详解MRS HBase全局二级索引
本文分享自华为云社区《MRS HBase全局二级索引原理与使用场景》,作者:学习一下大数据 。
一、HBase二级索引背景介绍
HBase是基于Key-Value的分布式存储数据库,对表中的数据按照rowkey的字典进行排序;当已知要查询的数据rowkey或其范围,可以快速查找到需要读取的数据;HBase提供Filter功能来查询具有特定列值的数据,当无法确定rowkey范围时,条件查询会劣化为全表查询,表数据量较大的场景下,查询容易超时,无法满足查询时延要求。
与结构化数据库(例如MySQL)相似,HBase二级索引就是为了提升此类条件查询场景性能:查询条件无法精确/模糊匹配rowkey(类似于DB主键),同时严格要求查询时延。
二、MRS HBase二级索引原理
用户可以将定义经常查询的列定义为索引列,通过冗余存储索引列数据以达到加速查询的效果,将时间不可控的全表条件查询转换为区间条件查询,从而做到查询低时延。
MRS提供两种HBase二级索引:本地索引(HIndex)和 全局索引(GSI);两者的区别是:
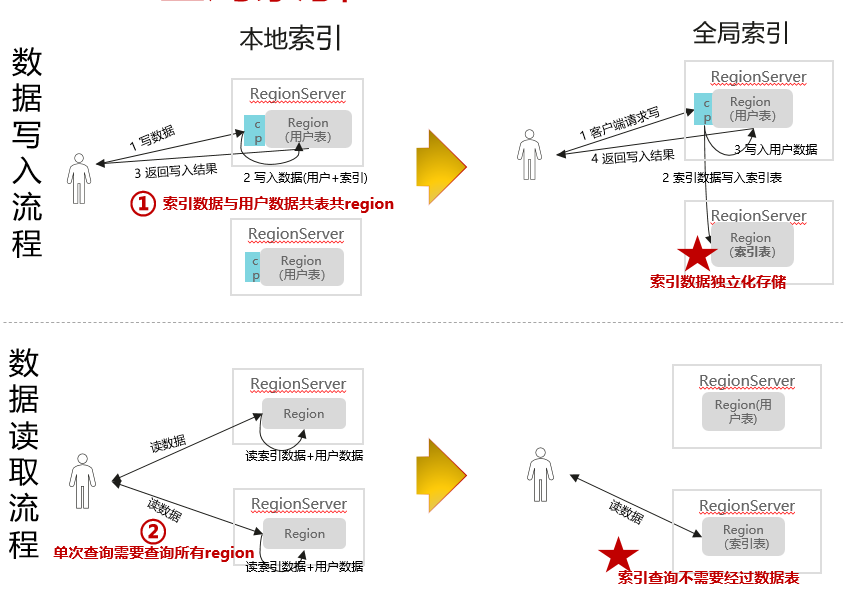

- 索引数据存储方式:本地索引存储索引数据到用户表的一个单独的列族中,全局索引存储到一个索引表中(索引数据独立存储)。
- 写入流程:本地索引一次性写入用户数据和索引数据,全局索引需要先后写入索引表和数据表。
- 读取流程:本地索引需要读取所有region的索引+用户数据,全局索引读取索引表(覆盖查询列场景下,不经过数据表)或索引表+数据表。
MRS 3.x版本提供了HBase全局索引能力,相较于本地索引,具有的优势有:
- 索引数据独立存储,解耦用户数据,稳定性更优。
- 索引查询链路优化,支持覆盖列(支持全覆盖),可以将经常查询的非索引列冗余存储到索引表,避免从原表获取数据,同时减少了查询过程中内部的RPC操作,在大规模数据场景下,查询性能更优。
此外,全局索引还提供以下工具,用于索引的维护:
- 索引创建/删除/状态修改工具
- 索引数据批量构建工具
- 索引数据一致性校验工具
三、MRS 全局二级索引使用场景
全局二级索引适用于以下场景:
- 经常使用固定条件(非rowkey)查询
- 查询时延有严格要求
- 用户表的数据量较大(region数量较多)
- 读多写少,对写入时延无严格要求(为保障索引数据一致性,全局索引采用分阶段式写入的方式,写入时延会有一定上升)
全局二级索引同时需要考虑,预留足够存储空间给索引表,索引数量/覆盖列/索引列越多,需要的空间越大,极限场景(全覆盖)下,与数据表大小相当。
四、MRS HBase全局二级设计与实战
基于HBase全局二级索引查询时,并非所有查询都能命中索引进行加速(HBase全局二级索引的使用规范详见用户手册),想要利用好索引功能,必须根据查询条件设计好索引。
以下实例展示了城市地点人流量统计功能实现,包括索引设计、查询条件等。
数据表定义
create 'city','cf',{SPLITS=>['0','1','2','3','4','5']}
rowkey定义:数据id(随机数字id,用于离散数据)

索引定义
索引名:idx_vn_time
索引字段:cf:visitors_nums+cf:time
覆盖列:全覆盖
该索引用于筛选人流量较大的地区信息
数据表查询对比
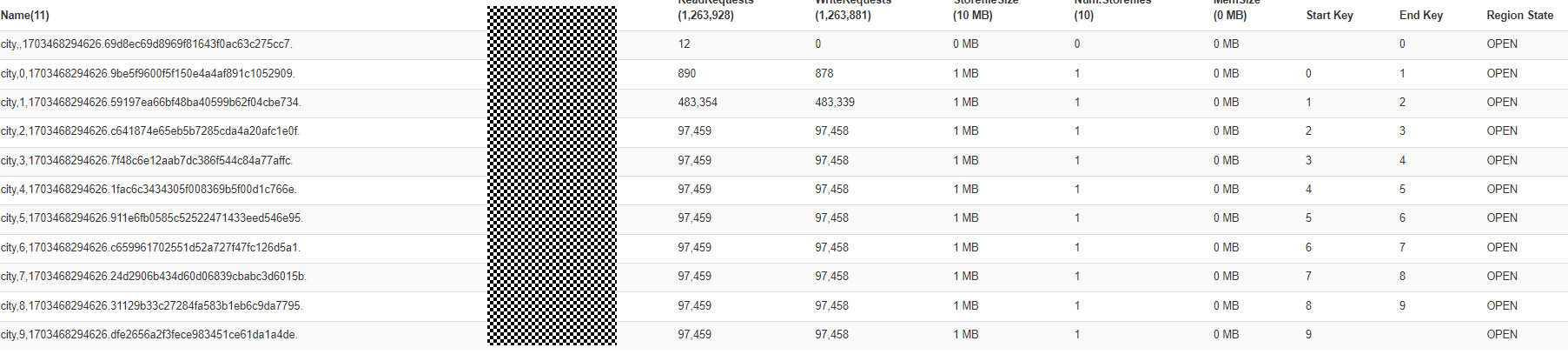
预置数据:10MB,预分区11个region,HBase集群节点3个
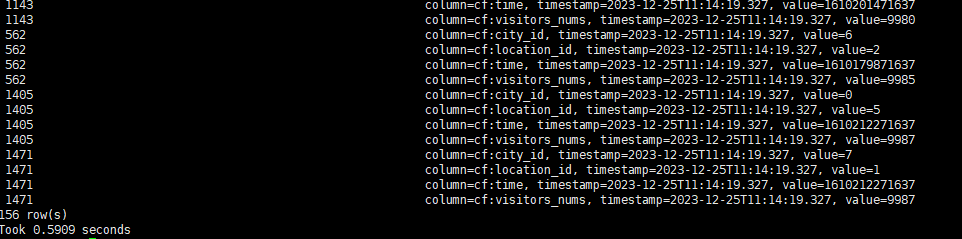
查询条件1:查询人流量大于9000的地区信息
scan 'city',{COLUMN=>'cf', FILTER=>"SingleColumnValueFilter('cf','visitors_nums',>=,'binary:9000')"}
禁用索引后再次查询
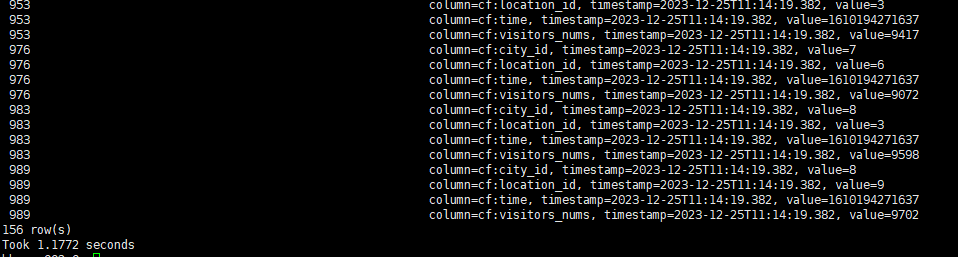
查询条件2:查询2021-01-10 0点-12点,人流量大于9000的地区信息
scan 'city',{COLUMN=>'cf', FILTER=>"SingleColumnValueFilter('cf','visitors_nums',>=,'binary:9000') AND SingleColumnValueFilter('cf','time',>=,'binary:1610208000000') AND SingleColumnValueFilter('cf','time',<,'binary:1610251200000')"}
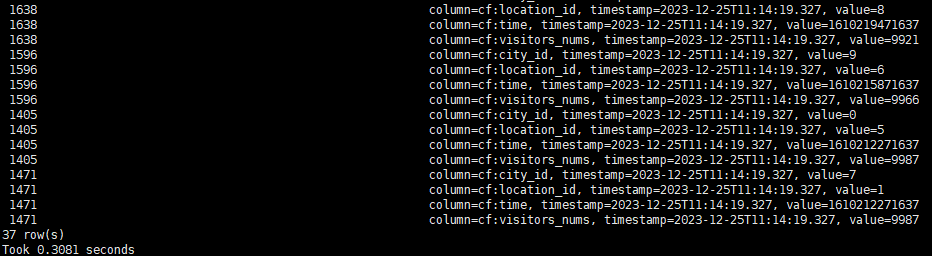
禁用索引后再次查询
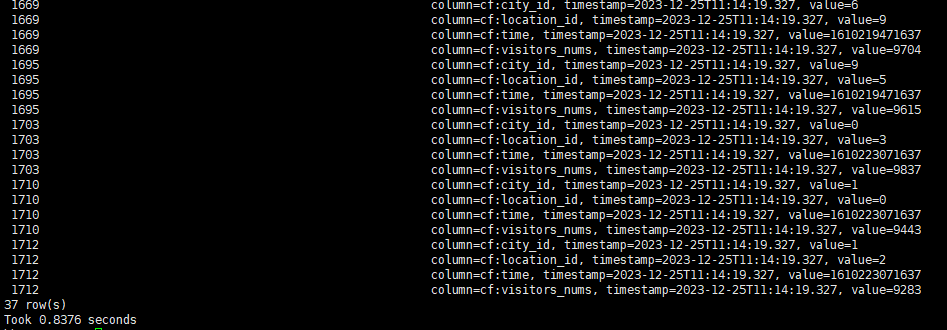
可以看到,命中索引时,查询效率提升十分明显,即使在小表上,也能获得数倍的性能提升。
注:命中索引后的查询结果按索引定义排序
详解MRS HBase全局二级索引的更多相关文章
- HBase详解(05) - HBase优化 整合Phoenix 集成Hive
HBase详解(05) - HBase优化 整合Phoenix 集成Hive HBase优化 预分区 每一个region维护着startRow与endRowKey,如果加入的数据符合某个region维 ...
- HBase的二级索引,以及phoenix的安装(需再做一次)
一:HBase的二级索引 1.讲解 uid+ts 11111_20161126111111:查询某一uid的某一个时间段内的数据 查询某一时间段内所有用户的数据:按照时间 索引表 rowkey:ts+ ...
- 085 HBase的二级索引,以及phoenix的安装(需再做一次)
一:问题由来 1.举例 有A列与B列,分别是年龄与姓名. 如果想通过年龄查询姓名. 正常的检索是通过rowkey进行检索. 根据年龄查询rowkey,然后根据rowkey进行查找姓名. 这样的效率不高 ...
- HBase建立二级索引的一些解决方式
HBase的一级索引就是rowkey,我们仅仅能通过rowkey进行检索. 假设我们相对hbase里面列族的列列进行一些组合查询.就须要採用HBase的二级索引方案来进行多条件的查询. 常见的二级索引 ...
- HBase详解(04) - HBase Java API使用
HBase详解(04) - HBase Java API使用 环境准备 新建Maven项目,在pom.xml中添加依赖 <dependency> <groupId>org.ap ...
- 大数据学习day11------hbase_day01----1. zk的监控机制,2动态感知服务上下线案例 3.HDFS-HA的高可用基本的工作原理 4. HDFS-HA的配置详解 5. HBASE(简介,安装,shell客户端,java客户端)
1. ZK的监控机制 1.1 监听数据的变化 (1)监听一次 public class ChangeDataWacher { public static void main(String[] arg ...
- 基于Solr实现HBase的二级索引
文章来源:http://www.open-open.com/lib/view/open1421501717312.html 实现目的: 由于hbase基于行健有序存储,在查询时使用行健十分高效,然后想 ...
- hbase coprocessor 二级索引
Coprocessor方式二级索引 1. Coprocessor提供了一种机制可以让开发者直接在RegionServer上运行自定义代码来管理数据.通常我们使用get或者scan来从Hbase中获取数 ...
- elasticsearch系列二:索引详解(快速入门、索引管理、映射详解、索引别名)
一.快速入门 1. 查看集群的健康状况 http://localhost:9200/_cat http://localhost:9200/_cat/health?v 说明:v是用来要求在结果中返回表头 ...
- [How to] MapReduce on HBase ----- 简单二级索引的实现
1.简介 MapReduce计算框架是二代hadoop的YARN一部分,能够提供大数据量的平行批处理.MR只提供了基本的计算方法,之所以能够使用在不用的数据格式上包括HBase表上是因为特定格式上的数 ...
随机推荐
- 【RocketMQ】RocketMQ存储结构设计
CommitLog 生产者向Broker发送的消息,会以顺序写的方式,写入CommitLog文件,CommitLog文件的根目录由配置参数storePathRootDir决定,默认每一个CommitL ...
- 文心一言 VS 讯飞星火 VS chatgpt (111)-- 算法导论10.2 2题
二.用go语言,用一个单链表 L实现一个栈.要求操作 PUSH和 POP 的运行时间仍为 O(1). 文心一言: 在 Go 语言中,我们可以用结构体来实现一个单链表,然后再用栈的相关操作. 以下是一个 ...
- Kafka的零拷贝技术Zero-Copy
传统的拷贝过程 流程步骤: (1)操作系统将数据从磁盘文件中读取到内核空间的页面缓存: (2)应用程序将数据从内核空间读入用户空间缓冲区: (3)应用程序将读到数据写回内核空间并放入socket缓冲区 ...
- 如何写出优雅的代码?试试这些开源项目「GitHub 热点速览」
又是一期提升开发效率的热点速览,无论是本周推特的检查 Python 语法和代码格式的 ruff,或者是 JS.TS 编译器 oxc,都是不错的工具,有意思的是它们都是 Rust 写的. 此外,还有用来 ...
- 文心一言 VS 讯飞星火 VS chatgpt (130)-- 算法导论11.2 2题
二.用go语言,对于一个用链接法解决冲突的散列表,说明将关键字 5,28,19,15,20,33,12,17,10 插入到该表中的过程.设该表中有 9 个槽位,并设其散列函数为 h(k)=k mod ...
- 解决IDEA中.properties文件中文变问号(???)的问题(已解决)
问题背景 构建SpringBoot项目时,项目结构中有一个application.properties文件.这个项目是Spring Boot一个特有的配置文件.内容如下(我写了一些日志的配置): 写到 ...
- SNN_文献阅读_Effective and Efficient Computation with Multiple-timescaleSpiking Recurrent Neural Networks
Adaptive SRNN 基于多时间尺度脉冲循环神经网络的高效计算(SRNN) 中心思想: 使用替代梯度进行训练,克服SNN中梯度不连续的问题. 在PyTorch中直接使用BPTT进行训练. 结构 ...
- re1-100
虽然关键的判断函数和"成功"的提示也在这里,但是具体对输入flag的操作却在后面 看到对数组bufParentRead[1]开始赋值"53fc275d81",b ...
- 一篇文章带你了解Python常用自动化测试框架——Pytest
一篇文章带你了解Python常用自动化测试框架--Pytest 在之前的文章里我们已经学习了Python自带测试框架UnitTest,但是UnitTest具有一定的局限性 这篇文章里我们来学习第三方框 ...
- 在路上---学习篇(一)Python 数据结构和算法 (1)
数据结构和算法 现阶段的肤浅理解数据结构是各式各样的类型数据在内存中是如何构造的,原理是怎么样的. 了解了其本质后,在面对问题时候,根据数据结构利用算法计算可以最快,最有效的完成任务.通常情况下,精心 ...