聊聊CacheLine
本文转载自聊聊CacheLine
导语
文章聊聊缓存一致性协议中我们提到过,缓存里面最小的单位是缓存行/缓存条目,但是缓存中的具体存储结构是什么样的,缓存行中有存放的是什么?在缓存中是如何寻找指定是还是还存在?本篇我们就聊聊一下Cache Line
缓存中的组构
文章中出现的缓存和Cache,指的是高速缓存,在后面提到的缓存都指的是高速缓存,出现的缓存行指的就是CacheLine
在之前文章中我们只提到了缓存中数据是存储在CacheLine中的,CacheLine是Cache缓存数据的最小单位,但是Cache的结构是怎么样的,CacheLine的结构又是怎么样的,我们先来看一下Cache的整体结构图
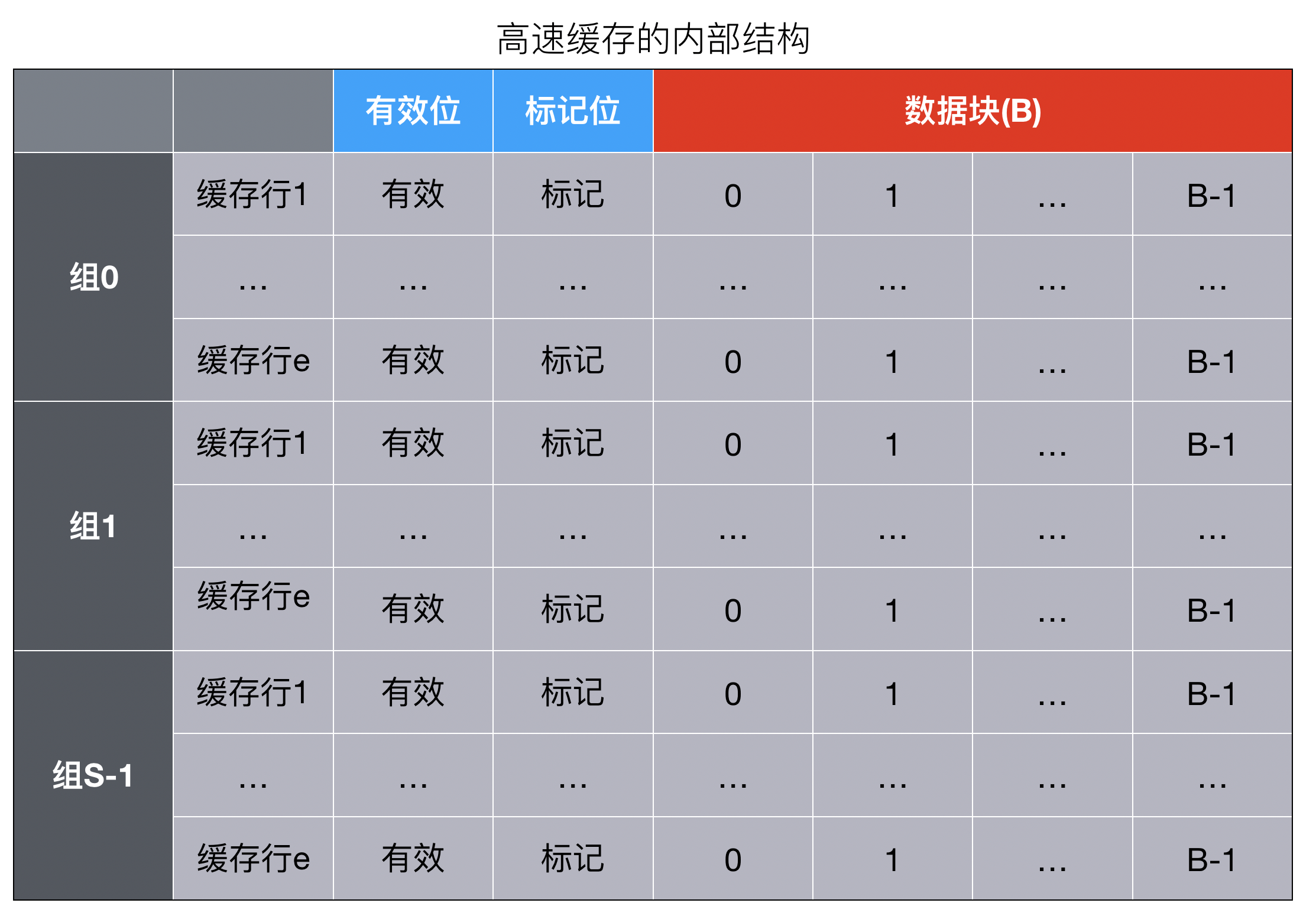
由上图可以看出
高速缓存的组成由S个高速缓存组(cache set )
每一组包含E个高速缓存行( cache line),
每一行由一个有效位(valid bit)指明这个行是否包含有意义的信息;一个长度为t的标记位(tag bit ),唯一标识存储在这个高速缓存行中的块在内存中的地址;和一个B字节的数据块(block)构成
高速缓存的结构可以用元组(S,E,B,m )来描述,高速缓存的大小C指的是所有块的大小的和。标记位和有效位不包含在内,因此*C=SEB*
块是一个固定大小的信息包,在高速缓存和主存之间来回传送
行是高速缓存中的一个容器,存储块以及其它信息(有效位和标记位)
组是一个或多个行的集合,直接映射高速缓存中的组只由一行组成;组相联和全相联高速缓存中的组是由多个行组成
因为一行总是存储一个块,术语”行”和”块”通常互换使用,我们经常总是说高速缓存的缓存行大小是固定的,缓存行的大小一般为64个字节(不包含有效位和标记位),实际上指的是块大小。这样的叫法十分普遍,只要要以理解块和行之间的区别,就不会造成任何误会
如何查找缓存条目
当从缓存中获取一个数据时,如果缓存行中存在该数据的有效副本,称为缓存命中,否则称为缓存未命中。 高速缓存确定一个请求是还命中, 要分为三步选择组、选择行、字抽取
根据每个组的高速缓存行数E,高速缓存被分为不同的类型,在不同的cache映射下,查找查询过程也是不一样的,在讨论之前回顾一下前面的说的高速缓存的结构可以用元组(S,E,B,m )来描述, 里面的m表示有m位表示地址(主存物理地址数),地址的构成如下图

高速缓存的结构将m个地址划分成了
| 位名称 | 用途 |
|---|---|
| t位标记位 | 用来标识当前缓存行数据是还有效 |
| s个组索引 | 用来定位所访问的地址在高速缓存中所属的组编号 |
| b个偏移块位 | 访问数据在缓存行中块的偏移量 |
下面我们分情况讨论一下
直接映射高速缓存
在这种模式下,每个组只有一行(E=1)的高速缓存称为直接映射高速缓存(direct-mapped cache ),它是最容易实现和理解的。它将一个主内存块存储到唯一的一个缓存行中,是一种多对一的映射关系,
主内存块块号Y到缓存行行号X的映射函数为
$$
f(X)=Y % s
$$
高速缓存从地址中取出s个组索引位(地址中蓝色区域),去高速缓存中去访问组,由于E=1,一个组内只有一个缓存行,所以只要组内的缓存行设置了有效位,并且高速缓存行中的*标记与地址中的标记(绿色区域)相匹配*时,那么就缓存命中,根据偏移地址(红色区域)在缓存行中获取对应偏移地址的内容即可。
组相关高速缓存
直接映射高速缓存中冲突不命中千万的问题源于每个组只有一行这个限制,组相关高速缓存(set associative cache)放松了这条限制 ,每个组都保存有多于一个的高速缓存行,即**1
在这种模式下,高速缓存存在s个组,每组有t个缓存行,主内存数据块映射到哪个组是固定的,但是存储到组内哪一缓存行是不固定的,因为涉及到缓存淘汰策略
设主内存块号为x,那么映射函数为
$$
f(x) = x % s
$$
在这种模式下,组选择的过程和直接映射高速缓存是一样的,使用组索引位(蓝色区域)标识组
组相联高速缓存中的行匹配比直接映射高速缓存中的要复杂,因为每组包含多个缓存行,所以它必须检查组中多个行的标记位和有效位,如果高速缓存行中的某一行的标记位与地址中的标记位(绿色区域)匹配,则缓存命中,然后根据偏移地址(红色区域)在缓存行中获取对应偏移地址的内容即可。
如果缓存未命中,则需从主从中读取包含数据的块号,并且替换高速缓存中的一个数据行,至于替换哪个数据行,则根据高速缓存的替换策略来判断,如果替换的数据正是我们下次要用到的,下次在使用到相关的数据时候,则又要替换一次缓存行中的数据,这样无法使用局部性原理,程序执行效率会很差的
全相联高速缓存
该缓存中只有一个分组,一个分组中包含所有的缓存行 (即E=C/B), 主存储块块号可以对应到任意一个缓存行
在这种模式下,组选择非常简单,因为只有一个组,所以默认总是选择组0,地址的结构也会发生变化,因为组索引不用,所以地址中去除了组索引位,地址被划分成了一个标记位和一个块偏移位

行匹配与组相联高速缓存中是一样的,它们之间的区别主要是遍历缓存行规模大小不同,因为构造一个又大双快的相联高速缓存我也爱你困难,而且很昂贵,所以它只适合做小高速缓存。
缓存行的伪共享
缓存工作原理要求它尽量保存最新数据,当从主存向Cache传送一个新块,而Cache中可用位置已被占满时,就会产生Cache替换的问题。
缓存中交换数据的最小单位是缓存行,所以如果一个共享变量被多个cpu核心所使用时,就会出现相同的主内存块号内容被缓存到不同的缓存行中,如果一个cpu核心对它所关心的变量进行了修改,就会导致另一个cpu核心的缓存行失效,产生缓存未命中,如果这样的情况经常发生,会严重的影响程序性能,这就是伪共享**,它会严重浪费系统资源。
如下图,CPUA和CPUB都缓存了相同的数据 ,但是CPUA要对里面的变量A进行修改,CPUB要对变量B进行修改,这时候就产生了伪共享。

其实伪共享产生的本质问题是,不同CPU使用到的数据,被缓存在相同的缓存行中,只要可以解决此问题,就会消除伪共享。
java中如何解决伪共享
java中是通过数据填充的方式,保证变量不会和其他东西同时存在于一个缓存行中,这样失去了地址连续性被加载到同一个缓存行,就避免了伪共享, 当然填充是需要技巧的,需要对缓存行的大小以及操作的数据在内存中的布局有个了解。下面以Java对伪共享的解决为例进行举例。
package com.bk.exercise;
/**
* @author BK
* @description: 伪共享测试
* @date 2019-09-02 01:01
*/
public class FalseSharingTest {
//核心数据
private volatile long value;
// cache line padding
private long p1, p2, p3, p4, p5, p6=1L;
}
该对象中定义一个long类型的value是核心数据 ,还有p1-p6 t个Long类型的固定值1,因为value + (p1+..+p6) 是7个Long 类型,一个long类型8字符,总大小为56字节,再加上java中对象头占用的8个字节,刚好一个缓存行的大小64字节,这样就解决了伪共享。这种缓存行填充方法在早期是比较流行的一种解决办法,比较有名的Disruptor框架就采用了这种解决办法提高性能。
Java7 对伪共享的解决
由于Java7会编译期间会淘汰或者是重新排列无用的字段,所以原来的填充long类型无用字段的办法在Java 7下就失效了,但是伪共享依然会发生,但是将用于填充的long字段写到父类同样可以解决伪共享
package com.bk.exercise;
/**
* @author BK
* @description: 伪共享测试
* @date 2019-09-02 01:01
*/
public class FalseSharing {
// cache line padding
private long p1, p2, p3, p4, p5, p6=1L;
}
class FalseSharingTest extends FalseSharing{
//核心数据
private volatile long value;
}
Java8 对伪共享的解决
Java8中,Java官方已经提供了对伪共享的解决办法,那就是sun.misc.Contended注解。 有了这个注解解决伪共享就变得简单多了:
@sun.misc.Contended
public class FalseSharingTest {
volatile long value = 0L;
}
class FalseSharingTest extends FalseSharing{
//核心数据
private long value;
}
要注意的是直接使用此注解默认是无效的,需要在jvm启动时设置-XX:-RestrictContended
在程序中利用局部性
理解存储器层次结构本质,对于利用这些知识编辑更有效的程序有很大的帮助,推荐以下技术
- 将你的注意力集中在内循环上,大部分计算机的内存访问都发生在这里
- 通过按照数据对象存储在内存中的顺通,以步长为1的来读取数据(减少cache中数据被多次替换),来发挥中的空间局部性
- 一旦从存储器中读入一个数据对象,就尽量多地使用它,从而使得程序中的时间局部性最大
参考
深入计算机系统 第三版 第6章存储器层次结构
聊聊CacheLine的更多相关文章
- 聊聊Unity项目管理的那些事:Git-flow和Unity
0x00 前言 目前所在的团队实行敏捷开发已经有了一段时间了.敏捷开发中重要的一个话题便是如何对项目进行恰当的版本管理.项目从最初使用svn到之后的Git One Track策略再到现在的GitFlo ...
- Mono为何能跨平台?聊聊CIL(MSIL)
前言: 其实小匹夫在U3D的开发中一直对U3D的跨平台能力很好奇.到底是什么原理使得U3D可以跨平台呢?后来发现了Mono的作用,并进一步了解到了CIL的存在.所以,作为一个对Unity3D跨平台能力 ...
- fir.im Weekly - 聊聊 Google 开发者大会
中国互联网的三大错觉:索尼倒闭,诺基亚崛起,谷歌重返中国.12月8日,2016 Google 开发者大会正式发布了Google Developers 中国网站 ,包含了Android Develope ...
- 聊聊asp.net中Web Api的使用
扯淡 随着app应用的崛起,后端服务开发的也越来越多,除了很多优秀的nodejs框架之外,微软当然也会在这个方面提供更便捷的开发方式.这是微软一贯的作风,如果从开发的便捷性来说的话微软是当之无愧的老大 ...
- 没有神话,聊聊decimal的“障眼法”
0x00 前言 在上一篇文章<妥协与取舍,解构C#中的小数运算>的留言区域有很多朋友都不约而同的说道了C#中的decimal类型.事实上之前的那篇文章的立意主要在于聊聊使用二进制的计算机是 ...
- 聊聊 C 语言中的 sizeof 运算
聊聊 sizeof 运算 在这两次的课上,同学们已经学到了数组了.下面几节课,应该就会学习到指针.这个速度的确是很快的. 对于同学们来说,暂时应该也有些概念理解起来可能会比较的吃力. 先说一个概念叫内 ...
- 聊聊 Apache 开源协议
摘要 用一句话概括 Apache License 就是,你可以用这代码,但是如果开源你必须保留我写的声明:你可以改我的代码,但是如果开源你必须写清楚你改了哪些:你可以加新的协议要求,但不能与我所 公布 ...
- 【原】聊聊js代码异常监控
在平时的工作,js报错是比较常见的一个情景,尤其是有一些错误可能我们在本地测试的时候测试不出来,当发布到线上之后才可以发现,如果抢救及时,那还好,假如很晚才发 现,那就可能造成很大的损失了.如果我们前 ...
- Replication的犄角旮旯(三)--聊聊@bitmap
<Replication的犄角旮旯>系列导读 Replication的犄角旮旯(一)--变更订阅端表名的应用场景 Replication的犄角旮旯(二)--寻找订阅端丢失的记录 Repli ...
随机推荐
- 读取EXCEL文档解析工具类
package test;import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException ...
- HPE 交换机基础配置
1.交换机命名 (config)# hostname POE-SW 2.vlan创建及端口划分 1)端口加入vlan,两种方式 (config)# vlan 2 (vlan-2)# untagged ...
- 牛客NC15879 A Simple Problem
传送门:A Simple Problem 题意 给定两个序列s1和s2,同样的数字可以用相同的别的数字代替(并且也可以是出现过的数字),问s2在s1中出现了几次. 题解 首先预处理一下这两个序列,因为 ...
- Codeforces Round #647 (Div. 2) C. Johnny and Another Rating Drop(数学)
题目链接:https://codeforces.com/contest/1362/problem/C 题意 计算从 $0$ 到 $n$ 相邻的数二进制下共有多少位不同,考虑二进制下的前导 $0$ .( ...
- 使用scrapy爬取jian shu文章
settings.py中一些东西的含义可以看一下这里 python的scrapy框架的使用 和xpath的使用 && scrapy中request和response的函数参数 & ...
- hdu5459 Jesus Is Here
Problem Description I've sent Fang Fang around 201314 text messages in almost 5 years. Why can't she ...
- Codeforces Round #649 (Div. 2) C. Ehab and Prefix MEXs (构造,贪心)
题意:有长度为\(n\)的数组\(a\),要求构造一个相同长度的数组\(b\),使得\({b_{1},b_{2},....b_{i}}\)集合中没有出现过的最小的数是\(a_{i}\). 题解:完全可 ...
- Python 遭遇 ProxyError 问题记录
最近遇到的一个问题,在搞清楚之后才发现这么多年的 HTTPS_PROXY 都配置错了! 起因 想用 Python 在网上下载一些图片素材,结果 requests 报错 requests.excepti ...
- java源码之集合类ArrayList
1. ArrayList概述: ArrayList是List接口的可变数组的实现.实现了所有可选列表操作,并允许包括 null 在内的所有元素.除了实现 List 接口外,此类还提供一些方法来操作内部 ...
- 334A Candy Bags
A. Candy Bags time limit per test 1 second memory limit per test 256 megabytes input standard input ...