Spark RDD详解 | RDD特性、lineage、缓存、checkpoint、依赖关系
RDD(Resilient Distributed Datasets)弹性的分布式数据集,又称Spark core,它代表一个只读的、不可变、可分区,里面的元素可分布式并行计算的数据集。
RDD是一个很抽象的概念,不易于理解,但是要想学好Spark,必须要掌握RDD,熟悉它的编程模型,这是学习Spark其他组件的基础。笔者在这里从名字和几个重要的概念给大家一一解读:
Resilient(弹性的)
提到大数据必提分布式,而在大规模的分布式集群中,任何一台服务器随时都有可能出现故障,如果一个task任务所在的服务器出现故障,必然导致这个task执行失败。此时,RDD的"弹性的"特点可以使这个task在集群内进行迁移,从而保证整体任务对故障服务器的平稳过渡。对于整个任务而言,只需重跑某些失败的task即可,而无需完全重跑,大大提高性能
Distributed(分布式)
首先了解一下分区,即数据根据一定的切分规则切分成一个个的子集。spark中分区划分规则默认是根据key进行哈希取模,切分后的数据子集可以独立运行在各个task中并且在各个集群服务器中并行执行。当然使用者也可以自定义分区规则,这个还是很有应用场景的,比如自定义分区打散某个key特别多的数据集以避免数据倾斜(数据倾斜是大数据领域常见问题也是调优重点,后续会单独讲解)
Datasets(数据集)
初学者很容易误解,认为RDD是存储数据的,毕竟从名字看来它是一个"弹性的分布式数据集"。但是,笔者强调,RDD并不存储数据,它只记录数据存储的位置。内部处理逻辑是通过使用者调用不同的Spark算子,一个RDD会转换为另一个RDD(这也体现了RDD只读不可变的特点,即一个RDD只能由另一个RDD转换而来),以transformation算子为例,RDD彼此之间会形成pipeline管道,无需等到上一个RDD所有数据处理逻辑执行完就可以立即交给下一个RDD进行处理,性能也得到了很大提升。但是RDD在进行transform时,不是每处理一条数据就交给下一个RDD,而是使用小批量的方式进行传递(这也是一个优化点)
lineage
既然Spark将RDD之间以pipeline的管道连接起来,如何避免在服务器出现故障后,重算这些数据呢?这些失败的RDD由哪来呢?这就牵涉到,Spark中的一个很重要的概念:Lineage即血统关系。它会记录RDD的元数据信息和依赖关系,当该RDD的部分分区数据丢失时,可以根据这些信息来重新运算和恢复丢失的分区数据。简单而言就是它会记录哪些RDD是怎么产生的、怎么“丢失”的等,然后Spark会根据lineage记录的信息,恢复丢失的数据子集,这也是保证Spark RDD弹性的关键点之一
Spark缓存和checkpoint
缓存(cache/persist)
cache和persist其实是RDD的两个API,并且cache底层调用的就是persist,区别之一就在于cache不能显示指定缓存方式,只能缓存在内存中,但是persist可以通过指定缓存方式,比如显示指定缓存在内存中、内存和磁盘并且序列化等。通过RDD的缓存,后续可以对此RDD或者是基于此RDD衍生出的其他的RDD处理中重用这些缓存的数据集容错(checkpoint)
本质上是将RDD写入磁盘做检查点(通常是checkpoint到HDFS上,同时利用了hdfs的高可用、高可靠等特征)。上面提到了Spark lineage,但在实际的生产环境中,一个业务需求可能非常非常复杂,那么就可能会调用很多算子,产生了很多RDD,那么RDD之间的linage链条就会很长,一旦某个环节出现问题,容错的成本会非常高。此时,checkpoint的作用就体现出来了。使用者可以将重要的RDD checkpoint下来,出错后,只需从最近的checkpoint开始重新运算即可使用方式也很简单,指定checkpoint的地址[SparkContext.setCheckpointDir("checkpoint的地址")],然后调用RDD的checkpoint的方法即可。checkpoint与cache/persist对比
都是lazy操作,只有action算子触发后才会真正进行缓存或checkpoint操作(懒加载操作是Spark任务很重要的一个特性,不仅适用于Spark RDD还适用于Spark sql等组件)
cache只是缓存数据,但不改变lineage。通常存于内存,丢失数据可能性更大
改变原有lineage,生成新的CheckpointRDD。通常存于hdfs,高可用且更可靠
RDD的依赖关系
Spark中使用DAG(有向无环图)来描述RDD之间的依赖关系,根据依赖关系的不同,划分为宽依赖和窄依赖
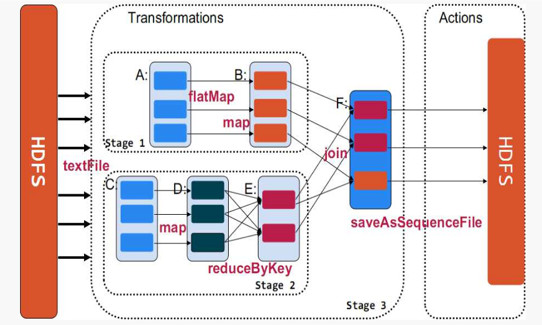
通过上图,可以很容易得出所谓宽依赖:多个子RDD的partition会依赖同一个parentRDD的partition;窄依赖:每个parentRDD的partition最多被子RDD的一个partition使用。这两个概念很重要,像宽依赖是划分stage的关键,并且一般都会伴有shuffle,而窄依赖之间其实就形成前文所述的pipeline管道进行处理数据。(图中的map、filter等是Spark提供的算子,具体含义大家可以自行到Spark官网了解,顺便感受一下scala函数式编程语言的强大)。
Spark任务以及stage等的具体划分,牵涉到源码,后续会单独讲解
最后笔者以RDD源码中的注释,阐述一下RDD的属性:
1.分区列表(数据块列表,只保存数据位置,不保存具体地址)
2. 计算每个分片的函数(根据父RDD计算出子RDD)
3. RDD的依赖列表
4. RDD默认是存储于内存,但当内存不足时,会spill到disk(可通过设置StorageLevel来控制)
5. 默认hash分区,可自定义分区器
6. 每一个分片的优先计算位置(preferred locations)列表,比如HDFS的block的所在位置应该是优先计算的位置
关注微信公众号:大数据学习与分享,获取更对技术干货
Spark RDD详解 | RDD特性、lineage、缓存、checkpoint、依赖关系的更多相关文章
- Spark参数详解 一(Spark1.6)
Spark参数详解 (Spark1.6) 参考文档:Spark官网 在Spark的web UI在"Environment"选项卡中列出Spark属性.这是一个很有用的地方,可以检查 ...
- Spark:常用transformation及action,spark算子详解
常用transformation及action介绍,spark算子详解 一.常用transformation介绍 1.1 transformation操作实例 二.常用action介绍 2.1 act ...
- EF+LINQ事物处理 C# 使用NLog记录日志入门操作 ASP.NET MVC多语言 仿微软网站效果(转) 详解C#特性和反射(一) c# API接受图片文件以Base64格式上传图片 .NET读取json数据并绑定到对象
EF+LINQ事物处理 在使用EF的情况下,怎么进行事务的处理,来减少数据操作时的失误,比如重复插入数据等等这些问题,这都是经常会遇到的一些问题 但是如果是我有多个站点,然后存在同类型的角色去操作 ...
- 详解C#特性和反射(四)
本篇内容是特性和反射的最后一篇内容,前面三篇文章: 详解C#特性和反射(一) 详解C#特性和反射(二) 详解C#特性和反射(三) 一.晚期绑定(Late Binding)是一种在编译时不知道类型及其成 ...
- 详解C#泛型(二) 获取C#中方法的执行时间及其代码注入 详解C#泛型(一) 详解C#委托和事件(二) 详解C#特性和反射(四) 记一次.net core调用SOAP接口遇到的问题 C# WebRequest.Create 锚点“#”字符问题 根据内容来产生一个二维码
详解C#泛型(二) 一.自定义泛型方法(Generic Method),将类型参数用作参数列表或返回值的类型: void MyFunc<T>() //声明具有一个类型参数的泛型方法 { ...
- 详解Java8特性之新的日期时间 API
详解Java8特性之新的日期时间 API http://blog.csdn.net/timheath/article/details/71326329 Java8中时间日期库的20个常用使用示例 ht ...
- 关于spark RDD trans action算子、lineage、宽窄依赖详解
这篇文章想从spark当初设计时为何提出RDD概念,相对于hadoop,RDD真的能给spark带来何等优势.之前本想开篇是想总体介绍spark,以及环境搭建过程,但个人感觉RDD更为重要 铺垫 在h ...
- Spark 核心概念 RDD 详解
RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此,RDD支持 ...
- Spark函数详解系列之RDD基本转换
摘要: RDD:弹性分布式数据集,是一种特殊集合 ‚ 支持多种来源 ‚ 有容错机制 ‚ 可以被缓存 ‚ 支持并行操作,一个RDD代表一个分区里的数据集 RDD有两种操作算子: ...
随机推荐
- 被产品经理怼了,线上出Bug为啥你不知道
前言 前几天跟读者聊天,他说被产品经理给怼了.原因是线上出 Bug 了,最后是客户反馈才知道的. 我就问他:你们是不是没做监控? 读者:我们是刚成立的创业团队,目前最重要的就是堆功能,很多基础设施都没 ...
- 静态代理、jdk动态代理、cglib动态代理
一.静态代理 Subject:抽象主题角色,抽象主题类可以是抽象类,也可以是接口,是一个最普通的业务类型定义,无特殊要求. RealSubject:具体主题角色,也叫被委托角色.被代理角色.是业务逻辑 ...
- vulnhub-Os-hackNos-3
vulnhub-Os-hackNos-3 nmap 192.168.114.0/24 查看存活主机,发现192.168.114.142. 具体探究: 发现80和22端口是开放的. dirb没扫出来啥, ...
- 论文阅读 A SIMPLE BUT TOUGH-TO-BEAT BASELINE FOR SEN- TENCE EMBEDDINGS
这篇论文提出了SIF sentence embedding方法, 作者提供的代码在Github. 引入 作为一种无监督计算句子之间相似度的方法, sif sentence embedding使用预训练 ...
- java安全编码指南之:可见性和原子性
目录 简介 不可变对象的可见性 保证共享变量的复合操作的原子性 保证多个Atomic原子类操作的原子性 保证方法调用链的原子性 读写64bits的值 简介 java类中会定义很多变量,有类变量也有实例 ...
- 3、JVM中的对象
1.对象的创建 A a = new A() A:引用的类型 a::引用的名称 new A():创建一个A类对象 当创建一个对象时,具体创建过程是什么呢? (1)JVM遇到new的字节码指令后,检查类 ...
- 【CF1425H】Huge Boxes of Animal Toys 题解
原题链接 题意简介: 已知分别处在 \((-\infty,-1]\) H.\((-1,0)\) .\((0,1)\) .\([1,\infty)\) 的实数的数量(下记为集合 \(A,B,C,D\) ...
- Emgu.CV怎么加载Bitmap
EmguCV 在4.0.1版本之后没办法用Bitmap创建Image了. 我给大家说下 EmguCV怎么加载Bitmap 下边是 EmguCV 官方文档写的,意思是从4.0.1以后的版本不能直接Bit ...
- 可变参数__VA_ARGS__使用
1. 调试功能一般会使用到宏+可变参数的方式 1.1 ##__VA_ARGS__ 之详细解析 例如: case A. #define my_print1(...) printf(__V ...
- python数据结构之图深度优先和广度优先实例详解
本文实例讲述了python数据结构之图深度优先和广度优先用法.分享给大家供大家参考.具体如下: 首先有一个概念:回溯 回溯法(探索与回溯法)是一种选优搜索法,按选优条件向前搜索,以达到目标.但当探索到 ...