,实体属性抽取是信息抽取的关键任务:实体关系抽取是指从一段文本中抽取关系三元组,实体属性抽取是指从一段文本中抽取属性三元组: ...
- 基于MVC4+EasyUI的Web开发框架经验总结(16)--使用云打印控件C-Lodop打印页面或套打报关运单信息
在最新的MVC4+EasyUI的Web开发框架里面,我整合了关于网购运单处理的一个模块,其中整合了客户导单.运单合并.到货扫描.扣仓.出仓.查询等各个模块的操作,里面涉及到一些运单套打的操作,不过由于 ...
- PoiDemo【Android将表单数据生成Word文档的方案之二(基于Poi4.0.0)】
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 前言 使用Poi实现android中根据模板文件生成Word文档的功能.这里的模板文件是doc文件.如果模板文件是docx文件的话,请阅读 ...
随机推荐
- Codeforces Round 908 (Div. 2)
总结 T1 题目大意: A,B两人玩游戏,游戏规则如下: 整场游戏有多轮,每轮游戏先胜 \(X\) 局的人获胜,每场游戏先胜 \(Y\) 局的人获胜. 你在场边观看了比赛,但是你忘记了 \(x\) 和 ...
- 机器学习周刊 第4期:动手实战人工智能、计算机科学热门论文、免费的基于ChatGPT API的安卓端语音助手、每日数学、检索增强 (RAG) 生成技术综述
LLM开发者必读论文:检索增强(RAG)生成技术综述! 目录: 1.动手实战人工智能 Hands-on Al 2.huggingface的NLP.深度强化学习.语音课 3.Awesome Jupyte ...
- 数据工程师必备的8项技能,不要只知道Python!
欢迎关注公众号:机器学习算法与Python实战(ID:tjxj666) 原作:Mohammed M Jubapu 译者:机器学习算法与Python实战(公众号ID:tjxj666) 英文:https: ...
- MIGO BAPI_GOODSMVT_CREATE创建及增强
1.MIGO过账BAPI新增字段 BAPI新增收货行号字段,保存外围系统的数据 1.1.MATDOC表新增收货行号 1.2.MSEG表新增收货行号 创建DDL视图用于扩展NSDM_E_MSEG 1.3 ...
- Python | __init__.py的神奇用法
0._init_.py 在Python工程里,当python检测到一个目录下存在_init_.py文件时,python就会把它当成一个模块(module).Module跟C++的命名空间和Java的P ...
- 拥抱开放,Serverless 时代的下一征程
Serverless 作为云计算的最佳实践和未来演进趋势,其全托管免运维的使用体验和按量付费的成本优势使得它在云原生时代备受推崇.Serverless 的使用场景也由事件驱动,数据处理等部分特定场景转 ...
- S3C2440移植uboot之支持DM9000
上一节S3C2440移植uboot之支持NANDFLASH操作移植了uboot 支持了NANDFLASH的操作,这一节修改uboot支持DM9000. 目录 通过Makefile把dm9000x编 ...
- vue-devtools调试工具
- canvas验证码 uni-app/小程序
1 <template> 2 <view class="logo-wrapper"> 3 <view class="logo-img&quo ...
- C# 开发桌面应用简单介绍
一. C#使用场景介绍 C#是微软公司发布的一种由C和C++衍生出来的面向对象的编程语言.运行于.NET Framework和.NET Core(完全开源,跨平台)之上的高级程序设计语言. 二. 开发 ...