spark(1.1) mllib 源代码分析
在spark mllib 1.1加入版本stat包,其中包括一些统计数据有关的功能。本文分析中卡方检验和实施的主要原则:
一个、根本
在stat包实现Pierxunka方检验,它包括以下类别
(1)适配度检验(Goodness of Fit test):验证一组观察值的次数分配是否异于理论上的分配。
(2)独立性检验(independence test) :验证从两个变量抽出的配对观察值组是否互相独立(比如:每次都从A国和B国各抽一个人,看他们的反应是否与国籍无关)
计算公式:
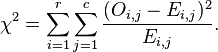
当中O表示观測值,E表示期望值
具体原理能够參考:http://zh.wikipedia.org/wiki/%E7%9A%AE%E7%88%BE%E6%A3%AE%E5%8D%A1%E6%96%B9%E6%AA%A2%E5%AE%9A
二、java api调用example
三、源代码分析
1、外部api
通过Statistics类提供了4个外部接口

// Goodness of Fit test
def chiSqTest(observed: Vector, expected: Vector): ChiSqTestResult = {
ChiSqTest.chiSquared(observed, expected)
}
//Goodness of Fit test
def chiSqTest(observed: Vector): ChiSqTestResult = ChiSqTest.chiSquared(observed) //independence test
def chiSqTest(observed: Matrix): ChiSqTestResult = ChiSqTest.chiSquaredMatrix(observed)
//independence test
def chiSqTest(data: RDD[LabeledPoint]): Array[ChiSqTestResult] = {
ChiSqTest.chiSquaredFeatures(data)
}
2、Goodness of Fit test实现
这个比較简单。关键是依据(observed-expected)2/expected计算卡方值
/*
* Pearon's goodness of fit test on the input observed and expected counts/relative frequencies.
* Uniform distribution is assumed when `expected` is not passed in.
*/
def chiSquared(observed: Vector,
expected: Vector = Vectors.dense(Array[Double]()),
methodName: String = PEARSON.name): ChiSqTestResult = { // Validate input arguments
val method = methodFromString(methodName)
if (expected.size != 0 && observed.size != expected.size) {
throw new IllegalArgumentException("observed and expected must be of the same size.")
}
val size = observed.size
if (size > 1000) {
logWarning("Chi-squared approximation may not be accurate due to low expected frequencies "
+ s" as a result of a large number of categories: $size.")
}
val obsArr = observed.toArray
// 假设expected值没有设置,默认取1.0 / size
val expArr = if (expected.size == 0) Array.tabulate(size)(_ => 1.0 / size) else expected.toArray / 假设expected、observed值都必需要大于1
if (!obsArr.forall(_ >= 0.0)) {
throw new IllegalArgumentException("Negative entries disallowed in the observed vector.")
}
if (expected.size != 0 && ! expArr.forall(_ >= 0.0)) {
throw new IllegalArgumentException("Negative entries disallowed in the expected vector.")
} // Determine the scaling factor for expected
val obsSum = obsArr.sum
val expSum = if (expected.size == 0.0) 1.0 else expArr.sum
val scale = if (math.abs(obsSum - expSum) < 1e-7) 1.0 else obsSum / expSum // compute chi-squared statistic
val statistic = obsArr.zip(expArr).foldLeft(0.0) { case (stat, (obs, exp)) =>
if (exp == 0.0) {
if (obs == 0.0) {
throw new IllegalArgumentException("Chi-squared statistic undefined for input vectors due"
+ " to 0.0 values in both observed and expected.")
} else {
return new ChiSqTestResult(0.0, size - 1, Double.PositiveInfinity, PEARSON.name,
NullHypothesis.goodnessOfFit.toString)
}
}
// 计算(observed-expected)2/expected
if (scale == 1.0) {
stat + method.chiSqFunc(obs, exp)
} else {
stat + method.chiSqFunc(obs, exp * scale)
}
}
val df = size - 1
val pValue = chiSquareComplemented(df, statistic)
new ChiSqTestResult(pValue, df, statistic, PEARSON.name, NullHypothesis.goodnessOfFit.toString)
}
3、independence test实现
先通过以下的公式计算expected值,矩阵共同拥有 r 行 c 列
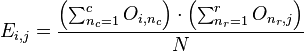
然后依据(observed-expected)2/expected计算卡方值
/*
* Pearon's independence test on the input contingency matrix.
* TODO: optimize for SparseMatrix when it becomes supported.
*/
def chiSquaredMatrix(counts: Matrix, methodName:String = PEARSON.name): ChiSqTestResult = {
val method = methodFromString(methodName)
val numRows = counts.numRows
val numCols = counts.numCols // get row and column sums
val colSums = new Array[Double](numCols)
val rowSums = new Array[Double](numRows)
val colMajorArr = counts.toArray
var i = 0
while (i < colMajorArr.size) {
val elem = colMajorArr(i)
if (elem < 0.0) {
throw new IllegalArgumentException("Contingency table cannot contain negative entries.")
}
colSums(i / numRows) += elem
rowSums(i % numRows) += elem
i += 1
}
val total = colSums.sum // second pass to collect statistic
var statistic = 0.0
var j = 0
while (j < colMajorArr.size) {
val col = j / numRows
val colSum = colSums(col)
if (colSum == 0.0) {
throw new IllegalArgumentException("Chi-squared statistic undefined for input matrix due to"
+ s"0 sum in column [$col].")
}
val row = j % numRows
val rowSum = rowSums(row)
if (rowSum == 0.0) {
throw new IllegalArgumentException("Chi-squared statistic undefined for input matrix due to"
+ s"0 sum in row [$row].")
}
val expected = colSum * rowSum / total
statistic += method.chiSqFunc(colMajorArr(j), expected)
j += 1
}
val df = (numCols - 1) * (numRows - 1)
val pValue = chiSquareComplemented(df, statistic)
new ChiSqTestResult(pValue, df, statistic, methodName, NullHypothesis.independence.toString)
}
版权声明:本文博客原创文章,博客,未经同意,不得转载。
spark(1.1) mllib 源代码分析的更多相关文章
- Spark机器学习之MLlib整理分析
友情提示: 本文档根据林大贵的<Python+Spark 2.0 + Hadoop机器学习与大数据实战>整理得到,代码均为书中提供的源码(python 2.X版本). 本文的可以利用pan ...
- Spark里边:Worker源代码分析和架构
首先由Spark图表理解Worker于Spark中的作用和地位: watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvYW56aHNvZnQ=/font/5a6L ...
- Spark SQL 源代码分析系列
从决定写Spark SQL文章的源代码分析,到现在一个月的时间,一个又一个几乎相同的结束很快,在这里也做了一个综合指数,方便阅读,下面是读取顺序 :) 第一章 Spark SQL源代码分析之核心流程 ...
- Spark MLlib之线性回归源代码分析
1.理论基础 线性回归(Linear Regression)问题属于监督学习(Supervised Learning)范畴,又称分类(Classification)或归纳学习(Inductive Le ...
- Spark MLlib LDA 基于GraphX实现原理及源代码分析
LDA背景 LDA(隐含狄利克雷分布)是一个主题聚类模型,是当前主题聚类领域最火.最有力的模型之中的一个,它能通过多轮迭代把特征向量集合按主题分类.眼下,广泛运用在文本主题聚类中. LDA的开源实现有 ...
- Spark SQL 源代码分析之 In-Memory Columnar Storage 之 in-memory query
/** Spark SQL源代码分析系列文章*/ 前面讲到了Spark SQL In-Memory Columnar Storage的存储结构是基于列存储的. 那么基于以上存储结构,我们查询cache ...
- Spark SQL Catalyst源代码分析之TreeNode Library
/** Spark SQL源代码分析系列文章*/ 前几篇文章介绍了Spark SQL的Catalyst的核心执行流程.SqlParser,和Analyzer,本来打算直接写Optimizer的,可是发 ...
- Spark SQL Catalyst源代码分析Optimizer
/** Spark SQL源代码分析系列*/ 前几篇文章介绍了Spark SQL的Catalyst的核心运行流程.SqlParser,和Analyzer 以及核心类库TreeNode,本文将具体解说S ...
- Spark SQL源代码分析之核心流程
/** Spark SQL源代码分析系列文章*/ 自从去年Spark Submit 2013 Michael Armbrust分享了他的Catalyst,到至今1年多了,Spark SQL的贡献者从几 ...
随机推荐
- zTree市县实现三个梯级数据库映射
zTree市县实现三个梯级数据库映射 Province.hbm.xml: <?xml version="1.0" encoding="UTF-8"? &g ...
- (转)Maven最佳实践:划分模块
“分天下为三十六郡,郡置守,尉,监” —— <史记·秦始皇本纪> 所有用Maven管理的真实的项目都应该是分模块的,每个模块都对应着一个pom.xml.它们之间通过继承和聚合(也称作多模块 ...
- 开源NetWorkSocket通讯组件
开源NetWorkSocket通讯组件 前言 在<化茧成蝶,开源NetWorkSocket通讯组件>发表之后,收到大家很多个star,在此感谢!更可贵的是,一些网友提出了许多好建议,经 ...
- UVA 11992 - Fast Matrix Operations(段树)
UVA 11992 - Fast Matrix Operations 题目链接 题意:给定一个矩阵,3种操作,在一个矩阵中加入值a,设置值a.查询和 思路:因为最多20列,所以全然能够当作20个线段树 ...
- shell脚本—根据文件个数定时备份
最近在了解Jenkins时,出现这样一个问题:linux ext3系统目录下的子目录个数不能超过31998个(参考:http://www.xshell.net/linux/1267.html),但je ...
- Android学习路径(十)怎么会Action Bar堆放在布局
默认情况下.action bar出如今activity窗体的顶部.稍微降低了activity布局的总空间. 假设你想隐藏或者显示action bar.在这堂用户体验的课程中,你能够通过调用hide() ...
- 软体project(两)——软体project
每本书的第一章,都是在讲宏观的东西.软工也不例外.接下来.我们就要介绍软件project"是什么"的问题. 一.是什么? watermark/2/text/aHR0cDov ...
- 【转】Android内存机制分析1——了解Android堆和栈
昨天用Gallery做了一个图片浏览选择开机画面的功能,当我加载的图片多了就出现OOM问题.以前也出现过这个问题,那时候并没有深究.这次打算好好分析一下Android的内存机制. 因为我以前是做VC+ ...
- 如何获得SQL Server索引使用情况
原文:如何获得SQL Server索引使用情况 原文出自: http://www.mssqltips.com/sqlservertip/1239/how-to-get-index-usage-info ...
- Different ways of associating known types in wcf
解释一下这个博客Known Types此属性标签,假设翻译的单词,所谓已知类型它.在服务契约中实现多态的行为.有四种方式实现,以下来分别演示一下. 1.User KnownType attribute ...