[Spark] - HashPartitioner & RangePartitioner 区别
Spark RDD的宽依赖中存在Shuffle过程,Spark的Shuffle过程同MapReduce,也依赖于Partitioner数据分区器,Partitioner类的代码依赖结构主要如下所示:
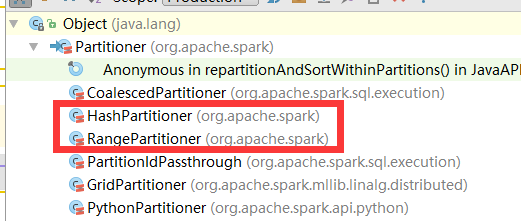
主要是HashPartitioner和RangePartitioner两个类,分别用于根据RDD中key的hashcode值进行分区以及根据范围进行数据分区
一、Partitioner
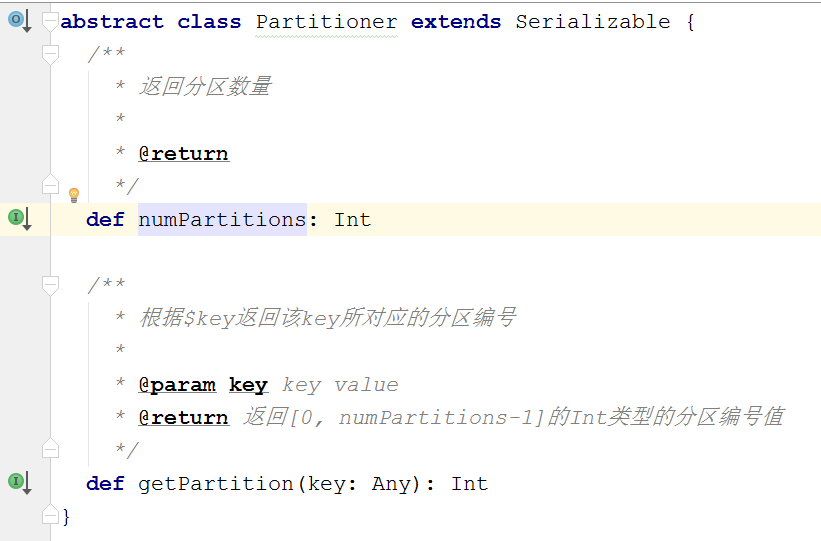
Spark中数据分区的主要工具类(数据分区类),主要用于Spark底层RDD的数据重分布的情况中,主要方法两个,如下:
二、HashPartitioner
Spark中非常重要的一个分区器,也是默认分区器,默认用于90%以上的RDD相关API上;功能:依据RDD中key值的hashCode的值将数据取模后得到该key值对应的下一个RDD的分区id值,支持key值为null的情况,当key为null的时候,返回0;该分区器基本上适合所有RDD数据类型的数据进行分区操作;但是需要注意的是,由于JAVA中数组的hashCode是基于数组对象本身的,不是基于数组内容的,所以如果RDD的key是数组类型,那么可能导致数据内容一致的数据key没法分配到同一个RDD分区中,这个时候最好自定义数据分区器,采用数组内容进行分区或者将数组的内容转换为集合。HashPartitioner代码说明如下:

三、RangePartitioner
SparkCore中除了HashPartitioner分区器外,另外一个比较重要的已经实现的分区器,主要用于RDD的数据排序相关API中,比如sortByKey底层使用的数据分区器就是RangePartitioner分区器;该分区器的实现方式主要是通过两个步骤来实现的,第一步:先重整个RDD中抽取出样本数据,将样本数据排序,计算出每个分区的最大key值,形成一个Array[KEY]类型的数组变量rangeBounds;第二步:判断key在rangeBounds中所处的范围,给出该key值在下一个RDD中的分区id下标;该分区器要求RDD中的KEY类型必须是可以排序的,代码说明如下:
class RangePartitioner[K: Ordering : ClassTag, V](
partitions: Int,
rdd: RDD[_ <: Product2[K, V]],
private var ascending: Boolean = true)
extends Partitioner { // We allow partitions = 0, which happens when sorting an empty RDD under the default settings.
require(partitions >= 0, s"Number of partitions cannot be negative but found $partitions.") // 获取RDD中key类型数据的排序器
private var ordering = implicitly[Ordering[K]] // An array of upper bounds for the first (partitions - 1) partitions
private var rangeBounds: Array[K] = {
if (partitions <= 1) {
// 如果给定的分区数是一个的情况下,直接返回一个空的集合,表示数据不进行分区
Array.empty
} else {
// This is the sample size we need to have roughly balanced output partitions, capped at 1M.
// 给定总的数据抽样大小,最多1M的数据量(10^6),最少20倍的RDD分区数量,也就是每个RDD分区至少抽取20条数据
val sampleSize = math.min(20.0 * partitions, 1e6)
// Assume the input partitions are roughly balanced and over-sample a little bit.
// 计算每个分区抽取的数据量大小, 假设输入数据每个分区分布的比较均匀
// 对于超大数据集(分区数超过5万的)乘以3会让数据稍微增大一点,对于分区数低于5万的数据集,每个分区抽取数据量为60条也不算多
val sampleSizePerPartition = math.ceil(3.0 * sampleSize / rdd.partitions.size).toInt
// 从rdd中抽取数据,返回值:(总rdd数据量, Array[分区id,当前分区的数据量,当前分区抽取的数据])
val (numItems, sketched) = RangePartitioner.sketch(rdd.map(_._1), sampleSizePerPartition)
if (numItems == 0L) {
// 如果总的数据量为0(RDD为空),那么直接返回一个空的数组
Array.empty
} else {
// If a partition contains much more than the average number of items, we re-sample from it
// to ensure that enough items are collected from that partition.
// 计算总样本数量和总记录数的占比,占比最大为1.0
val fraction = math.min(sampleSize / math.max(numItems, 1L), 1.0)
// 保存样本数据的集合buffer
val candidates = ArrayBuffer.empty[(K, Float)]
// 保存数据分布不均衡的分区id(数据量超过fraction比率的分区)
val imbalancedPartitions = mutable.Set.empty[Int]
// 计算抽取出来的样本数据
sketched.foreach { case (idx, n, sample) =>
if (fraction * n > sampleSizePerPartition) {
// 如果fraction乘以当前分区中的数据量大于之前计算的每个分区的抽象数据大小,那么表示当前分区抽取的数据太少了,该分区数据分布不均衡,需要重新抽取
imbalancedPartitions += idx
} else {
// 当前分区不属于数据分布不均衡的分区,计算占比权重,并添加到candidates集合中
// The weight is 1 over the sampling probability.
val weight = (n.toDouble / sample.size).toFloat
for (key <- sample) {
candidates += ((key, weight))
}
}
} // 对于数据分布不均衡的RDD分区,重新进行数据抽样
if (imbalancedPartitions.nonEmpty) {
// Re-sample imbalanced partitions with the desired sampling probability.
// 获取数据分布不均衡的RDD分区,并构成RDD
val imbalanced = new PartitionPruningRDD(rdd.map(_._1), imbalancedPartitions.contains)
// 随机种子
val seed = byteswap32(-rdd.id - 1)
// 利用rdd的sample抽样函数API进行数据抽样
val reSampled = imbalanced.sample(withReplacement = false, fraction, seed).collect()
val weight = (1.0 / fraction).toFloat
candidates ++= reSampled.map(x => (x, weight))
} // 将最终的抽样数据计算出rangeBounds出来
RangePartitioner.determineBounds(candidates, partitions)
}
}
} // 下一个RDD的分区数量是rangeBounds数组中元素数量+ 1个
def numPartitions: Int = rangeBounds.length + 1 // 二分查找器,内部使用java中的Arrays类提供的二分查找方法
private var binarySearch: ((Array[K], K) => Int) = CollectionsUtils.makeBinarySearch[K] // 根据RDD的key值返回对应的分区id。从0开始
def getPartition(key: Any): Int = {
// 强制转换key类型为RDD中原本的数据类型
val k = key.asInstanceOf[K]
var partition = 0
if (rangeBounds.length <= 128) {
// If we have less than 128 partitions naive search
// 如果分区数据小于等于128个,那么直接本地循环寻找当前k所属的分区下标
while (partition < rangeBounds.length && ordering.gt(k, rangeBounds(partition))) {
partition += 1
}
} else {
// Determine which binary search method to use only once.
// 如果分区数量大于128个,那么使用二分查找方法寻找对应k所属的下标;
// 但是如果k在rangeBounds中没有出现,实质上返回的是一个负数(范围)或者是一个超过rangeBounds大小的数(最后一个分区,比所有数据都大)
partition = binarySearch(rangeBounds, k)
// binarySearch either returns the match location or -[insertion point]-1
if (partition < 0) {
partition = -partition - 1
}
if (partition > rangeBounds.length) {
partition = rangeBounds.length
}
} // 根据数据排序是升序还是降序进行数据的排列,默认为升序
if (ascending) {
partition
} else {
rangeBounds.length - partition
}
}
其实RangePartitioner的重点是在于构建rangeBounds数组对象,主要步骤是:
1. 如果分区数量小于2或者rdd中不存在数据的情况下,直接返回一个空的数组,不需要计算range的边界;如果分区数据大于1的情况下,而且rdd中有数据的情况下,才需要计算数组对象
2. 计算总体的数据抽样大小sampleSize,计算规则是:至少每个分区抽取20个数据或者最多1M的数据量
3. 根据sampleSize和分区数量计算每个分区的数据抽样样本数量sampleSizePrePartition
4. 调用RangePartitioner的sketch函数进行数据抽样,计算出每个分区的样本
5. 计算样本的整体占比以及数据量过多的数据分区,防止数据倾斜
6. 对于数据量比较多的RDD分区调用RDD的sample函数API重新进行数据抽取
7. 将最终的样本数据通过RangePartitoner的determineBounds函数进行数据排序分配,计算出rangeBounds
RangePartitioner的sketch函数的作用是对RDD中的数据按照需要的样本数据量进行数据抽取,主要调用SamplingUtils类的reservoirSampleAndCount方法对每个分区进行数据抽取,抽取后计算出整体所有分区的数据量大小;reservoirSampleAndCount方法的抽取方式是先从迭代器中获取样本数量个数据(顺序获取), 然后对剩余的数据进行判断,替换之前的样本数据,最终达到数据抽样的效果
RangePartitioner的determineBounds函数的作用是根据样本数据记忆权重大小确定数据边界, 代码注释讲解如下:
def determineBounds[K: Ordering : ClassTag](
candidates: ArrayBuffer[(K, Float)],
partitions: Int): Array[K] = {
val ordering = implicitly[Ordering[K]]
// 按照数据进行数据排序,默认升序排列
val ordered = candidates.sortBy(_._1)
// 获取总的样本数量大小
val numCandidates = ordered.size
// 计算总的权重大小
val sumWeights = ordered.map(_._2.toDouble).sum
// 计算步长
val step = sumWeights / partitions
var cumWeight = 0.0
var target = step
val bounds = ArrayBuffer.empty[K]
var i = 0
var j = 0
var previousBound = Option.empty[K]
while ((i < numCandidates) && (j < partitions - 1)) {
// 获取排序后的第i个数据及权重
val (key, weight) = ordered(i)
// 累计权重
cumWeight += weight
if (cumWeight >= target) {
// Skip duplicate values.
// 权重已经达到一个步长的范围,计算出一个分区id的值
if (previousBound.isEmpty || ordering.gt(key, previousBound.get)) {
// 上一个边界值为空,或者当前边界key数据大于上一个边界的值,那么当前key有效,进行计算
// 添加当前key到边界集合中
bounds += key
// 累计target步长界限
target += step
// 分区数量加1
j += 1
// 上一个边界的值重置为当前边界的值
previousBound = Some(key)
}
}
i += 1
}
// 返回结果
bounds.toArray
}
四、总结
一般而已,使用默认的HashPartitioner即可,RangePartitioner的使用有一定的局限性
[Spark] - HashPartitioner & RangePartitioner 区别的更多相关文章
- 简要MR与Spark在Shuffle区别
一.区别 ①本质上相同,都是把Map端数据分类处理后交由Reduce的过程. ②数据流有所区别,MR按map, spill, merge, shuffle, sort, r educe等各阶段逐一实现 ...
- spark与Hadoop区别
2分钟读懂Hadoop和Spark的异同 2016.01.25 11:15:59 来源:51cto作者:51cto ( 0 条评论 ) 谈到大数据,相信大家对Hadoop和Apache Spark ...
- Apache Spark支持三种分布式部署方式 standalone、spark on mesos和 spark on YARN区别
链接地址: http://dongxicheng.org/framework-on-yarn/apache-spark-comparing-three-deploying-ways/ Spark On ...
- Pandas dataframe 与 Spark dataframe 的区别
区别 :http://www.voidcn.com/article/p-wsqbotem-boa.html 获取列名的列表: DataFrame.columns.values.tolist()
- Scala中sortBy和Spark中sortBy区别
Scala中sortBy是以方法的形式存在的,并且是作用在Array或List集合排序上,并且这个sortBy默认只能升序,除非实现隐式转换或调用reverse方法才能实现降序,Spark中sortB ...
- Spark中repartition和partitionBy的区别
repartition 和 partitionBy 都是对数据进行重新分区,默认都是使用 HashPartitioner,区别在于partitionBy 只能用于 PairRDD,但是当它们同时都用于 ...
- Spark深入之RDD
目录 Part III. Low-Level APIs Resilient Distributed Datasets (RDDs) 1.介绍 2.RDD代码 3.KV RDD 4.RDD Join A ...
- Spark Partition
分区的意义 Spark RDD 是一种分布式的数据集,由于数据量很大,因此它被切分成不同分区并存储在各个Worker节点的内存中.从而当我们对RDD进行操作时,实际上是对每个分区中的数据并行操作.Sp ...
- Spark 3.x Spark Core详解 & 性能优化
Spark Core 1. 概述 Spark 是一种基于内存的快速.通用.可扩展的大数据分析计算引擎 1.1 Hadoop vs Spark 上面流程对应Hadoop的处理流程,下面对应着Spark的 ...
随机推荐
- @synthesize和@dynamic
@synthesize 除非开发人员已经做了,否则由编译器自动生成getter/setter方法.当开发人员自定义存或取方法时,自定义会屏蔽自动生成该方法. @dynamic 告诉编译器,不自动生成g ...
- 苹果应用商店AppStore审核中文指南 分类: ios相关 app相关 2015-07-27 15:33 84人阅读 评论(0) 收藏
目录 1. 条款与条件 2. 功能 3. 元数据.评级与排名 4. 位置 5. 推送通知 6. 游戏中心 7. 广告 8. 商标与商业外观 9. 媒体内容 10. 用户界面 11. 购买与货币 12. ...
- el5,6,7的ntpdate服务
在el5里没有ntpdate服务 在el6里有ntpdate服务 在el7里有ntpdate服务
- 重拾python
前一段碰到几次关于日期计算的题:给出一个日期,计算下一天的日期.虽然不限语言,可是我就C/C++还算熟悉,别的都是刚了解皮毛,根本不会用现成的库啊,无奈啊...只好用c语言一点点实现了,当时真是无比怀 ...
- PHPEXCEL实例-导出EXCEL
PHPExcel 是相当强大的 MS Office Excel 文档生成类库,当需要输出比较复杂格式数据的时候,PHPExcel 是个不错的选择. <?php /* * 导出EXCEL * ...
- html5 安卓拨打电话 发短信
方法一: <input name=”phone_no” format=”*m” value=”13″/> <do type=”option” label=”呼出号”> < ...
- Python3基础 setdefault() 根据键查找值,找不到键会添加
镇场诗: 诚听如来语,顿舍世间名与利.愿做地藏徒,广演是经阎浮提. 愿尽吾所学,成就一良心博客.愿诸后来人,重现智慧清净体.-------------------------------------- ...
- Python装饰器学习(九步入门)
这是在Python学习小组上介绍的内容,现学现卖.多练习是好的学习方式. 第一步:最简单的函数,准备附加额外功能 ? 1 2 3 4 5 6 7 8 # -*- coding:gbk -*- '''示 ...
- linux Cron 执行Django 任务计划
用shell 脚本调用python 脚本如下 #!/bin/bash export FLAVOR=liveexport PYTHONPATH=$PYTHONPATH:/home/alex/Django ...
- eclipse 设置编辑窗口字体和背景颜色
最近装了几次系统,公司也换过电脑,所以换了几次eclipse,当然家里用的当然是最新版,公司就只有用几百年前的东西了 进入重点,我的编辑窗口习惯使用灰色的背景,感觉全白的不好看,还伤视力(没有科学依据 ...