spark RDD编程,scala版本
1.RDD介绍:
val input=sc.textFile(inputFileDir)
val lines =sc.parallelize(List("hello world","this is a test"));
val lines =sc.parallelize(List("error:a","error:b","error:c","test"));
val errors=lines.filter(line => line.contains("error"));
errors.collect().foreach(println);
val lines =sc.parallelize(List("error:a","error:b","error:c","test","warnings:a"));
val errors=lines.filter(line => line.contains("error"));
val warnings =lines.filter(line => line.contains("warnings"));
val unionLines =errors.union(warnings);
unionLines.collect().foreach(println);
/**
* Take the first num elements of the RDD. This currently scans the partitions *one by one*, so
* it will be slow if a lot of partitions are required. In that case, use collect() to get the
* whole RDD instead.
*/
def take(num: Int): JList[T]
程序示例:接上
unionLines.take(2).foreach(println);
val all =unionLines.collect();
all.foreach(println);
class searchFunctions (val query:String){
def isMatch(s: String): Boolean = {
s.contains(query)
}
def getMatchFunctionReference(rdd: RDD[String]) :RDD[String]={
//问题: isMach表示 this.isMatch ,因此我们需要传递整个this
rdd.filter(isMatch)
}
def getMatchesFunctionReference(rdd: RDD[String]) :RDD[String] ={
//问题: query表示 this.query ,因此我们需要传递整个this
rdd.flatMap(line => line.split(query))
}
def getMatchesNoReference(rdd:RDD[String]):RDD[String] ={
//安全,只把我们需要的字段拿出来放入局部变量之中
val query1=this.query;
rdd.flatMap(x =>x.split(query1)
)
}
}

val rdd=sc.parallelize(List(1,2,3,4));
val result=rdd.map(value => value*value);
println(result.collect().mkString(","));
val rdd=sc.parallelize(List(1,2,3,4));
val result=rdd.filter(value => value!=1);
println(result.collect().mkString(","));
def filterFunction(value:Int):Boolean ={
value!=1
}
val rdd=sc.parallelize(List(1,2,3,4));
val result=rdd.filter(filterFunction);
println(result.collect().mkString(","));
val rdd=sc.parallelize(List("Hello world","hello you","world i love you"));
val result=rdd.flatMap(line => line.split(" "));
println(result.collect().mkString("\n"));
|
函数
|
用途
|
|
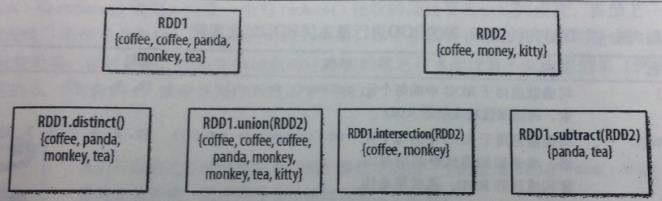
RDD1.distinct()
|
生成一个只包含不同元素的新RDD。需要数据混洗。 |
|
RDD1.union(RDD2)
|
返回一个包含两个RDD中所有元素的RDD |
|
RDD1.intersection(RDD2)
|
只返回两个RDD中都有的元素 |
|
RDD1.substr(RDD2)
|
返回一个只存在于第一个RDD而不存在于第二个RDD中的所有元素组成的RDD。需要数据混洗。 |
|
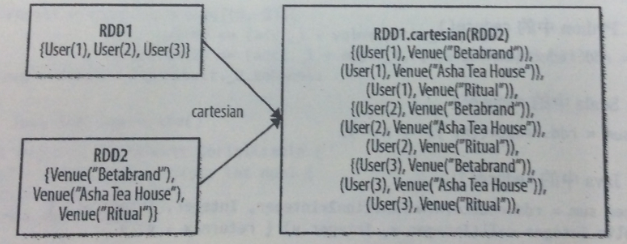
RDD1.cartesian(RDD2)
|
返回两个RDD数据集的笛卡尔集 |
val rdd1=sc.parallelize(List(1,2));
val rdd2=sc.parallelize(List(1,2));
val rdd=rdd1.cartesian(rdd2);
println(rdd.collect().mkString("\n"));
val rdd=sc.parallelize(List(1,2,3,4,5,6,7,8,9,10));
val results=rdd.reduce((x,y) =>x+y);
println(results);
val rdd=sc.parallelize(List(1,2,3,4,5,6,7,8,9,10));
val results=rdd.fold(0)((x,y) =>x+y);
println(results);
val rdd=sc.parallelize(List(1,2,3,4,5,6,7,8,9,10));
val results=rdd.fold(1)((x,y) =>x*y);
println(results);
val rdd=sc.parallelize(List(1,2,3,4,5,6,7,8,9,10));
val result=rdd.aggregate((0,0))(
(acc,value) =>(acc._1+value,acc._2+1),
(acc1,acc2) => (acc1._1+acc2._1, acc1._2+acc2._2)
)
val average=result._1/result._2;
println(average)
| 函数名 | 目的 | 示例 | 结果 |
| collect() | 返回RDD的所有元素 | rdd.collect() | {1,2,3,3} |
| count() | RDD的元素个数 | rdd.count() | 4 |
| countByValue() | 各元素在RDD中出现的次数 | rdd.countByValue() | {(1,1), (2,1), (3,2) } |
| take(num) | 从RDD中返回num个元素 | rdd.take(2) | {1,2} |
| top(num) | 从RDD中返回最前面的num个元素 | rdd.takeOrdered(2)(myOrdering) | {3,3} |
| takeOrdered(num) (ordering) |
从RDD中按照提供的顺序返回最前面的num个元素 |
rdd.takeSample(false,1) | 非确定的 |
| takeSample(withReplacement,num,[seed]) | 从RDD中返回任意一些元素 | rdd.takeSample(false,1) | 非确定的 |
| reduce(func) | 并行整合RDD中所有数据 | rdd.reduce((x,y) => x+y) |
9 |
| fold(zero)(func) | 和reduce()一样,但是需要提供初始值 | rdd.fold(0)((x,y) => x+y) |
9 |
| aggregate(zeroValue)(seqOp,combOp) | 和reduce()相似,但是通常返回不同类型的函数 | rdd.aggregate((0,0)) ((x,y) => (x._1+y,x._2+1), (x,y)=> (x._1+y._1,x._2+y._2) ) |
(9,4) |
| foreach(func) | 对RDD中的每个元素使用给定的函数 | rdd.foreach(func) | 无 |
| 级别 |
使用的空间
|
cpu时间
|
是否在内存
|
是否在磁盘
|
备注
|
|
MEMORY_ONLY
|
高 |
低
|
是
|
否
|
直接储存在内存 |
| MEMORY_ONLY_SER |
低
|
高
|
是
|
否
|
序列化后储存在内存里
|
|
MEMORY_AND_DISK
|
低 |
中等
|
部分
|
部分
|
如果数据在内存中放不下,溢写在磁盘上 |
|
MEMORY_AND_DISK_SER
|
低 |
高
|
部分
|
部分
|
数据在内存中放不下,溢写在磁盘中。内存中存放序列化的数据。 |
|
DISK_ONLY
|
低
|
高
|
否
|
是
|
直接储存在硬盘里面
|
val rdd=sc.parallelize(List(1,2,3,4,5,6,7,8,9,10)).persist(StorageLevel.MEMORY_ONLY);
println(rdd.count())
println(rdd.collect().mkString(","));
val rdd=sc.parallelize(List(1.0,2.0,3.0,4.0,5.0));
println(rdd.mean());
spark RDD编程,scala版本的更多相关文章
- Spark—RDD编程常用转换算子代码实例
Spark-RDD编程常用转换算子代码实例 Spark rdd 常用 Transformation 实例: 1.def map[U: ClassTag](f: T => U): RDD[U] ...
- Spark RDD编程-大数据课设
目录 一.实验目的 二.实验平台 三.实验内容.要求 1.pyspark交互式编程 2.编写独立应用程序实现数据去重 3.编写独立应用程序实现求平均值问题 四.实验过程 (一)pyspark交互式编程 ...
- Spark RDD编程核心
一句话说,在Spark中对数据的操作其实就是对RDD的操作,而对RDD的操作不外乎创建.转换.调用求值. 什么是RDD RDD(Resilient Distributed Dataset),弹性分布式 ...
- Spark RDD编程(博客索引,日常更新)
本篇主要是记录自己在中解决RDD编程性能问题中查阅的论文博客,为我认为写的不错的建立索引方便查阅,我的总结会另立他篇 1)通过分区(Partitioning)提高spark性能https://blog ...
- Spark基础:(二)Spark RDD编程
1.RDD基础 Spark中的RDD就是一个不可变的分布式对象集合.每个RDD都被分为多个分区,这些分区运行在分区的不同节点上. 用户可以通过两种方式创建RDD: (1)读取外部数据集====> ...
- Spark RDD/Core 编程 API入门系列之动手实战和调试Spark文件操作、动手实战操作搜狗日志文件、搜狗日志文件深入实战(二)
1.动手实战和调试Spark文件操作 这里,我以指定executor-memory参数的方式,启动spark-shell. 启动hadoop集群 spark@SparkSingleNode:/usr/ ...
- spark 中的RDD编程 -以下基于Java api
1.RDD介绍: RDD,弹性分布式数据集,即分布式的元素集合.在spark中,对所有数据的操作不外乎是创建RDD.转化已有的RDD以及调用RDD操作进行求值.在这一切的背后,Spark会自动 ...
- Spark学习笔记2:RDD编程
通过一个简单的单词计数的例子来开始介绍RDD编程. import org.apache.spark.{SparkConf, SparkContext} object word { def main(a ...
- Spark编程模型(RDD编程模型)
Spark编程模型(RDD编程模型) 下图给出了rdd 编程模型,并将下例中用 到的四个算子映射到四种算子类型.spark 程序工作在两个空间中:spark rdd空间和 scala原生数据空间.在原 ...
随机推荐
- opentsdb
http://blog.javachen.com/2014/01/22/all-things-opentsdb.html http://blog.csdn.net/bingjie1217/articl ...
- hrbustoj 2130 一笔画(状态压缩)
基础状态压缩 转移方程为 dp[j][i] = min(dp[j][i],dp[k][i^(1<<j)] + dis[k][j]); #include<iostream> #i ...
- 根据浏览器UA信息进行跳转(移动和pc)
如何用php判断一个客户端是手机还是电脑?其实很简单,开发人员都知道,通过浏览器访问网站时,浏览器都会向服务器发送UA,即User Agent(用户代理).不同浏览器.同一浏览器的不同版本.手机浏览器 ...
- IFeatureWorkspace OpenFeatureClass Example(转)
网络来源:http://changqingnew.blog.163.com/blog/static/1075233820103383633639/ //IFeatureWorkspace OpenFe ...
- Paragraph 对象'代表所选内容、范围或文档中的一个段落。Paragraph 对象是 Paragraphs 集合的一个成员。Paragraphs 集合包含所选内容、范围或文档中的所有段落。
Paragraph 对象'代表所选内容.范围或文档中的一个段落.Paragraph 对象是 Paragraphs 集合的一个成员.Paragraphs 集合包含所选内容.范围或文档中的所有段落. 方法 ...
- 计算机学院大学生程序设计竞赛(2015’12) 1006 01 Matrix
#include<stdio.h> #include<string.h> #include<iostream> #include<algorithm> ...
- Gradle依赖项学习总结,dependencies、transitive、force、exclude的使用与依赖冲突解决
http://www.paincker.com/gradle-dependencies https://docs.gradle.org/current/userguide/dependency_man ...
- ubuntu中mysql修改编码utf8
摘要:Ubuntu Server 服务器下使用apt-get 命令安装的mysql,默认不是utf8.在这里记录一下如何将编码修改成utf8. 办法解决: 1.查看mysql编码 show varia ...
- Android Camera HAL浅析
1.Camera成像原理介绍 Camera工作流程图 Camera的成像原理可以简单概括如下: 景物(SCENE)通过镜头(LENS)生成的光学图像投射到图像传感器(Sensor)表面上,然后转为电信 ...
- Quick Cocos2dx 场景对象基类实现
从使用Quick-Cocos2d-x搭建一个横版过关游戏(四)拷来个进度条类, 但是由于那个类有个bug,在setProgress里面self.fill是找不到的,所以我改进了一下,代码如下: loc ...