RDD | 算子 | 持久化
分布式集合对象上的API称之为算子
算子分为两类:
transformation算子:指返回值仍然是rdd,类似于stream里的中间流
这类算子与中间流相同,是懒加载的
action算子:返回值不是rdd,类似于stream里的终结流
常见算子:
transformation算子
1.map(func):将rdd的数据一条一条的处理,返回新的rdd,和stream流的一样
2.flatmap:对rdd先执行map操作,再进行解除嵌套操作
3.reduceByKey:针对KV型RDD,自动按照key分组,根据提供的聚合逻辑完成聚合操作
4.mapValues:针对KV型RDD,对其中的value进行map操作
5.groupBy:通过这个算子指定你选择谁进行分组 lambda t:t[0]
6.filter:和stream一样
7.distinct:去重,无参
#下面这几个都是传入的参数也为rdd
8.union:合并,将2个rdd合并为一个,参数为另一个rdd 注意:1.不同类型可以合并 2.不会去重
9.join:使用方法同上,类似于MySQL的join,所以也有左连接和右连接。注意:只能用于二元的
10.intersection:用法同上,求交集
11.glom:将rdd进行嵌套,这个嵌套按照分区进行
12.groupByKey:针对KV型RDD,自动按照K分组(与reduceByKey相比,他少一步聚合的操作)
13.sortBy:排序,函数自己定,三个参数:func,T/F(升/降序),使用多少分区
14.sortByKey:三个参数:T/F,分区,对key进行处理的lambda。注意,这里对key进行的处理不会影响到collect的结果
action算子
15.countByKey:通过key进行计数(KV型RDD)返回的是dict
16.collect:新手村算子 返回的是list
17.reduce:聚合逻辑类似reduceByKey,但是返回的不是rdd
18.fold:类似于reduce,带有初始值 注意:如果是有分区的话,这个方法会在分区内分区外都进行初始值的相加,会产生n+1个初始值
19.first:返回第一个元素
20.take:参数为n,返回前n个元素
21.top:参数n,降序排序取前n
22.count:返回的是有多少条
23.takeSample:随便抽样rdd数据,参数1:T/F T:允许取同一数据 参数2:抽样的个数 参数3:步径,可省略
24.takeOrdered:正常情况下与top相反。参数1:返回几个元素 参数2:(lambda x:-x)控制升序降序,就是强化的top
//下面两个效率性能是比较好的,他们会由executor进行输出,绕过了driver
25.foreach:和map一样,但是没有返回值。与其他action算子不同的是,这个算子是由executor输出的,而非driver,因此他的效率更高 # 还是像stream流
26.saveAsTextFile:支持本地/hdfs的写出 # 生成几个文件和你分区使用几个有关。与上一个算子相同,他也不经过driver
transformation分区操作算子
27.mapPartitions:一次传输一整个分区,而且接收和传出的都是迭代器对象,比map的性能更好,减少了IO
28.foreachPartitions:同上
29.partitionBy:自定义分区操作 参数1:有几个分区 参数2:分区规则 | 如果不用这个就是用hash分区
30.repartition:重新分区(但是仅数量)!!慎重使用!!:除了全局排序要用一个分区以外,多数的时候分区我们一般不理会。分区增加极大可能导致shuffle
面试题:
groupByKey与reduceByKey的区别
1.groupByKey仅仅是分组,reduceByKey在此之上还有个聚合功能
2.reduceByKey的性能是远远大于groupByKey+聚合:groupByKey需要先分组再执行聚合,而reduceByKey会先预聚合再分组再聚合,shuffle的开销很小
RDD持久化:
RDD的数据是过程数据:一旦新RDD生成,老RDD就会消失。这样会腾出内存,可最大化的利用资源。所以如果重复使用同一个RDD,那么这个RDD的前置RDD都需要执行
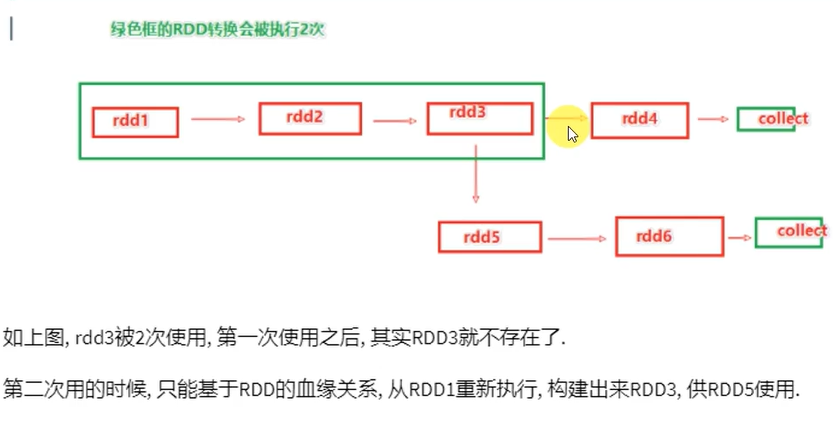
RDD缓存:

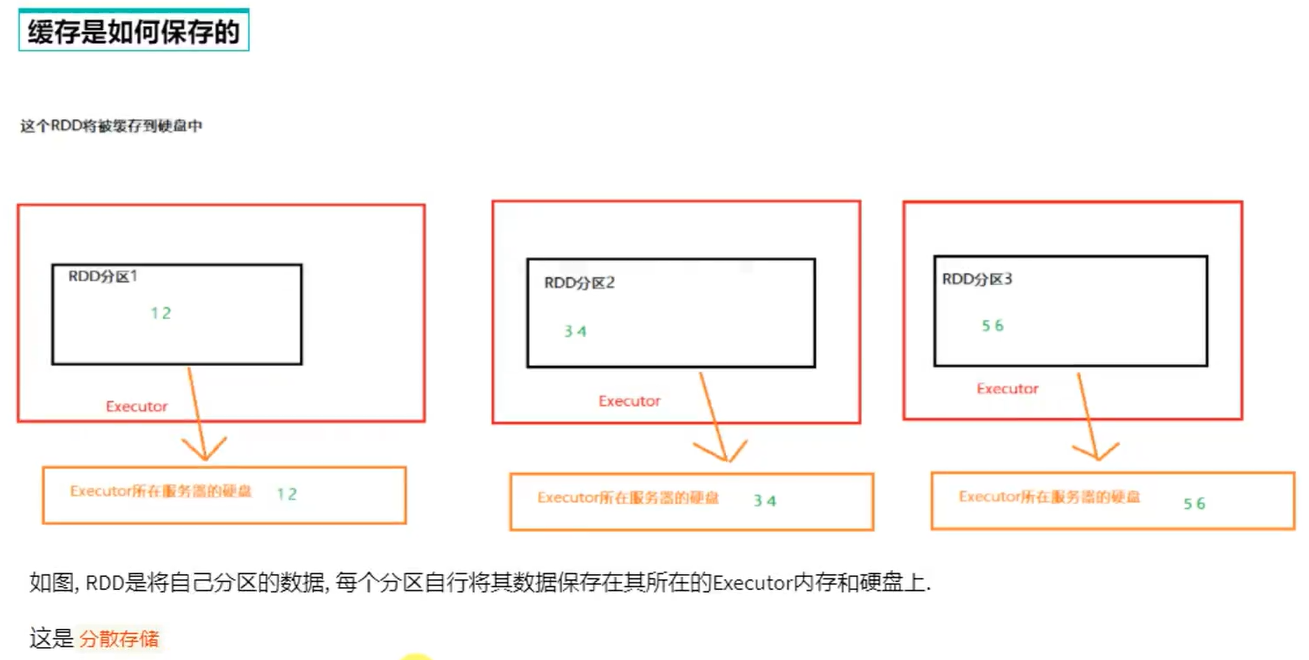
缓存的特点:可以将过程RDD数据持久化保存在内存/硬盘,但是设定上被认为是不安全的
保留RDD之间的血缘关系,因为一旦缓存丢失,可以基于血缘关系的记录重新计算这个RDD的数据
为什么不安全?内存中的缓存会因为断电,计算任务内存不足把缓存清理给计算让路,而硬盘中因为硬盘损坏也是可能丢失的
CheckPoint技术
将RDD数据保存起来,仅支持硬盘存储
checkpoint:设计认为是安全的,所以才不保留血缘关系
checkpoint是集中收集各个分区的数据进行集中存储,可以放在HDFS中,而缓存是分散存储
因此checkpoint不管分区多少数量风险一致,但缓存分区越高风险越高
缓存的性能比checkpoint好一些,因为缓存直接拉内存
sc.setCheckpointDir(" ") # 设置cp的保存路径
rdd.checkpoint() # 直接调用checkpoint算子 这句话就是和rdd.cache()一样
cache与checkpoint对比
cache是轻量化的,可以存储在硬盘或内存,分散存储,设计上认为是不安全的。性能更好,是executor并行执行
checkpoint是重量化的,仅存储在硬盘(HDFS),集中存储,设计上是安全的,所以不设血缘关系。性能差,设计到网络IO
RDD | 算子 | 持久化的更多相关文章
- Spark RDD 算子总结
Spark算子总结 算子分类 Transformation(转换) 转换算子 含义 map(func) 返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成 filter(func) ...
- Spark性能调优-RDD算子调优篇(深度好文,面试常问,建议收藏)
RDD算子调优 不废话,直接进入正题! 1. RDD复用 在对RDD进行算子时,要避免相同的算子和计算逻辑之下对RDD进行重复的计算,如下图所示: 对上图中的RDD计算架构进行修改,得到如下图所示的优 ...
- Spark(七)【RDD的持久化Cache和CheckPoint】
RDD的持久化 1. RDD Cache缓存 RDD通过Cache或者Persist方法将前面的计算结果缓存,默认情况下会把数据以缓存在JVM的堆内存中.但是并不是这两个方法被调用时立即缓存,而是 ...
- 对一些常用RDD算子的总结
虽然目前逐渐sql化,但是掌握 RDD 常用算子是做好 Spark 应用开发的基础,而数据转换类算子则是基础中的基础,因此学习这些算子还是很有必要的. 这篇博客主要参考Spark官方文档中RDD编程一 ...
- spark新能优化之多次使用RDD的持久化或checkPoint
如果程序中,对某一个RDD,基于它进行了多次transformation或者action操作.那么就非常有必要对其进行持久化操作,以避免对一个RDD反复进行计算. 此外,如果要保证在RDD的持久化数据 ...
- RDD算子
RDD算子 #常用Transformation(即转换,延迟加载) #通过并行化scala集合创建RDD val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8 ...
- RDD 算子补充
一.RDD算子补充 1.mapPartitions mapPartitions的输入函数作用于每个分区, 也就是把每个分区中的内容作为整体来处理. (map是把每一行) mapPa ...
- RDD算子、RDD依赖关系
RDD:弹性分布式数据集, 是分布式内存的一个抽象概念 RDD:1.一个分区的集合, 2.是计算每个分区的函数 , 3.RDD之间有依赖关系 4.一个对于key-value的RDD的Partit ...
- 28、对多次使用的RDD进行持久化或Checkpoint
一.图解 二.说明 如果程序中,对某一个RDD,基于它进行了多次transformation或者action操作.那么就非常有必要对其进行持久化操作,以避免对一个RDD反复进行计算. 此外,如果要保证 ...
- spark教程(四)-SparkContext 和 RDD 算子
SparkContext SparkContext 是在 spark 库中定义的一个类,作为 spark 库的入口点: 它表示连接到 spark,在进行 spark 操作之前必须先创建一个 Spark ...
随机推荐
- Python实现五子棋人机对战的二次开发
Python实现人机对战的二次开发 在网上找到了一个使用python实现五子棋游戏,其中通过加入一个简单的AI算法实现了人机对战的功能,我觉得这个人机对战还是蛮有意思的,下面我分析一下五子棋游 ...
- Qt OPC UA通信
介绍 OPC UA全称Open Platform Unified Architecture,开放平台统一架构,是工业自动化领域通用的数据交换协议,它有两套主要的通信机制:1.客户端-服务器通信:2.发 ...
- 为何Mysql数据库上读和代码读取的数据不一致
上周,做了一个同步删除的功能,具体流程是,数据库删除-->调用第三方运行删除接口,同步删除. 具体流程 数据库删除数据后,这里使用标志删除,再调用第三方数据. 在调用第三方数据之前需要通过id查 ...
- C# 机器学习
前言: 提起人工智能,机器学习.大家都是一脸懵的样子.其实呢,就是根据数据进行训练.然后可以大概的预测结果.Visual Studio2019 Preview中提供了图形界面的ML.Net,所以,只要 ...
- LeetCode 673. Number of Longest Increasing Subsequence 最长递增子序列的个数 (C++/Java)
题目: Given an unsorted array of integers, find the number of longest increasing subsequence. Example ...
- C++常用模板
常用模板: 数学: 1. 组合数 组合数 #include<bits/stdc++.h> using namespace std; #define ll long long const l ...
- Vue学习:5.v-bind使用
第一节算是对v-bind的粗略了解,仅仅是列举了v-bind的使用.这一节将更详细的了解v-bind的具体用法. v-bind是 Vue.js 中常用的指令之一,用于动态地绑定属性或者表达式到 HTM ...
- 如何将 iPhone 的照片同步到 windows 电脑上
首先在电脑上,新建一个文件夹,并把共享权限打开. 文件夹 右键 属性,共享,添加 Everyone. 然后,让手机和电脑连接到同一个局域网,手机热点即可. 在手机端看 文件 app,找到电脑的共享文件 ...
- Java实现延迟执行代码
Java实现延迟执行代码对于Java程序在它们的操作中添加延迟或暂停是比较常见的.这对于任务暂停直到另外任务完成执行场景比较有用.本文我们提供两类方法实现延迟执行. 1. 基于线程(Thread)方法 ...
- LocalDateTime日期相互转换字符串
/** LocalDateTime日期相互转换字符串 * 默认的时间日期样式 */ public static final String YYYYMMDDHHMMSSS_PATTERN = " ...