PHP处理海量样本相似度聚类算法
catalogue
. TF-IDF
. 基于空间向量的余弦算法
. 最长公共子序列
. 最小编辑距离算法
. similar_text
. local sensitive hash 局部非敏感哈希
. SSDEEP Hash
. K-means聚类算法
. 二分K-means算法
1. TF-IDF
Relevant Link:
http://qianxunniao.iteye.com/blog/1831780
2. 基于空间向量的余弦算法
将分词后的词频作为向量分量,将每个文件转化为一个向量,通过计算向量之间的余弦值,本质上是在计算不同文本的词频的相似度
3. 最长公共子序列
该算法的最大缺陷是计算CPU消耗较大
. 将两个字符串分别以行和列组成矩阵
. 计算每个节点行列字符是否相同,如相同则为1。
. 通过找出值为1的最长对角线即可得到最长公共子串
为进一步提升该算法,我们可以将字符相同节点的值加上左上角(d[i-1,j-1])的值,这样即可获得最大公共子串的长度。如此一来只需以行号和最大值为条件即可截取最大子串
Relevant Link:
https://segmentfault.com/q/1010000000738974
http://www.speedphp.com/thread-4840-1-1.html
http://www.cnblogs.com/liangxiaxu/archive/2012/05/05/2484972.html
4. 最小编辑距离算法
设A、B为两个字符串,狭义的编辑距离定义为把A转换成B需要的最少删除(删除A中一个字符)、插入(在A中插入一个字符)和替换(把A中的某个字符替换成另一个字符)的次数,用ED(A,B)来表示。直观来说,两个串互相转换需要经过的步骤越多,差异越大
. 对两部分文本进行处理,将所有的非文本字符替换为分段标记"#"
. 较长文本作为基准文本,遍历分段之后的短文本,发现长文本包含短文本子句后在长本文中移除,未发现匹配的字句累加长度
. 比较剩余文本长度与两段文本长度和,其比值为不匹配比率
PHP中的levenshtein()函数已经实现了该功能
Relevant Link:
http://php.net/manual/zh/function.levenshtein.php
5. similar_text
Relevant Link:
http://php.net/manual/zh/function.metaphone.php
http://php.net/manual/zh/function.soundex.php
http://php.net/manual/zh/function.similar-text.php
6. local sensitive hash 局部非敏感哈希
在对海量样本进行大规模相似度聚类运算的时候,需要首要考虑的问题是计算耗时。为此我们需要一种应对于海量数据场景的去重方案,可以采取一种叫做 local sensitive hash 局部敏感哈希 的算法,该算法模型可以把文档降维到hash数字,数字两两计算运算量要小很多(google对于网页去重使用的是simhash,他们每天需要处理的文档在亿级别)。simhash是由 Charikar 在2002年提出来的,参考 《Similarity estimation techniques from rounding algorithms》
0x1: 基本概念
. 分词
把需要判断文本分词形成这个文章的特征单词。最后形成去掉噪音词的单词序列并为每个词加上权重,我们假设权重分为5个级别( ~ )。比如
"美国51区雇员称内部有9架飞碟,曾看见灰色外星人" ==> 分词后为
"美国(4) 51区(5) 雇员(3) 称(1) 内部(2) 有(1) 9架(3) 飞碟(5) 曾(1) 看见(3) 灰色(4) 外星人(5)": 括号里是代表单词在整个句子里重要程度,数字越大越重要 . hash
通过hash算法把每个词变成hash值,比如
"美国"通过hash算法计算为
"51区"通过hash算法计算为
这样我们的字符串就变成了一串串数字,下一步我们要把文章变为数字计算才能提高相似度计算性能,现在是降维过程进行时 . 加权
通过2步骤的hash生成结果,需要按照单词的权重形成加权数字串,比如
"美国"的hash值为"",通过加权计算为"4 -4 -4 4 -4 4"
"51区"的hash值为"",通过加权计算为"5 -5 5 -5 5 5" . 合并
把上面各个单词算出来的序列值累加,变成只有一个序列串。比如
"美国"的"4 -4 -4 4 -4 4"
"51区"的"5 -5 5 -5 5 5"
把每一位进行累加,"4+5 -4+-5 -4+5 4+-5 -4+5 4+5" ==》 "9 -9 1 -1 1 9"(这里作为示例只算了两个单词的,真实计算需要把所有单词的序列串累加) . 降维
把4步算出来的"9 -9 1 -1 1 9"变成 串,形成我们最终的simhash签名。 如果每一位大于0 记为 ,小于0 记为 。最后算出结果为: "1 0 1 0 1 1"
整个过程图为

Relevant Link:
http://blog.jobbole.com/46839/
http://jacoxu.com/?p=366
https://github.com/yanyiwu/simhash
https://github.com/leonsim/simhash
https://github.com/zhujun1980/simhash
https://github.com/Sin30/simhash-demo/blob/master/simhash.php
https://github.com/tgalopin/SimHashPhp
http://www.cs.princeton.edu/courses/archive/spr04/cos598B/bib/CharikarEstim.pdf
7. SSDEEP Hash
SSDEEP Hash的思想和MD5/SHAX正好相反,是一种局部不敏感Hash算法,通过对待检测文本的分段切割,综合加权得到一个降维的模糊化Hash。能够对小范围的修改有较好的容错性
0x1: 改善SSDEEP Hash效果
、 对不满32byte的文本,填充Padding到32bytes
Relevant Link:
8. K-means聚类算法
. 使用K-means(K近邻)算法对文本进行分类,首先要面对的问题是,如何将文本转化为可度量距离的"点特征集合",一个可行的方法是将文本提取为一个词频向量(高维空间的坐标点),这样就将文本转化为一个点
. 二维坐标点的X, Y 坐标,其实是一种向量,是一种数学抽象。现实世界中很多属性是可以抽象成向量的,比如,我们的年龄,我们的喜好,我们的商品,等等,能抽象成向量的目的就是可以让计算机知道某两个属性间的距离。如:我们认为,18岁的人离24岁的人的距离要比离12岁的距离要近,鞋子这个商品离衣服这个商品的距离要比电脑要近,等等
. 只要能把现实世界的物体的属性抽象成向量,就可以用K-Means算法来归类了
. 所以使用k-means进行样本分类的难点在于如何提取feature,构成一个多维的坐标点空间,并带入模型运算
聚类属于无监督学习,以往的回归、朴素贝叶斯、SVM等都是有类别标签y的,也就是说样例中已经给出了样例的分类。而聚类的样本中却没有给定y,只有特征x,比如假设宇宙中的星星可以表示成三维空间中的点集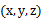 。聚类的目的是找到每个样本x潜在的类别y,并将同类别y的样本x放在一起。比如上面的星星,聚类后结果是一个个星团,星团里面的点相互距离比较近,星团间的星星距离就比较远了。
。聚类的目的是找到每个样本x潜在的类别y,并将同类别y的样本x放在一起。比如上面的星星,聚类后结果是一个个星团,星团里面的点相互距离比较近,星团间的星星距离就比较远了。
在聚类问题中,给我们的训练样本是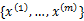 ,每个
,每个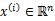 ,没有了y。
,没有了y。
K-means算法是将样本聚类成k个簇(cluster),具体算法描述如下
1、 随机选取k个聚类质心点(cluster centroids)为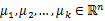 。
。
2、 重复下面过程直到收敛 {
对于每一个样例i,计算其应该属于的类
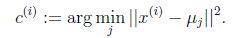
对于每一个类j,重新计算该类的质心
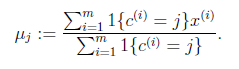
}
K是我们事先给定的聚类数, 代表样例i与k个类中距离最近的那个类,
代表样例i与k个类中距离最近的那个类, 的值是1到k中的一个。质心
的值是1到k中的一个。质心 代表我们对属于同一个类的样本中心点的猜测,拿星团模型来解释就是要将所有的星星聚成k个星团,首先随机选取k个宇宙中的点(或者k个星星)作为k个星团的质心,然后第一步对于每一个星星计算其到k个质心中每一个的距离,然后选取距离最近的那个星团作为
代表我们对属于同一个类的样本中心点的猜测,拿星团模型来解释就是要将所有的星星聚成k个星团,首先随机选取k个宇宙中的点(或者k个星星)作为k个星团的质心,然后第一步对于每一个星星计算其到k个质心中每一个的距离,然后选取距离最近的那个星团作为 ,这样经过第一步每一个星星都有了所属的星团;第二步对于每一个星团,重新计算它的质心
,这样经过第一步每一个星星都有了所属的星团;第二步对于每一个星团,重新计算它的质心 (对里面所有的星星坐标求平均)。重复迭代(逐个遍历所有点假设为质心)第一步和第二步直到质心不变或者变化很小(得到最优解)
(对里面所有的星星坐标求平均)。重复迭代(逐个遍历所有点假设为质心)第一步和第二步直到质心不变或者变化很小(得到最优解)
下图展示了对n个样本点进行K-means聚类的效果,这里k取2(二分)

K-means面对的第一个问题是如何保证收敛,最优解求解算法中强调结束条件就是收敛,可以证明的是K-means完全可以保证收敛性。下面我们定性的描述一下收敛性,我们定义畸变函数(distortion function)如下:

J函数表示每个样本点到其质心的距离平方和。K-means是要将J调整到最小。假设当前J没有达到最小值,那么首先可以固定每个类的质心 ,调整每个样例的所属的类别
,调整每个样例的所属的类别 来让J函数减少,同样,固定
来让J函数减少,同样,固定 ,调整每个类的质心
,调整每个类的质心 也可以使J减小。这两个过程就是内循环中使J单调递减的过程。当J递减到最小时,
也可以使J减小。这两个过程就是内循环中使J单调递减的过程。当J递减到最小时, 和c也同时收敛。(在理论上,可以有多组不同的
和c也同时收敛。(在理论上,可以有多组不同的 和c值能够使得J取得最小值,但这种现象实际上很少见)
和c值能够使得J取得最小值,但这种现象实际上很少见)
由于畸变函数J是非凸函数,意味着我们不能保证取得的最小值是全局最小值,也就是说k-means对质心初始位置的选取比较感冒,但一般情况下k-means达到的局部最优已经满足需求。但如果你怕陷入局部最优,那么可以选取不同的初始值跑多遍k-means,然后取其中最小的J对应的 和c输出。
和c输出。
Relevant Link:
http://coolshell.cn/articles/7779.html
http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006910.html
9. 二分K-means算法
K-means算法本身存在几个缺陷
. 可能收敛到局部最小值
. 在大规模数据集上收敛较慢
当陷入局部最小值的时候,处理方法就是多运行几次K-means算法,然后选择畸变函数J较小的作为最佳聚类结果。这样的效率显然太低,我们希望能得到一次就能给出接近最优的聚类结果
其实K-means的缺点的根本原因就是:对K个质心的初始选取比较敏感。质心选取得不好很有可能就会陷入局部最小值
基于以上情况,有人提出了二分K-means算法来解决这种情况,也就是弱化初始质心的选取对最终聚类效果的影响
Relevant Link:
http://blog.jobbole.com/86914/
Copyright (c) 2015 LittleHann All rights reserved
PHP处理海量样本相似度聚类算法的更多相关文章
- K-means聚类算法的三种改进(K-means++,ISODATA,Kernel K-means)介绍与对比
一.概述 在本篇文章中将对四种聚类算法(K-means,K-means++,ISODATA和Kernel K-means)进行详细介绍,并利用数据集来真实地反映这四种算法之间的区别. 首先需要明确 ...
- K-Means聚类算法原理
K-Means算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛.K-Means算法有大量的变体,本文就从最传统的K-Means算法讲起,在其基础上讲述K-Means的优化变体 ...
- FCM聚类算法介绍
FCM算法是一种基于划分的聚类算法,它的思想就是使得被划分到同一簇的对象之间相似度最大,而不同簇之间的相似度最小.模糊C均值算法是普通C均值算法的改进,普通C均值算法对于数据的划分是硬性的,而FCM则 ...
- 聚类算法:K-means
2013-12-13 20:00:58 Yanjun K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.该算法认为簇是由距离 ...
- 【转】常用聚类算法(一) DBSCAN算法
原文链接:http://www.cnblogs.com/chaosimple/p/3164775.html#undefined 1.DBSCAN简介 DBSCAN(Density-Based Spat ...
- 聚类算法kmeans
1. 聚类问题 所谓聚类问题,就是给定一个元素集合D,其中每个元素具有n个可观察属性,使用某种算法将D划分成k个子集,要求每个子集内部的元素之间相异度尽可能低,而不同子集的元素相异度尽可能高. 2. ...
- 常用聚类算法(一) DBSCAN算法
1.DBSCAN简介 DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度 ...
- Kmeans聚类算法原理与实现
Kmeans聚类算法 1 Kmeans聚类算法的基本原理 K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一.K-means算法的基本思想是:以空间中k个点为中心进行聚类,对 ...
- 转载: scikit-learn学习之K-means聚类算法与 Mini Batch K-Means算法
版权声明:<—— 本文为作者呕心沥血打造,若要转载,请注明出处@http://blog.csdn.net/gamer_gyt <—— 目录(?)[+] ================== ...
随机推荐
- RunLoop-Custom input source
Creating Creating a custom input source involves defining the following: The information you want yo ...
- yii2批量添加的问题
作者:白狼 出处:http://www.manks.top/yii2_batch_insert.html 本文版权归作者,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否 ...
- Oracle shutdown immediate无法关闭数据库解决方法
在测试服务器上使用shutdown immediate命令关闭数据库时,长时间无法关闭数据库,如下所示 1: [oracle@DB-Server admin]$ sqlplus / as sysdba ...
- WordPress建站和搭独立博客
之前有帮外面的公司建站的经历 不去管html css js 服务器脚本等 对于菜鸟新手而言, 一个WAMP + WordPress(博客程序)就够了 都弄好了再部署到云端服务器上 其实整个过程只是安装 ...
- phpAdmin安装
phpAdmin是和Navicat重复的功能 负责管理MySql数据库 不过他是使用浏览器进行管理MySql数据库 PHP环境搭建的完整步骤 http://www.cnblogs.com/azhe-s ...
- Android欢迎界面
欢迎界面,最典型的表现: 1.是整个应用的启动界面: 2.没有标题栏: 3.几秒之后才进入主界面. 所以实现上面3点,一个最基本的欢迎界面就做出来了. 首先,新建一个Activity,命名为Splas ...
- asp.net设置默认打开页面,Web.config,defaultDocument
The web.config file can be used to set a default document, or list of default documents for your web ...
- ios合并静态库
lipo -create SQY/iOS/iphoneos/libGamePlusAPI.a SQY/iOS/iphonesimulator/libGamePlusAPI.a -output SQY/ ...
- Machine Learning Algorithms Study Notes(6)—遗忘的数学知识
机器学习中遗忘的数学知识 最大似然估计( Maximum likelihood ) 最大似然估计,也称为最大概似估计,是一种统计方法,它用来求一个样本集的相关概率密度函数的参数.这个方法最早是遗传学家 ...
- 更新chrom遇到flash过期解决办法
更新chrom遇到flash过期解决办法 百度最新adobe flash player ppapi最新版 下载并安装,重启浏览器即可