聊聊魔塔社区MGeo模型的部署与运行
从现今与今后的发展来看,单一的业务不再仅仅依靠于传统的技术开发,而是应该结合AI模型来应用、实践。只有这样,才能更数智化,更高效化,更贴合时代的发展。
魔塔 社区就类似国外的Hugging Face,是一个模型即服务的运行平台。在这个平台上运行着很多的大模型示例,网站直接提供了试运行的环境,也可以下载代码到本地部署运行或是在阿里云的PAI平台运行。
pytorch环境搭建
我是跟着 Pytorch-Gpu环境配置 博文一步一步搭建起来的。唯一不同的是,我不是基于Anaconda虚拟环境搭建,而是直接在本地环境部署pytorch与CUDA。
开着西部世界的VPN,下载pytorch与CUDA会快一些,在本地下载好了pytorch的whl文件后,直接在下载目录中打开cmd窗口,使用pip install xxxx.whl安装pytorch即可。
RaNER 模型搭建与运行
进入魔塔官网,找到MGeo模型,首先必须要下载modelscope包。在MGeo的模型介绍中,以及有详细的命令说明,如下:
# GPU版本
conda create -n py37testmaas python=3.7
pip install cryptography==3.4.8 tensorflow-gpu==1.15.5 torch==1.11.0 torchvision==0.12.0 torchaudio==0.11.0
pip install "modelscope[nlp]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
但是对于我来说,并没有用到conda虚拟环境,所以我只是运行了最后的pip命令,如下:
pip install "modelscope[nlp]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
命令输出内容如下:
最好是开着VPN执行命令,否则会很慢。下载完后有一个报错,可以忽略,最后我成功安装的组件有:
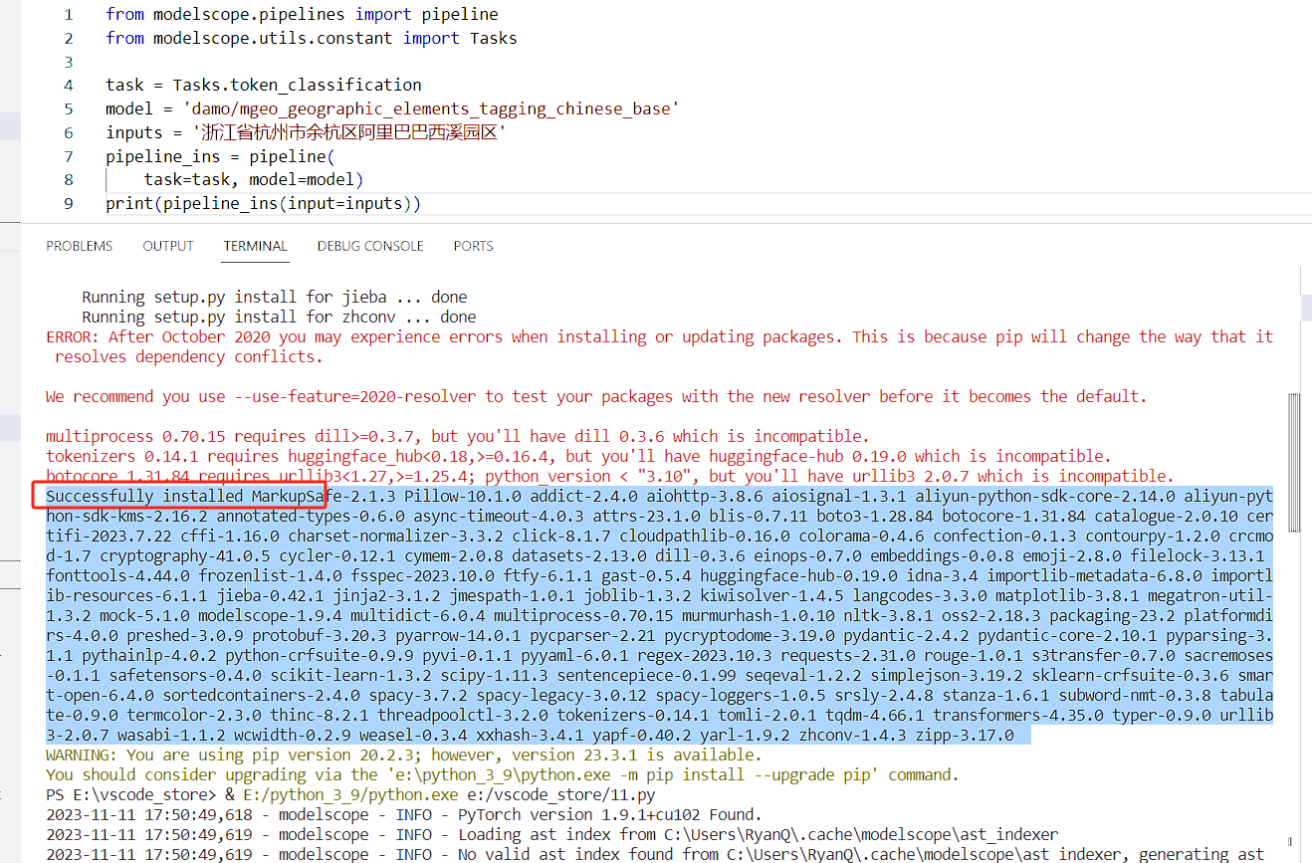
如此,便完成了modelscope包的安装。然后拷贝示例代码在本地运行即可,示例代码如下:
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
task = Tasks.token_classification
model = 'damo/mgeo_geographic_elements_tagging_chinese_base'
inputs = '浙江省杭州市余杭区阿里巴巴西溪园区'
pipeline_ins = pipeline(
task=task, model=model)
print(pipeline_ins(input=inputs))
# 输出
# {'output': [{'type': 'prov', 'start': 0, 'end': 3, 'span': '浙江省'}, {'type': 'city', 'start': 3, 'end': 6, 'span': '杭州市'}, {'type': 'district', 'start': 6, 'end': 9, 'span': '余杭区'}, {'type': 'poi', 'start': 9, 'end': 17, 'span': '阿里巴巴西溪园区'}]}
运行过程中,也会有一些提示,还是很有意思的,可以看看.
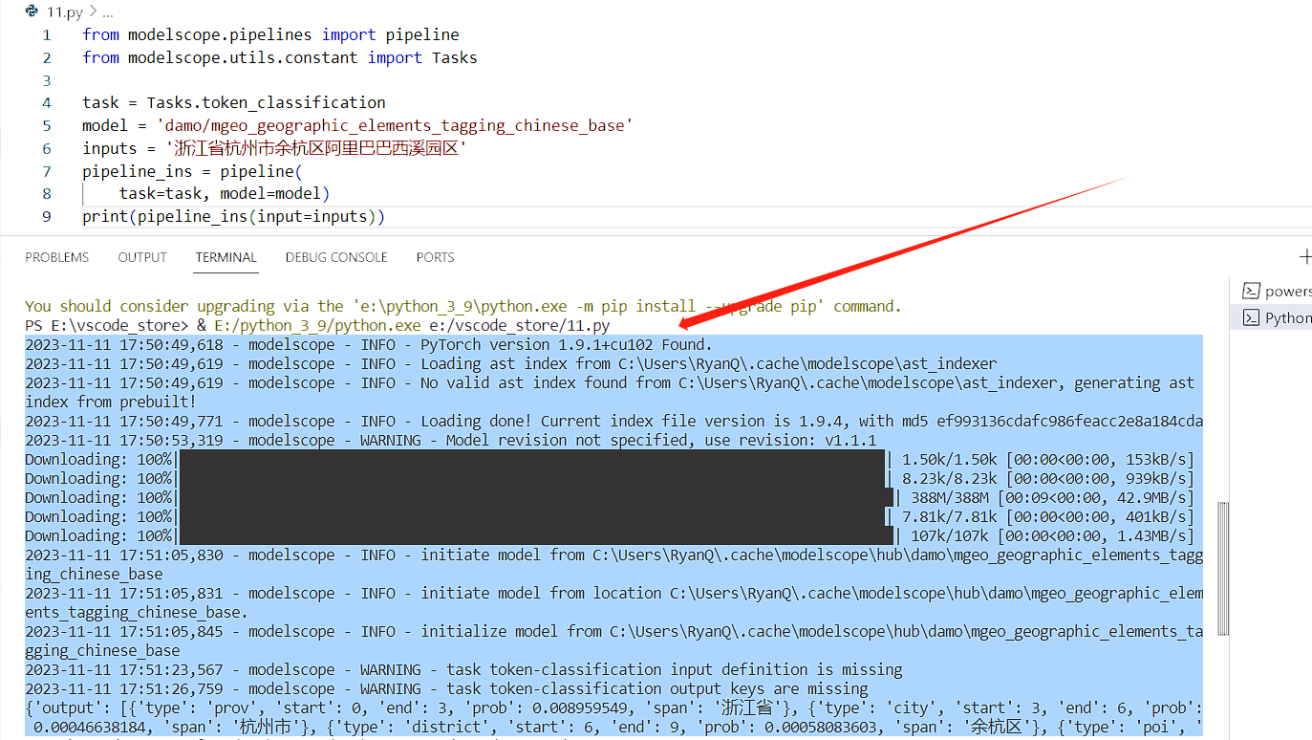
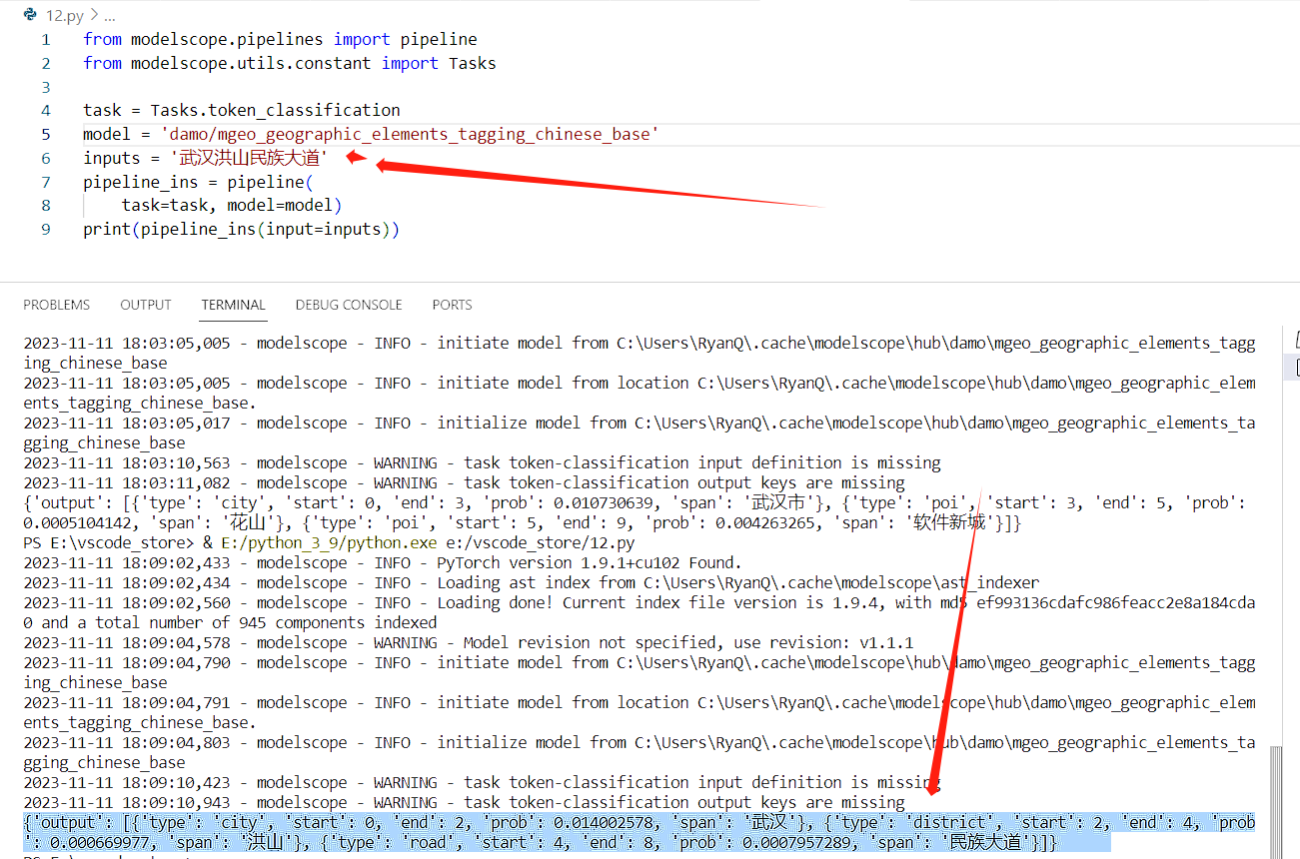
最后的结果也是正常的输出了,对于输出结果的解释,我就不多说,可以看API文档解释。我换成其它地址继续测试:
总结
最后说一下自己的实际感受。首先这个MGEO的AI模型,在我上家公司我主导做的项目就用到了,当时是花钱在阿里云的 地址标准化 产品上购买使用,用于在实际的项目中根据客户输入的地址提取省市区并再次输入到目标网站。当时一开始想的是自己找开源的库来实现,后来发现有点难,因为客户输入的辨识度太低,可能性太多,而且我们不能规范客户的输入(主要是历史数据太多)。因此当时找了好多方案,最后发现阿里云有这个支持,就花钱购买调用解决问题。从现在来看,其实整个模型与应用完全可以自己搭建部署起来,省钱又能自我管控,而且还能二次开发,毕竟现在以及前几年做AI算法的人还是不少的(当时我们公司也有少数做AI相关的人,自己现在也算是个半吊子水平,看得懂也能改一点),唉,总的来说还是当时的能力限制了,还是得多学多思考,尤其是现在AI模型的普遍性与高速发展,程序猿学习成本与门槛降低很多很多。
聊聊魔塔社区MGeo模型的部署与运行的更多相关文章
- 139、TensorFlow Serving 实现模型的部署(二) TextCnn文本分类模型
昨晚终于实现了Tensorflow模型的部署 使用TensorFlow Serving 1.使用Docker 获取Tensorflow Serving的镜像,Docker在国内的需要将镜像的Repos ...
- 138、Tensorflow serving 实现模型的部署
将Tensorflow模型部署成Restful接口 下面是实现过程,整个操作都是在Linux上面实现的,因为Tensorflow Serving 目前还只支持Linux 这个意义真的是革命性的,因为从 ...
- 百度大脑EasyEdge端模型生成部署攻略
EasyEdge是百度基于Paddle Mobile研发的端计算模型生成平台,能够帮助深度学习开发者将自建模型快速部署到设备端.只需上传模型,最快2分种即可生成端计算模型并获取SDK.本文介绍Easy ...
- 三分钟快速上手TensorFlow 2.0 (下)——模型的部署 、大规模训练、加速
前文:三分钟快速上手TensorFlow 2.0 (中)——常用模块和模型的部署 TensorFlow 模型导出 使用 SavedModel 完整导出模型 不仅包含参数的权值,还包含计算的流程(即计算 ...
- 三分钟快速上手TensorFlow 2.0 (中)——常用模块和模型的部署
本文学习笔记参照来源:https://tf.wiki/zh/basic/basic.html 前文:三分钟快速上手TensorFlow 2.0 (上)——前置基础.模型建立与可视化 tf.train. ...
- 二手车价格预测 | 构建AI模型并部署Web应用 ⛵
作者:韩信子@ShowMeAI 数据分析实战系列:https://www.showmeai.tech/tutorials/40 机器学习实战系列:https://www.showmeai.tech/t ...
- 【实战】yolov8 tensorrt模型加速部署
[实战]yolov8 tensorrt模型加速部署 TensorRT-Alpha基于tensorrt+cuda c++实现模型end2end的gpu加速,支持win10.linux,在2023年已经更 ...
- Windows10下yolov8 tensorrt模型加速部署【实战】
Windows10下yolov8 tensorrt模型加速部署[实战] TensorRT-Alpha基于tensorrt+cuda c++实现模型end2end的gpu加速,支持win10.linux ...
- Win10下yolov8 tensorrt模型加速部署【实战】
Win10下yolov8 tensorrt模型加速部署[实战] TensorRT-Alpha基于tensorrt+cuda c++实现模型end2end的gpu加速,支持win10.linux,在20 ...
- Xamarin 跨移动端开发系列(01) -- 搭建环境、编译、调试、部署、运行
如果是.NET开发人员,想学习手机应用开发(Android和iOS),Xamarin 无疑是最好的选择,编写一次,即可发布到Android和iOS平台,真是利器中的利器啊!好了,废话不多说,就开始吧, ...
随机推荐
- Linux 命令:gpasswd 管理用户组
工作中经常需要将用户加入docker组,可执行如下操作: sudo gpasswd -a ec2-user docker newgrp # 不用加sudo gpasswd gpasswd -h Usa ...
- Linux 下的 OpenGL 之路(九):天空盒、反射和折射
前言 搞定了天空盒,才算是真正完成了场景的搭建,以后再要进行什么样的图形学测试,都可以在这个场景下进行.比如后面的反射.折射就是这样的例子. 写完这篇,我决定暂时结束这个系列.主要是因为我太懒了,居然 ...
- TypeScript:Type 'boolean' is not assignable to type 'never'.
问题原因 当我们声明一个空数组而不显示键入它并尝试向其中添加元素时,会发生该错误. 解决方案 声明数组类型即可 参考链接 https://bobbyhadz.com/blog/typescript-a ...
- Django链接数据库出现的错误以及解决方法
问题一:django.db.utils.OperationalError: (1045, "Access denied for user 'leo'@'localhost' (using p ...
- CentOS7系统初始化个人配置
以下内容为个人最小化安装后的配置步骤 更换yum源为阿里云 yum install -y epel-release lrzsz wget yum-axelget mv /etc/yum.repos.d ...
- 1.创建一个类,类A中定义了一个方法,该方法能接受3个参数根据参数判断是做加法还是减法并返回计算结果;
class A: def cal(self,x,y,z): if z=='+': return x+y if z=='-': return x-y else: print('error') a=A() ...
- Go代码包与引入:如何有效组织您的项目
本文深入探讨了Go语言中的代码包和包引入机制,从基础概念到高级应用一一剖析.文章详细讲解了如何创建.组织和管理代码包,以及包引入的多种使用场景和最佳实践.通过阅读本文,开发者将获得全面而深入的理解,进 ...
- k8s添加节点报[WARNING SystemVerification]: missing optional cgroups: blkio
环境信息: ubuntu-master01 192.1681.195.128 ubuntu-work01 192.168.195.129 k8s版本 1.25.2 背景描述:初始环境是一个ma ...
- 基于Python的HTTP代理爬虫开发初探
前言 HTTP代理爬虫在爬取网页数据时,使用Python程序模拟客户端请求,同时使用HTTP代理服务器来隐藏客户端的真实IP地址.这样可以有效防止在爬取大量网页数据时被目标网站封禁IP地址. 以下是基 ...
- maven缺失ojdbc6解决方法(手动安装ojdbc6)
maven缺失ojdbc6解决方法(手动安装ojdbc6) 1. 首先下载ojdbc6jar包 jar下载地址一(需登录) jar下载地址二(直接下载) 2. 进入到jar包所在文件夹,执行cmd命令 ...