kafka学习(三)kafka生产者,消费者详解
文章更新时间:2020/06/14
一、生产者
当我们发送消息之前,先问几个问题:每条消息都是很关键且不能容忍丢失么?偶尔重复消息可以么?我们关注的是消息延迟还是写入消息的吞吐量?
举个例子,有一个信用卡交易处理系统,当交易发生时会发送一条消息到 Kafka,另一个服务来读取消息并根据规则引擎来检查交易是否通过,将结果通过 Kafka 返回。对于这样的业务,消息既不能丢失也不能重复,由于交易量大因此吞吐量需要尽可能大,延迟可以稍微高一点。
再举个例子,假如我们需要收集用户在网页上的点击数据,对于这样的场景,少量消息丢失或者重复是可以容忍的,延迟多大都不重要只要不影响用户体验,吞吐则根据实时用户数来决定。
不同的业务需要使用不同的写入方式和配置。具体的方式我们在这里不做讨论,现在先看下生产者写消息的基本流程:
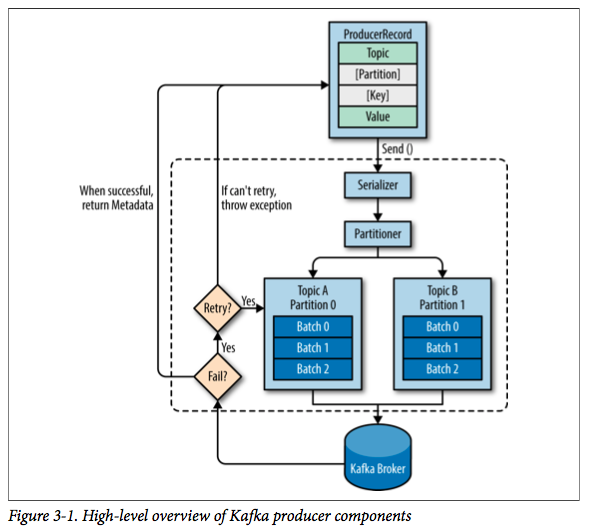
流程如下:
- 首先,我们需要创建一个ProducerRecord,这个对象需要包含消息的主题(topic)和值(value),可以选择性指定一个键值(key)或者分区(partition)。
- 发送消息时,生产者会对键值和值序列化成字节数组,然后发送到分配器(partitioner)。
- 如果我们指定了分区,那么分配器返回该分区即可;否则,分配器将会基于键值来选择一个分区并返回。
- 选择完分区后,生产者知道了消息所属的主题和分区,它将这条记录添加到相同主题和分区的批量消息中,另一个线程负责发送这些批量消息到对应的Kafka broker。
- 当broker接收到消息后,如果成功写入则返回一个包含消息的主题、分区及位移的RecordMetadata对象,否则返回异常。
- 生产者接收到结果后,对于异常可能会进行重试。
一句话流程:
- 【创建包含topic和value的对象】
- 【消息到分配器】
- 【分配器返回分区信息】
- 【消息添加到相同topic中,并根据分区策略添加到对应的分区里面】
- 【成功写入返回RecordMetadata,否则返回异常】
- 【异常可能重试】
二、消费者
消费者与消费组
假设这么个场景:我们从Kafka中读取消息,并且进行检查,最后产生结果数据。我们可以创建一个消费者实例去做这件事情,但如果生产者写入消息的速度比消费者读取的速度快怎么办呢?这样随着时间增长,消息堆积越来越严重。对于这种场景,我们需要增加多个消费者来进行水平扩展。
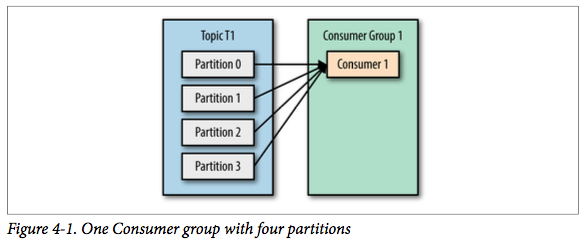
Kafka消费者是消费组的一部分,当多个消费者形成一个消费组来消费主题时,每个消费者会收到不同分区的消息。假设有一个T1主题,该主题有4个分区;同时我们有一个消费组G1,这个消费组只有一个消费者C1。那么消费者C1将会收到这4个分区的消息,如下所示:
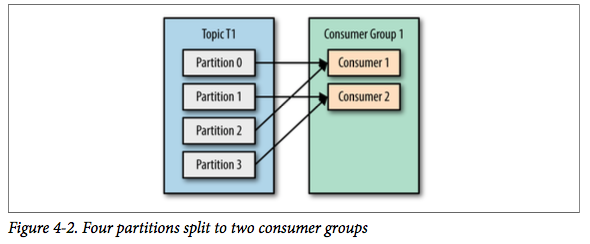
如果我们增加新的消费者C2到消费组G1,那么每个消费者将会分别收到两个分区的消息,如下所示:
如果增加到4个消费者,那么每个消费者将会分别收到一个分区的消息,如下所示:
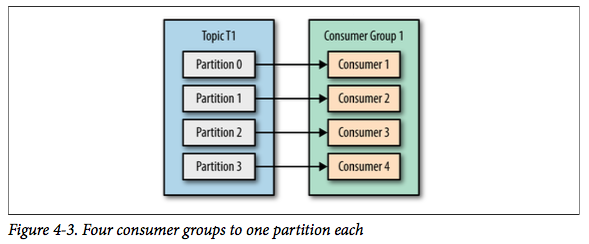
但如果我们继续增加消费者到这个消费组,剩余的消费者将会空闲,不会收到任何消息:
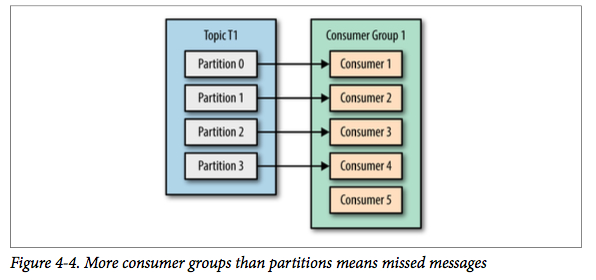
总而言之,我们可以通过增加消费组的消费者来进行水平扩展提升消费能力。这也是为什么建议创建主题时使用比较多的分区数,这样可以在消费负载高的情况下增加消费者来提升性能。另外,消费者的数量不应该比分区数多,因为多出来的消费者是空闲的,没有任何帮助。
Kafka一个很重要的特性就是,只需写入一次消息,可以支持任意多的应用读取这个消息。换句话说,每个应用都可以读到全量的消息。为了使得每个应用都能读到全量消息,应用需要有不同的消费组。对于上面的例子,假如我们新增了一个新的消费组G2,而这个消费组有两个消费者,那么会是这样的:
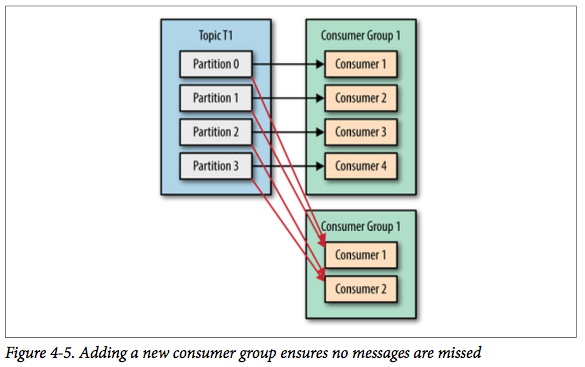
在这个场景中,消费组G1和消费组G2都能收到T1主题的全量消息,在逻辑意义上来说它们属于不同的应用。
小结:如果应用需要读取全量消息,那么请为该应用设置一个消费组;如果该应用消费能力不足,那么可以考虑在这个消费组里增加消费者。
消费组与分区重平衡
可以看到,当新的消费者加入消费组,它会消费一个或多个分区,而这些分区之前是由其他消费者负责的;另外,当消费者离开消费组(比如重启、宕机等)时,它所消费的分区会分配给其他分区。这种现象称为重平衡(rebalance)。重平衡是 Kafka 一个很重要的性质,这个性质保证了高可用和水平扩展。不过也需要注意到,在重平衡期间,所有消费者都不能消费消息,因此会造成整个消费组短暂的不可用。而且,将分区进行重平衡也会导致原来的消费者状态过期,从而导致消费者需要重新更新状态,这段期间也会降低消费性能。后面我们会讨论如何安全的进行重平衡以及如何尽可能避免。
消费者通过定期发送心跳(hearbeat)到一个作为组协调者(group coordinator)的 broker 来保持在消费组内存活。这个 broker 不是固定的,每个消费组都可能不同。当消费者拉取消息或者提交时,便会发送心跳。
如果消费者超过一定时间没有发送心跳,那么它的会话(session)就会过期,组协调者会认为该消费者已经宕机,然后触发重平衡。可以看到,从消费者宕机到会话过期是有一定时间的,这段时间内该消费者的分区都不能进行消息消费;通常情况下,我们可以进行优雅关闭,这样消费者会发送离开的消息到组协调者,这样组协调者可以立即进行重平衡而不需要等待会话过期。
在 0.10.1 版本,Kafka 对心跳机制进行了修改,将发送心跳与拉取消息进行分离,这样使得发送心跳的频率不受拉取的频率影响。另外更高版本的 Kafka 支持配置一个消费者多长时间不拉取消息但仍然保持存活,这个配置可以避免活锁(livelock)。活锁,是指应用没有故障但是由于某些原因不能进一步消费。
Partition 与消费模型
Q:Kafka 中一个 topic 中的消息是被打散分配在多个 Partition(分区) 中存储的, Consumer Group 在消费时需要从不同的 Partition 获取消息,那最终如何重建出 Topic 中消息的顺序呢?
A:没有办法。Kafka 只会保证在 Partition 内消息是有序的,而不管全局的情况。
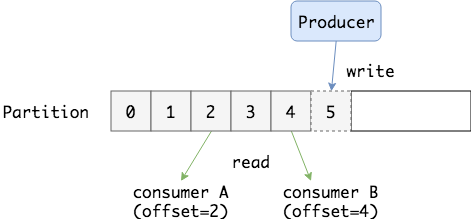
Q:Partition 中的消息可以被(不同的 Consumer Group)多次消费,那 Partition中被消费的消息是何时删除的? Partition 又是如何知道一个 Consumer Group 当前消费的位置呢?
A:无论消息是否被消费,除非消息到期 Partition 从不删除消息。例如设置保留时间为 2 天,则消息发布 2 天内任何 Group 都可以消费,2 天后,消息自动被删除。 Partition 会为每个 Consumer Group 保存一个偏移量,记录 Group 消费到的位置。 如下图:
Q:多个 partitions 的好处?
A:对 broker 上的数据进行分片,有效减少了消息的容量从而提升 io 性能,且不同消费者组可以消费不同的分区数据,也提高消费端的消费能力。
为什么 Kafka 是 pull 模型
Q:消费者应该向 Broker 要数据(pull)还是 Broker 向消费者推送数据(push)?
A:作为一个消息系统,Kafka 遵循了传统的方式,选择由 Producer 向 broker push 消息并由 Consumer 从 broker pull 消息。一些 logging-centric system,比如 Facebook 的Scribe和 Cloudera 的Flume,采用 push 模式。事实上,push 模式和 pull 模式各有优劣。
push 模式很难适应消费速率不同的消费者,因为消息发送速率是由 broker 决定的。push 模式的目标是尽可能以最快速度传递消息,但是这样很容易造成 Consumer 来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而 pull 模式则可以根据 Consumer 的消费能力以适当的速率消费消息。
对于 Kafka 而言,pull 模式更合适。pull 模式可简化 broker 的设计,Consumer 可自主控制消费消息的速率,同时 Consumer 可以自己控制消费方式——即可批量消费也可逐条消费,同时还能选择不同的提交方式从而实现不同的传输语义。
三、可靠性问题
当我们讨论可靠性的时候,我们总会提到*保证**这个词语。可靠性保证是基础,我们基于这些基础之上构建我们的应用。比如关系型数据库的可靠性保证是ACID,也就是原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。
Kafka 中的可靠性保证有如下四点:
- 对于一个分区来说,它的消息是有序的。如果一个生产者向一个分区先写入消息A,然后写入消息B,那么消费者会先读取消息A再读取消息B。
- 当消息写入所有in-sync状态的副本后,消息才会认为已提交(committed)。这里的写入有可能只是写入到文件系统的缓存,不一定刷新到磁盘。生产者可以等待不同时机的确认,比如等待分区主副本写入即返回,后者等待所有in-sync状态副本写入才返回。【参见第二篇的ACK应答机制:戳这里】
- 一旦消息已提交,那么只要有一个副本存活,数据不会丢失。
- 消费者只能读取到已提交的消息。
使用这些基础保证,我们构建一个可靠的系统,这时候需要考虑一个问题:究竟我们的应用需要多大程度的可靠性?可靠性不是无偿的,它与系统可用性、吞吐量、延迟和硬件价格息息相关,得此失彼。因此,我们往往需要做权衡,一味的追求可靠性并不实际。
四、分区策略
Range strategy(范围分区)
Range 策略是对每个主题而言的,首先对同一个主题里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。假设我们有 10 个分区,3 个消费者,排完序的分区 将会是 0, 1, 2, 3, 4, 5, 6, 7, 8, 9;消费者线程排完序将会是 C1-0, C2-0, C3-0。然后将 partitions 的个数除于消费者线程的总数来决定每个消费者线程消费几个分区。如果除不尽,那么前面几个消费者线程将会多消费一个分区。在例子里面,我们有 10 个分区,3 个消费者线程, 10 / 3=3,而且除不尽,那么消费者线程 C1-0 将会多消费一个分区,所以最后分区分配的结果看起来是这样的:
- C1-0 将消费 0, 1, 2, 3 分区
- C2-0 将消费 4, 5, 6 分区
- C3-0 将消费 7, 8, 9 分区
假如我们有 11 个分区,那么最后分区分配的结果看起来是这样的:
- C1-0 将消费 0, 1, 2, 3 分区
- C2-0 将消费 4, 5, 6, 7 分区
- C3-0 将消费 8, 9, 10 分区
假如我们有 2 个主题(T1 和 T2),分别有 10 个分区,那么最后分区分配的结果看起来是这样的:
- C1-0 将消费 T1主题的 0, 1, 2, 3 分区以及 T2主题的 0, 1, 2, 3 分区
- C2-0 将消费 T1主题的 4,5,6 分区以及 T2主题的 4,5, 6 分区
- C3-0 将消费 T1主题的 7,8,9 分区以及 T2主题的 7,8, 9 分区
可以看出,C1-0 消费者线程比其他消费者线程多消费了 2 个 分区,这就是 Range strategy 的一个很明显的弊端。
RoundRobin strategy(轮询分区)
轮询分区策略是把所有 partition 和所有 consumer 线程都列出来,然后按照 hashcode 进行排序。最后通过轮询算法分配 partition 给消费线程。如果所有 consumer 实例的订阅是相同的,那么 partition 会均匀分布。
在例子里面,假如按照 hashCode 排序完的 topic- partitions 组依次为 T1-5, T1-3, T1-0, T1-8, T1-2, T1-1, T1-4,T1-7, T1-6, T1-9,我们的消费者线程排序为 C1-0, C1-1, C2- 0, C2-1,最后分区分配的结果为:
- C1-0 将消费 T1-5, T1-2, T1-6 分区
- C1-1 将消费 T1-3, T1-1, T1-9 分区
- C2-0 将消费 T1-0, T1-4 分区
- C2-1 将消费 T1-8, T1-7 分区
使用轮询分区策略必须满足两个条件
- 1. 每个主题的消费者实例具有相同数量的流
- 2. 每个消费者订阅的主题必须是相同的
Q:什么时候会触发这个策略呢?
A:当出现以下几种情况时,kafka 会进行一次分区分配操作,也就是 kafka consumer 的 rebalance:
- 同一个 consumer group 内新增了消费者
- 消费者离开当前所属的 consumer group,比如主动停机或者宕机
- topic 新增了分区(也就是分区数量发生了变化)
PS:kafka consuemr 的 rebalance 机制规定了一个 consumer group 下的所有 consumer 如何达成一致来分配订阅 topic 的每个分区。而具体如何执行分区策略,就是前面提到过的两种内置的分区策略。而 kafka 对于分配策略这块,提供了可插拔的实现方式,也就是说,除了这两种之外,我们还可以创建自己的分配机制。
Q:谁来执行 Rebalance 以及管理 consumer 的 group 呢?
A:Kafka 提供了一个角色:coordinator【调配器】 来执行对于 consumer group 的管理,当 consumer group 的第一个 consumer 启动的时候,它会去和 kafka server 确定谁是它们组的 coordinator。之后该 group 内的所有成员都会和该 coordinator 进行协调通信。
Q:如何确定 coordinator 【调配器】呢?
A:consumer group 如何确定自己的 coordinator 是谁呢, 消费者向 kafka 集群中的任意一个 broker 发送一个 GroupCoordinatorRequest 请求,服务端会返回一个负载最小的 broker 节点的 id,并将该 broker 设置为 coordinator。
参考资料
- kafka入门就这一篇(特此感谢!)
kafka学习(三)kafka生产者,消费者详解的更多相关文章
- kafka学习(三)-kafka集群搭建
kafka集群搭建 下面简单的介绍一下kafka的集群搭建,单个kafka的安装更简单,下面以集群搭建为例子. 我们设置并部署有三个节点的 kafka 集合体,必须在每个节点上遵循下面的步骤来启动 k ...
- 流媒体学习三-------SIP消息结构详解
SIP消息由三部分组成,即:开始行(start line).消息头(header).正文(body)Start-line:请求行Request-line 消息为 request消息时使用reques ...
- nodejs的mysql模块学习(三)数据库连接配置选项详解
连接选项 当在创建数据连接的时候 第一种大多数人用的方法 let mysql = require('mysql'); let connection = mysql.createConnection({ ...
- Linux防火墙iptables学习笔记(三)iptables命令详解和举例[转载]
Linux防火墙iptables学习笔记(三)iptables命令详解和举例 2008-10-16 23:45:46 转载 网上看到这个配置讲解得还比较易懂,就转过来了,大家一起看下,希望对您工作能 ...
- 《从0到1学习Flink》—— Flink 配置文件详解
前面文章我们已经知道 Flink 是什么东西了,安装好 Flink 后,我们再来看下安装路径下的配置文件吧. 安装目录下主要有 flink-conf.yaml 配置.日志的配置文件.zk 配置.Fli ...
- Python学习一:序列基础详解
作者:NiceCui 本文谢绝转载,如需转载需征得作者本人同意,谢谢. 本文链接:http://www.cnblogs.com/NiceCui/p/7858473.html 邮箱:moyi@moyib ...
- Python学习二:词典基础详解
作者:NiceCui 本文谢绝转载,如需转载需征得作者本人同意,谢谢. 本文链接:http://www.cnblogs.com/NiceCui/p/7862377.html 邮箱:moyi@moyib ...
- IP2——IP地址和子网划分学习笔记之《子网掩码详解》
2018-05-04 16:21:21 在学习掌握了前面的<进制计数><IP地址详解>这两部分知识后,要学习子网划分,首先就要必须知道子网掩码,只有掌握了子网掩码这部分内容 ...
- “全栈2019”Java第一百零三章:匿名内部类详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- 重新学习MySQL数据库7:详解MyIsam与InnoDB引擎的锁实现
重新学习Mysql数据库7:详解MyIsam与InnoDB引擎的锁实现 说到锁机制之前,先来看看Mysql的存储引擎,毕竟不同的引擎的锁机制也随着不同. 三类常见引擎: MyIsam :不支持事务,不 ...
随机推荐
- C++ 7种排序方法代码合集
class Solution { public: /******************************************************************** 直接插入排 ...
- 求X值问题
这,其实是一道数学题,难就难在要把数学模型用编程语言实现,其中的规律如果看不出来就比较鸡肋,这类题可以算是智商题,做这类题千万不能紧张,血的教训. 题目描述 已知有整数x,x + 100为一个平方数. ...
- MySQL 索引结构
谈到 MYSQL 索引服务端的同学应该是熟悉的不能再熟悉,新建表的时候怎么着都知道先来个主键索引,对于经常查询的列也会加个索引加快查询速度.那么 MYSQL 索引都有哪些类型呢?索引结构是什么样的呢? ...
- C语言复习-字符串与指针
C语言复习-字符串与指针 例一: [字符串处理 去除C代码中的注释] C/C++代码中有两种注释,/* */和//.编译器编译预处理时会先移除注释.就是把/*和*/之间的部分去掉,把//以及之后的部分 ...
- h5c3
HTML5 第一天 一.什么是 HTML5 HTML5 的概念与定义 定义:HTML5 定义了 HTML 标准的最新版本,是对 HTML 的第五次重大修改,号称下一代的 HTML 两个概念: 是一个新 ...
- UnitTest框架的快速构建与运行
我们先来简单介绍一下unittest框架,先上代码: 1.建立结构的文件夹: 注意,上面的文件夹都是package,也就是说你在new新建文件夹的时候不要选directory,而是要选package: ...
- JS - 日期时间比较函数
JS日期比较(yyyy-mm-dd) function duibi(a, b) { var arr = a.split("-"); var starttime = new Date ...
- e3mall商城的归纳总结4之图片服务器以及文本编辑器
一.图片服务器 --1.认识图片服务器 大家可能都知道在分布式架构中使用图片上传可能会导致文件存放在某一个项目,而我们的项目基本上都采用集群的方式 ,因此这样会导致图片的问题比较难以存放,在这里我们有 ...
- ABP VNext实践之搭建可用于生产的IdentityServer4
一.前言 用了半年多的abp vnext,在开发的效果还是非常的好,可以说节省了很多时间,像事件总线.模块化开发.动态API进行远程调用.自动API控制器等等,一整套的规范,让开发人员更方便的集成,提 ...
- Android Studio Eclipse运行时出现 finished with non-zero exit value 2 错误解决方法
作者:程序员小冰,CSDN博客:http://blog.csdn.net/qq_21376985 QQ986945193 微博:http://weibo.com/mcxiaobing Error:Ex ...