简介: 对于运维人而言,如何安装维护一套监控系统,或如何进行技术选型,从来不是工作重点。如何借助工具对所需的应用、组件进行监控,发现并解决问题才是重中之重。随着 Prometheus 逐渐成为云原生时代可观测标准,为了帮助更多运维人用好 Prometheus,阿里云云原生团队将定期更新 Prometheus 最佳实践系列。第一期我们讲解了《最佳实践|Spring Boot 应用如何接入 Prometheus 监控》,今天将为大家带来,消息队列产品 Kafka 的监控最佳实践。
对于运维人而言,如何安装维护一套监控系统,或如何进行技术选型,从来不是工作重点。如何借助工具对所需的应用、组件进行监控,发现并解决问题才是重中之重。 随着 Prometheus 逐渐成为云原生时代可观测标准,为了帮助更多运维人用好 Prometheus,阿里云云原生团队将定期更新 Prometheus 最佳实践系列。第一期我们讲解了《最佳实践|Spring Boot 应用如何接入 Prometheus 监控》,今天将为大家带来,消息队列产品 Kafka 的监控最佳实践。 本篇内容主要包括三部分:Kafka 概览介绍、常见关键指标解读、如何建立相应监控体系。 什么是 Kafka Kafka 起源 Kafka 是由 Linkedin 公司开发,并捐赠给 Apache 软件基金会的分布式发布订阅消息系统,Kafka 的目的是通过 Hadoop 的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
Kafka 的诞生是为了解决 Linkedin 的数据管道问题,用作 LinkedIn 的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础。起初 Linkedin 采用 ActiveMQ 进行数据交换,但当时的 ActiveMQ 无法满足 Linkedin 对数据传递系统的要求,经常出现消息阻塞或者服务无法正常访问等问题。Linkedin 决定研发自己的消息队列,Linkedin 时任首席架构师 Jay Kreps 便开始组建团队进行消息队列的研发。 Kafka 特性 相较于其他消息队列产品,Kafka 存在以下特性:
与此同时,区别于其他消息队列产品,Kafka 不使用 AMQP 或任何其他预先存在的协议进行通信,使用基于 TCP 的自定义二进制协议。并具有强大的排序语义和持久性保证。 Kafka 应用场景 基于以上的特性,Kafka 通过实时的处理大量数据以满足各种需求场景:
大数据领域:如网站行为分析、日志聚合、应用监控、流式数据处理、在线和离线数据分析等领域。
数据集成:将消息导入 ODPS、OSS、RDS、Hadoop、HBase 等离线数据仓库。
流计算集成:与 StreamComput e、E-MapReduce、Spark、Storm 等流计算引擎集成。
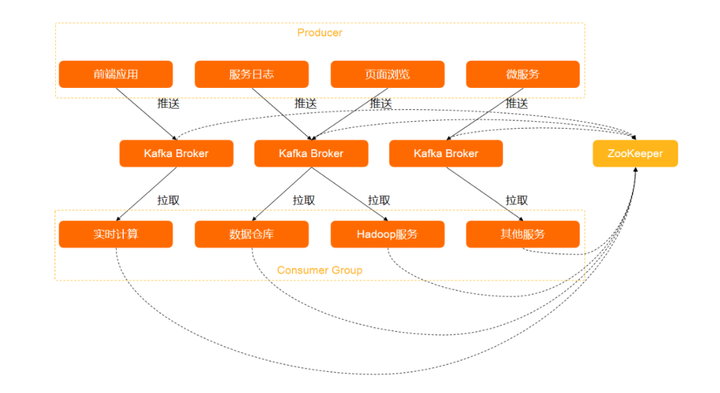
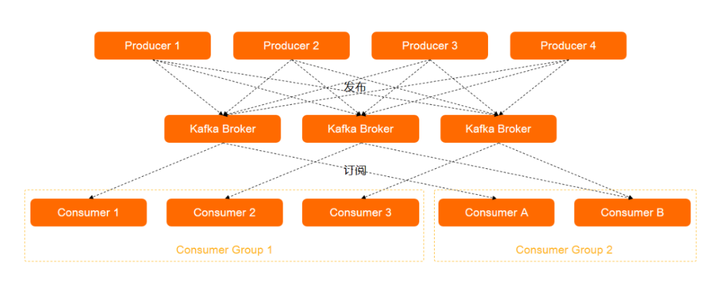
Kafka 技术架构 一个消息队列 Kafka 版集群包括 Producer、Kafka Broker、Consumer Group、Zookeeper。

添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
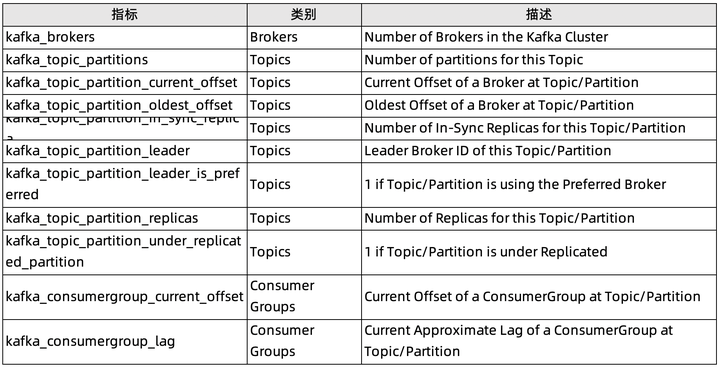
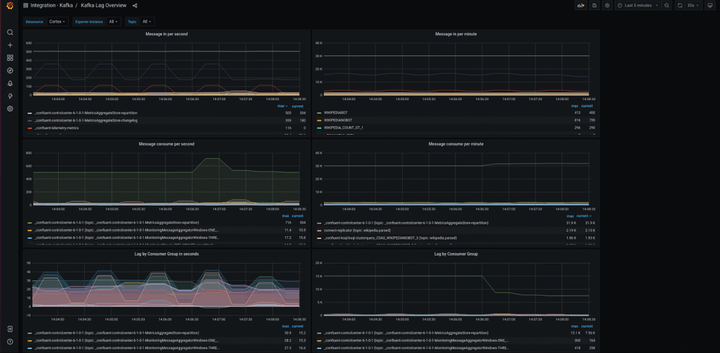
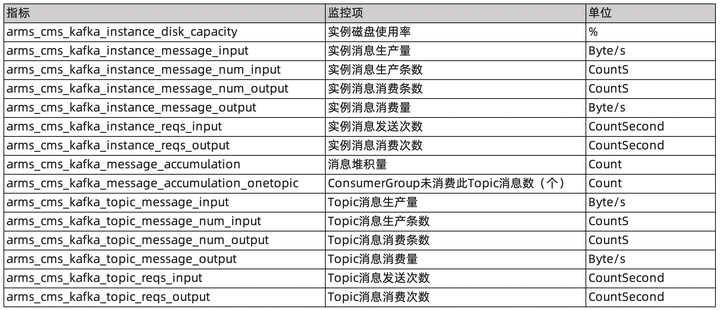
监控 Kafka 的关键指标 这里我们根据 Kafka 云服务以及自建 Kafka 两个不同的产品进行讲解。 如果使用的 Kafka 是云厂商提供的托管服务,对外暴露的指标相对有限,可以忽略 Zookeeper 相关指标。以阿里云 Kafka 举例,主要针对各资源类型进行监控: 1、实例监控项
Topic 消息生产流量(bytes/s)
Topic 消息消费流量(bytes/s)
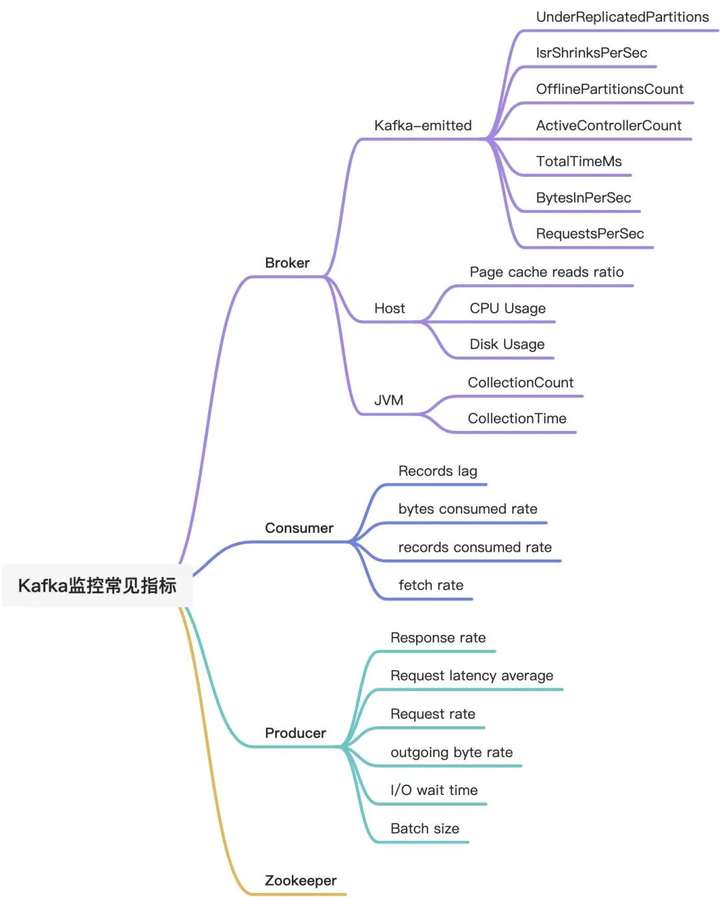
如果使用自建 Kafka,那么需要关注的指标就非常多,主要包含以下四个方向:Broker、Producer、Consumer、Zookeeper。
添加图片注释,不超过 140 字(可选)
Broker 指标 由于所有消息都必须通过 Broker 才能被使用,因此,对 Broker 进行监控并预警非常重要。Broker 指标关注:Kafka-emitted 指标、Host-level 指标、JVM 垃圾收集指标。
1. 未复制的分区数:UnderReplicatedPartitions(可用性)kafka.server:type=ReplicaManager,name=UnderReplicatedPartitions 在运行正常集群中,同步副本(ISR)数量应等于副本总数。如果分区副本远远落后于 Leader,则从 ISR 池中删除这个 follower。如果代理不可用,则 UnderReplicatedPartitions 指标急剧增加。Tips:UnderReplicatedPartitions 较长时间内大于零,需要进行排查。 2. 同步副本(ISR)池缩小/扩展的速率:IsrShrinksPerSec / IsrExpandsPerSec(可用性)kafka.server:type=ReplicaManager,name=IsrShrinksPerSec Tips:如果某副本在一段时间内未联系 Leader 或者 follower 的 offset 远远落后于 Leader,则将其从 ISR 池中删除。因此,需要关注 IsrShrinksPerSec / IsrExpandsPerSec 的相关波动。IsrShrinksPerSec 增加,不应该造成 IsrExpandsPerSec 增加。在扩展 Brokers 集群或删除分区等特殊情况以外,特定分区同步副本(ISR)数量应保持相对稳定。 3. 离线分区数(仅控制器):OfflinePartitionsCount(可用性)kafka.controller:type=KafkaController,name=OfflinePartitionsCount 顾名思义,主要统计没有活跃 Leader 的分区数。Tips:由于所有读写操作仅在分区引导程序上执行,因此该指标出现非零值,就需要进行关注,防止服务中断。 4. 集群中活动控制器的数量:ActiveControllerCount(可用性)kafka.server:type=ReplicaManager,name=IsrShrinksPerSec Tips:所有 brokers 中 ActiveControllerCount 总和始终等于 1,如出现波动应及时告警。Kafka 集群中启动的第一个节点将自动成为Controller且只有一个。Kafka 集群中的Controller负责维护分区 Leader 列表,并协调 Leader 变更(比如某分区 leader 不可用)。 5. 每秒 UncleanLeader 选举次数:UncleanLeaderElectionsPerSec(可用性)kafka.controller:type=ControllerStats,name=UncleanLeaderElectionsPerSec 在可用性和一致性之间,Kafka 默选了可用性。当 Kafka Brokers 的分区 Leader 不可用时,就会发生 unclean 的 leader 选举。当作为分区 Leader 的代理脱机时,将从该分区的 ISR 集中选举出新的 Leader。Tips:UncleanLeaderElectionsPerSec 代表着数据丢失,因此需要进行告警。 6. 特定请求(生产/提取)用时:TotalTimeMs(性能)kafka.network:type=RequestMetrics,name=TotalTimeMs,request={Produce|FetchConsumer|FetchFollower} TotalTimeMs 作为一个指标族,用来衡量服务请求(包括生产请求,获取消费者请求或获取跟随者请求)的用时,其中涵盖在请求队列中等待所花费的时间 Queue,处理所花费的时间 Local,等待消费者响应所花费的时间 Remote(仅当时requests.required.acks=-1)发送回复的时间 Response。 Tips:正常情况下 TotalTimeMs 应该近似静态且只有非常小的波动。如果发现异常,需要检查各个队列、本地、远程和响应值,定位导致速度下降的确切请求段。 7. 传入/传出字节率:BytesInPerSec / BytesOutPerSec(性能)kafka.server:type=ReplicaManager,name=IsrShrinksPerSec Tips:我们可以考虑是否启用消息的端到端压缩等优化措施。磁盘吞吐量、网络吞吐量都可能成为 Kafka 的性能瓶颈。比如跨数据中心发送消息且 Topic 数量众多,或副本恰好是 Leader。 8. 每秒请求数:RequestsPerSec(性能)kafka.network:type=RequestMetrics,name=RequestsPerSec,request={Produce|FetchConsumer|FetchFollower},version=([0-9]+) 通过 RequestsPerSec,了解 Producer、Consumer、Followers 的请求率,确保 Kafka 的高效通信。 Tips:请求率会随着 Producer发送更多流量或集群扩展而增加,从而增加需要提取消息的 Consumer 或 Followers。如果 RequestsPerSec 持续高企,需要考虑增加 Producer、Consumer、Followers。通过减少请求数量来提高吞吐量,减少非必要开销。
除了主机级别的相关指标,由于 Kafka 是由 Scala 编写且运行在 JVM 上,需要依赖 Java 的垃圾回收机制来释放内存,并随着集群活跃度提升,垃圾回收频率不断提升。 1. 消耗磁盘空间消耗与可用磁盘空间:Disk usage(可用性)由于 Kafka 将所有数据持久保存到磁盘,因此需要监视 Kafka 可用磁盘空间量。 2. 页面缓存读取与磁盘读取的比率:Page cache reads ratio(性能)类似于数据库 cache-hit ratio 缓存命中率,该指标越高读取速度越快,性能越好。如果副本追上了 Leader(如产生新代理),则该指标短暂下降。 3. CPU 使用率:CPU usage(性能)CPU 很少是性能问题根因。但如果发生 CPU 使用率暴涨,最好还是检查一下。 4. 网络字节发送/接收(性能)代理托管其他网络服务情况下。网络使用率过高可能是性能下降的先兆。 5. JVM 执行垃圾回收进程总数:CollectionCount(性能)java.lang:type=GarbageCollector,name=G1 (Young|Old) Generation YoungGarbageCollector 相对经常发生。在执行时所有应用线程都会暂停,因此该指标的波动会造成 Kafka 性能的波动。 6. JVM 执行垃圾收集进程用时:CollectionTime(性能)java.lang:type=GarbageCollector,name=G1 (Young|Old) Generation OldGarbageCollector 释放老堆栈中未使用的内存,虽然也会暂停应用线程,但只是间歇运行。如果该动作的耗时或者发生频次过高,需要考虑是否有相应的内存支撑。 Producer 指标 Producer 将消息推送到 Broker 进行消费。如果 Producer 失败,Consumer 将没有新消息。因此,我们需要监测以下指标,保障稳定的传入数据流。 1. 每秒收到的平均响应数: Response rate(性能)kafka.[producer|consumer|connect]:type=[consumer|producer|connect]-node-metrics,client-id=([-.\w]+),node-id=([0-9]+) 对于 Producer,响应率表示从 Brokers 收到的响应率。收到数据后,Brokers 对 Producer 做出响应。结合 request.required.acks 实际配置,“收到”具备不同含义,比如:Leader 已将消息写入磁盘,Leader 已从所有副本收到确认已将数据写入磁盘。在收到确认之前,Producer 数据不可用于消费。 2. 每秒发送的平均请求数: Request rate(性能)kafka.network:type=RequestMetrics,name=RequestsPerSec,request={Produce|FetchConsumer|FetchFollower},version=([0-9]+) 请求速率指 Producer 将数据发送给 Brokers 的速率。速率走势是保障服务可用性的重要指标。 3. 平均请求等待时长: Request latency average(性能)kafka.[producer|consumer|connect]:type=[consumer|producer|connect]-node-metrics,client-id=([-.\w]+),node-id=([0-9]+) 从调用 KafkaProducer.send()到 Producer 收到来自 Broker 的响应之间的时长。Producer 的 linger.ms 值确定在发送消息批之前将等待的最长时间,这允许它累积大量消息,再在单个请求中发送它们。如果增加 linger.ms 提高 Kafka 吞吐量,则应关注请求延迟,确保不会超过限制。 4. 每秒平均传出/传入字节数:Outgoing byte rate(性能)kafka.producer:type=producer-metrics,client-id=([-.w]+) 了解 Producer 效率,并定位可能的传输延迟原因。 5. I / O 线程等待的平均时长: I/O wait time(性能)kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) 6. 每个分区每个请求发送的平均字节数:Batch size(性能) kafka.producer:type=producer-metrics,client-id=([-.w]+) 为了提升网络资源使用率,Producer 尝试在发送消息前将消息分组。Producer 将等待累积由 batch.size 定义的数据量,等待时长受 linger.ms 约束。 Consumer 指标 1. Consumer 在此分区上滞后于 Producer 的消息数:Records lag/Records lag max(性能)kafka.consumer:type=consumer-fetch-manager-metrics,partition="{partition}",topic="{topic}",client-id="{client-id}" 该指标用来记录 Consumer 当前的日志偏移量和 Producer 的当前日志偏移量之间的计算差。如果 Consumer 是处理实时数据,则始终较高的滞后值可能表示使用者过载,在这种情况下,配置更多使用者和将 Topic 划分到更多分区中提高吞吐量并减少滞后。 2. 特定 Topic 每秒平均消耗的字节数: bytes consumed rate(性能)kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{client-id}",topic="{topic}" 3. 特定 Topic 每秒平均消耗的记录数: records consumed rate(性能)kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{client-id}",topic="{topic}" 4. Consumer 每秒获取的请求数: fetch rate(性能)kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{client-id}",topic="{topic}" 该指标可以直观反映 Consumer 的整体状况。接近零值的获取率表明 Consumer 存在问题。如果出现指标下降,则可能是 Consumer 消费消息失败。 相关指标可以参考 Kafka 官方文档,指标名称、指标定义、Mean name 在实际操作过程中以文档中最新版本为准。 搭建相关监控体系 通过自建 Prometheus 进行监控 这里不对开源 Prometheus 搭建流程进行阐述(虽然相对繁杂,但技术社区有保姆级教程,可自行百度)。这里只简单介绍相关的 Kafka Exporter,当前最新版本是 v1.4.2 ,发布于 2021.09.16 。最近一次更新是 3 个月前,关于 kafka_exporter.go 的。 但如果你跟我一样遇到了以下一个或多个场景:
初级水平,自己搞不定开源 Prometheus 部署;
比较懒,又不想日常维护 Prometheus 系统,包括相关组件更新、系统整体扩容;
业务上线非常着急,需要马上有相应的监控系统;
企业级用户 希望 Prometheus 服务低成本、数据库规模无上限、高性能高可用
那么,阿里云 Prometheus 监控服务是一个最佳选择,不用再考虑以上问题,真正做到开箱即用,一键集成。 通过阿里云 Prometheus 监控进行监控 登录 Prometheus 控制台。在页面左上角选择目标地域,然后根据需要单击容器服务、Kubernetes 或者 ECS 类型的 Prometheus 实例名称。在左侧导航栏单击组件监控。
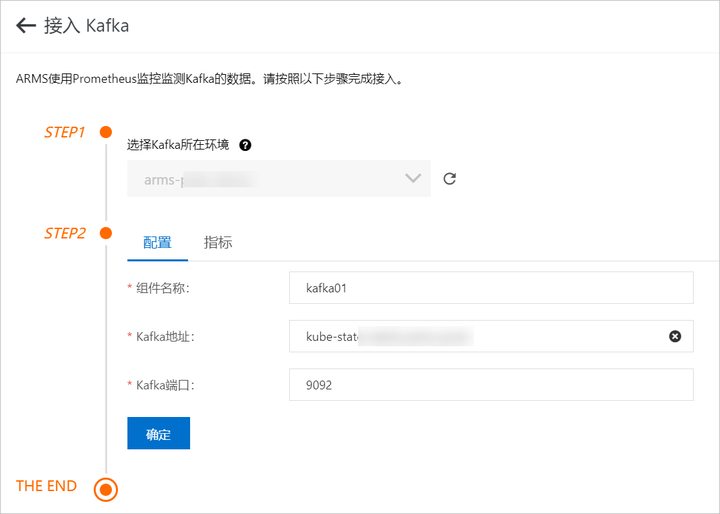
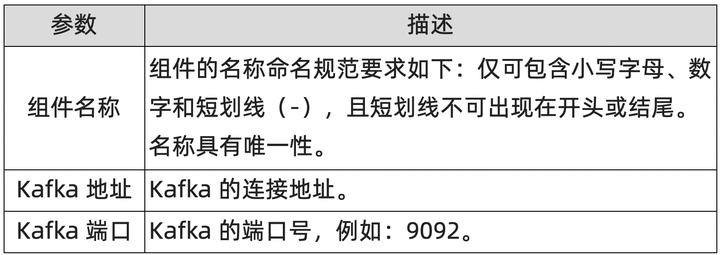
1. 在组件监控页面,单击右上角的添加组件监控。在接入中心面板中单击 Kafka 组件图标。在接入 Kafka 面板 STEP2 区域的配置页签输入各项参数,并单击确定。在接入 Kafka 面板 STEP2 区域的指标页签可查看监控指标。
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
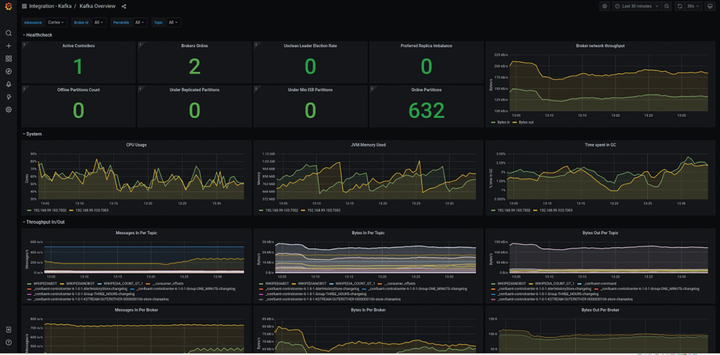
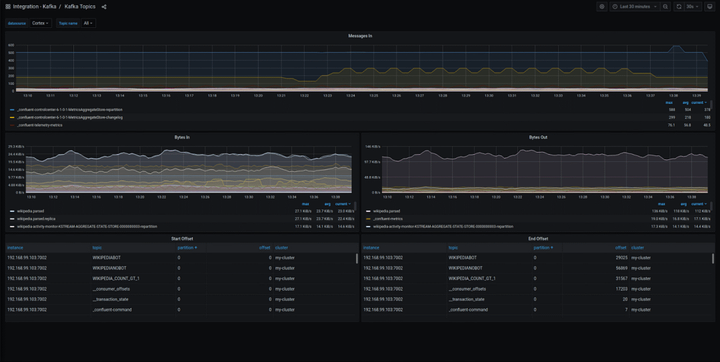
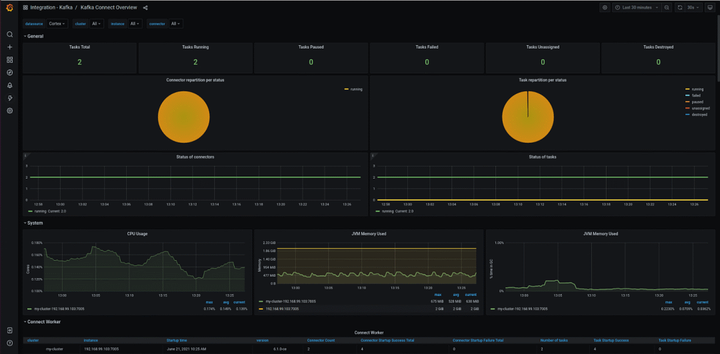
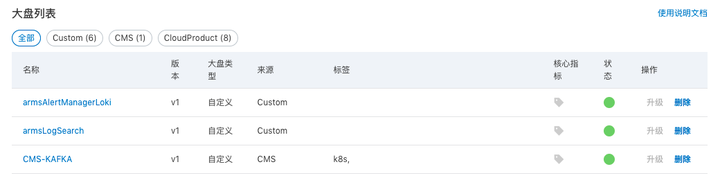
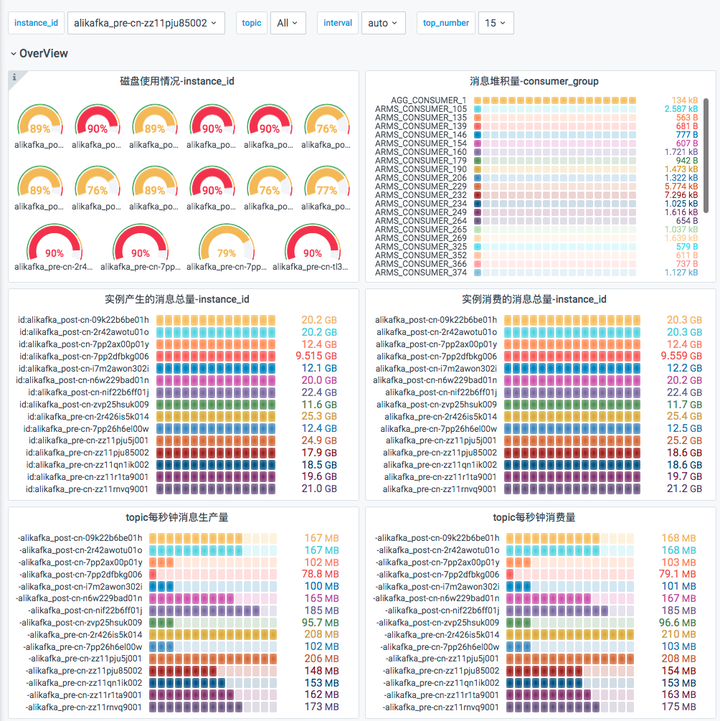
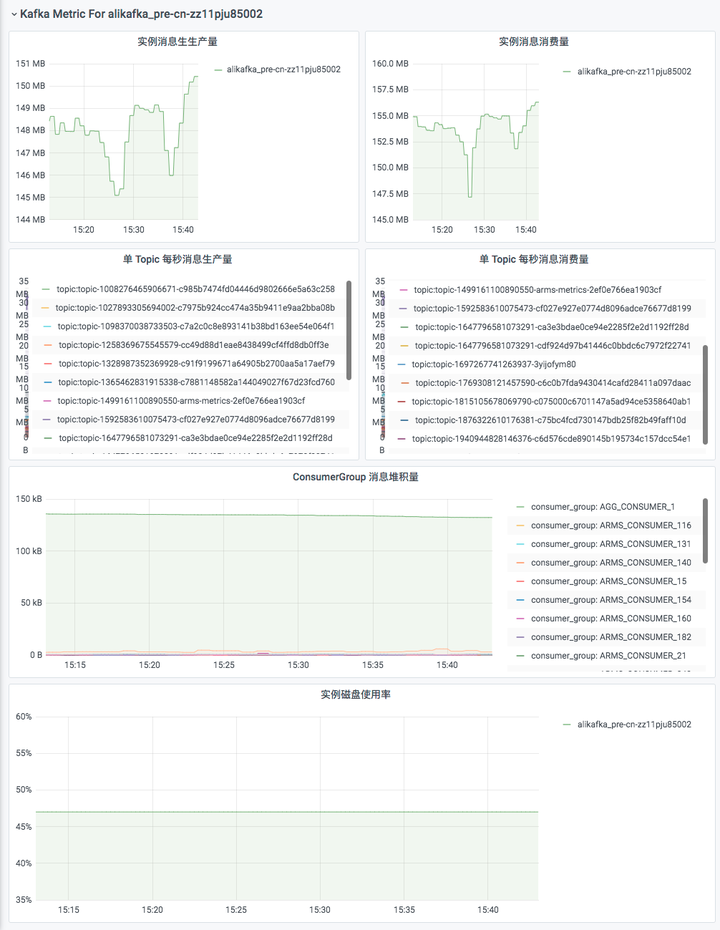
在组件监控页面,会显示已接入的组件实例。单击该组件实例大盘列的大盘,查看该组件监控指标数据。通过 Grafana 进行更全面的数据展示。

添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
如果是购买 Kafka 云产品,可以通过”Prometheus for 云服务“进行监控 登录 Prometheus 控制台。在页面左上角选择目标地域,然后选择新建 Prometheus 实例。在弹出页面单击 Prometheus 实例 for 云服务。
添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
在弹出页面选中添加 Alibaba Cloud Kafka,然后点击确定按钮开启 Kafka 云产品监控。
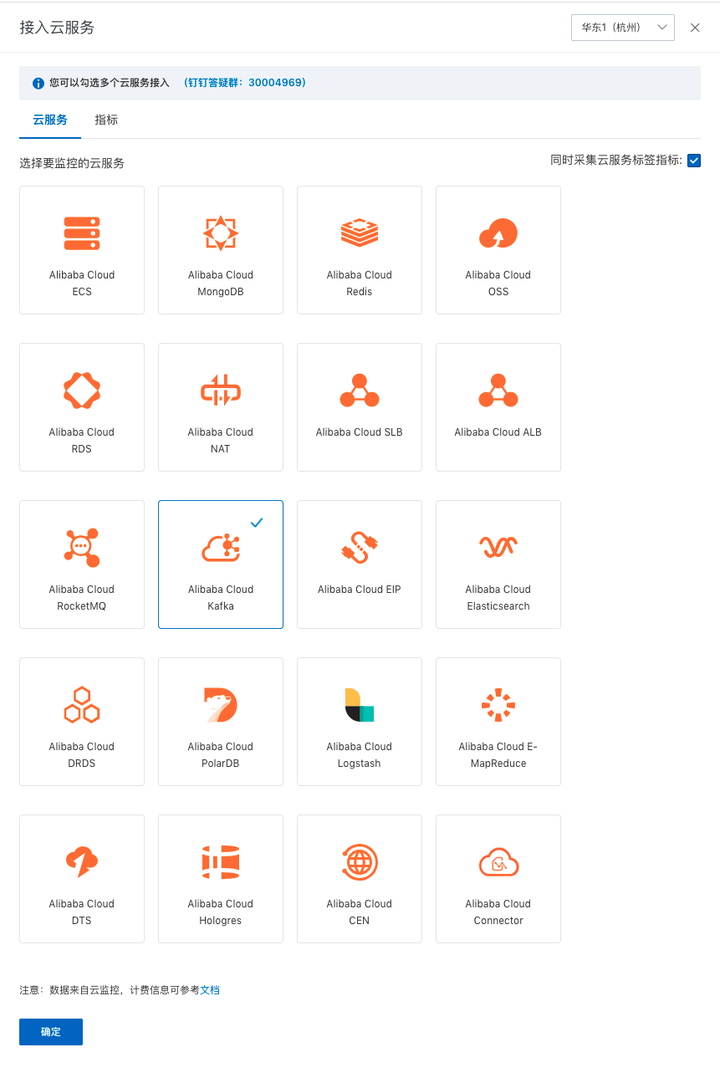
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
在 Prometheus 云监控详情大盘列表页面,会显示已接入的 Kafka。单击该组件实例大盘列的 CMS-KAFKA 大盘,查看该组件监控指标数据。通过 Grafana 进行更全面的数据展示。
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
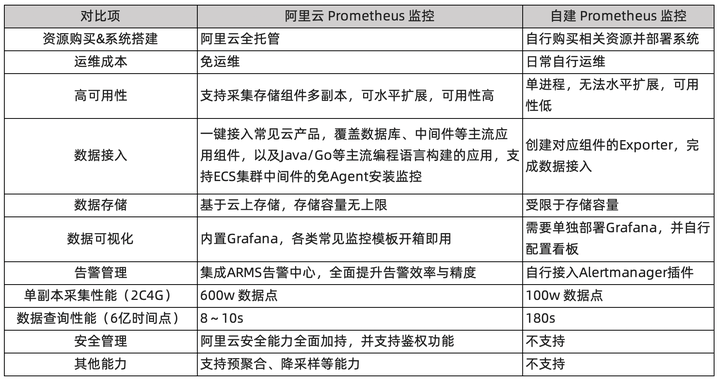
相较于开源 Prometheus,阿里云 Prometheus 监控具备以下特性
添加图片注释,不超过 140 字(可选)
- 大规模使用 Apache Kafka 的20个最佳实践
必读 | 大规模使用 Apache Kafka 的20个最佳实践 配图来源:书籍<深入理解Kafka> Apache Kafka是一款流行的分布式数据流平台,它已经广泛地被诸如New Re ...
- Kafka在大型应用中的 20 项最佳实践
原标题:Kafka如何做到1秒处理1500万条消息? Apache Kafka 是一款流行的分布式数据流平台,它已经广泛地被诸如 New Relic(数据智能平台).Uber.Square(移动支付公 ...
- 如何创建Kafka客户端:Avro Producer和Consumer Client
1.目标 - Kafka客户端 在本文的Kafka客户端中,我们将学习如何使用Kafka API 创建Apache Kafka客户端.有几种方法可以创建Kafka客户端,例如最多一次,至少一次,以及一 ...
- Kubernetes集群的监控报警策略最佳实践
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/M2l0ZgSsVc7r69eFdTj/article/details/79652064 本文为Kub ...
- 京东前端:PhantomJS 和NodeJS在网站前端监控平台的最佳实践
1. 为什么需要一个前端监控系统 通常在一个大型的 Web 项目中有很多监控系统,比如后端的服务 API 监控,接口存活.调用.延迟等监控,这些一般都用来监控后台接口数据层面的信息.而且对于大型网站系 ...
- Docker监控:最佳实践以及cAdvisor和Prometheus监控工具的对比
在DockerCon EU 2015上,Brian Christner阐述了“Docker监控”的概况,分享了这方面的最佳实践和Docker stats API的指南,并对比了三个流行的监控方案:cA ...
- Sentry 后端监控 - 最佳实践(官方教程)
系列 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Maps Sentry For ...
- Ubuntu14.04+RabbitMQ3.6.3+Golang的最佳实践
目录 [TOC] 1.RabbitMQ介绍 1.1.什么是RabbitMQ? RabbitMQ 是由 LShift 提供的一个 Advanced Message Queuing Protocol ...
- 【译】Kafka最佳实践 / Kafka Best Practices
本文来自于DataWorks Summit/Hadoop Summit上的<Apache Kafka最佳实践>分享,里面给出了很多关于Kafka的使用心得,非常值得一看,今推荐给大家. 硬 ...
- 基于消息队列 RocketMQ 的大型分布式应用上云最佳实践
作者|绍舒 审核&校对:岁月.佳佳 编辑&排版:雯燕 前言 消息队列是分布式互联网架构的重要基础设施,在以下场景都有着重要的应用: 应用解耦 削峰填谷 异步通知 分布式事务 大数据处理 ...
随机推荐
- SPEAK 510全向麦克风无线蓝牙拾音器产品体验及评测
产品简介 大家开会的时候,很多人都直接使用手机app了,比如,zoom,腾讯会议等.既方便又快捷.由于手机设备拾音距离有限,也不是针对会议场景做的,所有,在多人会议的时候,问题就出来了.这个时 ...
- Activity系列博客5篇
目录介绍 01.前沿介绍 02.handleLaunchActivity 03.performLaunchActivity 04.activity.attach 05.Activity的onCreat ...
- DevOps迈向标准化,平台工程让开发运维更轻松
在近一代人的时间里,DevOps 在软件开发和运维领域占据了主导地位.这是一套开发人员都离不开的技能和方法.Pearl Zhu 在 "The Digital Master" 一书中 ...
- KingbaseES V8R6备份恢复案例之---sys_restore实现schema转换
**案例说明:** sys_restore用于sys_dump备份的数据恢复,在实际的应用中有需求,将从sys_dump备份对象从原schema中转换到到另外的schema,sys_restore支持 ...
- KingbaseES V8R6数据库运维案例之---索引坏块故障处理
案例说明: 在执行表数据查询时,出现下图所示错误,索引故障导致表无法访问,后重建索引问题解决.本案例复现了此类故障解决过程. 适用版本: KingbaseES V8R3/R6 一.创建测试环境 # 表 ...
- KingbaseES V8R3集群运维案例之---failover故障处理
案例说明: 此案例,为KingbaseES V8R3集群failover切换时,通用的故障处理方式.通过对failover.log和recovery.log日志的解读,让大家了解KingbaseE ...
- Boruvka 简介
Boruvka 是一种最小生成树算法,用于求解稠密图的 MST. [典题]CF Xor-MST: 发现边数是 $n^2$ 级别的,直接把 Kruskal 和 Prim ban 了,所以考虑使用 Bor ...
- 开启 Keep-Alive 可能会导致http 请求偶发失败
大家好,我是蓝胖子,说起提高http的传输效率,很多人会开启http的Keep-Alive选项,这会http请求能够复用tcp连接,节省了握手的开销.但开启Keep-Alive真的没有问题吗?我们来细 ...
- 11 JavaScript关于时间
11 JavaScript关于时间 获取js的时间使用内置的Date函数完成 var d = new Date(); // 获取系统时间 // var d = new Date('2023-08-15 ...
- #计数#A 古老谜题
From NOIP2020 模拟赛 B 组 Day4 题目 给定一个长度为\(n\)的01序列\(a\), 问有多少个三元组\((l,p,r),1\leq l<p<r\leq n\) 满足 ...